
 Technologie-Peripheriegeräte
KI
Die Bildgeschwindigkeit in Echtzeit stieg um das Fünf- bis Zehnfache, Tsinghua LCM/LCM-LoRA wurde mit über einer Million Aufrufen und über 200.000 Downloads populär
Technologie-Peripheriegeräte
KI
Die Bildgeschwindigkeit in Echtzeit stieg um das Fünf- bis Zehnfache, Tsinghua LCM/LCM-LoRA wurde mit über einer Million Aufrufen und über 200.000 Downloads populär
Die Bildgeschwindigkeit in Echtzeit stieg um das Fünf- bis Zehnfache, Tsinghua LCM/LCM-LoRA wurde mit über einer Million Aufrufen und über 200.000 Downloads populär

Generative Modelle treten in die „Echtzeit“-Ära ein?
Die Verwendung von Vincentian-Diagrammen und Tusheng-Diagrammen ist nichts Neues mehr. Bei der Verwendung dieser Tools stellten wir jedoch fest, dass sie oft langsam laufen, was dazu führt, dass wir eine Weile warten müssen, um die generierten Ergebnisse zu erhalten
Aber kürzlich hat ein Modell namens „LCM“ diese Situation geändert und ist sogar in der Lage um eine kontinuierliche Bilderzeugung in Echtzeit zu erreichen.


Quelle: https://twitter.com/javilopen/status/1724398666889224590
Der vollständige Name von LCM lautet Latent Consistency Models (latentes Konsistenzmodell), entwickelt von Cross Information der Tsinghua University Forschung Konstruiert von Forschern des Instituts. Vor der Veröffentlichung dieses Modells war die Generierung latenter Diffusionsmodelle (LDM) wie Stable Diffusion aufgrund der rechnerischen Komplexität des iterativen Stichprobenprozesses sehr langsam. Durch einige innovative Methoden kann LCM mit nur wenigen Inferenzschritten hochauflösende Bilder erzeugen. Laut Statistik kann LCM die Effizienz gängiger vinzentinischer Graphenmodelle um das Fünf- bis Zehnfache steigern und so Echtzeiteffekte zeigen. 
Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/pdf/2310.04378.pdf
Projektadresse: https://github.com/luosiallen/latent-consistency-model
Der Inhalt wurde innerhalb eines Monats nach seiner Veröffentlichung mehr als eine Million Mal angesehen, und der Autor wurde außerdem eingeladen, das neu entwickelte LCM-Modell und die Demonstration auf mehreren Plattformen wie Hugging Face, Replicate und Puyuan einzusetzen. Unter anderem wurde das LCM-Modell mehr als 200.000 Mal auf der Hugging Face-Plattform heruntergeladen, und die Anzahl der Online-API-Aufrufe auf der Replicate-Plattform hat 540.000 Mal überschritten. Auf dieser Grundlage schlug das Forschungsteam das LCM-LoRa weiter vor. Mit dieser Methode kann die schnelle Sampling-Fähigkeit von LCM ohne zusätzliche Schulung auf andere LoRA-Modelle übertragen werden. Dies bietet eine direkte und effektive Lösung für die vielen verschiedenen Modellstile, die bereits in der Open-Source-Community existieren.
 Link zum technischen Bericht: https://arxiv.org/pdf/2311.05556.pdf Die Generierungsfähigkeit von Modellen eröffnet neue Anwendungsgebiete für die Bilderzeugungstechnologie. Dieses Modell ermöglicht eine Hochgeschwindigkeitsbildgenerierung durch schnelle Verarbeitung und Wiedergabe von in Echtzeit erfassten Bildern basierend auf Eingabetext (Eingabeaufforderungen). Dies bedeutet, dass Benutzer die Szenen oder visuellen Effekte, die sie anzeigen möchten, individuell anpassen können.
