
 Technologie-Peripheriegeräte
KI
NeRF und die Vergangenheit und Gegenwart des autonomen Fahrens, eine Zusammenfassung von fast 10 Artikeln!
Technologie-Peripheriegeräte
KI
NeRF und die Vergangenheit und Gegenwart des autonomen Fahrens, eine Zusammenfassung von fast 10 Artikeln!
NeRF und die Vergangenheit und Gegenwart des autonomen Fahrens, eine Zusammenfassung von fast 10 Artikeln!

Seit Neural Radiance Fields im Jahr 2020 vorgeschlagen wurde, hat die Anzahl verwandter Arbeiten exponentiell zugenommen. Es hat sich nicht nur zu einem wichtigen Zweig der dreidimensionalen Rekonstruktion entwickelt, sondern ist auch nach und nach als wichtiges Werkzeug für die autonome Forschung aktiv geworden Fahren.
NeRF ist in den letzten zwei Jahren plötzlich aufgetaucht, hauptsächlich weil es die Merkmalspunktextraktion und -anpassung, die epipolare Geometrie und Triangulation, PnP plus Bündelanpassung und andere Schritte der traditionellen CV-Rekonstruktionspipeline überspringt und sogar die Netzrekonstruktion, Kartierung usw. überspringt Erlernen Sie ein Strahlungsfeld direkt aus einem 2D-Eingabebild und geben Sie dann ein gerendertes Bild aus dem Strahlungsfeld aus, das einem echten Foto nahekommt. Mit anderen Worten: Lassen Sie ein implizites 3D-Modell, das auf einem neuronalen Netzwerk basiert, das 2D-Bild aus einer bestimmten Perspektive anpassen und sorgen Sie dafür, dass es sowohl über neue Perspektivensynthese als auch über neue Fähigkeiten verfügt. Die Entwicklung von NeRF steht auch in engem Zusammenhang mit dem autonomen Fahren, was sich insbesondere in der Anwendung realer Szenenrekonstruktionen und autonomer Fahrsimulatoren widerspiegelt. NeRF eignet sich gut zum Rendern von Bildern auf Fotoebene, sodass mit NeRF modellierte Straßenszenen äußerst realistische Trainingsdaten für autonomes Fahren liefern können. NeRF-Karten können bearbeitet werden, um Gebäude, Fahrzeuge und Fußgänger in verschiedenen Ecken zu kombinieren, die in der Realität schwer zu erfassen sind. case kann verwendet werden, um die Leistung von Algorithmen wie Wahrnehmung, Planung und Hindernisvermeidung zu testen. Daher ist NeRF ein Zweig der 3D-Rekonstruktion und ein Modellierungswerkzeug. Die Beherrschung von NeRF ist zu einer unverzichtbaren Fähigkeit für Forscher geworden, die Rekonstruktionen oder autonomes Fahren durchführen.
Heute werde ich die Inhalte rund um Nerf und autonomes Fahren klären.
1 Die Pionierarbeit von Nerf
Die Neufassung Inhalt ist: NeRF: Neural Radiation Field Representation of Scenes for View Synthesis. Im ersten Artikel von ECCV2020
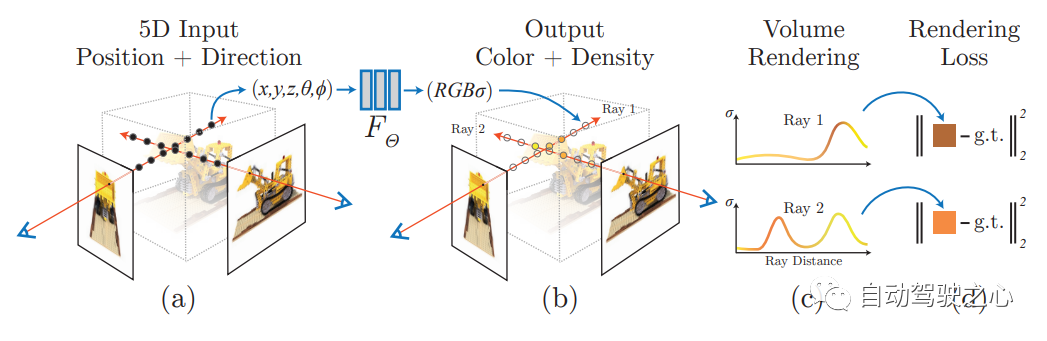
wird eine Nerf-Methode vorgeschlagen, die einen spärlichen Eingabeansichtssatz verwendet, um die zugrunde liegende Szenenfunktion mit kontinuierlichem Volumen zu optimieren und die neuesten Ansichtsergebnisse für die Synthese komplexer Szenen zu erzielen. Dieser Algorithmus verwendet ein vollständig verbundenes (nicht faltendes) tiefes Netzwerk zur Darstellung der Szene. Die Eingabe ist eine einzelne kontinuierliche 5D-Koordinate (einschließlich räumlicher Position (x, y, z) und Blickrichtung (θ, ξ)) und die Ausgabe ist die räumliche Position der Volumendichte und der ansichtsbezogenen Emissionsstrahlung.
