


Nachrichten vom 10. November: Große Sprachmodelle (LLM) nehmen rasant zu und zeigen gute Aussichten für die Sprachgenerierung und das Sprachverständnis. Ihr Einfluss geht über den Bereich der Sprache hinaus und erstreckt sich auf Logik, Mathematik, Physik und andere Bereiche.
Allerdings müssen Sie einen hohen Preis zahlen, um diese „außergewöhnliche Energie“ freizuschalten. Zum Beispiel erfordert das Training eines 540B-Modells 6144 TPUv4-Chips von Project PaLM und das Training von 175B GPT-3 erfordert Tausende von Petaflops – Tag.
Eine gute Lösung besteht darin, mit geringer Präzision zu trainieren, was die Verarbeitungsgeschwindigkeit erhöhen und die Speichernutzung und Kommunikationskosten reduzieren kann. Zu den aktuellen Mainstream-Trainingssystemen gehören Megatron-LM, MetaSeq und Colossal-AI, die standardmäßig FP16/BF16-Mischpräzision oder FP32-Vollpräzision verwenden, um große Sprachmodelle zu trainieren
Diese Genauigkeitsstufen sind zwar für große Sprachmodelle unerlässlich, aber sie sind es rechenintensiv.
Wenn Sie FP8 mit niedriger Präzision verwenden, können Sie die Geschwindigkeit um das Zweifache erhöhen, die Speicherkosten um 50 % bis 75 % senken und Kommunikationskosten sparen.
Derzeit ist nur die Nvidia Transformer Engine mit dem FP8-Framework kompatibel und nutzt diese Präzision hauptsächlich für GEMM-Berechnungen (General Matrix Multiplication), während Master-Gewichte und -Verläufe mit hoher FP16- oder FP32-Präzision beibehalten werden.
Um dieser Herausforderung zu begegnen, hat ein Forscherteam von Microsoft Azure und Microsoft Research ein effizientes FP8-Framework mit gemischter Präzision eingeführt, das auf das Training großer Sprachmodelle zugeschnitten ist.
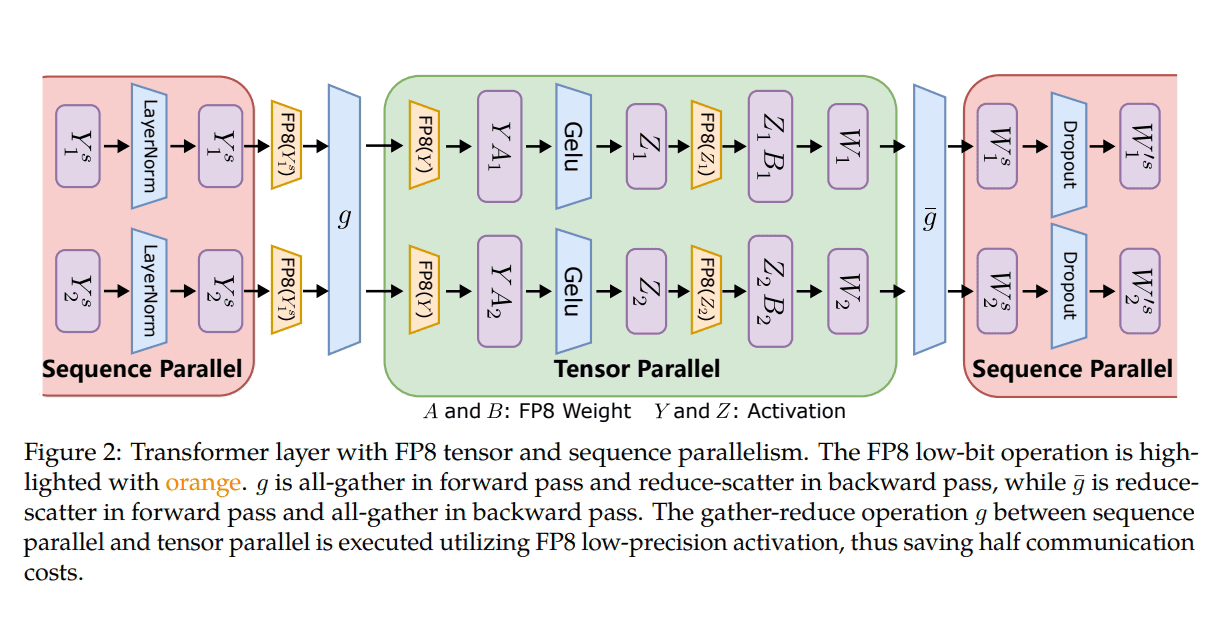
Microsoft hat drei Optimierungsstufen eingeführt, um FP8 für verteiltes und gemischtes Präzisionstraining zu nutzen. Je weiter diese Stufen voranschreiten, desto stärker wird die Integration von FP8, was auf einen größeren Einfluss auf den LLM-Ausbildungsprozess hindeutet.
