
 Technologie-Peripheriegeräte
KI
Lassen Sie große KI-Modelle autonom Fragen stellen: GPT-4 beseitigt Barrieren beim Gespräch mit Menschen und zeigt ein höheres Leistungsniveau
Technologie-Peripheriegeräte
KI
Lassen Sie große KI-Modelle autonom Fragen stellen: GPT-4 beseitigt Barrieren beim Gespräch mit Menschen und zeigt ein höheres Leistungsniveau
Lassen Sie große KI-Modelle autonom Fragen stellen: GPT-4 beseitigt Barrieren beim Gespräch mit Menschen und zeigt ein höheres Leistungsniveau

Bei den neuesten Trends im Bereich der künstlichen Intelligenz hat die Qualität künstlich generierter Eingabeaufforderungen einen entscheidenden Einfluss auf die Antwortgenauigkeit großer Sprachmodelle (LLM). OpenAI geht davon aus, dass präzise, detaillierte und spezifische Fragen für die Leistung dieser großen Sprachmodelle von entscheidender Bedeutung sind. Können normale Benutzer jedoch sicherstellen, dass ihre Fragen für LLM klar genug sind?
Der Inhalt, der neu geschrieben werden muss, ist: Es ist erwähnenswert, dass es einen erheblichen Unterschied zwischen dem natürlichen Verständnis des Menschen in bestimmten Situationen und der Interpretation von Maschinen gibt. Beispielsweise bezieht sich das Konzept der „geraden Monate“ offensichtlich auf Monate wie Februar und April für Menschen, aber GPT-4 missversteht es möglicherweise als Monate mit einer geraden Anzahl von Tagen. Dies zeigt nicht nur die Grenzen künstlicher Intelligenz beim Verständnis alltäglicher Zusammenhänge auf, sondern regt uns auch dazu an, darüber nachzudenken, wie wir mit diesen großen Sprachmodellen effektiver kommunizieren können. Angesichts der kontinuierlichen Weiterentwicklung der Technologie der künstlichen Intelligenz ist die Frage, wie die Kluft zwischen Mensch und Maschine beim Sprachverständnis überbrückt werden kann, ein wichtiges Thema für die zukünftige Forschung.
In dieser Angelegenheit hat das General Research Institute unter der Leitung von Professor Gu Quanquan von der University of California , Los Angeles (UCLA) Das Artificial Intelligence Laboratory hat einen Forschungsbericht veröffentlicht, der eine innovative Lösung für das Mehrdeutigkeitsproblem beim Problemverständnis großer Sprachmodelle (wie GPT-4) vorschlägt. Diese Forschung wurde von den Doktoranden Deng Yihe, Zhang Weitong und Chen Zixiang abgeschlossen Adresse: https://uclaml.github.io/Rephrase-and-Respond