Link zum technischen Bericht: https://arxiv.org/pdf/2311.05556.pdf Die Generierungsfähigkeit von Modellen eröffnet neue Anwendungsgebiete für die Bilderzeugungstechnologie. Dieses Modell ermöglicht eine Hochgeschwindigkeitsbildgenerierung durch schnelle Verarbeitung und Wiedergabe von in Echtzeit erfassten Bildern basierend auf Eingabetext (Eingabeaufforderungen). Dies bedeutet, dass Benutzer die Szenen oder visuellen Effekte, die sie anzeigen möchten, individuell anpassen können.
Auf dem , Echtzeit-Video-Rendering und anderen verschiedenen Anwendungen.

Der Inhalt, der neu geschrieben werden muss, ist: Bildquelle: https://twitter.com/javilopen/status/1724398708052414748

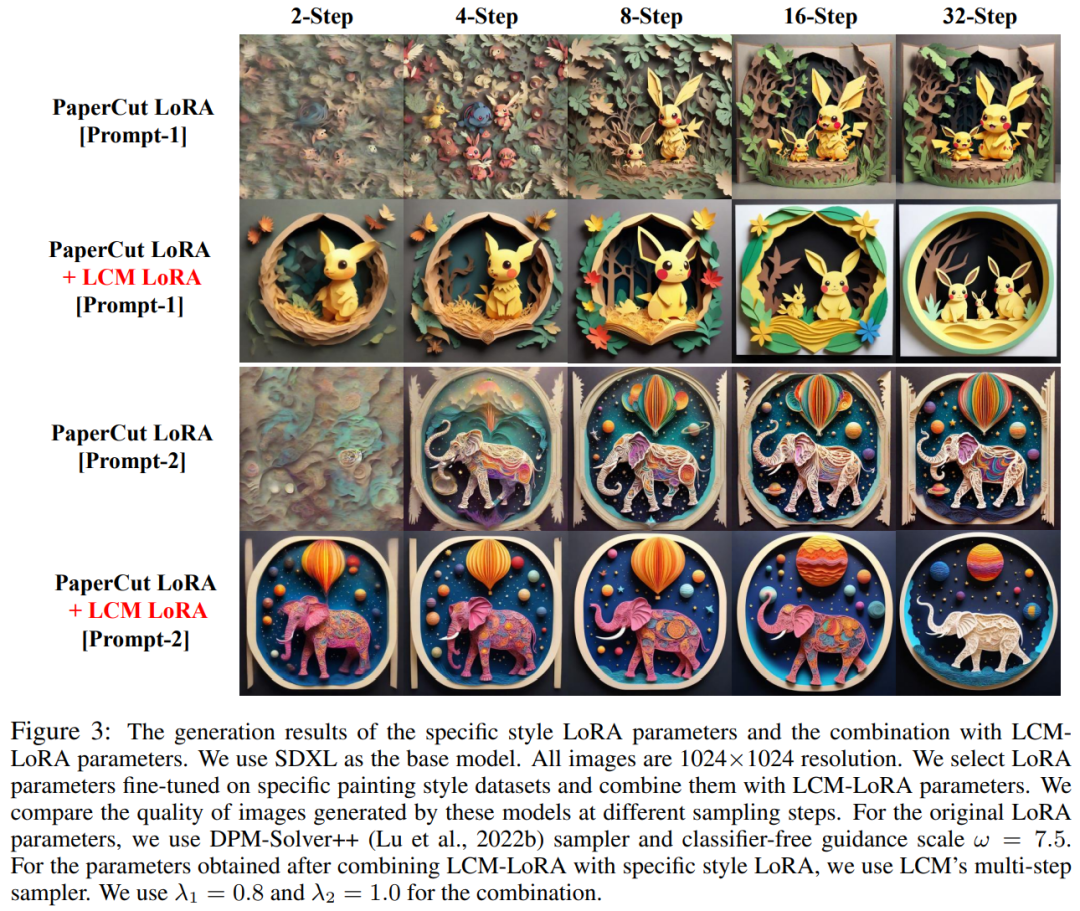
Als nächstes stellen wir die beiden Forschungsergebnisse von LCM bzw. LCM-LoRA vor. LCM: Generieren Sie hochauflösende Bilder mit nur wenigen Inferenzschritten In der AIGC-Ära haben auf Diffusionsmodellen basierende Vincentian-Graph-Modelle, einschließlich Stable Diffusion und DALL-E 3, große Aufmerksamkeit erhalten. Diffusionsmodelle erzeugen qualitativ hochwertige Bilder, indem sie den Trainingsdaten Rauschen hinzufügen und den Prozess dann umkehren. Das Diffusionsmodell erfordert jedoch eine mehrstufige Abtastung, um Bilder zu erzeugen, was ein relativ langsamer Prozess ist und die Kosten der Inferenz erhöht. Das Problem der langsamen mehrstufigen Stichprobenentnahme ist ein großer Engpass bei der Bereitstellung solcher Modelle. Das von Dr. Song Yang von OpenAI in diesem Jahr vorgeschlagene Konsistenzmodell (CM) bietet eine Idee zur Lösung der oben genannten Probleme. Es wurde darauf hingewiesen, dass das Konsistenzmodell so konzipiert ist, dass es in einem einzigen Schritt erstellt werden kann, was ein großes Potenzial zur Beschleunigung der Erstellung von Diffusionsmodellen aufweist. Da das Konsistenzmodell jedoch auf die bedingungslose Bilderzeugung beschränkt ist, können viele praktische Anwendungen, einschließlich vinzentinischer Bilder, grafisch generierter Bilder usw., die potenziellen Vorteile dieses Modells immer noch nicht nutzen. Latent Consistency Model (LCM) wurde geboren, um die oben genannten Probleme zu lösen. Das latente Konsistenzmodell unterstützt die Bildgenerierungsaufgabe gegebener Bedingungen und kombiniert latente Codierung, klassifikatorfreie Führung und viele andere Technologien, die in Diffusionsmodellen weit verbreitet sind, wodurch der bedingte Entrauschungsprozess erheblich beschleunigt wird und viele praktische Anwendungen bereitgestellt werden