
 Technologie-Peripheriegeräte
KI
Die NVIDIA RTX-Grafikkarte beschleunigt die KI-Inferenz um das Fünffache! Der RTX-PC bewältigt große Modelle problemlos lokal
Technologie-Peripheriegeräte
KI
Die NVIDIA RTX-Grafikkarte beschleunigt die KI-Inferenz um das Fünffache! Der RTX-PC bewältigt große Modelle problemlos lokal
Die NVIDIA RTX-Grafikkarte beschleunigt die KI-Inferenz um das Fünffache! Der RTX-PC bewältigt große Modelle problemlos lokal

Auf der Microsoft Iginte Global Technology Conference veröffentlichte Microsoft eine Reihe neuer KI-bezogener Optimierungsmodelle und Ressourcen für Entwicklungstools, die Entwicklern dabei helfen sollen, die Hardwareleistung voll auszunutzen und KI-Anwendungsfelder zu erweitern.
Speziell für NVIDIA, das derzeit eine absolute Dominanz im KI-Bereich einnimmt, hat Microsoft dieses Mal ein großes Geschenkpaket verschickt, Ob es sich um die TensorRT-LLM-Paketschnittstelle für die OpenAI-Chat-API oder die Leistungsverbesserung des RTX-Treibers handelt DirectML für Llama 2 sowie andere beliebte Large Language Models (LLM) können eine bessere Beschleunigung und Anwendung auf NVIDIA-Hardware erreichen.
Unter diesen ist TensorRT-LLM eine Bibliothek zur Beschleunigung der LLM-Inferenz, die die KI-Inferenzleistung erheblich verbessern kann. Sie wird ständig aktualisiert, um immer mehr Sprachmodelle zu unterstützen, und ist außerdem Open Source.
NVIDIA hat im Oktober TensorRT-LLM für die Windows-Plattform veröffentlicht. Bei Desktops und Laptops, die mit GPU-Grafikkarten der RTX 30/40-Serie ausgestattet sind, können anspruchsvolle KI-Arbeitslasten einfacher erledigt werden, solange der Grafikspeicher 8 GB oder mehr erreicht
Jetzt kann Tensor RT-LLM für Windows über eine neue Paketschnittstelle mit der beliebten Chat-API von OpenAI kompatibel sein, sodass verschiedene verwandte Anwendungen direkt lokal ausgeführt werden können, ohne dass eine Verbindung zur Cloud erforderlich ist, was der Speicherung auf dem PC zuträglich ist Private und proprietäre Daten, um Datenschutzlecks zu verhindern.
Solange es sich um ein großes, von TensorRT-LLM optimiertes Sprachmodell handelt, kann es mit dieser Paketschnittstelle verwendet werden, einschließlich Llama 2, Mistral, NV LLM usw.Für Entwickler ist kein mühsames Umschreiben und Portieren des Codes erforderlich.
Ändern Sie einfach ein oder zwei Codezeilen. Die KI-Anwendung kann schnell lokal ausgeführt werden.
 ↑ ↑ ↑ Microsoft Visual Studio-Code-Plug-in basierend auf TensorRT-LLM – Continue.dev-Codierungsassistent
↑ ↑ ↑ Microsoft Visual Studio-Code-Plug-in basierend auf TensorRT-LLM – Continue.dev-Codierungsassistent
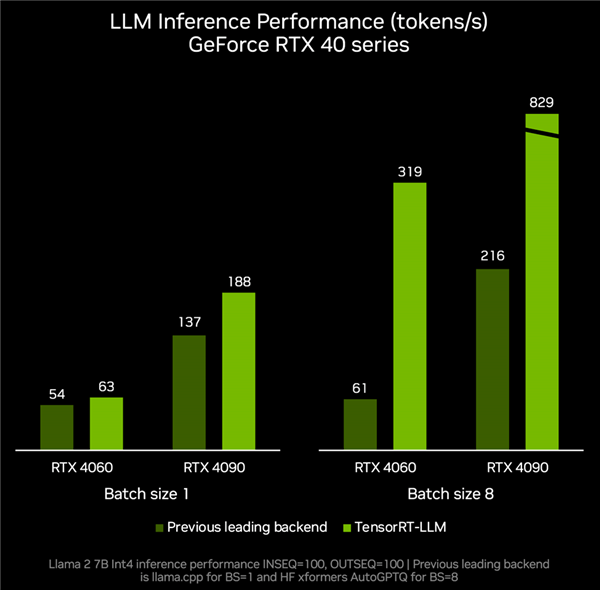
und die Unterstützung beliebterer LLMs, einschließlich des neuen Mistral mit 7 Milliarden Parametern, The 8 Milliarden Parameter Nemotron-3 ermöglicht es Desktops und Laptops, LLM jederzeit lokal, schnell und genau auszuführen. Laut tatsächlichen Messdaten,
RTX 4060-Grafikkarte gepaart mit TenroRT-LLM, kann die Inferenzleistung 319 Token pro Sekunde erreichen, was ganze 4,2-mal schneller ist als die 61 Token pro Sekunde anderer Backends.RTX 4090 kann von Token pro Sekunde auf 829 Token pro Sekunde beschleunigen, was einer Steigerung um das 2,8-fache entspricht.