NERF verwendet 2D-gestellte Bilder als Überwachung. Es ist nicht erforderlich, das Bild zu falten. Stattdessen lernt es eine Reihe impliziter Parameter durch kontinuierliches Erlernen der Positionskodierung und Verwendung der Bildfarbe als Aufsicht, Darstellung komplexer 3D-Szenen. Durch implizite Darstellung kann das Rendern aus jeder Perspektive abgeschlossen werden.
2.Mip-NeRF 360
Der Forschungsinhalt von CVPR2020 befasst sich mit grenzenlosen Außenszenen. Darunter ist Mip-NeRF 360: Boundless Anti-Aliasing Neural Radiation Field eine der Forschungsrichtungen im Objekt und in kleinen begrenzten Raumbereichen, aber in „grenzenlosen“ Szenen, in denen die Kamera in jede Richtung gerichtet werden kann und der Inhalt in jeder Entfernung vorhanden sein kann, sind sie jedoch schwierig zu erreichen. In diesem Fall erzeugen vorhandene NeRF-ähnliche Modelle häufig unscharfe oder niedrig aufgelöste Darstellungen (aufgrund unausgeglichener Details und Skalierung von nahen und entfernten Objekten), sind langsamer zu trainieren und leiden möglicherweise unter einer schlechten Rekonstruktion aus einer Reihe kleiner Bilder erscheinen aufgrund der inhärenten Mehrdeutigkeit der Aufgabe in großen Szenen. In diesem Artikel wird eine Erweiterung von mip-NeRF vorgeschlagen, einer NeRF-Variante, die Sampling- und Aliasing-Probleme löst und nichtlineare Szenenparametrisierung, Online-Destillation und einen neuen verzerrungsbasierten Regularisierer verwendet, um die Probleme zu überwinden, die durch unbegrenzte Szenenherausforderungen entstehen. Es erreicht eine Reduzierung des mittleren quadratischen Fehlers um 57 % im Vergleich zu mip-NeRF und ist in der Lage, realistische synthetische Ansichten und detaillierte Tiefenkarten für hochkomplexe, grenzenlose reale Szenen zu generieren.