ein Weg. LCM Technische Details Konkret interpretiert das latente Konsistenzmodell das Entrauschungsproblem des Diffusionsmodells als einen Prozess zur Lösung der unten gezeigten erweiterten probabilistischen Fluss-Differentialgleichung. Die Lösungseffizienz kann durch die Verbesserung des traditionellen Diffusionsmodells verbessert werden. Die traditionelle Methode verwendet numerische Iteration, um gewöhnliche Differentialgleichungen zu lösen, aber selbst mit einem genaueren Löser ist die Genauigkeit jedes Schritts begrenzt und es sind etwa 10 Iterationen erforderlich, um ein zufriedenstellendes Ergebnis zu erhalten Es unterscheidet sich von der traditionellen iterativen Lösung von Bei gewöhnlichen Differentialgleichungen erfordert das latente Konsistenzmodell eine direkte einstufige Lösung der gewöhnlichen Differentialgleichung, die die endgültige Lösung der Gleichung vorhersagt, und kann theoretisch in einem einzigen Schritt ein Bild erzeugen Um das Latente zu trainieren Konsistenzmodell: In dieser Studie wird vorgeschlagen, die Parameter vorab trainierter Diffusionsmodelle (z. B. stabile Diffusion) zu optimieren, um eine schnelle Modellgenerierung mit minimalem Ressourcenverbrauch zu erreichen. Dieser Destillationsprozess basiert auf der von Dr. Song Yang vorgeschlagenen Optimierung der Konsistenzverlustfunktion. Um eine bessere Leistung zu erzielen und den Rechenaufwand für die Vincentian-Graph-Aufgabe zu reduzieren, werden in diesem Artikel drei Schlüsseltechnologien vorgeschlagen: Umgeschriebener Inhalt: (1) Durch die Verwendung eines vorab trainierten Autoencoders wird das Originalbild in eine latente Darstellung im Raum codiert um redundante Informationen beim Komprimieren von Bildern zu reduzieren und Bilder semantisch konsistenter zu machen (2) Destillieren Sie die klassifikatorfreie Führung als Eingabeparameter des Modells in das latente Konsistenzmodell und genießen Sie klassenlose. Während die Klassifikatorführung eine bessere Bild-Text-Konsistenz bringt, da Die klassifikatorfreie Leitamplitude wird als Eingabeparameter in das latente Konsistenzmodell destilliert. Dadurch kann der während der Inferenz erforderliche Rechenaufwand reduziert werden. (3) Die Verwendung der Sprungstrategie zur Berechnung des Konsistenzverlusts beschleunigt den Destillationsprozess erheblich potenzielles Konsistenzmodell. Der Pseudocode des Destillationsalgorithmus des latenten Konsistenzmodells ist in der folgenden Abbildung dargestellt. Qualitative und quantitative Ergebnisse zeigen, dass