Der neu geschriebene chinesische Inhalt ist: Der Kern dieser Lösung besteht darin, ein großes Sprachmodell die aufgeworfenen Fragen wiederholen und erweitern zu lassen, um so zu helfen um die Genauigkeit Ihrer Antworten zu verbessern. Die Studie ergab, dass die von GPT-4 neu formulierten Fragen detaillierter und das Fragenformat klarer waren. Diese Methode der Neuformulierung und Erweiterung verbessert die Antwortgenauigkeit des Modells erheblich. Experimente haben gezeigt, dass eine gut einstudierte Frage die Genauigkeit der Antwort von 50 % auf nahezu 100 % erhöht. Diese Leistungsverbesserung zeigt nicht nur das Potenzial zur Selbstverbesserung großer Sprachmodelle, sondern bietet auch eine neue Perspektive, wie künstliche Intelligenz menschliche Sprache effektiver verarbeiten und verstehen kann. Eine einfache, aber effektive Aufforderung: „Formulieren Sie die Frage neu und erweitern Sie sie.“ antworten“ (kurz: RaR). Dieses prompte Wort verbessert direkt die Qualität der LLM-Antworten auf Fragen und zeigt eine wichtige Verbesserung bei der Problembearbeitung.
- Das Forschungsteam schlug außerdem eine Variante von RaR namens „Two-step RaR“ vor, um die Fähigkeit großer Modelle wie GPT-4, das Problem neu zu formulieren, voll auszunutzen. Dieser Ansatz besteht aus zwei Schritten: Erstens wird für eine bestimmte Frage ein spezielles Umformulierungs-LLM verwendet, um eine Umformulierungsfrage zu generieren. Zweitens werden die ursprüngliche Frage und die umformulierte Frage kombiniert und verwendet, um ein antwortendes LLM zur Antwort aufzufordern.
- Ergebnisse
Die Forscher führten Experimente zu verschiedenen Aufgaben durch und die Ergebnisse zeigten, dass sowohl einstufiges RaR als auch zweistufiges RaR die Antwortgenauigkeit von GPT4 effektiv verbessern können. Bemerkenswert ist, dass RaR erhebliche Verbesserungen bei Aufgaben zeigt, die für GPT-4 ansonsten eine Herausforderung darstellen würden, und in einigen Fällen sogar eine Genauigkeit von nahezu 100 % erreicht. Das Forschungsteam fasste die folgenden zwei wichtigen Schlussfolgerungen zusammen:
1. Restate and Extend (RaR) bietet eine Plug-and-Play-Blackbox-Eingabeaufforderungsmethode, die die Leistung von LLM bei verschiedenen Aufgaben effektiv verbessern kann.
2. Bei der Bewertung der Leistung von LLM bei Fragebeantwortungsaufgaben (QA) ist es entscheidend, die Qualität der Fragen zu überprüfen. 
Die Forscher verwendeten die zweistufige RaR-Methode, um Untersuchungen durchzuführen, um die Leistung verschiedener Modelle wie GPT-4, GPT-3.5 und Vicuna-13b-v.15 zu untersuchen. Experimentelle Ergebnisse zeigen, dass die RaR-Methode bei Modellen mit komplexerer Architektur und stärkeren Verarbeitungsfähigkeiten wie GPT-4 die Genauigkeit und Effizienz von Verarbeitungsproblemen erheblich verbessern kann. Bei einfacheren Modellen wie Vicuna ist die Verbesserung zwar geringer, zeigt aber dennoch die Wirksamkeit der RaR-Strategie. Auf dieser Grundlage untersuchten die Forscher die Qualität der Fragen weiter, nachdem sie verschiedene Modelle nacherzählt hatten. Wiederholungsfragen für kleinere Modelle können manchmal die Absicht der Frage zerstören. Und fortgeschrittene Modelle wie GPT-4 stellen Paraphrasierungsfragen bereit, die mit menschlichen Absichten übereinstimmen und die Antworten anderer Modelle verbessern können

