
 Technologie-Peripheriegeräte
KI
Eine Gewinnvorhersage ist nicht mehr schwierig. Mit der linearen Regressionsmethode von Scikit-Learn können Sie mit halbem Aufwand das Doppelte des Ergebnisses erzielen
Technologie-Peripheriegeräte
KI
Eine Gewinnvorhersage ist nicht mehr schwierig. Mit der linearen Regressionsmethode von Scikit-Learn können Sie mit halbem Aufwand das Doppelte des Ergebnisses erzielen
Eine Gewinnvorhersage ist nicht mehr schwierig. Mit der linearen Regressionsmethode von Scikit-Learn können Sie mit halbem Aufwand das Doppelte des Ergebnisses erzielen

1、简介
生成式人工智能无疑是一个改变游戏规则的技术,但对于大多数商业问题来说,回归和分类等传统的机器学习模型仍然是首选。
重写后的内容:设想一下私募股权或风险投资等投资者如何利用机器学习。要回答这个问题,首先需要了解投资者关注的数据以及数据的使用方式。投资公司的决策不仅仅基于可量化的数据,例如支出、增长和烧钱率等,还包括创始人的记录、客户反馈和产品体验等定性数据
本文将介绍线性回归的基础知识,可以在这里找到完整的代码。
需要重写的内容是:【代码】:https://github.com/RoyiHD/linear-regression
2、项目设置
本文将使用Jupyter Notebook进行这个项目。首先导入一些库。
导入库
# 绘制图表import matplotlib.pyplot as plt# 数据管理和处理from pandas import DataFrame# 绘制热力图import seaborn as sns# 分析from sklearn.metrics import r2_score# 用于训练和测试的数据管理from sklearn.model_selection import train_test_split# 导入线性模型from sklearn.linear_model import LinearRegression# 代码注释from typing import List
3、数据
为了简化问题,本文将使用区域数据。这些数据代表了公司的支出类别和利润。可以看到一些不同数据点的示例。本文希望使用支出数据来训练一个线性回归模型并预测利润。
重要的是要理解本文所描述的数据是关于一家公司的支出情况。只有当将支出数据与收入增长、当地税收、摊销和市场状况等数据结合起来时,才能得出有意义的预测能力
R&D Spend |
行政管理 |
Marketing |
投资收益 |
需要进行重写的内容是:165349.2 |
136897.8 |
需要重写的内容是:471784.1 |
需要改写的内容是:192261.83 |
162597.7 |
需要被重写的内容是:151377.59 |
443898.53 |