das latente Konsistenzmodell in der Lage ist, schnell qualitativ hochwertige Bilder zu erzeugen. Dieses Modell kann in 1 bis 4 Schritten hochwertige Bilder erzeugen. Durch den Vergleich der tatsächlichen Inferenzzeit und des Generierungsqualitätsindikators FID ist ersichtlich, dass das potenzielle Konsistenzmodell im Vergleich zu DPM Solver++, einem der schnellsten existierenden Sampler, die tatsächliche Inferenzzeit bei gleichbleibender Generierungsqualität um etwa das Vierfache beschleunigen kann . Basierend auf dem Konsistenzmodell veröffentlichte das Autorenteam anschließend seinen technischen Bericht zu LCM-LoRA. Da der Destillationsprozess des latenten Konsistenzmodells als Feinabstimmungsprozess für das ursprünglich vorab trainierte Modell betrachtet werden kann, können effiziente Feinabstimmungstechniken wie LoRA zum Trainieren des latenten Konsistenzmodells verwendet werden. Dank der Ressourceneinsparungen, die die LoRA-Technologie mit sich bringt, führte das Team des Autors eine Destillation auf dem SDXL-Modell mit der größten Anzahl von Parametern in der Stable Diffusion-Reihe durch und erzielte erfolgreich einen potenziellen Konsens, der in sehr wenigen Schritten generiert werden kann und mit dem vergleichbar ist Dutzende von SDXL-Sexualmodellen. In der Einleitung des Papiers weist die Studie darauf hin, dass das Latent Diffusion Model (LDM) zwar erfolgreich bei der Generierung von Textbildern und Strichzeichnungsbildern war, sein langsamer Reverse-Sampling-Prozess jedoch Echtzeitanwendungen einschränkt und Auswirkungen auf die Benutzererfahrung hat . Aktuelle Open-Source-Modelle und Beschleunigungstechnologien können noch keine Echtzeitgenerierung auf gewöhnlichen GPUs für Verbraucher erreichen. Methoden zur Beschleunigung von LDM werden im Allgemeinen in zwei Kategorien unterteilt: Die erste Kategorie umfasst fortgeschrittene ODE-Solver wie DDIM, DPMSolver und DPM-Solver++. und Beschleunigen Sie den Generierungsprozess. Die zweite Kategorie umfasst die Destillation von LDM, um seine Funktionalität zu vereinfachen. ODE – Solver reduziert die Inferenzschritte, erfordert jedoch immer noch einen erheblichen Rechenaufwand, insbesondere bei Verwendung einer klassifikatorfreien Anleitung. Destillationsmethoden wie Guided-Distill sind zwar vielversprechend, stoßen jedoch aufgrund ihres hohen Rechenaufwands auf praktische Einschränkungen. Es bleibt eine Herausforderung auf diesem Gebiet, ein Gleichgewicht zwischen Geschwindigkeit und Qualität von LDM-generierten Bildern zu