
 Technologie-Peripheriegeräte
KI
Patent zur parallelen menschlichen Haltungsschätzung: Microsoft AR/VR-Technologie realisiert virtuelle Darstellung
Technologie-Peripheriegeräte
KI
Patent zur parallelen menschlichen Haltungsschätzung: Microsoft AR/VR-Technologie realisiert virtuelle Darstellung
Patent zur parallelen menschlichen Haltungsschätzung: Microsoft AR/VR-Technologie realisiert virtuelle Darstellung

(Nweon, 13. November 2023) Informationen über die Körperhaltung menschlicher Benutzer können auf virtuelle artikulierte Darstellungen abgebildet werden. Wenn beispielsweise ein menschlicher Benutzer an einer Virtual-Reality-Umgebung teilnimmt, weist er in der virtuellen Umgebung Haltungen auf, die den Haltungen in der realen Welt ähneln. Die reale Pose des Benutzers kann von einem zuvor trainierten Modell in die Pose einer virtuellen artikulierten Darstellung umgewandelt werden, und das Modell kann so trainiert werden, dass es die gleiche Pose der virtuellen artikulierten Darstellung für das endgültige Rendern ausgibt.
Manchmal muss das System eine unrealistische Leistung zeigen. Benutzer können beispielsweise Zeichentrickfiguren mit unterschiedlichen Körperproportionen, Knochen oder anderen Aspekten auswählen
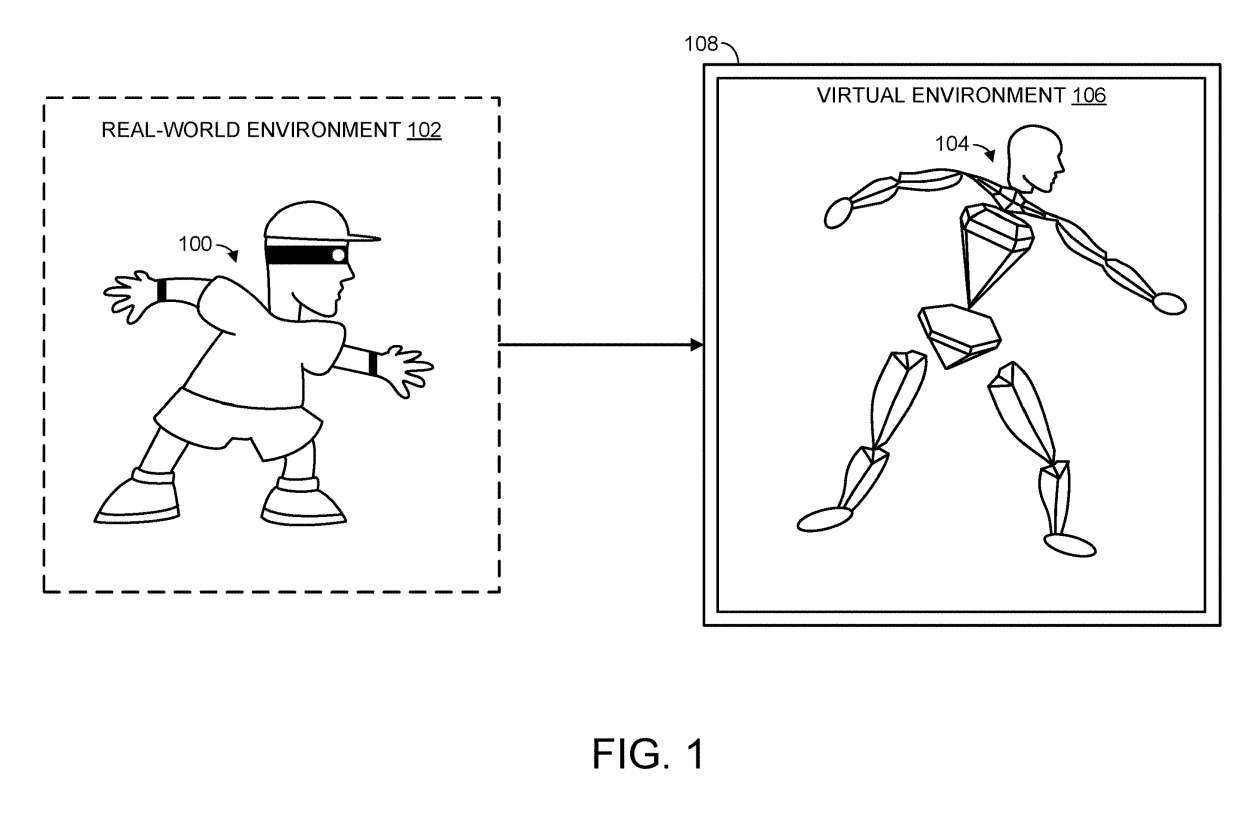
Wie in Abbildung 1 gezeigt, ist ein menschlicher Benutzer 100 in einer realen Umgebung 102 dargestellt. Wie zu sehen ist, werden die Gesten des menschlichen Benutzers auf die artikulierte Darstellung 104 angewendet. Mit anderen Worten: Wenn ein menschlicher Benutzer Aktivitäten in einer realen Umgebung ausführt, werden die entsprechenden Aktionen in Bewegungen der artikulierten Darstellung 104 in der virtuellen Umgebung 106 übersetzt
Manchmal kann sich die virtuelle Artikulationsdarstellung von der zum Trainieren des Modells verwendeten Darstellung unterscheiden und muss neu geschrieben werden. Um dieses Problem zu lösen, führt das Microsoft-Patent „Concurrent human Pose Estimates for Virtual Representation“ eine Technologie ein, die gleichzeitig die Posen der Modell-Artikulationsdarstellung und der Ziel-Artikulationsdarstellung schätzen kann
