
 Technologie-Peripheriegeräte
KI
Die große Modellforschung von Google hat heftige Kontroversen ausgelöst: Die Generalisierungsfähigkeit über die Trainingsdaten hinaus wurde in Frage gestellt, und Internetnutzer sagten, dass sich die AGI-Singularität möglicherweise verzögern könnte.
Technologie-Peripheriegeräte
KI
Die große Modellforschung von Google hat heftige Kontroversen ausgelöst: Die Generalisierungsfähigkeit über die Trainingsdaten hinaus wurde in Frage gestellt, und Internetnutzer sagten, dass sich die AGI-Singularität möglicherweise verzögern könnte.
Die große Modellforschung von Google hat heftige Kontroversen ausgelöst: Die Generalisierungsfähigkeit über die Trainingsdaten hinaus wurde in Frage gestellt, und Internetnutzer sagten, dass sich die AGI-Singularität möglicherweise verzögern könnte.

Ein neues Ergebnis, das kürzlich von Google DeepMind entdeckt wurde, hat im Transformer-Bereich für große Kontroversen gesorgt:
Seine Generalisierungsfähigkeit kann nicht auf Inhalte ausgeweitet werden, die über die Trainingsdaten hinausgehen.
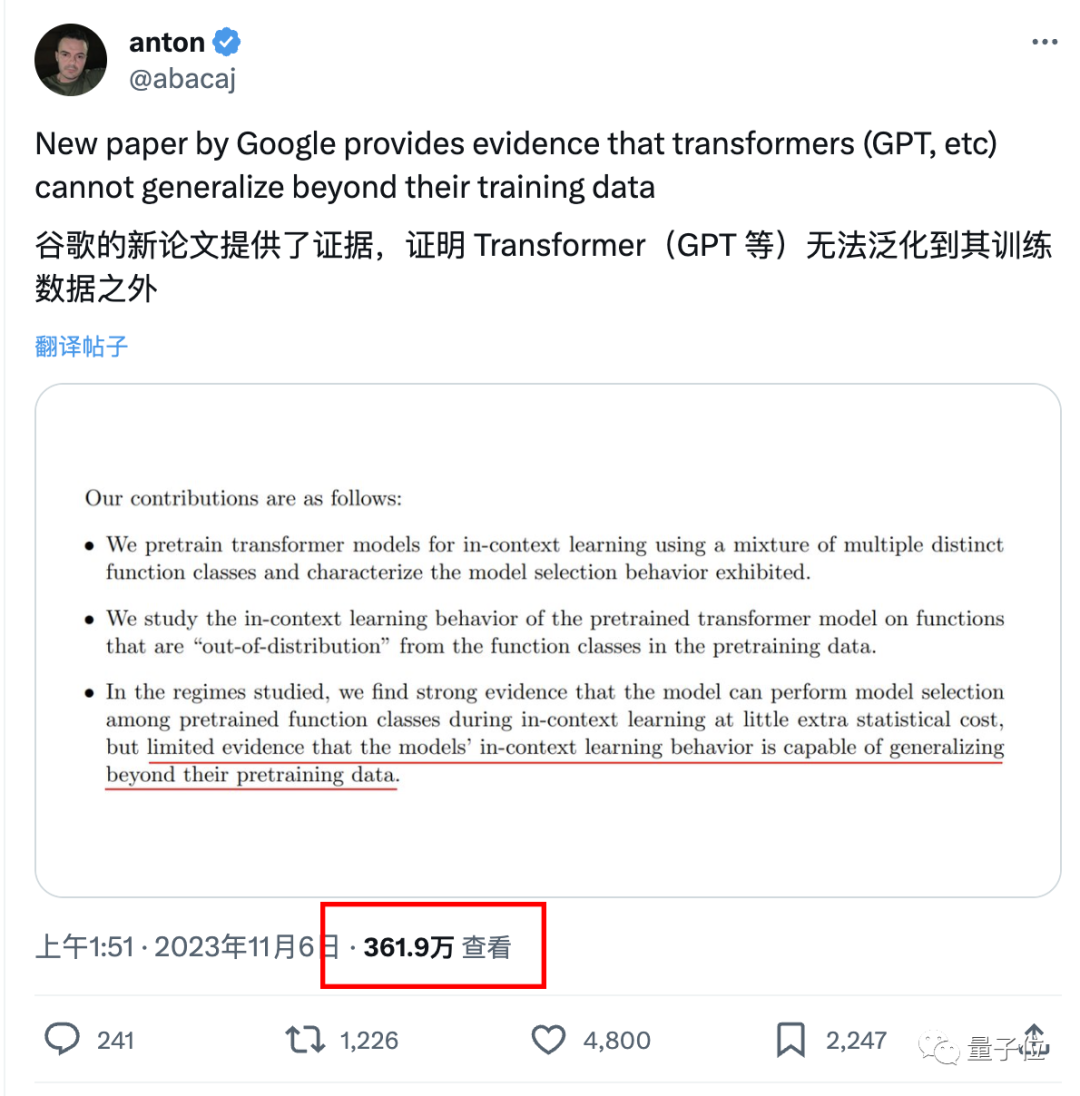
Diese Schlussfolgerung wurde derzeit nicht weiter bestätigt, aber sie hat viele große Namen alarmiert. Francois Chollet, der Vater von Keras, sagte beispielsweise, dass es zu einem großen Ereignis werden würde, wenn die Nachricht wahr sei der großen Modellindustrie.

Google Transformer ist die Infrastruktur hinter den heutigen großen Modellen, und das uns bekannte „T“ in GPT bezieht sich darauf.
Eine Reihe großer Modelle zeigt starke kontextbezogene Lernfähigkeiten und kann schnell Beispiele lernen und neue Aufgaben erledigen.
Aber jetzt scheinen Forscher auch von Google auf seinen fatalen Fehler hingewiesen zu haben – es ist machtlos gegenüber den Trainingsdaten, also dem vorhandenen menschlichen Wissen.
Eine Zeit lang glaubten viele Praktizierende, dass AGI wieder außer Reichweite geraten sei.