finden. Inspiriert durch das Konsistenzmodell (CM) entstand kürzlich das Latent Consistency Model (LCM) als Lösung für das Problem der langsamen Abtastung bei der Bilderzeugung. LCM betrachtet den Rückdiffusionsprozess als ein PF-ODE-Problem (Enhanced Probability Flow ODE). Dieser Modelltyp sagt auf innovative Weise Lösungen im latenten Raum voraus, ohne dass iterative Lösungen über numerische ODE-Löser erforderlich sind. Dadurch ermöglichen sie eine effiziente Synthese hochauflösender Bilder mit nur 1 bis 4 Inferenzschritten. Darüber hinaus schnitt LCM auch in Bezug auf die Destillationseffizienz gut ab und es dauerte nur 32 Stunden Training mit A100, um die Schlussfolgerung des kleinsten Schritts abzuschließen Auf dieser Grundlage wurde eine Methode namens Latent Consistency Fine-Tuning (LCF) entwickelt , mit dem vorab trainiertes LCM verfeinert werden kann, ohne von einem Lehrerdiffusionsmodell ausgehen zu müssen. Für spezielle Datensätze wie Anime-, Realfoto- oder Fantasy-Bilddatensätze sind zusätzliche Schritte erforderlich, z. B. die Destillation von vorab trainiertem LDM in LCM mithilfe der Latent Consistent Distillation (LCD) oder die Feinabstimmung von LCM direkt mithilfe von LCF. Dieses zusätzliche Training kann jedoch den schnellen Einsatz von LCM auf verschiedenen Datensätzen behindern, was eine wichtige Frage aufwirft: ob eine schnelle, trainingsfreie Inferenz auf benutzerdefinierten Datensätzen erreicht werden kann. Um die obige Frage zu beantworten, schlugen die Forscher LCM-LoRA vor. LCM-LoRA ist ein allgemeines, trainingsfreies Beschleunigungsmodul, das direkt in verschiedene fein abgestimmte Stable-Diffusion (SD)-Modelle oder SD LoRA eingesteckt werden kann, um schnelle Inferenz mit minimalen Schritten zu unterstützen. Im Vergleich zu frühen numerischen probabilistischen Fluss-ODE-Lösern (PF-ODE) wie DDIM, DPM-Solver und DPM-Solver++ stellt LCM-LoRA eine neue Klasse von PF-ODE-Lösermodulen dar, die auf neuronalen Netzen basieren. Es zeigt starke Generalisierungsfähigkeiten über verschiedene fein abgestimmte SD-Modelle und LoRA Die technischen Details von LCM-LoRA können wie folgt umgeschrieben werden: Im Allgemeinen wird das latente Konsistenzmodell mithilfe einer einstufigen geführten Destillationsmethode trainiert, die den vorab trainierten latenten Raum des Autoencoders für die Destillation des geführten Diffusionsmodells nutzt in LCM. Dieser Prozess beinhaltet die Erweiterung des probabilistischen Fluss-ODE, den wir uns als mathematische Formel vorstellen können, die