191792.06 |
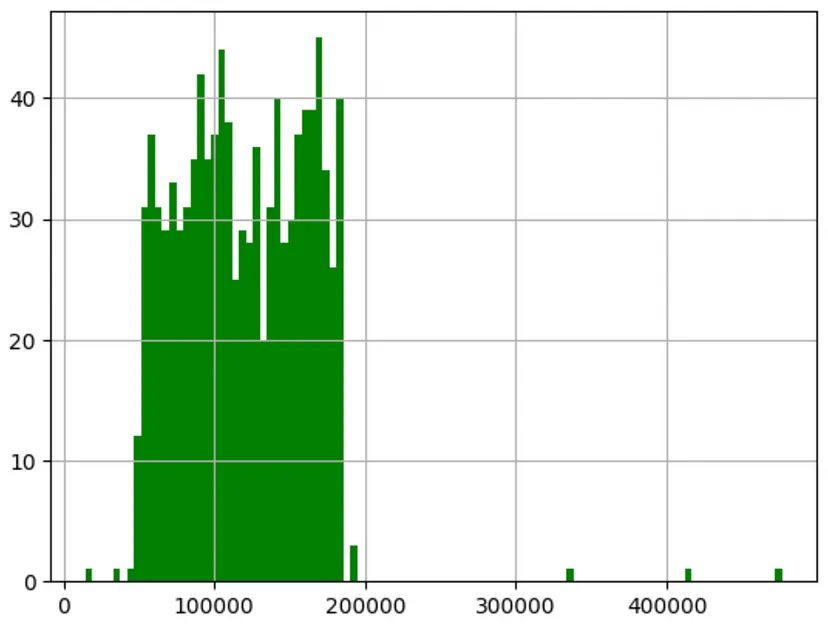
加载数据companies: DataFrame = pd.read_csv("companies.csv", header = 0)Nach dem Login kopieren 4、数据可视化了解数据对于确定要使用的特征、需要进行归一化和转换的特征、从数据中删除异常值以及对特定数据点进行的处理是很重要的。 目标(利润)直方图 可以直接使用DataFrame绘制直方图(Pandas使用Matplotlib来绘制数据帧),可以直接访问利润并绘制它。 companies['Profit'].hist( color='g', bins=100); Nach dem Login kopieren
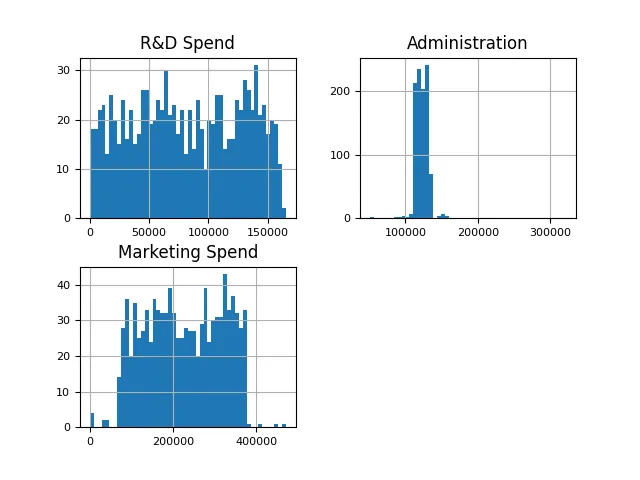
从数据中可以清楚地看出,利润超过20万美元的异常值非常罕见。这表明本文所涉及的数据代表的是规模较大的公司。鉴于异常值数量较少,可以将其保留 特征(支出)直方图在这里,本文旨在使用特征的直方图,并观察其分布情况。Y轴表示数字频率,X轴表示支出 companies[["R&D Spend", "行政管理", "Marketing Spend"]].hist(figsize=(16, 20), bins=50, xlabelsize=8, ylabelsize=8) Nach dem Login kopieren
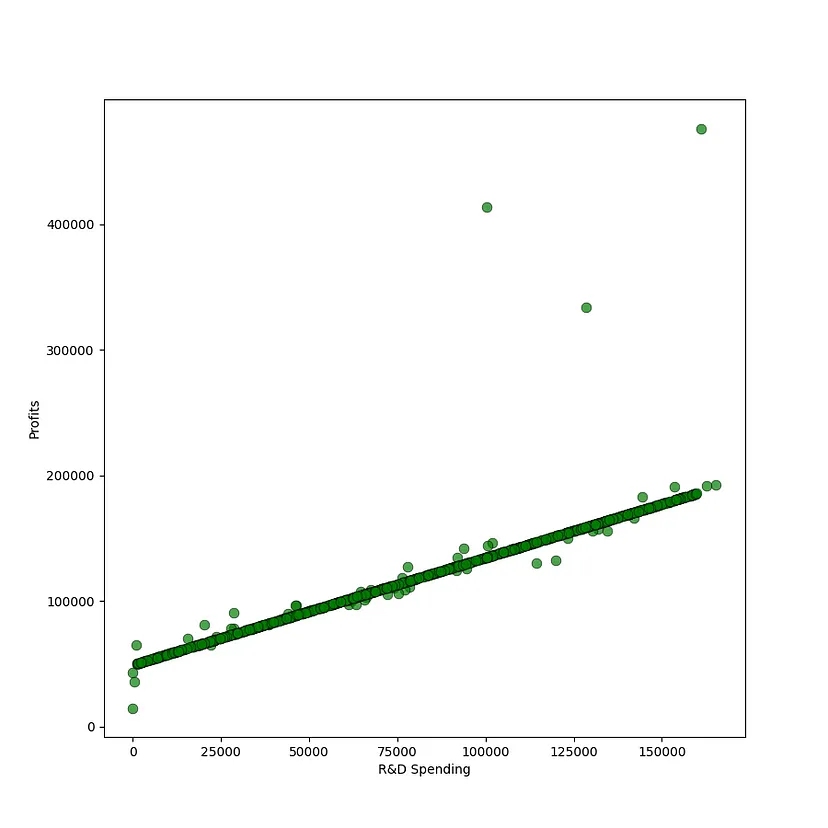
可以观察到一个健康的分布,只有很少的异常值。根据直觉,可以预期投入更多资金在研发和市场营销上的公司会获得更高的利润。从下面的散点图中可以看出,研发支出和利润之间存在明显的相关性 profits: DataFrame = companies[["Profit"]]research_and_development_spending: DataFrame = companies[["R&D Spend"]]figure, ax = plt.subplots(figsize = (9, 9))plt.xlabel("R&D Spending")plt.ylabel("Profits")ax.scatter(research_and_development_spending, profits, s=60, alpha=0.7, edgecolors="k",color='g',linewidths=0.5)Nach dem Login kopieren
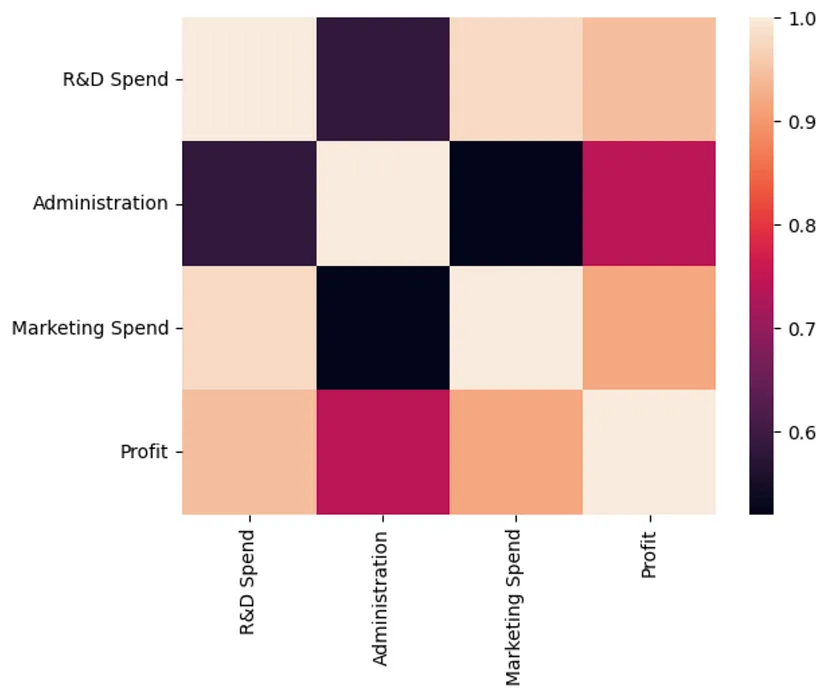
可以使用相关的热图来进一步探索支出和利润之间的关系。从图中可以观察到研发和市场营销支出与利润之间的相关性比行政支出更高 sns.heatmap(companies.corr()) Nach dem Login kopieren
5、模型训练首先需要将数据集分割为训练集和测试集两部分。Sklearn提供了一个辅助方法来完成这个任务。鉴于本文的数据集很简单且足够小,可以按照以下方式将特征和目标分离开来。 数据集features: DataFrame = companies[["R&D Spend", "行政管理", "Marketing Spend",]]targets: DataFrame = companies[["Profit"]]train_features, test_features, train_targets, test_targets = train_test_split(features, targets,test_size=0.2) Nach dem Login kopieren 大多数数据科学家会使用不同的命名约定,如X_train、y_train或其他类似的变体。