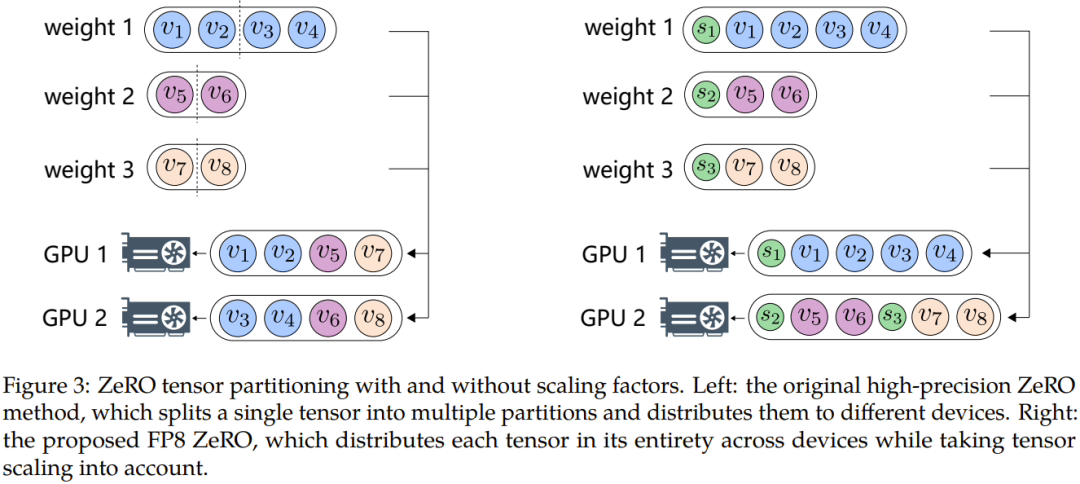
Um Probleme wie Datenüberlauf oder -unterlauf zu überwinden, schlugen Microsoft-Forscher außerdem zwei Schlüsselmethoden vor: automatische Abtastung und präzise Entkopplung. Erstere umfasst Komponenten, die nicht empfindlich auf Genauigkeit reagieren, die Genauigkeit verringern und die Tensor-Abtastung dynamisch anpassen Faktor, um sicherzustellen, dass der Gradientenwert innerhalb des FP8-Darstellungsbereichs erhalten bleibt. Dies verhindert Unterlauf- und Überlaufereignisse während der Kommunikation und sorgt so für einen reibungsloseren Trainingsprozess.
Microsoft hat getestet, dass im Vergleich zur weit verbreiteten BF16-Methode mit gemischter Präzision die Speichernutzung um 27 % bis 42 % und der Gewichtsgradienten-Kommunikationsaufwand deutlich um 63 % bis 65 % reduziert wird. Läuft 64 % schneller als weit verbreitete BF16-Frameworks wie Megatron-LM und 17 % schneller als die Nvidia Transformer Engine.
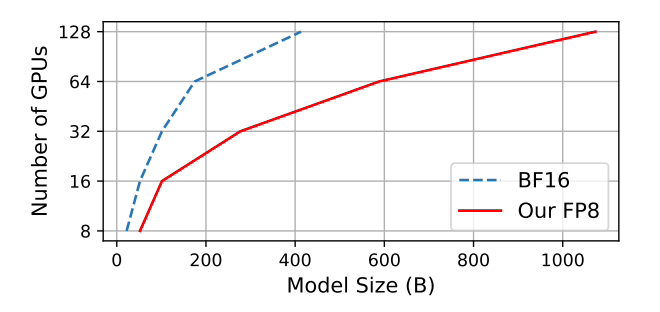
Beim Training des GPT-175B-Modells spart das hybride FP8-Präzisionsframework 21 % Speicher auf der H100-GPU-Plattform und reduziert die Trainingszeit im Vergleich zu TE (Transformer Engine) um 17 %.
Diese Seite fügt hier die GitHub-Adresseund die Thesenadresse hinzu:https://www.php.cn/link/7b3564b05f78b6739d06a2ea3187f5ca
Das obige ist der detaillierte Inhalt vonMicrosoft veröffentlicht neues Mixed Precision Training Framework FP8: 64 % schneller als BF16, 42 % weniger Speicherverbrauch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