sicherstellt, dass die generierten Proben einer Flugbahn folgen, die qualitativ hochwertige Bilder erzeugt. Es ist erwähnenswert, dass der Schwerpunkt der Destillation darauf liegt, die Genauigkeit dieser Flugbahnen beizubehalten und gleichzeitig die Anzahl der erforderlichen Probenahmeschritte erheblich zu reduzieren. Algorithmus 1 liefert den Pseudocode für das LCD. LoRA aktualisiert die vorab trainierte Gewichtsmatrix durch Anwendung einer Low-Rank-Zerlegung. Insbesondere wird bei einer gegebenen Gewichtsmatrix h stellt den Ausgabevektor dar. Aus Formel (1) kann beobachtet werden, dass durch Zerlegen der vollständigen Parametermatrix in das Produkt zweier niedriger Werte. Rangmatrizen, LoRA Die Anzahl der trainierbaren Parameter wurde erheblich reduziert, wodurch die Speichernutzung reduziert wurde. Die folgende Tabelle vergleicht die Gesamtzahl der Parameter im vollständigen Modell mit den trainierbaren Parametern bei Verwendung der LoRA-Technologie. Offensichtlich wird durch die Integration der LoRA-Technologie in den LCM-Destillationsprozess die Anzahl der trainierbaren Parameter erheblich reduziert, wodurch der Speicherbedarf für das Training effektiv reduziert wird. Diese Studie zeigt anhand einer Reihe von Experimenten, dass das LCD-Paradigma gut an größere Modelle wie SDXL und SSD-1B angepasst werden kann. Die Generierungsergebnisse verschiedener Modelle sind in Abbildung 2 dargestellt. Der Autor stellte fest, dass der Einsatz der LoRA-Technologie die Effizienz des Destillationsprozesses verbessern kann. Er fand auch heraus, dass die durch Training erhaltenen LoRA-Parameter als allgemeines Beschleunigungsmodul verwendet und direkt mit anderen LoRA-Parametern kombiniert werden können Wie in Abbildung 1 oben dargestellt, stellte das Autorenteam fest, dass es durch einfache lineare Kombination der durch Feinabstimmung eines bestimmten Stildatensatzes erhaltenen „Stilparameter“ und der durch Destillation latenter Konsistenz erhaltenen „Beschleunigungsparameter“ möglich ist, beides zu erhalten Schnelle Generierungsfunktionen und spezifische Stile. Ein neues latentes Konsistenzmodell. Diese Entdeckung verleiht der großen Anzahl von Open-Source-Modellen, die bereits in der bestehenden Open-Source-Community vorhanden sind, einen starken Schub, sodass diese Modelle sogar ohne zusätzliches Training von den Beschleunigungseffekten profitieren können, die das latente Konsistenzmodell mit sich bringt. zeigt den Effekt der neuen Modellgenerierung nach Verwendung dieser Methode zur Verbesserung