
 Technologie-Peripheriegeräte
KI
Das große Modell von Kai-Fu Lee, das auf LLaMA basiert, aber den Tensornamen geändert hat, sorgte für Kontroversen, und die offizielle Antwort ist hier
Technologie-Peripheriegeräte
KI
Das große Modell von Kai-Fu Lee, das auf LLaMA basiert, aber den Tensornamen geändert hat, sorgte für Kontroversen, und die offizielle Antwort ist hier
Das große Modell von Kai-Fu Lee, das auf LLaMA basiert, aber den Tensornamen geändert hat, sorgte für Kontroversen, und die offizielle Antwort ist hier

Vor einiger Zeit wurde im Bereich der Open-Source-Großmodelle ein neues Modell eingeführt: „Yi“ mit einer Kontextfenstergröße von mehr als 200 KB, das 400.000 chinesische Schriftzeichen gleichzeitig verarbeiten kann.
Vorsitzender und CEO von Sinovation Ventures Kai-fu Lee gründete das große Modellunternehmen „Zero One Everything“ und baute dieses große Modell, das zwei Versionen von Yi-6B und Yi-34B umfasst
Laut Hugging Face Yi-34B, eine englische Open-Source-Community-Plattform und eine chinesische C-Eval-Bewertungsliste, erhielt bei seiner Einführung eine Reihe internationaler SOTA-Auszeichnungen für die besten Leistungsindikatoren und wurde zum „Doppelchampion“ globaler Open-Source-Großmodelle und besiegte Open-Source-Konkurrenzprodukte wie z wie LLaMA2 und Falcon.
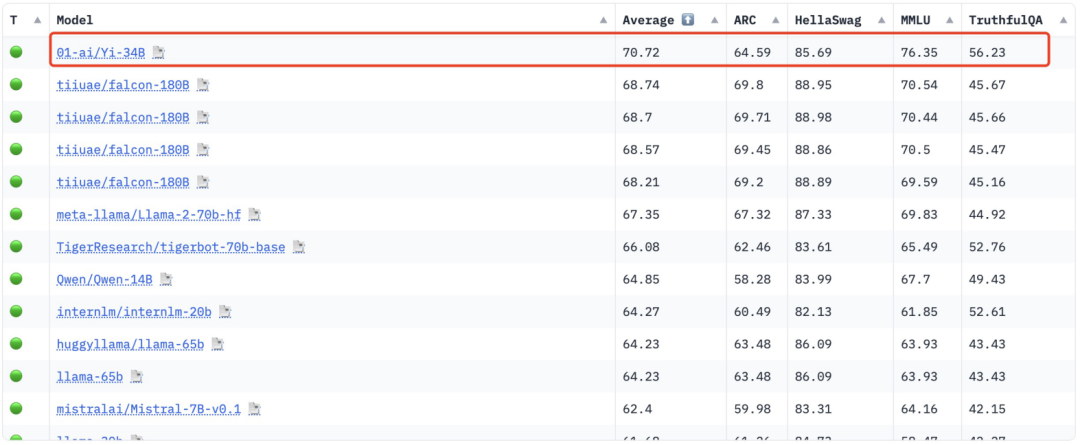
Yi-34B war zu dieser Zeit auch das einzige inländische Modell, das die globale Open-Source-Modell-Rangliste von Hugging Face erfolgreich anführte, und wurde als „das stärkste Open-Source-Modell der Welt“ bezeichnet.
Nach seiner Veröffentlichung erregte dieses Modell die Aufmerksamkeit vieler in- und ausländischer Forscher und Entwickler
Aber kürzlich entdeckten einige Forscher, dass das Yi-34B-Modell im Wesentlichen die LLaMA-Architektur verwendet, aber gerade in „Zwei Tensoren“ umbenannt wurde.
Bitte klicken Sie auf diesen Link, um den Originalbeitrag anzuzeigen: https://news.ycombinator.com/item?id=38258015
Der Beitrag erwähnte auch:
Der Code von Yi-34B Tatsächlich handelt es sich um eine Umgestaltung des LLaMA-Codes, die jedoch offenbar keine wesentlichen Änderungen vorgenommen hat. Dieses Modell ist offensichtlich eine Bearbeitung, die auf der ursprünglichen LLaMA-Datei der Apache-Version 2.0 basiert, aber LLaMA wird nicht erwähnt:

Yi vs. LLaMA-Codevergleich. Code-Link: https://www.diffchecker.com/bJTqkvmQ/
Darüber hinaus werden diese Codeänderungen nicht über Pull Request an das Transformers-Projekt übermittelt, sondern im Mai in Form von externem Code angehängt ein Sicherheitsrisiko darstellen oder vom Framework nicht unterstützt werden. Die HuggingFace-Bestenliste wird dieses Modell nicht einmal mit einem Kontextfenster von bis zu 200 KB vergleichen, da es keine benutzerdefinierte Codestrategie hat.
