

Extrahieren Sie die Tabelle mit Python aus dem Bild

Vor etwa einem Jahr wurde mir die Aufgabe übertragen, Daten aus Dateien zu extrahieren und zu strukturieren, hauptsächlich in Tabellen enthaltene Daten. Ich hatte keine Vorkenntnisse in Computer Vision und hatte Schwierigkeiten, eine geeignete „Plug-and-Play“-Lösung zu finden. Die damals verfügbaren Optionen waren entweder Lösungen auf Basis der neuesten neuronalen Netze (NN), die groß und umständlich waren, oder einfachere Lösungen auf Basis von OpenCV, die nicht konsistent genug waren.
Inspiriert von vorhandenen OpenCV-Skripten habe ich eine einfache und konsistente Methode zum Extrahieren von Tabellen entwickelt und daraus eine Open-Source-Python-Bibliothek gemacht: img2table
Was neu geschrieben werden muss, ist: Link: https://github.com/ xavctn/img2table

Was macht meine Bibliothek?
Im Vergleich zu Deep-Learning-Lösungen erfordert dieses leichte Paket keine Schulung und minimale Parametrisierung. Es bietet die folgenden Funktionen:
- Identifiziert Tabellen in Bildern und PDF-Dateien, einschließlich Begrenzungsrahmen auf Tabellenzellenebene.
- Extrahieren Sie Tabelleninhalte durch unterstützende OCR-Dienste/-Tools (Tesseract, PaddleOCR, AWS Textract, Google Vision und Azure OCR werden derzeit unterstützt).
- Verarbeiten Sie komplexe Tabellenstrukturen wie zusammengeführte Zellen.
- Implementieren Sie Methoden zur Korrektur der Neigung und Drehung von Bildern.
- Die extrahierte Tabelle wird als einfaches Objekt zurückgegeben, einschließlich einer Pandas DataFrame-Darstellung.
- Option zum Exportieren der extrahierten Tabelle in eine Excel-Datei unter Beibehaltung der ursprünglichen Struktur.
Wie benutzt man es?
Sie können diese Bibliothek mit pip installieren und nach Abschluss der Installation verwenden.
pip install img2table
Um die Tabelle im Dokument zu identifizieren, müssen Sie nur eine Funktion aufrufen:
从img2table.document导入Image类# 图像实例化 img = Image(src="myimage.jpg")# 表格识别 img_tables = img.extract_tables()# 表格识别结果 img_tables[ExtractedTable(title=None, bbox=(10, 8, 745, 314),shape=(6, 3)), ExtractedTable(title=None, bbox=(936, 9, 1129, 111),shape=(2, 2))]
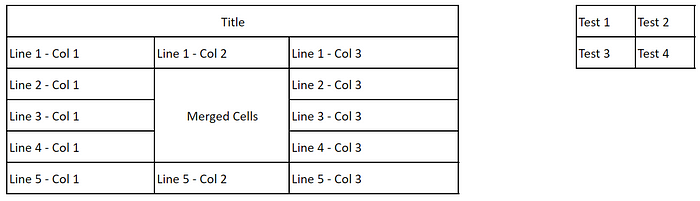
Der Inhalt, der neu geschrieben werden muss, ist: Das im obigen Beispiel verwendete Bild