Einige Internetnutzer wiesen darauf hin, dass einige wichtige Details in der Arbeit ignoriert wurden, z. B. dass das Experiment nur den Maßstab von GPT-2 umfasst und die Trainingsdaten nicht umfangreich genug sind
Wie Mit der Zeit wiesen ernsthaftere Internetnutzer, die dieses Papier studiert haben, darauf hin, dass an den Forschungsergebnissen selbst nichts Falsches sei, aber die Leute auf ihrer Grundlage übermäßige Interpretationen vorgenommen hätten.

Nachdem das Papier heftige Diskussionen unter Internetnutzern ausgelöst hatte, machte einer der Autoren auch öffentlich zwei Klarstellungen:
Erstens wurde im Experiment ein einfacher Transformer verwendet, der weder ein „großes“ Modell noch ein Sprachmodell ist;
Zweitens kann das Modell neue Aufgaben erlernen, aber es kann nicht auf neue Arten von Aufgaben

verallgemeinert werden. Seitdem haben einige Internetnutzer dieses Experiment in Colab wiederholt, kamen aber zu völlig anderen Ergebnissen.

Also werfen wir zunächst einen Blick auf dieses Papier und darauf, was Samuel, der andere Ergebnisse vorschlug, dazu gesagt hat.
Die neue Funktion ist fast unmöglich vorherzusagen
In diesem Experiment verwendete der Autor ein Jax-basiertes Framework für maschinelles Lernen, um ein Transformer-Modell zu trainieren, das der Größe von GPT-2 nahe kommt und nur den Decoder-Teil enthält
Dieses Modell enthält 12 Schichten, 8 Es gibt einen Aufmerksamkeitskopf, die Einbettungsraumdimension beträgt 256 und die Anzahl der Parameter beträgt etwa 9,5 Millionen
Um seine Generalisierungsfähigkeit zu testen, wählte der Autor Funktionen als Testobjekt. Sie geben die lineare Funktion und die Sinusfunktion als Trainingsdaten in das Modell ein, und die Vorhersageergebnisse sind natürlich sehr gut, wenn die Forscher die lineare Funktion und die Sinusfunktion vergleichen , Probleme entstehen bei der Kombination von Konvexitäten.