Sie behaupten, dass es sich um ein 32K-Modell handelt, aber es ist als 4K-Modell konfiguriert, es gibt keine RoPE-Skalierungskonfiguration und es gibt keine Erklärung zur Skalierung (Hinweis: Zero One Thousand Things gab zuvor an, dass das Modell selbst ein 4K-Modell ist trainiert auf 4K-Sequenzen, kann aber in Inferenzphasen auf 32K erweitert werden). Derzeit gibt es keine Informationen über die Feinabstimmungsdaten. Sie lieferten auch keine Anweisungen zur Reproduktion ihrer Benchmarks, einschließlich der verdächtig hohen MMLU-Werte.
Wer schon länger auf dem Gebiet der künstlichen Intelligenz tätig ist, wird dafür nicht blind sein. Ist das falsche Werbung? Lizenzverstoß? War es tatsächlich ein Betrug beim Benchmark? Wen interessiert das? Wir könnten ein Papier ändern oder in diesem Fall das gesamte Risikokapital übernehmen. Zumindest liegt Yi über dem Standard, da es sich um ein Basismodell handelt und die Leistung wirklich gut ist
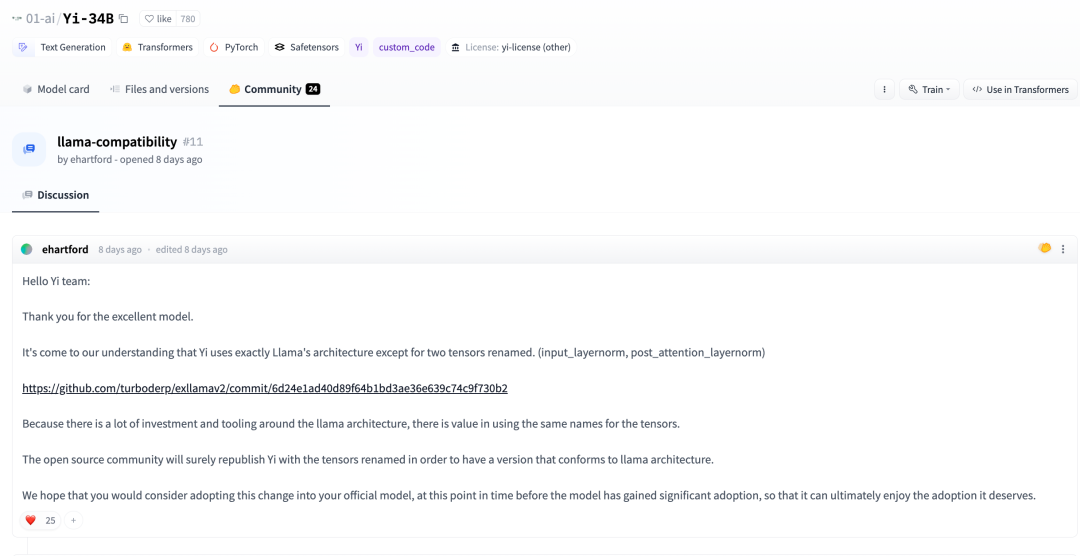
Vor ein paar Tagen hat ein Entwickler in der Huggingface-Community auch darauf hingewiesen:
Nach unserem Verständnis zusätzlich Zur Umbenennung der beiden Tensoren übernimmt Yi vollständig die LLaMA-Architektur. (input_layernorm, post_attention_layernorm)
In der Diskussion sagten einige Internetnutzer: Wenn sie die Architektur, Codebibliothek und andere zugehörige Ressourcen von Meta LLaMA korrekt nutzen möchten, müssen sie die von LLaMA festgelegte Lizenzvereinbarung einhalten

Um der Open-Source-Lizenz von LLaMA zu entsprechen, hat ein Entwickler beschlossen, seinen Namen wieder zu ändern und ihn erneut auf Huggingface zu veröffentlichen.