3.Instant-NGP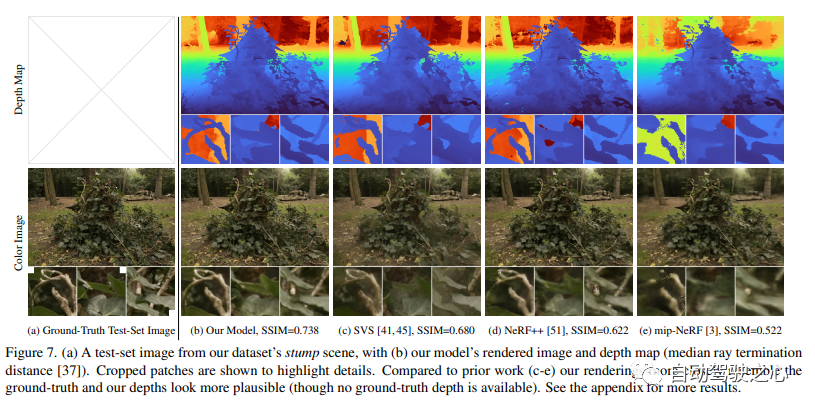
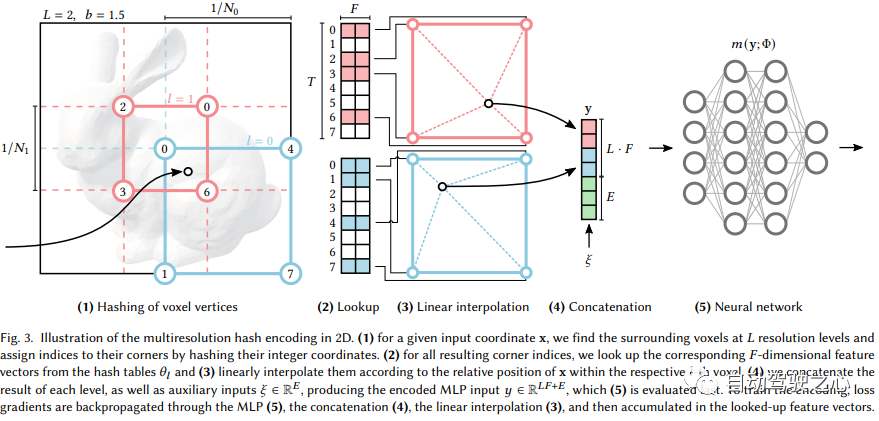
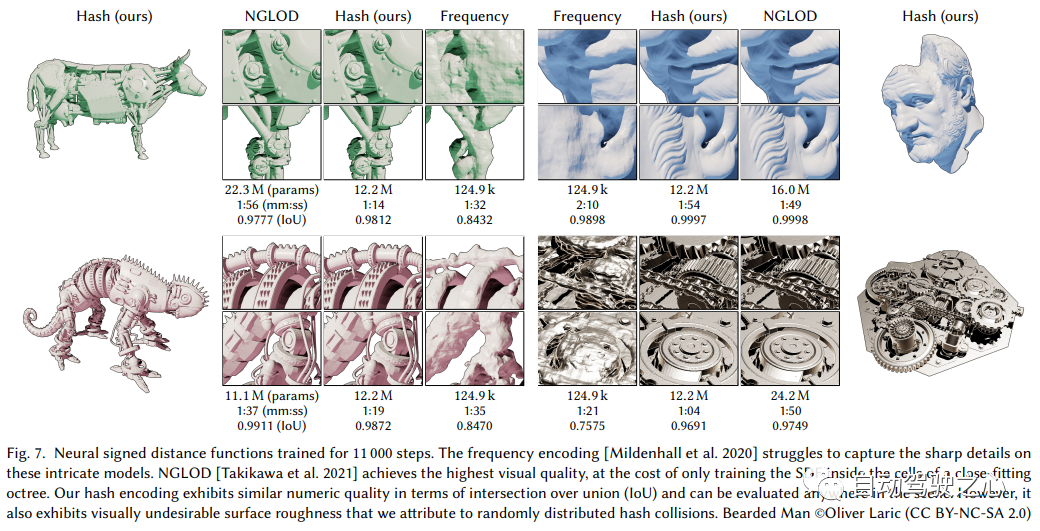
Der Inhalt, der neu geschrieben werden muss, ist: „Hybrider Szenenausdruck von expliziten Voxeln plus impliziten Funktionen (SIGGRAPH 2022)“ Verwendung von Hash-Codierung mit mehreren Auflösungen Instant Neurographic Primitive
muss neu geschrieben werden: Link: https://nvlabs.github.io/instant-ngp
Werfen wir zunächst einen Blick auf die Ähnlichkeiten und Unterschiede zwischen Instant-NGP und NeRF:
- Auch basierend auf Volumen-Rendering
- Anders als NeRFs MLP verwendet NGP ein spärlich parametrisiertes Voxelgitter als Szenenausdruck.
- Basierend auf Farbverläufen optimiert es gleichzeitig die Szene und MLP (ein MLP wird als Decoder verwendet). .
Es ist ersichtlich, dass der große Rahmen immer noch derselbe ist. Der wichtigste Unterschied besteht darin, dass NGP das parametrisierte Voxelgitter als Szenenausdruck ausgewählt hat. Durch Lernen werden die im Voxel gespeicherten Parameter zur Form der Szenendichte. Das größte Problem bei MLP ist, dass es langsam ist. Um die Szene mit hoher Qualität zu rekonstruieren, ist oft ein relativ großes Netzwerk erforderlich, und es wird viel Zeit in Anspruch nehmen, das Netzwerk für jeden Abtastpunkt zu durchlaufen. Die Interpolation innerhalb des Rasters ist viel schneller. Wenn das Raster jedoch hochpräzise Szenen ausdrücken möchte, sind Voxel mit hoher Dichte erforderlich, was zu einem extrem hohen Speicherverbrauch führt. Angesichts der Tatsache, dass es in der Szene viele leere Stellen gibt, hat NVIDIA eine spärliche Struktur vorgeschlagen, um die Szene auszudrücken. F2-NeRF
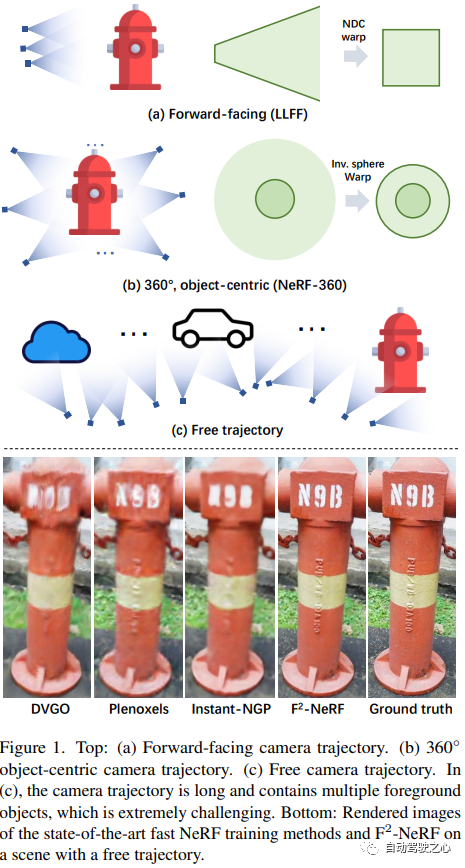
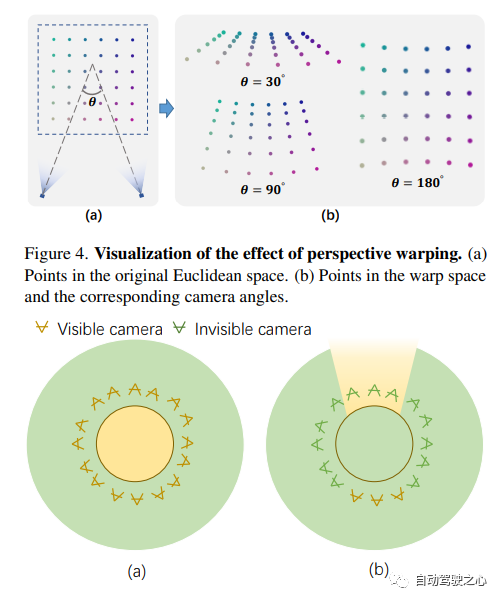