Konvexitätskombination ist nicht so mysteriös. Der Autor hat eine Funktion der Form f(x)=a·kx+(1-a)sin(x) konstruiert . .
Wir glauben das, weil unser Gehirn für diese Verallgemeinerungsfähigkeit ausgelegt ist, aber große Modelle sind anders.
Bei Modellen, denen nur lineare und Sinusfunktionen beigebracht wurden, sieht die einfache Addition neu aus.
Für diese neue Funktion haben die Vorhersagen von Transformer dies getan fast keine Genauigkeit (siehe Abbildung 4c), daher glaubt der Autor, dass das Modell nicht in der Lage ist, die Funktion zu verallgemeinern
Um seine Schlussfolgerung weiter zu überprüfen, passte der Autor das Gewicht der linearen oder sinusförmigen Funktion an, aber trotzdem änderte sich die Vorhersageleistung des Transformers nicht wesentlich.
Es gibt nur eine Ausnahme: Wenn das Gewicht eines der Elemente nahe bei 1 liegt, stimmen die Vorhersageergebnisse des Modells eher mit der tatsächlichen Situation überein.
Wenn das Gewicht 1 ist, bedeutet dies, dass die unbekannte neue Funktion direkt zu der Funktion wird, die während des Trainings gesehen wurde. Diese Art von Daten trägt offensichtlich nicht zur Generalisierungsfähigkeit des Modells bei. Weitere Experimente zeigen dies ebenfalls Der Transformator reagiert nicht nur sehr empfindlich auf die Art der Funktion, und selbst die gleiche Art von Funktion kann zu ungewohnten Bedingungen führen.
Forscher haben herausgefunden, dass sich die Vorhersageergebnisse zu ändern scheinen, wenn die Frequenz einer Sinusfunktion, selbst eines einfachen Funktionsmodells, geändert wird. 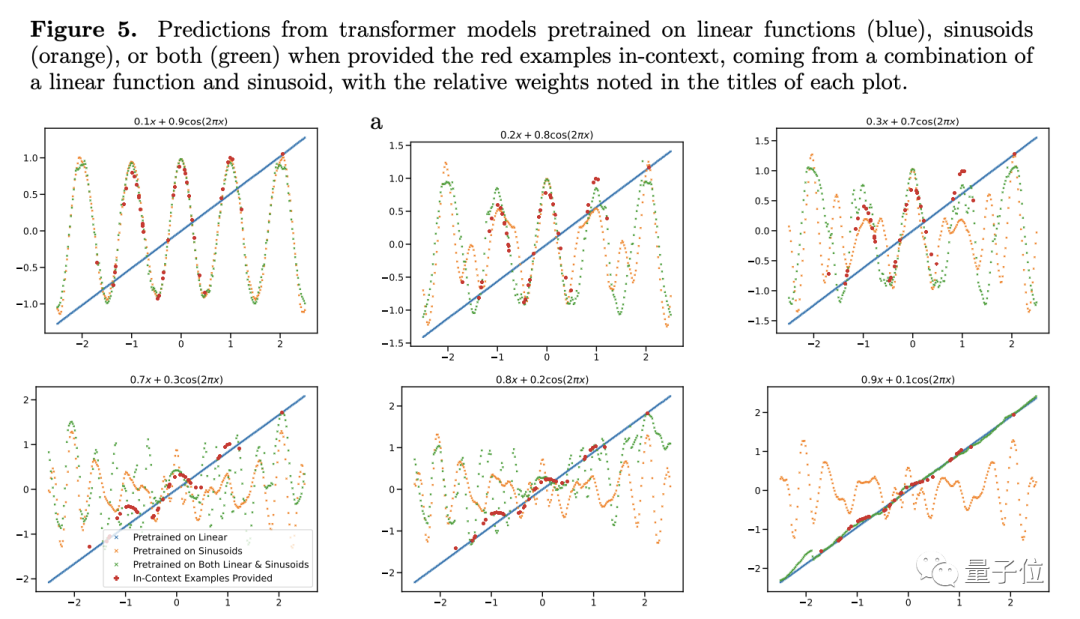
Demnach glaubt der Autor, dass das große Modell es nicht wissen wird, solange die Bedingungen leicht unterschiedlich sind Was ist zu tun? Bedeutet das nicht, dass Ihre chemischen Fähigkeiten im Allgemeinen schlecht sind?