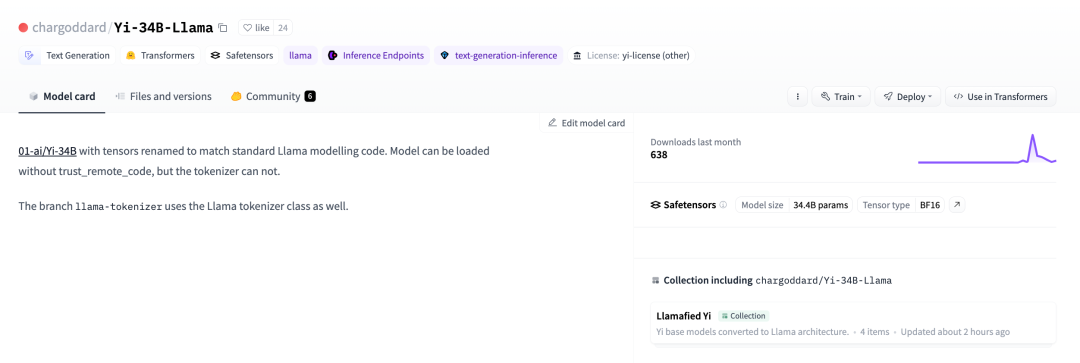 01-ai/Yi-34B, die Tensoren wurden umbenannt, um dem Standardmodell von LLaMA zu entsprechen Code. Verwandte Links: https://huggingface.co/chargoddard/Yi-34B-LLaMA
01-ai/Yi-34B, die Tensoren wurden umbenannt, um dem Standardmodell von LLaMA zu entsprechen Code. Verwandte Links: https://huggingface.co/chargoddard/Yi-34B-LLaMA
Aus der Lektüre dieses Inhalts können wir schließen, dass die Nachricht, dass Jia Yangqing Alibaba verlassen und ein Unternehmen gegründet hat, vor ein paar Tagen in seinem Freundeskreis erwähnt wurde

In dieser Angelegenheit auch das Herz der Maschine ausgedrückt: Null tausend Dinge wurden verifiziert. Lingyiwu antwortete:
GPT ist eine ausgereifte Architektur, die in der Branche anerkannt ist, und LLaMA hat eine Zusammenfassung zu GPT erstellt. Das strukturelle Design des großen Forschungs- und Entwicklungsmodells von Zero One Thousand Things basiert auf der ausgereiften Struktur von GPT und stützt sich auf erstklassige öffentliche Ergebnisse in der Branche. Gleichzeitig hat das Team von Zero One Thousand Things viel Arbeit geleistet zum Verständnis des Modells und zum Training. Dies ist das erste Mal, dass wir hervorragende Ergebnisse veröffentlicht haben. Gleichzeitig erforscht Zero One Thousand Things weiterhin wesentliche Durchbrüche auf der Ebene der Modellstruktur.
Der Modellaufbau ist nur ein Teil der Modellausbildung. Das Open-Source-Modell von Yi konzentriert sich auf andere Aspekte wie Datentechnik, Trainingsmethoden, Babysitting-Fähigkeiten (Überwachung des Trainingsprozesses), Hyperparametereinstellungen, Bewertungsmethoden, tiefes Verständnis der Natur von Bewertungsindikatoren und Tiefe der Forschung zu den Prinzipien von In die Funktionen zur Modellverallgemeinerung, die besten KI-Infrastrukturfunktionen usw. wurde viel Forschungs- und Entwicklungsaufwand investiert, und diese Aufgaben spielen oft eine größere Rolle und sind auch die Kerntechnologien von Zero Ein Wagen im großen Modellvorschulungsstadium.
Während der Durchführung einer großen Anzahl von Trainingsexperimenten haben wir den Code entsprechend den Anforderungen der experimentellen Ausführung umbenannt. Wir legen großen Wert auf das Feedback der Open-Source-Community und haben den Code aktualisiert, um ihn besser in das Transformer-Ökosystem zu integrieren.
Wir sind sehr dankbar für das Feedback der Community. Wir haben gerade erst in der Open-Source-Community angefangen und hoffen, dass wir arbeiten können mit allen, um eine erfolgreiche Community zu schaffen. Easy Open Source Wir werden unser Bestes tun, um weiterhin Fortschritte zu machen
Das obige ist der detaillierte Inhalt vonDas große Modell von Kai-Fu Lee, das auf LLaMA basiert, aber den Tensornamen geändert hat, sorgte für Kontroversen, und die offizielle Antwort ist hier. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