 F2-NeRF: Schnelles Neural Radiance Field Training mit kostenlosen Kameratrajektorien
F2-NeRF: Schnelles Neural Radiance Field Training mit kostenlosen Kameratrajektorien
Link zum Papier: https://totoro97.github.io /projects/f2-nerf/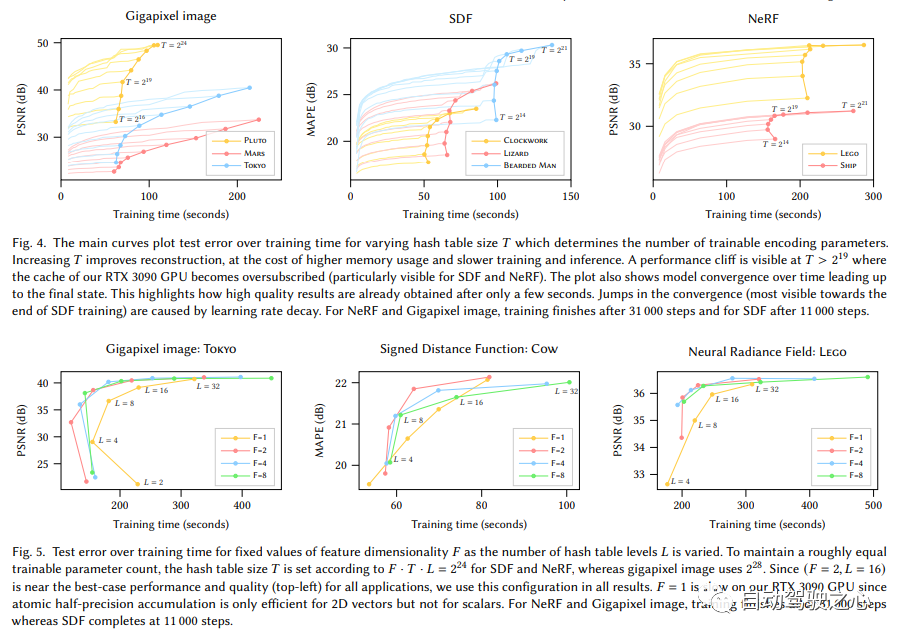

5.MobileNeRF
Echtzeit-Rendering-Anwendung auf der mobilen Seite, die die Funktion des Nerf-Exports von Mesh realisiert, und diese Technologie wurde von der CVPR2023-Konferenz übernommen!
MobileNeRF: Nutzung der Polygon-Rasterisierungspipeline für effizientes Rendern neuronaler Felder auf mobilen Architekturen.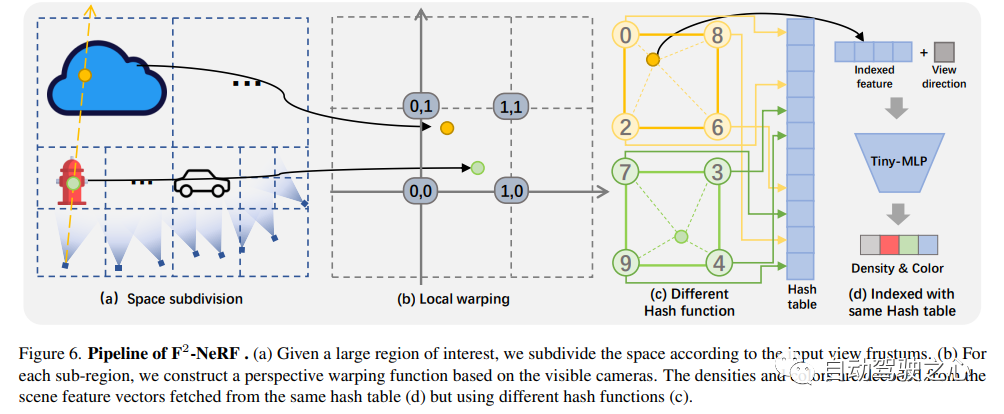
 Neural Radiation Field (NeRF) wurde bewiesen Die erstaunliche Fähigkeit, 3D-Szenenbilder aus neuartigen Ansichten zu synthetisieren. Sie stützen sich jedoch auf spezielle volumetrische Rendering-Algorithmen, die auf Ray Marching basieren und nicht mit den Fähigkeiten weit verbreiteter Grafikhardware mithalten können. In diesem Artikel wird eine neue texturierte, polygonbasierte NeRF-Darstellung vorgestellt, mit der neue Bilder über Standard-Rendering-Pipelines effizient synthetisiert werden können. NeRF wird als eine Reihe von Polygonen dargestellt, deren Textur binäre Opazität und Merkmalsvektoren darstellt. Beim herkömmlichen Rendern von Polygonen mithilfe eines Z-Puffers wird ein Bild erzeugt, in dem jedes Pixel Eigenschaften aufweist, die von einem kleinen ansichtsabhängigen MLP interpretiert werden, das im Fragment-Shader ausgeführt wird, um die endgültige Pixelfarbe zu erzeugen. Dieser Ansatz ermöglicht es NeRF, mithilfe einer herkömmlichen Polygon-Rasterisierungspipeline zu rendern, die eine massive Parallelität auf Pixelebene bietet und interaktive Bildraten auf einer Vielzahl von Computerplattformen, einschließlich Mobiltelefonen, ermöglicht.