Konkret empfängt das Computersystem Positionsdaten detaillierter Parameter eines oder mehrerer Körperteile eines menschlichen Benutzers, die zumindest teilweise auf Eingaben von einem oder mehreren Sensoren basieren. Zu diesen Sensoren können der Ausgang der Trägheitsmesseinheit des Headsets sowie der Ausgang der entsprechenden Kamera gehören
Der neu geschriebene Inhalt lautet: Das System behält gleichzeitig eine oder mehrere Zuordnungsbeschränkungen der Modellgelenkdarstellung bei, die mit der Zielgelenkdarstellung verknüpft sind, z. B. Gelenkzuordnungsbeschränkungen. Die Möglichkeit zur Posenoptimierung nutzt Positionierungsdaten und Zuordnungsbeschränkungen, um gleichzeitig die durch die Modellgelenke dargestellte Pose und die durch die Zielgelenke dargestellte Zielhaltung zu schätzen. Sobald die Schätzung abgeschlossen ist, kann das System die Zielgelenkdarstellung zusammen mit der Zielhaltung als virtuelle Darstellung für menschliche Benutzer anzeigen
Die Maschine zur Posenoptimierung kann mithilfe von Trainingspositionierungsdaten mit Ground-Truth-Labels für die artikulierte Darstellung des Modells trainiert werden. Den Trainingslokalisierungsdaten fehlen jedoch möglicherweise Ground-Truth-Labels für Zielartikulationsdarstellungen.
Mit diesem Ansatz kann eine genaue Reproduktion realer Posen effektiv erreicht werden, ohne dass teure Trainingsberechnungen für jedes einzelne potenzielle Ziel erforderlich sind. Eine erfinderische Beschreibung dieser Technologie kann einen positiven Einfluss auf menschliche Nutzer haben
Wenn Benutzer an einer virtuellen Umgebung teilnehmen, können sie jederzeit während des Kommunikationsprozesses einen anderen Avatar auswählen, der sich selbst darstellt, und ihr Aussehen ändern. Dem Menü der für die Benutzerauswahl verfügbaren Darstellungen können neue artikulierte Zieldarstellungen hinzugefügt werden, ohne dass das Modell für eine bestimmte Darstellung neu trainiert werden muss, wodurch Rechenkosten gespart werden
Die in der Erfindung beschriebene Technologie kann den technischen Vorteil bieten, den Verbrauch von Rechenressourcen zu reduzieren und gleichzeitig die reale Pose eines menschlichen Benutzers genau nachzubilden und die genaue Anwendung der Pose auf jede von mehreren verschiedenen Zielartikulationsdarstellungen zu ermöglichen. Die spezifische Methode besteht darin, die Pose des Ziels und des Modells gleichzeitig abzuschätzen.
