

Die Entwicklung der künstlichen Intelligenz schreitet rasant voran, dennoch treten häufig Probleme auf. Die neue GPT-Vision-API von OpenAI ist im Front-End erstaunlich, aber aufgrund von Halluzinationsproblemen ist es auch schwer, sich über das Back-End zu beschweren.
Illusion war schon immer der fatale Fehler großer Modelle. Aufgrund der Komplexität des Datensatzes ist es unvermeidlich, dass veraltete und fehlerhafte Informationen vorhanden sind, was die Ausgabequalität vor große Herausforderungen stellt. Zu viele wiederholte Informationen können auch große Modelle verzerren, was ebenfalls eine Art Illusion ist. Aber Halluzinationen sind keine unbeantwortbaren Aussagen. Während des Entwicklungsprozesses können die sorgfältige Verwendung von Datensätzen, strikte Filterung, die Erstellung hochwertiger Datensätze sowie die Optimierung der Modellstruktur und Trainingsmethoden das Halluzinationsproblem bis zu einem gewissen Grad lindern.
Es gibt so viele beliebte Großmodelle, wie wirksam sind sie bei der Linderung von Halluzinationen? Hier ist ein Ranking, das ihre Unterschiede klar vergleicht
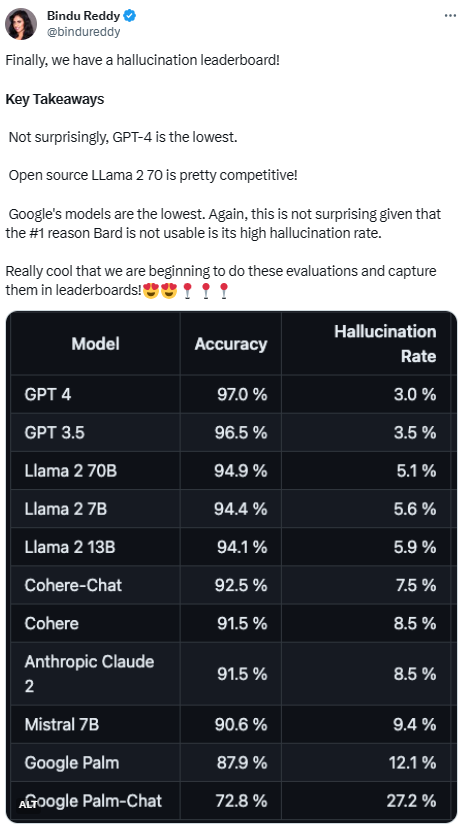
Vectara-Plattform hat dieses Ranking veröffentlicht, das sich auf künstliche Intelligenz konzentriert. Das Aktualisierungsdatum des Rankings ist der 1. November 2023. Vectara gab an, dass sie die Halluzinationsbewertung weiterhin verfolgen werden, um das Ranking zu aktualisieren, sobald das Modell aktualisiert wird
Projektadresse: https://github.com /vectara /hallucination-leaderboard
Um diese Bestenliste zu ermitteln, führte Vectara eine Faktenkonsistenzstudie durch und trainierte ein Modell zur Erkennung von Halluzinationen in der LLM-Ausgabe. Sie verwendeten ein vergleichbares SOTA-Modell und stellten jedem LLM 1.000 kurze Dokumente über eine öffentliche API zur Verfügung und forderten sie auf, jedes Dokument zusammenzufassen und dabei nur die im Dokument dargelegten Fakten zu verwenden. Von diesen 1000 Dokumenten wurden von jedem Modell nur 831 Dokumente zusammengefasst, und die restlichen Dokumente wurden von mindestens einem Modell aufgrund von Inhaltsbeschränkungen abgelehnt. Anhand dieser 831 Dokumente berechnete Vectara die Gesamtgenauigkeit und Illusionsrate für jedes Modell. Die Häufigkeit, mit der sich jedes Modell weigert, auf Eingabeaufforderungen zu antworten, wird in der Spalte „Antwortrate“ detailliert beschrieben. Keiner der an das Modell gesendeten Inhalte enthält illegale oder unsichere Inhalte, enthält jedoch genügend Auslösewörter, um bestimmte Inhaltsfilter auszulösen. Diese Dokumente stammen hauptsächlich aus dem Korpus von CNN/Daily Mail
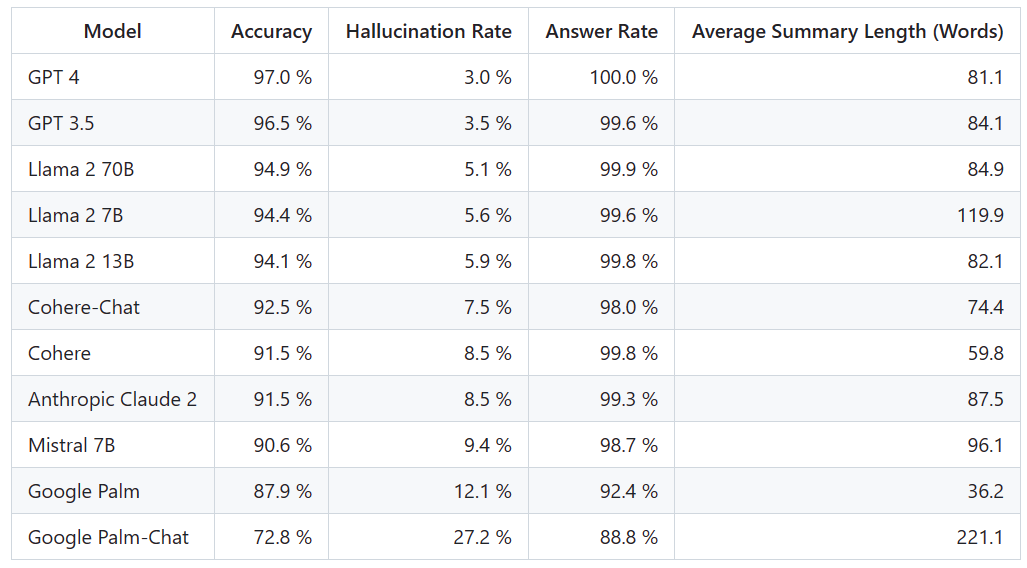
Es ist wichtig zu beachten, dass Vectara die Genauigkeit der Zusammenfassung und nicht die allgemeine sachliche Genauigkeit bewertet. Dies ermöglicht einen Vergleich der Reaktion des Modells auf die bereitgestellten Informationen. Mit anderen Worten: Bewertet wird, ob die Ausgabezusammenfassung „sachlich konsistent“ mit dem Quelldokument ist. Ohne zu wissen, auf welchen Daten jedes LLM trainiert wurde, ist es unmöglich, die Halluzination für ein bestimmtes Problem zu bestimmen. Darüber hinaus würde der Aufbau eines Modells, das ohne Referenzquelle bestimmen kann, ob eine Reaktion eine Halluzination ist, die Auseinandersetzung mit dem Halluzinationsproblem und das Training eines Modells erfordern, das genauso groß oder größer als das zu bewertende LLM ist. Daher hat sich Vectara dafür entschieden, bei der Zusammenfassungsaufgabe die Halluzinationsraten zu betrachten, da eine solche Analogie eine gute Möglichkeit ist, den Gesamtrealismus des Modells zu bestimmen.
Die Erkennungsadresse des Halluzinationsmodells lautet: https://huggingface.co/vectara/hallucination_evaluation_model
Darüber hinaus werden in der RAG-Pipeline (Retrieval Augmented Generation) immer mehr LLMs verwendet, um Benutzeranfragen zu beantworten wie Bing Chat und Google Chat-Integration. Im RAG-System wird das Modell als Aggregator von Suchergebnissen eingesetzt, daher ist diese Bestenliste auch ein guter Indikator für die Genauigkeit des Modells bei Verwendung im RAG-System
Angesichts der guten Leistung von GPT-4, seine Illusion Die niedrigste Rate scheint nicht überraschend. Einige Internetnutzer sagten jedoch, dass sie überrascht seien, dass es keinen großen Unterschied zwischen GPT-3.5 und GPT-4 gebe. Allerdings war die Leistung des großen Google-Modells unbefriedigend. Einige Internetnutzer sagten, dass Googles BARD oft „Ich trainiere noch“ verwendet, um falsche Antworten zu vermeiden. Mit einer solchen Rangliste können wir die Vor- und Nachteile verschiedener Modelle intuitiver verstehen . Vor ein paar Tagen hat
OpenAI GPT-4 Turbo eingeführt
Nein, einige Internetnutzer haben sofort vorgeschlagen, es in der Rangliste zu aktualisieren.