des Modells im „Papierschnittstil“, wie in der Abbildung unten dargestellt Luo Simian ist Masterstudent im zweiten Jahr am Fachbereich Informatik und Technologie der Tsinghua-Universität und sein Betreuer ist Professor Zhao Xing. Er schloss sein Studium an der Big Data School der Fudan-Universität mit einem Bachelor ab. Seine Forschungsrichtung sind multimodale generative Modelle. Er interessiert sich für Diffusionsmodelle, Konsistenzmodelle und AIGC-Beschleunigung und engagiert sich für die Entwicklung der nächsten Generation generativer Modelle. Zuvor veröffentlichte er als Erstautor zahlreiche Artikel auf Top-Konferenzen wie ICCV und NeurIPS. Tan Yiqin ist Masterstudent im zweiten Jahr an der Tsinghua-Universität und sein Betreuer ist Herr Huang Longbo. Als Student studierte er am Fachbereich Elektrotechnik der Tsinghua-Universität. Seine Forschungsinteressen umfassen hauptsächlich Deep Reinforcement Learning und Diffusionsmodelle. In früheren Forschungen veröffentlichte er als Erstautor einige hochkarätige Arbeiten auf akademischen Konferenzen wie der ICLR und gab mündliche BerichteErwähnenswert ist, dass einer der beiden ein Lehrer der School of Medicine Li Jian für Fortgeschrittene ist Im Computertheoriekurs wurde die Idee von LCM vorgeschlagen und schließlich als Abschlussprojekt des Kurses präsentiert. Unter den drei Dozenten sind Li Jian und Huang Longbo außerordentliche Professoren des Tsinghua-Instituts für interdisziplinäre Information, und Zhao Xing ist Assistenzprofessor am Tsinghua-Institut für interdisziplinäre Information. Die erste Reihe (von links nach rechts): Luo Simian, Tan Yiqin. Zweite Reihe (von links nach rechts): Huang Longbo, Li Jian, Zhao Xing. 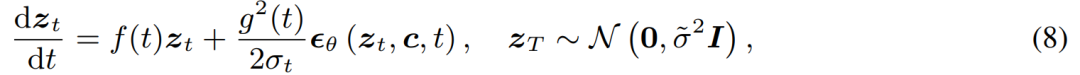


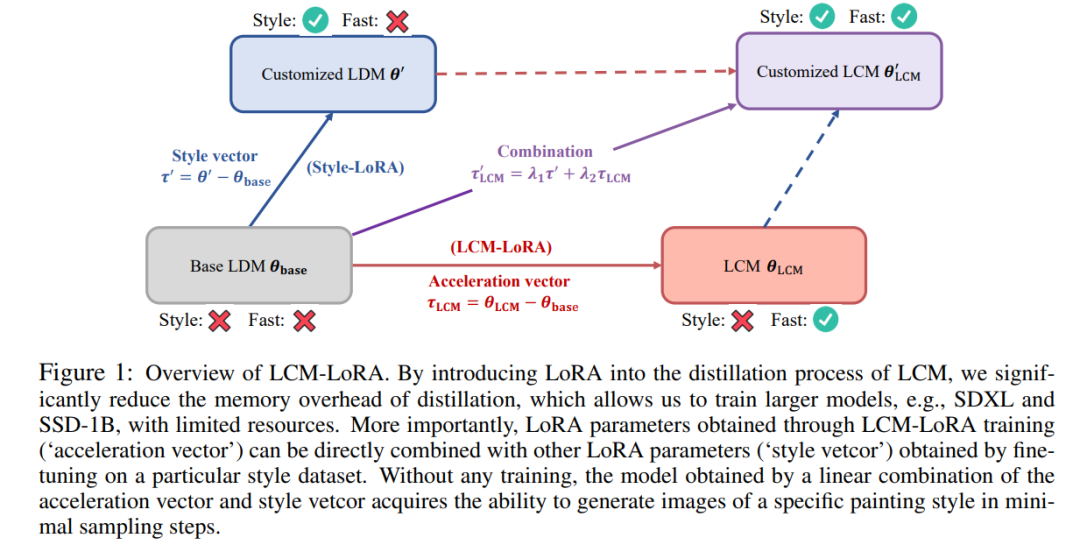 LCM-LoRA-Übersichtsdiagramm. Durch die Einführung von LoRA in den Destillationsprozess von LCM konnte in der Studie der Speicheraufwand der Destillation erheblich reduziert werden, sodass begrenzte Ressourcen zum Trainieren größerer Modelle wie SDXL und SSD-1B genutzt werden konnten. Noch wichtiger ist, dass die durch das LCM-LoRA-Training erhaltenen LoRA-Parameter (Beschleunigungsvektor) direkt mit anderen LoRA-Parametern (Stil-Vetcor) kombiniert werden können, die durch Feinabstimmung an einem bestimmten Stil-Datensatz erhalten werden. Ohne jegliches Training kann das durch die lineare Kombination von Beschleunigungsvektor und Stilvektor erhaltene Modell mit minimalen Abtastschritten Bilder eines bestimmten Malstils erzeugen.