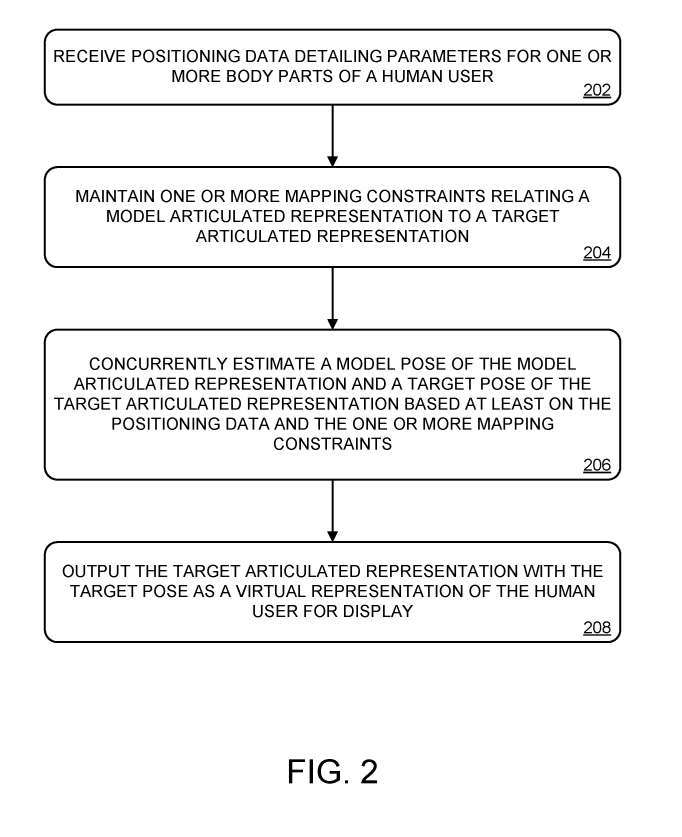
Eine Beispielmethode zur virtuellen Darstellung der menschlichen Pose 200 ist in Abbildung 2 dargestellt
Bei 202 werden Positionsdaten detaillierter Parameter eines oder mehrerer Körperteile des menschlichen Benutzers basierend auf Eingaben von einem oder mehreren Sensoren empfangen.
In 204 müssen eine oder mehrere Zuordnungsbeschränkungen im Zusammenhang mit der artikulierten Zieldarstellung beibehalten werden, um die Verbindung des Modells sicherzustellen. Wie in Abbildung 4 gezeigt, ist eine beispielhafte Modelldarstellung 400
dargestellt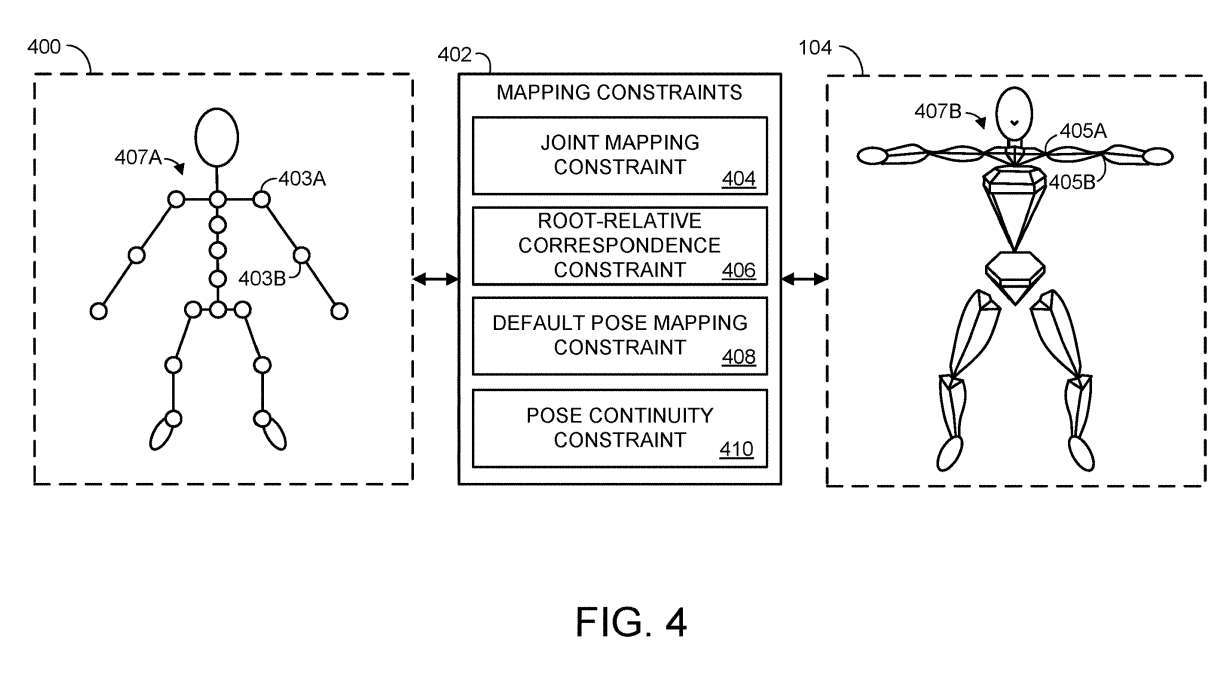
Wie oben erwähnt, wird die Ziel-Artikulationsdarstellung zur Anzeige in der virtuellen Umgebung gerendert und kann durch Ausgabe der Ziel-Pose über die Pose-Optimierungsmaschine angezeigt werden. Beispielsweise kann die artikulierte Zieldarstellung ein beliebiges geeignetes Aussehen und geeignete Proportionen haben und über eine beliebige geeignete Anzahl von Gliedmaßen, Gelenken und/oder anderen beweglichen Körperteilen verfügen.
Dies kann wie folgt umgeschrieben werden: Die artikulierte Zieldarstellung kann ein nichtmenschliches Tier, eine fiktive Figur oder einen beliebigen geeigneten Avatar darstellen. Die artikulierte Modelldarstellung und die artikulierte Zieldarstellung sind durch eine oder mehrere Zuordnungsbeschränkungen 402