Wir werden abwarten, wie das nächste Ranking aussehen wird und ob es größere Änderungen geben wird.
Das obige ist der detaillierte Inhalt vonRanking der Halluzinationsraten großer Modelle: GPT-4 ist mit 3 % am niedrigsten und Google Palm liegt sogar bei 27,2 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist eine .Xauthority-Datei?
Was ist eine .Xauthority-Datei?
 Was ist das Dateiformat von mkv?
Was ist das Dateiformat von mkv?
 Mein Computer kann es nicht durch Doppelklick öffnen.
Mein Computer kann es nicht durch Doppelklick öffnen.
 Einführung in die Gründe, warum der Remote-Desktop keine Verbindung herstellen kann
Einführung in die Gründe, warum der Remote-Desktop keine Verbindung herstellen kann
 So führen Sie Python in vscode aus
So führen Sie Python in vscode aus
 So lösen Sie devc-chinesische verstümmelte Zeichen
So lösen Sie devc-chinesische verstümmelte Zeichen
 Vergleichen Sie die Ähnlichkeiten und Unterschiede zwischen zwei Datenspalten in Excel
Vergleichen Sie die Ähnlichkeiten und Unterschiede zwischen zwei Datenspalten in Excel
 Der Unterschied zwischen Heap und Stack
Der Unterschied zwischen Heap und Stack








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