 Mit seiner leistungsstarken Hardwareleistung, seinem umfangreichen Entwicklungsökosystem und einer Vielzahl von Anwendungsszenarien wird NVIDIA RTX zu einem unverzichtbaren und leistungsstarken Assistenten für die lokale KI. Gleichzeitig beschleunigt sich mit der kontinuierlichen Anreicherung von Optimierungen, Modellen und Ressourcen auch die Beliebtheit von KI-Funktionen auf Hunderten Millionen RTX-PCs
Mit seiner leistungsstarken Hardwareleistung, seinem umfangreichen Entwicklungsökosystem und einer Vielzahl von Anwendungsszenarien wird NVIDIA RTX zu einem unverzichtbaren und leistungsstarken Assistenten für die lokale KI. Gleichzeitig beschleunigt sich mit der kontinuierlichen Anreicherung von Optimierungen, Modellen und Ressourcen auch die Beliebtheit von KI-Funktionen auf Hunderten Millionen RTX-PCs
Derzeit haben mehr als 400 Partner KI-Anwendungen und Spiele veröffentlicht, die die RTX-GPU-Beschleunigung unterstützen. Da sich die Benutzerfreundlichkeit der Modelle weiter verbessert, gehe ich davon aus, dass immer mehr AIGC-Funktionen auf der Windows-PC-Plattform erscheinen werden.
Das obige ist der detaillierte Inhalt vonDie NVIDIA RTX-Grafikkarte beschleunigt die KI-Inferenz um das Fünffache! Der RTX-PC bewältigt große Modelle problemlos lokal. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Ist Chatgpt 4 o verfügbar?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 ist derzeit verfügbar und weit verbreitet, wodurch im Vergleich zu seinen Vorgängern wie ChatGPT 3.5 signifikante Verbesserungen beim Verständnis des Kontextes und des Generierens kohärenter Antworten zeigt. Zukünftige Entwicklungen können mehr personalisierte Inters umfassen
 Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Beste KI -Kunstgeneratoren (kostenlos & amp; bezahlt) für kreative Projekte
Apr 02, 2025 pm 06:10 PM
Der Artikel überprüft Top -KI -Kunstgeneratoren, diskutiert ihre Funktionen, Eignung für kreative Projekte und Wert. Es zeigt MidJourney als den besten Wert für Fachkräfte und empfiehlt Dall-E 2 für hochwertige, anpassbare Kunst.
 O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 gegen GPT-4O: Ist OpenAIs neues Modell besser als GPT-4O?
Mar 16, 2025 am 11:47 AM
Openais O1: Ein 12-tägiger Geschenkbummel beginnt mit ihrem bisher mächtigsten Modell Die Ankunft im Dezember bringt eine globale Verlangsamung, Schneeflocken in einigen Teilen der Welt, aber Openai fängt gerade erst an. Sam Altman und sein Team starten ein 12-tägiges Geschenk Ex
 Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google: Wettervorhersage mit Gencast Mini Demo
Mar 16, 2025 pm 01:46 PM
Gencast von Google Deepmind: Eine revolutionäre KI für die Wettervorhersage Die Wettervorhersage wurde einer dramatischen Transformation unterzogen, die sich von rudimentären Beobachtungen zu ausgefeilten AI-angetriebenen Vorhersagen überschreitet. Google DeepMinds Gencast, ein Bodenbrei
 Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Welche KI ist besser als Chatgpt?
Mar 18, 2025 pm 06:05 PM
Der Artikel erörtert KI -Modelle, die Chatgpt wie Lamda, Lama und Grok übertreffen und ihre Vorteile in Bezug auf Genauigkeit, Verständnis und Branchenauswirkungen hervorheben. (159 Charaktere)