miteinander verbundenEine oder mehrere Zuordnungsbeschränkungen können gemeinsame Zuordnungsbeschränkungen 404 umfassen. Für Gelenke in einer Ziel-Gelenkdarstellung gibt eine Gelenkzuordnungsbeschränkung einen Satz von einem oder mehreren Gelenken in der Gelenkdarstellung des Modells an. Beispielsweise umfasst die Modellgelenkdarstellung 400 mehrere Gelenke, von denen zwei mit 403A und 403B gekennzeichnet sind und dem Schultergelenk und dem Ellenbogengelenk entsprechen.
Zielgelenk Nr. 104 enthält ähnliche Gelenke 405A und 405B. Daher können die Gelenke 405A und 405B der Zieldarstellung mehrere unterschiedliche Gelenkzuordnungsbeschränkungen aufweisen, die die Zuordnung dieser Gelenke zu den Gelenken 403A und 403B der Modelldarstellung darstellen
Gelenkzuordnungsbeschränkungen können das Gewicht jedes Modellgelenks bei der Zuordnung zur Zielgelenkdarstellung weiter spezifizieren. Wenn beispielsweise in der Gelenkdarstellung eines Modells nur ein Gelenk einem bestimmten Gelenk der Ziel-Gelenkdarstellung zugeordnet ist, beträgt die Gewichtung der Gelenke dieses Modells möglicherweise 100 %. Wenn zwei Modellgelenke Zielgelenken zugeordnet werden, können die Gewichte der beiden Modellgelenke 50 % und 50 %, 30 % und 70 %, 10 % und 90 % usw. betragen.