Neural Radiation Field (NeRF) wurde bewiesen Die erstaunliche Fähigkeit, 3D-Szenenbilder aus neuartigen Ansichten zu synthetisieren. Sie stützen sich jedoch auf spezielle volumetrische Rendering-Algorithmen, die auf Ray Marching basieren und nicht mit den Fähigkeiten weit verbreiteter Grafikhardware mithalten können. In diesem Artikel wird eine neue texturierte, polygonbasierte NeRF-Darstellung vorgestellt, mit der neue Bilder über Standard-Rendering-Pipelines effizient synthetisiert werden können. NeRF wird als eine Reihe von Polygonen dargestellt, deren Textur binäre Opazität und Merkmalsvektoren darstellt. Beim herkömmlichen Rendern von Polygonen mithilfe eines Z-Puffers wird ein Bild erzeugt, in dem jedes Pixel Eigenschaften aufweist, die von einem kleinen ansichtsabhängigen MLP interpretiert werden, das im Fragment-Shader ausgeführt wird, um die endgültige Pixelfarbe zu erzeugen. Dieser Ansatz ermöglicht es NeRF, mithilfe einer herkömmlichen Polygon-Rasterisierungspipeline zu rendern, die eine massive Parallelität auf Pixelebene bietet und interaktive Bildraten auf einer Vielzahl von Computerplattformen, einschließlich Mobiltelefonen, ermöglicht.

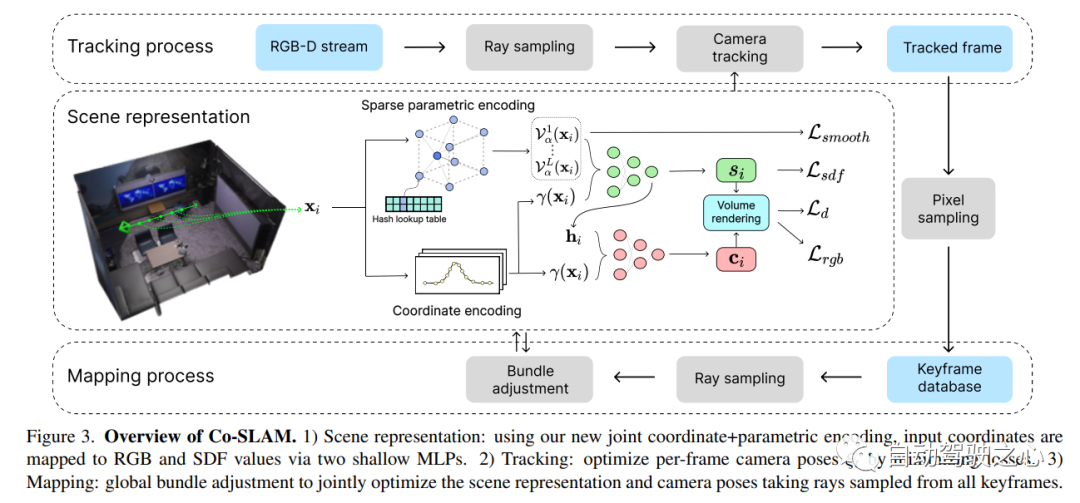
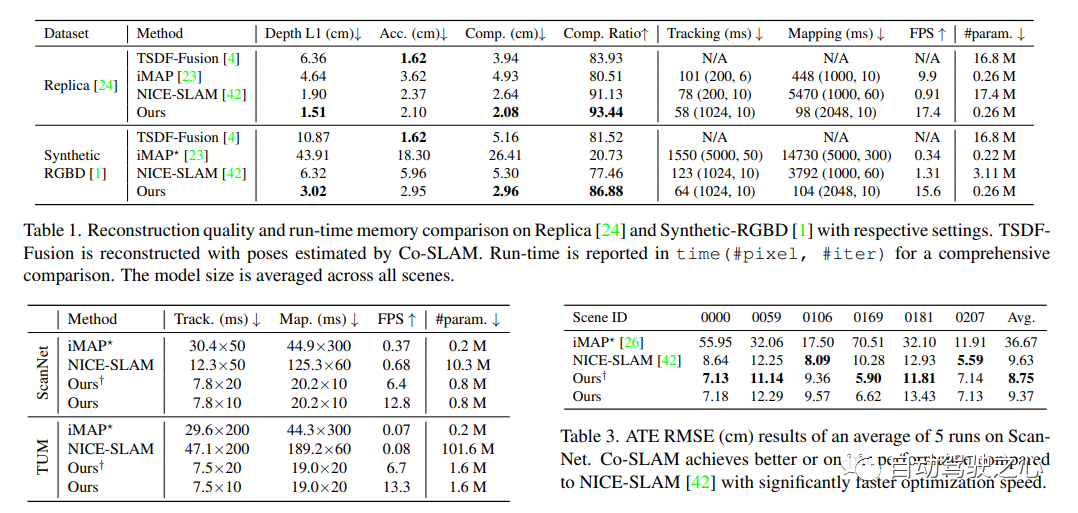
6.Co-SLAM
Unsere Arbeiten zur visuellen Echtzeitlokalisierung und NeRF-Kartierung wurden in CVPR2023 aufgenommen
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
Link zum Papier : https://arxiv.org/pdf/2304.14377.pdf
Co-SLAM ist ein Echtzeit-RGB-D-SLAM-System, das neuronale implizite Darstellungen für die Kameraverfolgung und die hochauflösende Oberflächenrekonstruktion verwendet. Co-SLAM stellt die Szene als Hash-Gitter mit mehreren Auflösungen dar, um seine Fähigkeit zur schnellen Konvergenz und Darstellung lokaler Merkmale