LCM-LoRA-Übersichtsdiagramm. Durch die Einführung von LoRA in den Destillationsprozess von LCM konnte in der Studie der Speicheraufwand der Destillation erheblich reduziert werden, sodass begrenzte Ressourcen zum Trainieren größerer Modelle wie SDXL und SSD-1B genutzt werden konnten. Noch wichtiger ist, dass die durch das LCM-LoRA-Training erhaltenen LoRA-Parameter (Beschleunigungsvektor) direkt mit anderen LoRA-Parametern (Stil-Vetcor) kombiniert werden können, die durch Feinabstimmung an einem bestimmten Stil-Datensatz erhalten werden. Ohne jegliches Training kann das durch die lineare Kombination von Beschleunigungsvektor und Stilvektor erhaltene Modell mit minimalen Abtastschritten Bilder eines bestimmten Malstils erzeugen. 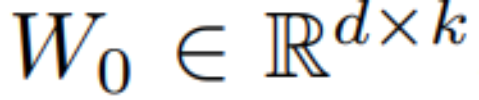 ihre Aktualisierungsmethode als
ihre Aktualisierungsmethode als 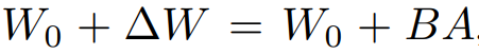 ausgedrückt, wobei
ausgedrückt, wobei 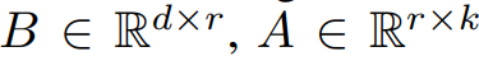 während des Trainingsprozesses W_0 unverändert bleibt und die Gradientenaktualisierung nur auf die beiden Parameter A und B angewendet wird. Somit wird für die Eingabe x die Änderung der Vorwärtsausbreitung wie folgt ausgedrückt:
während des Trainingsprozesses W_0 unverändert bleibt und die Gradientenaktualisierung nur auf die beiden Parameter A und B angewendet wird. Somit wird für die Eingabe x die Änderung der Vorwärtsausbreitung wie folgt ausgedrückt: 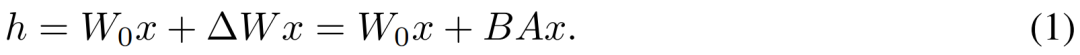


 Kurz gesagt, LCM-LoRA ist ein Modell für Stable-Diffusion (SD). ) Universelles, trainingsfreies Beschleunigungsmodul. Es fungiert als eigenständiges und effizientes, auf neuronalen Netzwerken basierendes Lösungsmodul zur Vorhersage von Lösungen für PF-ODE und ermöglicht schnelle Rückschlüsse mit minimalen Schritten auf verschiedenen fein abgestimmten SD-Modellen und SD LoRA. Eine große Anzahl von Text-zu-Bild-Generierungsexperimenten hat die starke Verallgemeinerungsfähigkeit und Überlegenheit von LCM-LoRA bewiesen Simian und Tan Yiqin.
Kurz gesagt, LCM-LoRA ist ein Modell für Stable-Diffusion (SD). ) Universelles, trainingsfreies Beschleunigungsmodul. Es fungiert als eigenständiges und effizientes, auf neuronalen Netzwerken basierendes Lösungsmodul zur Vorhersage von Lösungen für PF-ODE und ermöglicht schnelle Rückschlüsse mit minimalen Schritten auf verschiedenen fein abgestimmten SD-Modellen und SD LoRA. Eine große Anzahl von Text-zu-Bild-Generierungsexperimenten hat die starke Verallgemeinerungsfähigkeit und Überlegenheit von LCM-LoRA bewiesen Simian und Tan Yiqin.
Das obige ist der detaillierte Inhalt vonDie Bildgeschwindigkeit in Echtzeit stieg um das Fünf- bis Zehnfache, Tsinghua LCM/LCM-LoRA wurde mit über einer Million Aufrufen und über 200.000 Downloads populär. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Derzeit sind autoregressive groß angelegte Sprachmodelle, die das nächste Token-Vorhersageparadigma verwenden, auf der ganzen Welt populär geworden. Gleichzeitig haben uns zahlreiche synthetische Bilder und Videos im Internet bereits die Leistungsfähigkeit von Diffusionsmodellen gezeigt. Kürzlich hat ein Forschungsteam am MITCSAIL (darunter Chen Boyuan, ein Doktorand am MIT) erfolgreich die leistungsstarken Fähigkeiten des Vollsequenz-Diffusionsmodells und des nächsten Token-Modells integriert und ein Trainings- und Sampling-Paradigma vorgeschlagen: Diffusion Forcing (DF). ). Papiertitel: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Papieradresse: https:/