In Abbildung 2 schätzt Methode 200 gleichzeitig die durch die Modellartikulation dargestellte Modellpose und die durch die Zielartikulation dargestellte Zielpose durch Optimierung der zuvor trainierten Pose. Die Schätzung der Modellpose und der Zielpose basiert zumindest teilweise auf Positionsdaten
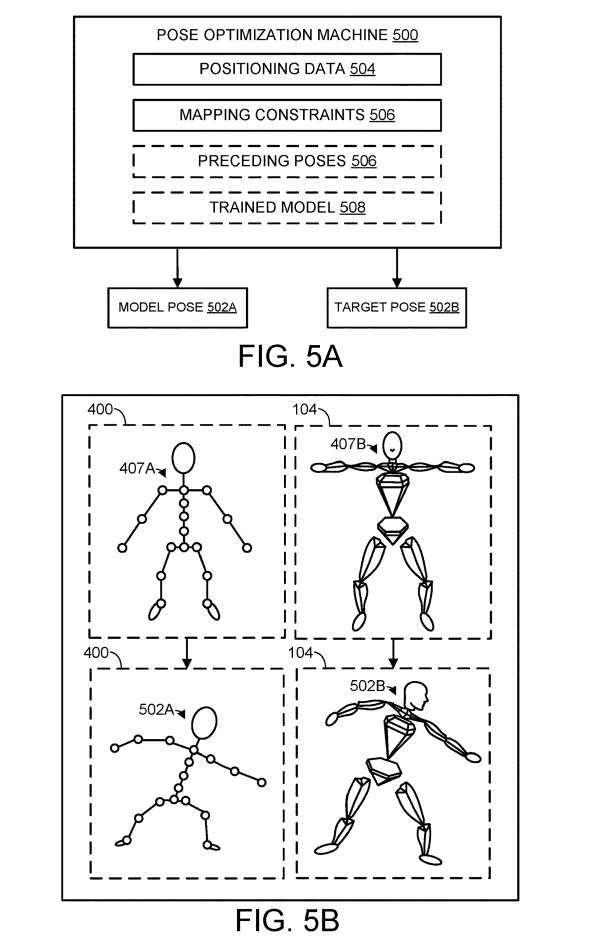
Abbildung 5A zeigt schematisch ein Beispiel einer Posenoptimierungsmaschine 500, die als jede geeignete Kombination von Computerlogikkomponenten implementiert werden kann. Als nicht einschränkendes Beispiel kann die Posenoptimierungsmaschine 500 als logisches Subsystem 602 implementiert werden, wie in Fig. 6 gezeigt.
Wie in Abbildung 5A gezeigt, schätzt die Maschine zur Haltungsoptimierung gleichzeitig die durch die Modellartikulation dargestellte Modellpose 502A und die durch die Zielartikulation dargestellte Zielpose 502B. Dies wird zumindest teilweise basierend auf Positionierungsdaten 504 und einer oder mehreren Zuordnungsbeschränkungen 506 erreicht.
Die Posenschätzung kann zumindest teilweise auf der Grundlage einer oder mehrerer vorheriger Modellposen und früherer Zielposen erfolgen, die in einem oder mehreren vorherigen Zeitrahmen geschätzt wurden. Daher speichert die Posenoptimierungsmaschine 500 mehrere vorherige Posen 506, die als mehrere lokale Drehungen für jedes Modellgelenk dargestellt werden können.
Eine oder mehrere Zuordnungsbeschränkungen können Posenkontinuitätsbeschränkungen umfassen, die von Frame zu Frame Einschränkungen hinsichtlich des Ausmaßes auferlegen, in dem sich die lokale Drehung eines bestimmten Gelenks von einem Frame zum anderen ändern kann. Eine Reihe von Zuordnungsbeschränkungen können angewendet werden, um die Kontinuität darzustellen und die lokale Drehung eines bestimmten Gelenks einzuschränken, indem der Grad der Änderung von Bild zu Bild begrenzt wird
Abbildung 5B zeigt schematisch den Prozess der Anwendung geschätzter Modell- und Zielposen auf modellierte und zielgerichtete artikulierte Darstellungen. Insbesondere zeigt FIG. 5B erneut die Standardhaltungen 407A und 407B, die der Modell-Gelenkdarstellung 400 und der Ziel-Gelenkdarstellung 104 entsprechen. Durch Ändern der Artikulationsrichtung nimmt dann die Modell-Artikulationsdarstellung 400 die Modellhaltung 502A ein, und die Ziel-Artikulationsdarstellung 104 nimmt die Zielhaltung 502B
einBei der Posenoptimierung ist es notwendig, gleichzeitig die Pose des Modells und die Pose des Ziels abzuschätzen. Mit anderen Worten: Im Gegensatz zu anderen Methoden gibt die Posenoptimierungsmaschine nicht zuerst die Posendarstellung des Modells aus und wandelt sie dann in die Posendarstellung des Ziels um. Im Gegensatz dazu ist die Posenschätzung der Prozess, bei dem gleichzeitig die Modellpose und die Zielpose gefunden werden, die eine Reihe von Einschränkungen erfüllen
Zum Beispiel kann die Pose der modellierten artikulierten Darstellung durch vorheriges Training einer Posenoptimierungsmaschine zur Ausgabe möglicher menschlicher Posen anhand eines Satzes von Positionierungsdaten eingeschränkt werden, und die Pose der Ziel-artikulierten Darstellung kann durch die Verknüpfung der Ziel-Artikulation eingeschränkt werden Darstellung zum Modell artikulierte Darstellung Eine Einschränkung, die mit einer oder mehreren Zuordnungsbeschränkungen verknüpft ist.