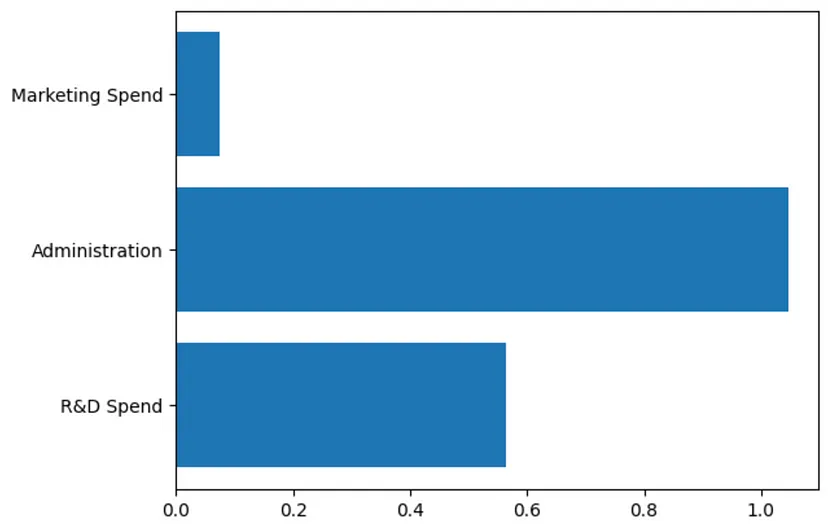
现在可以创建并训练模型了。Sklearn使事情变得非常简单。 model: LinearRegression = LinearRegression()model.fit(train_features, train_targets) Nach dem Login kopieren 6、模型评估本文希望对模型的性能及其可用性进行评估。首先查看一下计算得到的系数。在机器学习中,系数是用来与每个特征相乘的学习到的权重或数值。期望看到每个特征都有一个学习系数。 coefficients = model.coef_"""We should see the following in our consoleCoefficients[[0.55664299 1.08398919 0.07529883]]""" Nach dem Login kopieren 正如上述所看到的,有3个系数,每个特征对应一个系数(“研发支出”、“行政支出”、“市场营销支出”)。还可以将其绘制成图表,以便更直观地了解每个系数。 plt.figure()plt.barh(train_features.columns, coefficients[0])plt.show() Nach dem Login kopieren
计算误差希望了解模型的误差率,我们将使用Sklearn的R2得分 test_predictions: List[float] = model.predict(test_features)root_squared_error: float = r2_score(test_targets, test_predictions)"""floatWe should see an ouput similar to this0.9781424529214315""" Nach dem Login kopieren 离1越近,模型就越准确。实际上可以用一种非常简单的方式对这一点进行测试。 使用下面的支出模型来预测利润,并希望得到一个接近192261美元的数字,可以提取数据集的第一行 "R&D Spend" |"行政管理" |"Marketing Spend" | "Profit"需要进行重写的内容是:165349.2 136897.8需要重写的内容是:471784.1需要改写的内容是:192261.83 Nach dem Login kopieren 接下来创建一个推理请求。 inference_request: DataFrame = pd.DataFrame([{"R&D Spend":需要进行重写的内容是:165349.2, "行政管理":136897.8, "Marketing Spend":需要重写的内容是:471784.1 }])Nach dem Login kopieren 运行模型。 inference: float = model.predict(inference_request)"""We should get a number that is around199739.88721901""" Nach dem Login kopieren 现在可以看到的误差率是abs(199739-192261)/192261=0.0388。这是非常准确的。 7、结论处理数据、搭建模型和分析数据有很多方法。没有一种解决方案适用于所有情况,当用机器学习解决业务问题时,其中一个关键过程是搭建多个旨在解决同一个问题的模型,并选择最有前途的模型 |