Wenn wir den Inhalt der Tabelle extrahieren möchten, müssen wir ein OCR-Tool verwenden. Dies kann erreicht werden, indem Sie die folgenden Schritte ausführen:
from img2table.document import PDFfrom img2table.ocr import TesseractOCR# Instantiation of the pdfpdf = PDF(src="mypdf.pdf")# Instantiation of the OCR, Tesseract, which requires prior installationocr = TesseractOCR(lang="eng")# Table identification and extractionpdf_tables = pdf.extract_tables(ocr=ocr)# We can also create an excel file with the tablespdf.to_xlsx('tables.xlsx',ocr=ocr)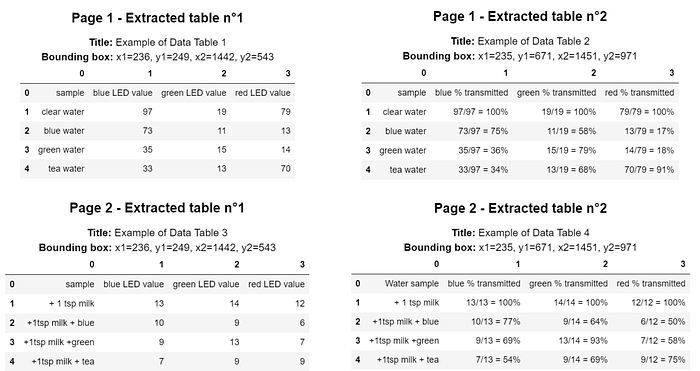
Die Beispieltabelle ist ein aus einer PDF-Datei extrahiertes Beispiel
Abschließend können Sie in einem einfachen Fall „borderless_tables“ ausführen, indem Sie das ` festlegen borderless_tables` Parameter „Extrahierung des Formulars. Dies ermöglicht die Erkennung von Tabellen, bei denen die Zellen nicht vollständig von Rändern umgeben sein müssen.
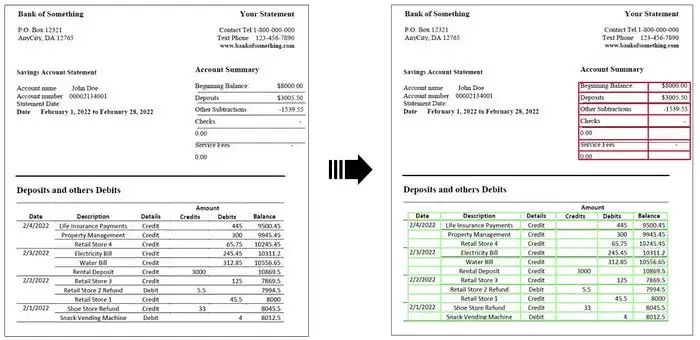
Die ursprüngliche Bedeutung muss nicht geändert werden. Was neu geschrieben werden muss, ist: Beispiel für eine „randlose“ Tabellenextraktion
Das ist alles! Tatsächlich ist das Repository nicht kompliziert, da unser Ziel darin besteht, es so weit wie möglich zu vereinfachen und die Einführung anderer Lösungen zu vermeiden, die Komplexität mit sich bringen könnten
Bitte besuchen Sie die GitHub-Seite des Projekts für detailliertere Dokumentation und Beispiele: https:// / github.com/xavctn/img2table
Zugrunde liegende Implementierung
Die gesamte Bildverarbeitung erfolgt mithilfe von OpenCV- und opencv-python-Bibliotheken. Dies ist jedoch immer noch ziemlich einfach.
Der Kern des Algorithmus ist die Hough-Transformation, die gerade Linien im Bild identifizieren kann, sodass wir horizontale und vertikale Linien im Bild erkennen können
需要重写的内容是:cv2.HoughLinesP(img, rho, theta, threshold, None, minLinLength, maxLineGap)
Danach müssen wir etwas verarbeiten auf den Linien, um sie aus Zellen heraus zu identifizieren und Tabellen aus Zellen weiter zu identifizieren
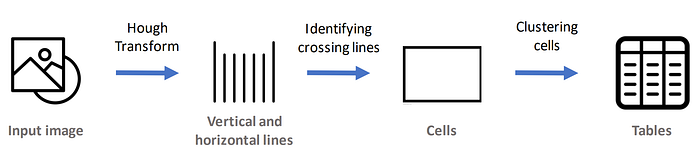
Vereinfachte Implementierung der algorithmischen Darstellung
Die meisten Berechnungen werden für eine gute Leistung und Geschwindigkeit mit Polaren durchgeführt.
Das obige ist der detaillierte Inhalt vonExtrahieren Sie die Tabelle mit Python aus dem Bild. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