zu nutzen. Darüber hinaus verwendet Co-SLAM zur Integration von Priorisierungen der Oberflächenkonsistenz eine Blockkodierungsmethode, die beweist, dass es die Szenenvervollständigung in unbeobachteten Bereichen wirkungsvoll abschließen kann. Unsere gemeinsame Kodierung vereint die Vorteile von Co-SLAMs Geschwindigkeit, High-Fidelity-Rekonstruktion und Oberflächenkonsistenz. Durch eine Ray-Sampling-Strategie ist Co-SLAM in der Lage, Anpassungen an allen Keyframes global zu bündeln.
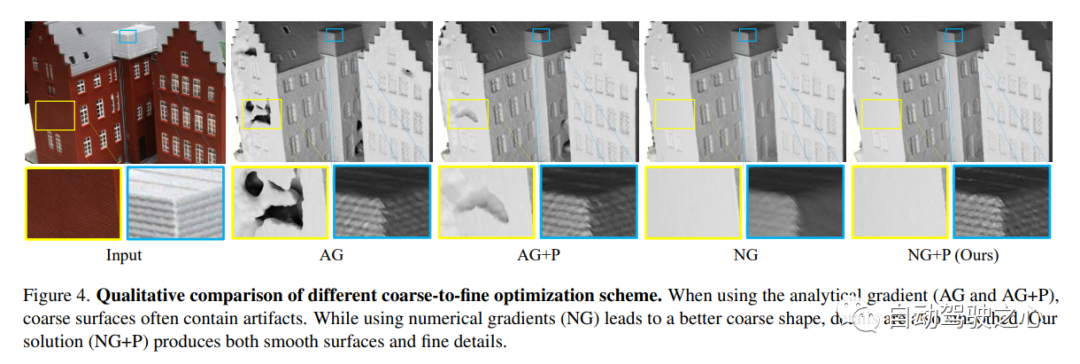
7.Neuralangelo
Die derzeit beste NeRF-Oberflächenrekonstruktionsmethode (CVPR2023)
Der neu geschriebene Inhalt ist wie folgt:
Es hat sich gezeigt, dass bildbasiertes neuronales Rendering in der Lage ist, neuronale Oberflächen zu rekonstruieren, um dichte 3D-Strukturen wiederherzustellen. Aktuelle Methoden haben jedoch immer noch Schwierigkeiten, die detaillierte Struktur realer Szenen wiederherzustellen. Um dieses Problem zu lösen, schlägt diese Studie eine Methode namens Neuralangelo vor, die die Darstellungsmöglichkeiten von 3D-Hash-Gittern mit mehreren Auflösungen mit neuronalem Oberflächenrendering kombiniert. Zwei Schlüsselelemente dieses Ansatzes sind:
(1) Numerische Gradienten zur Berechnung von Ableitungen höherer Ordnung als Glättungsoperationen und (2) Steuerung der Grob-zu-Fein-Optimierung auf Hash-Gittern auf verschiedenen Detailebenen.
Auch ohne Hilfseingaben wie Tiefe ist Neuralangelo immer noch in der Lage, dichte 3D-Oberflächenstrukturen aus Multi-View-Bildern effektiv wiederherzustellen. Die Wiedergabetreue ist im Vergleich zu früheren Methoden erheblich verbessert und ermöglicht eine detaillierte großflächige Szenenrekonstruktion aus der RGB-Videoaufnahme!
8.MARS
Das erste Open-Source-NeRF-Simulationstool für autonomes Fahren.