Der Autor beschrieb in dem Artikel auch einige Einschränkungen bei der Forschung und wie man Beobachtungen zu Funktionsdaten auf Probleme mit tokenisierter natürlicher Sprache anwenden kann. 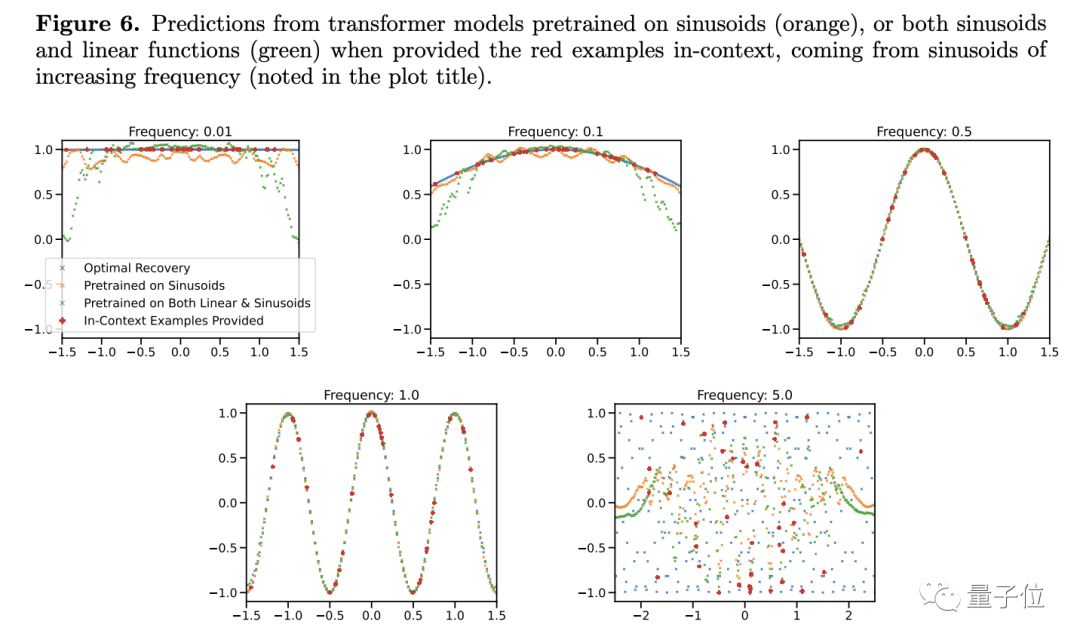
Gu Quanquan, Gewinner des Sloan-Preises und UCLA-Professor, sagte, dass die Schlussfolgerung des Papiers selbst Es gibt keine Kontroversen, aber es sollte nicht überinterpretiert werden.
Laut früheren Untersuchungen kann das Transformer-Modell nicht nur dann verallgemeinern, wenn es mit Inhalten konfrontiert wird, die sich erheblich von den Daten vor dem Training unterscheiden. Tatsächlich wird die Generalisierungsfähigkeit großer Modelle normalerweise anhand der Vielfalt und Komplexität der Aufgaben bewertet. 
Wenn Sie die Generalisierungsfähigkeit von Transformer sorgfältig untersuchen, befürchte ich, dass die Kugel für eine Weile fliegen wird.
Aber was können Sie tun, selbst wenn Ihnen die Fähigkeit zur Generalisierung wirklich fehlt? 
die Trainingsdaten das sind, was uns wichtig ist.