Dieser Befund zeigt ein wichtiges Phänomen: Verschiedene Ebenen der Paraphrasierung von Sprachmodellen. Die Fragen variieren in Qualität und Qualität Wirksamkeit. Insbesondere bei fortgeschrittenen Modellen wie GPT-4 verschaffen die darin neu formulierten Probleme nicht nur ein klareres Verständnis des Problems, sondern können auch als effektiver Input zur Verbesserung der Leistung anderer kleinerer Modelle dienen.
Unterschied von Chain of Thought (CoT)
Um den Unterschied zwischen RaR und Chain of Thought (CoT) zu verstehen, schlugen Forscher ihre mathematischen Darstellungen vor und stellten klar, wie sich RaR mathematisch von CoT unterscheidet und wie einfach sie dies können kombiniert werden.
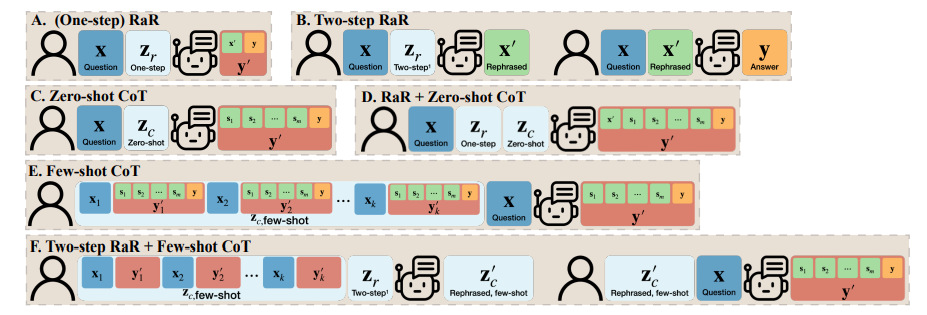
Bevor wir uns mit der Verbesserung der Denkfähigkeit des Modells befassen, weist diese Studie darauf hin, dass die Qualität der Fragen verbessert werden sollte, um sicherzustellen, dass die Denkfähigkeit des Modells korrekt bewertet werden kann. Beispielsweise wurde beim Problem „Münzwurf“ festgestellt, dass GPT-4 „Flip“ als eine zufällige Wurfaktion verstand, die sich von der menschlichen Absicht unterschied. Auch wenn „Lass uns Schritt für Schritt denken“ als Leitfaden für die Argumentation des Modells verwendet wird, bleibt dieses Missverständnis während des Schlussfolgerungsprozesses bestehen. Erst nach Klärung der Frage beantwortete das große Sprachmodell die beabsichtigte Frage

Darüber hinaus stellten die Forscher fest, dass neben dem Fragetext auch die für das Fence-Shot-CoT verwendeten Q&A-Beispiele von Menschen geschrieben wurden. Dies wirft die Frage auf: Wie reagieren große Sprachmodelle (LLMs), wenn diese künstlich konstruierten Beispiele fehlerhaft sind? Diese Studie liefert ein interessantes Beispiel und kommt zu dem Schluss, dass schlechte CoT-Beispiele mit wenigen Schüssen einen negativen Einfluss auf LLM haben können. Am Beispiel der Aufgabe „Final Letter Join“ zeigten die zuvor verwendeten Problembeispiele positive Effekte bei der Verbesserung der Modellleistung. Als sich jedoch die Eingabeaufforderungslogik änderte, beispielsweise von der Suche nach dem letzten Buchstaben zur Suche nach dem ersten Buchstaben, gab GPT-4 die falsche Antwort. Dieses Phänomen unterstreicht die Empfindlichkeit des Modells gegenüber künstlichen Beispielen.

Forscher haben herausgefunden, dass GPT-4 mithilfe von RaR logische Fehler in einem bestimmten Beispiel beheben und dadurch die Qualität und Robustheit von CoTs mit wenigen Schüssen verbessern kann.
Fazit: Mensch und große Kommunikation zwischen Sprachmodelle (LLMs) können missverstanden werden: Fragen, die für Menschen klar erscheinen, können von großen Sprachmodellen als andere Fragen verstanden werden. Das UCLA-Forschungsteam löste dieses Problem, indem es RaR vorschlug, eine neuartige Methode, die LLM dazu veranlasst, die Frage noch einmal zu formulieren und zu klären, bevor sie beantwortet wird. Weitere Analyseergebnisse zeigen, dass die Problemqualität durch Neuformulierung des Problems verbessert werden kann und dieser Verbesserungseffekt auf verschiedene Modelle übertragen werden kann
Für die Zukunft wird erwartet, dass RaR-ähnliche Methoden weiterhin verbessert werden Gleichzeitig wird die Integration mit anderen Methoden wie CoT eine genauere und effizientere Möglichkeit zur Interaktion zwischen Menschen und großen Sprachmodellen bieten und letztendlich die Grenzen der Erklärungs- und Argumentationsfähigkeiten der KI erweitern
Das obige ist der detaillierte Inhalt vonLassen Sie große KI-Modelle autonom Fragen stellen: GPT-4 beseitigt Barrieren beim Gespräch mit Menschen und zeigt ein höheres Leistungsniveau. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