Was neu geschrieben werden muss, ist: https://arxiv.org/pdf/2307.15058.pdf
Selbstfahrende Autos können in normalen Situationen reibungslos fahren, und es ist allgemein anerkannt, dass realistische Sensorsimulationen bei der Lösung eine Rolle spielen werden Die übrigen Ecksituationen spielen eine Schlüsselrolle. Zu diesem Zweck schlägt MARS einen autonomen Fahrsimulator vor, der auf neuronalen Strahlungsfeldern basiert. Im Vergleich zu bestehenden Werken weist MARS drei Besonderheiten auf: (1) Instanzbewusstsein. Der Simulator modelliert Vordergrundinstanzen und Hintergrundumgebungen separat mithilfe separater Netzwerke, sodass die statischen (z. B. Größe und Erscheinungsbild) und dynamischen (z. B. Flugbahn) Eigenschaften der Instanzen separat gesteuert werden können. (2) Modularität. Der Simulator ermöglicht den flexiblen Wechsel zwischen verschiedenen modernen NeRF-bezogenen Backbones, Sampling-Strategien, Eingabemodi usw. Es besteht die Hoffnung, dass dieser modulare Aufbau den akademischen Fortschritt und den industriellen Einsatz von NeRF-basierten autonomen Fahrsimulationen fördern kann. (3) Echt. Der Simulator ist für modernste fotorealistische Ergebnisse bei optimaler Modulauswahl ausgelegt.
Der wichtigste Punkt ist: Open Source!
. Papierlink: https://arxiv.org/abs/2306.09117
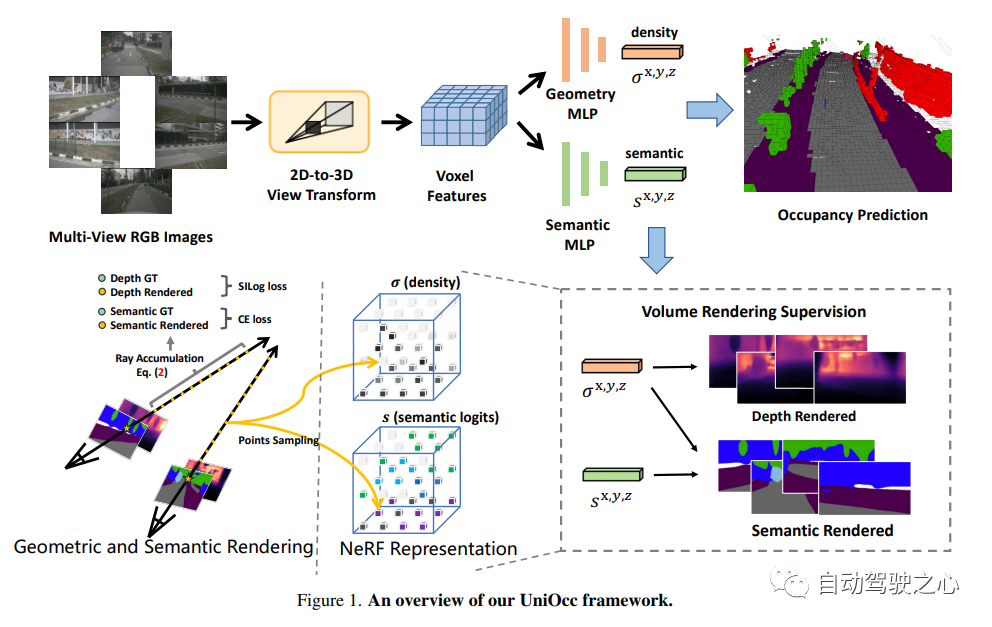
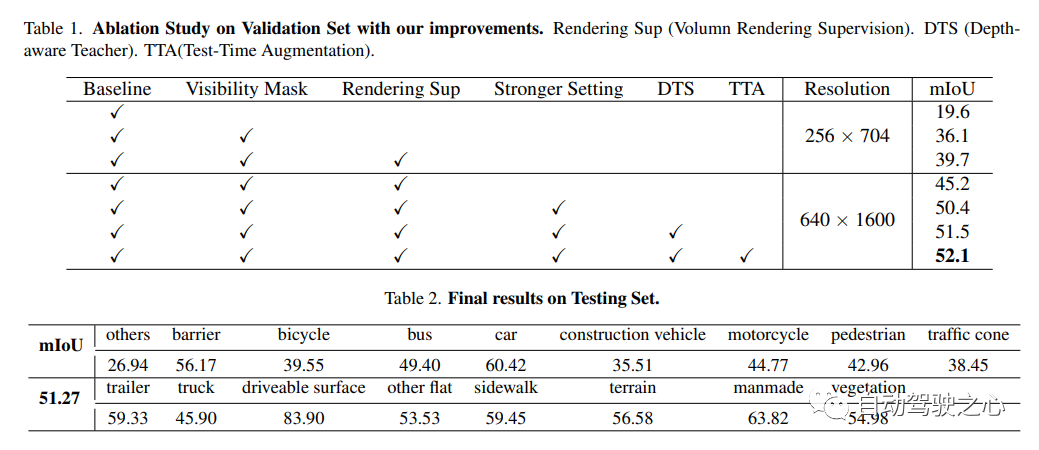
UniOCC ist eine visionsorientierte 3D-Belegungsvorhersagemethode. Herkömmliche Belegungsvorhersagemethoden verwenden hauptsächlich 3D-Belegungsetiketten, um die Projektionsmerkmale des 3D-Raums zu optimieren. Der Generierungsprozess dieser Etiketten ist jedoch komplex und teuer, basiert auf semantischen 3D-Anmerkungen, ist durch die Voxelauflösung begrenzt und kann keinen feinkörnigen Raum liefern . Semantik. Um dieses Problem anzugehen, schlägt dieses Papier eine neue Methode zur Vorhersage der einheitlichen Belegung (UniOcc) vor, die explizit räumliche geometrische Einschränkungen auferlegt und die feinkörnige semantische Überwachung durch Volumenstrahl-Rendering ergänzt. Dieser Ansatz verbessert die Modellleistung erheblich und zeigt das Potenzial zur Reduzierung der manuellen Annotationskosten. Angesichts der Komplexität der Kennzeichnung von 3D-Belegungen führen wir außerdem das Tiefenerkennungs-Lehrer-Schüler-Framework (DTS) ein, um unbeschriftete Daten zu nutzen und die Vorhersagegenauigkeit zu verbessern. Unsere Lösung erreichte einen mIoU-Wert von 51,27 % und belegte bei dieser Herausforderung den dritten Platz. Unisim. Hergestellt von Wowawawow, absolut ausgezeichnetes Produkt!
UniSim: Ein neuronaler Closed-Loop-Sensorsimulator
Link zum Papier: https://arxiv.org/pdf/2308.01898.pdf