 Jim fügte weiter hinzu: Das ist so, als würde man sagen, dass man 100 Milliarden Fotos von Katzen und Hunden verwendet, um ein visuelles Modell zu trainieren, und das Modell dann auffordert, Flugzeuge zu erkennen, und dann stellt man fest, dass das wirklich nicht der Fall ist erkenne sie.
Jim fügte weiter hinzu: Das ist so, als würde man sagen, dass man 100 Milliarden Fotos von Katzen und Hunden verwendet, um ein visuelles Modell zu trainieren, und das Modell dann auffordert, Flugzeuge zu erkennen, und dann stellt man fest, dass das wirklich nicht der Fall ist erkenne sie.
Daher besteht in einem zielorientierten Prozess, egal ob es sich um ein großes Modell oder einen Menschen handelt, das ultimative Ziel darin, das Problem zu lösen, und die Verallgemeinerung ist nur ein Mittel
Ändern Sie diesen Ausdruck ins Chinesische. Trainieren Sie ihn dann, bis keine anderen Daten als das Trainingsbeispiel vorhanden sind.
Was halten Sie von dieser Forschung?
Papieradresse: https://arxiv.org/abs/2311.00871
Das obige ist der detaillierte Inhalt vonDie große Modellforschung von Google hat heftige Kontroversen ausgelöst: Die Generalisierungsfähigkeit über die Trainingsdaten hinaus wurde in Frage gestellt, und Internetnutzer sagten, dass sich die AGI-Singularität möglicherweise verzögern könnte.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek ist eine proprietäre Suchmaschine, die nur schneller und genauer in einer bestimmten Datenbank oder einem bestimmten System sucht. Bei der Verwendung wird den Benutzern empfohlen, das Dokument zu lesen, verschiedene Suchstrategien auszuprobieren, Hilfe und Feedback zur Benutzererfahrung zu suchen, um die Vorteile optimal zu nutzen.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Dieser Artikel empfiehlt die Top Ten Ten Cryptocurrency -Handelsplattformen, die es wert sind, auf Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI und Xbit -dezentrale Börsen geachtet zu werden. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Transaktionswährungsmenge, Transaktionstyp, Sicherheit, Konformität und Besonderheiten. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf eigener Handelserfahrung, Risikotoleranz und Investitionspräferenzen basiert. Ich hoffe, dieser Artikel hilft Ihnen dabei, den besten Anzug für sich selbst zu finden
 Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Befolgen Sie diese einfachen Schritte, um auf die neueste Version des Binance -Website -Login -Portals zuzugreifen. Gehen Sie zur offiziellen Website und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Anmeldung". Wählen Sie Ihre vorhandene Anmeldemethode. Geben Sie Ihre registrierte Handynummer oder E -Mail und Kennwort ein und vervollständigen Sie die Authentifizierung (z. B. Mobilfifizierungscode oder Google Authenticator). Nach einer erfolgreichen Überprüfung können Sie auf das neueste Version des offiziellen Website -Login -Portals von Binance zugreifen.
 Die neueste Download -Adresse des Bitgets im Jahr 2025: Schritte zum Erhalten der offiziellen App
Feb 25, 2025 pm 02:54 PM
Die neueste Download -Adresse des Bitgets im Jahr 2025: Schritte zum Erhalten der offiziellen App
Feb 25, 2025 pm 02:54 PM
Dieser Leitfaden enthält detaillierte Download- und Installationsschritte für die offizielle Bitget Exchange -App, die für Android- und iOS -Systeme geeignet ist. Der Leitfaden integriert Informationen aus mehreren maßgeblichen Quellen, einschließlich der offiziellen Website, dem App Store und Google Play, und betont Überlegungen während des Downloads und des Kontoverwaltung. Benutzer können die App aus offiziellen Kanälen herunterladen, einschließlich App Store, offizieller Website APK Download und offizieller Website -Sprung sowie vollständige Registrierung, Identitätsüberprüfung und Sicherheitseinstellungen. Darüber hinaus deckt der Handbuch häufig gestellte Fragen und Überlegungen ab, wie z.