Darüber hinaus kann im vorherigen Training die Posenschätzung durch das maschinelle Lernmodell 508 implementiert werden, das eine Posenoptimierung durchführt. In einem Beispiel kann die Posenoptimierungsmaschine so konfiguriert sein, dass sie eine Pose basierend auf spärlich eingegebenen Positionierungsdaten ausgibt. Mit anderen Worten: Die Posenoptimierungsmaschine kann darauf trainiert werden, genauere Posenschätzungen auszugeben, was von mehr Eingabeparametern abhängt, die zur Laufzeit empfangen werden
Mit anderen Worten: Die von der Haltungsoptimierungsmaschine empfangenen Positionierungsdaten können die Rotationsparameter von n Gelenken des menschlichen Benutzers enthalten. Im vorherigen Training erhielt die Maschine zur Lageoptimierung die Rotationsparameter von n+m Gelenken als Eingabe, wobei m größer als 1 ist. Anschließend kann die geschätzte Pose des Modells durch Schätzung der Rotationsparameter der n+m Modellgelenke bestimmt werden, die durch die Modellartikulation dargestellt werden. Dazu sind mindestens Rotationsparameter erforderlich, die auf n Gelenken basieren, jedoch nicht auf m Gelenken
Darüber hinaus besteht beim Training der Einstellungsoptimierungsmaschine keine Notwendigkeit, die Grundwahrheitsbezeichnung der artikulierten Zieldarstellung einzubeziehen. Stattdessen wird die Ziel-Artikulationsdarstellung mit der Modell-Artikulationsdarstellung über eine oder mehrere Zuordnungsbeschränkungen verknüpft, die typischerweise die Zielpose so einschränken, dass sie der Modellpose im Wesentlichen ähnlich istMicrosoft weist darauf hin, dass mit der oben genannten Technologie die Geschwindigkeit des Prozesses vorteilhaft um zwei Größenordnungen gesteigert werden kann. Dies ermöglicht die gleichzeitige Schätzung von Modell- und Zielpositionen in Echtzeit, ohne dass eine spezielle Hardwarebeschleunigung erforderlich ist.
In Abbildung 2 umfasst Methode 200 die Ausgabe der Ziel-Artikulationsdarstellung mit der Zielpose als virtuelle Darstellung des menschlichen Benutzers zur Anzeige, wobei dieser Schritt bei 208 erfolgt. Beispielsweise wird in Fig. 1 die artikulierte Zieldarstellung 104 über das elektronische Anzeigegerät 108 angezeigt. Das zur Demonstration der artikulierten Darstellung des Ziels verwendete Anzeigegerät kann jede geeignete Form annehmen und jede geeignete zugrunde liegende Anzeigetechnologie verwenden
Verwandte Patente: Microsoft-Patent |. Gleichzeitige menschliche Posenschätzungen für die virtuelle Darstellung
Die Microsoft-Patentanmeldung mit dem Titel „Concurrent human Pose Estimates for Virtual Representation“ wurde ursprünglich im April 2022 eingereicht und kürzlich vom US-Patent- und Markenamt veröffentlicht.
Das obige ist der detaillierte Inhalt vonPatent zur parallelen menschlichen Haltungsschätzung: Microsoft AR/VR-Technologie realisiert virtuelle Darstellung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google Deepmind: Eine revolutionäre KI für die Wettervorhersage Die Wettervorhersage wurde einer dramatischen Transformation unterzogen, die sich von rudimentären Beobachtungen zu ausgefeilten AI-angetriebenen Vorhersagen überschreitet. Google DeepMinds Gencast, ein Bodenbrei
 Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Der Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)
 O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
Openais O1: Ein 12-tägiger Geschenkbummel beginnt mit ihrem bisher mächtigsten Modell Die Ankunft im Dezember bringt eine globale Verlangsamung, Schneeflocken in einigen Teilen der Welt, aber Openai fängt gerade erst an. Sam Altman und sein Team starten ein 12-tägiges Geschenk Ex
 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