Ein wichtiger Grund, der die Popularisierung des autonomen Fahrens behindert, ist die immer noch unzureichende Sicherheit. Die reale Welt ist zu komplex, insbesondere mit dem Long-Tail-Effekt. Grenzszenarien sind für sicheres Fahren von entscheidender Bedeutung und vielfältig, aber schwer zu erkennen. Es ist sehr schwierig, die Leistung autonomer Fahrsysteme in diesen Szenarien zu testen, da diese Szenarien schwer zu erfüllen sind und Tests in der realen Welt sehr teuer und gefährlich sind
Um diese Herausforderung zu lösen, haben sowohl die Industrie als auch die Wissenschaft begonnen, darauf zu achten zur Entwicklung von Simulationssystemen. Zu Beginn konzentrierte sich das Simulationssystem hauptsächlich darauf, das Bewegungsverhalten anderer Fahrzeuge/Fußgänger zu simulieren und die Genauigkeit des autonomen Fahrplanungsmoduls zu testen. In den letzten Jahren hat sich der Schwerpunkt der Forschung schrittweise auf die Simulation auf Sensorebene verlagert, d .
Im Gegensatz zu früheren Arbeiten hat UniSim gleichzeitig zum ersten Mal Folgendes erreicht:
Hoher Realismus:
Kann die reale Welt (Bilder und LiDAR) genau simulieren und die Domänenlücke verringern
Closed-Loop-Test (geschlossen -Loop-Simulation):
Kann seltene gefährliche Szenen erzeugen, um unbemannte Fahrzeuge zu testen, und unbemannte Fahrzeuge frei mit der Umgebung interagieren lassen
Skalierbar (skalierbar):
Kann leicht auf mehr erweitert werden. Für viele Szenarien, Sie Es müssen nur einmal Daten gesammelt werden, um die Messung zu rekonstruieren und zu simulieren Autonome Fahrszenen, einschließlich Autos, Fußgänger, Straßen, Gebäude und Verkehrszeichen. Steuern Sie dann die rekonstruierte Szene zur - Simulation, um einige seltene Schlüsselszenen zu generieren. Closed-Loop-Simulation
-
UniSim kann Closed-Loop-Simulationstests durchführen. Erstens kann UniSim durch die Steuerung des Verhaltens des Autos eine gefährliche und seltene Szene erzeugen, wie zum Beispiel ein Auto, das plötzlich auf der aktuellen Spur entgegenkommt. Anschließend führt UniSim eine Simulation durch, um entsprechende Daten zu generieren, und gibt die Ergebnisse der Pfadplanung aus. Das unbemannte Fahrzeug bewegt sich zum nächsten festgelegten Ort und aktualisiert die Szene (andere Fahrzeuge) positionieren), dann simulieren wir weiter, führen das autonome Fahrsystem aus und aktualisieren den Zustand der virtuellen Welt ... Durch diesen Closed-Loop-Test können das autonome Fahrsystem und die Simulationsumgebung interagieren, um eine Szene zu erstellen völlig anders als die Originaldaten
-






Das obige ist der detaillierte Inhalt vonNeRF und die Vergangenheit und Gegenwart des autonomen Fahrens, eine Zusammenfassung von fast 10 Artikeln!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