Das obige ist der detaillierte Inhalt vonEine Gewinnvorhersage ist nicht mehr schwierig. Mit der linearen Regressionsmethode von Scikit-Learn können Sie mit halbem Aufwand das Doppelte des Ergebnisses erzielen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google Deepmind: Eine revolutionäre KI für die Wettervorhersage Die Wettervorhersage wurde einer dramatischen Transformation unterzogen, die sich von rudimentären Beobachtungen zu ausgefeilten AI-angetriebenen Vorhersagen überschreitet. Google DeepMinds Gencast, ein Bodenbrei
 Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Der Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)
 O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
Openais O1: Ein 12-tägiger Geschenkbummel beginnt mit ihrem bisher mächtigsten Modell Die Ankunft im Dezember bringt eine globale Verlangsamung, Schneeflocken in einigen Teilen der Welt, aber Openai fängt gerade erst an. Sam Altman und sein Team starten ein 12-tägiges Geschenk Ex
 So verwenden Sie Mistral OCR für Ihr nächstes Lappenmodell
Mar 21, 2025 am 11:11 AM
So verwenden Sie Mistral OCR für Ihr nächstes Lappenmodell
Mar 21, 2025 am 11:11 AM
Mistral OCR: revolutionäre retrieval-ausgereifte Generation mit multimodalem Dokumentverständnis RAG-Systeme (Abrufen-Augment-Augmented Generation) haben erheblich fortschrittliche KI
