
 Technologie-Peripheriegeräte
KI
Princeton Open-Source-34B-Mathematikmodell: Parameter werden halbiert, die Leistung ist mit Google Minerva vergleichbar und 55 Milliarden Token werden für professionelles Datentraining verwendet
Technologie-Peripheriegeräte
KI
Princeton Open-Source-34B-Mathematikmodell: Parameter werden halbiert, die Leistung ist mit Google Minerva vergleichbar und 55 Milliarden Token werden für professionelles Datentraining verwendet
Princeton Open-Source-34B-Mathematikmodell: Parameter werden halbiert, die Leistung ist mit Google Minerva vergleichbar und 55 Milliarden Token werden für professionelles Datentraining verwendet

Mathematik als Eckpfeiler der Wissenschaft war schon immer ein Schlüsselbereich der Forschung und Innovation.
Kürzlich haben sieben Institutionen, darunter die Princeton University, gemeinsam ein großes Sprachmodell LLEMMA speziell für Mathematik veröffentlicht, dessen Leistung mit Google Minerva 62B vergleichbar ist, und sein Modell, seinen Datensatz und seinen Code veröffentlicht, was beispiellose Vorteile für die Mathematikforschung bringt Ressourcen.

Papieradresse: https://arxiv.org/abs/2310.10631
Die Linkadresse des Datensatzes lautet: https://huggingface.co/datasets/EleutherAI/proof-pile- 2
Projektadresse: https://github.com/EleutherAI/math-lm Was neu geschrieben werden muss, ist:
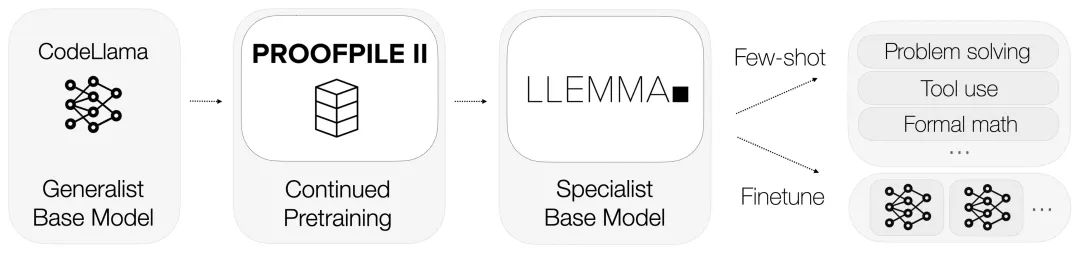
LLEMMA erbt die Grundlage von Code Llama und ist auf Proof-Pile-2 vorab trainiert.
Proof-Pile-2, ein riesiger gemischter Datensatz mit Informationen von 55 Milliarden Token, darunter wissenschaftliche Arbeiten, Webdaten mit hohem mathematischen Inhalt und mathematische Codes.
Ein Teil dieses Datensatzes, der Algebraic Stack, vereint 11B Datensätze aus 17 Sprachen und deckt numerische, symbolische und mathematische Beweise ab.
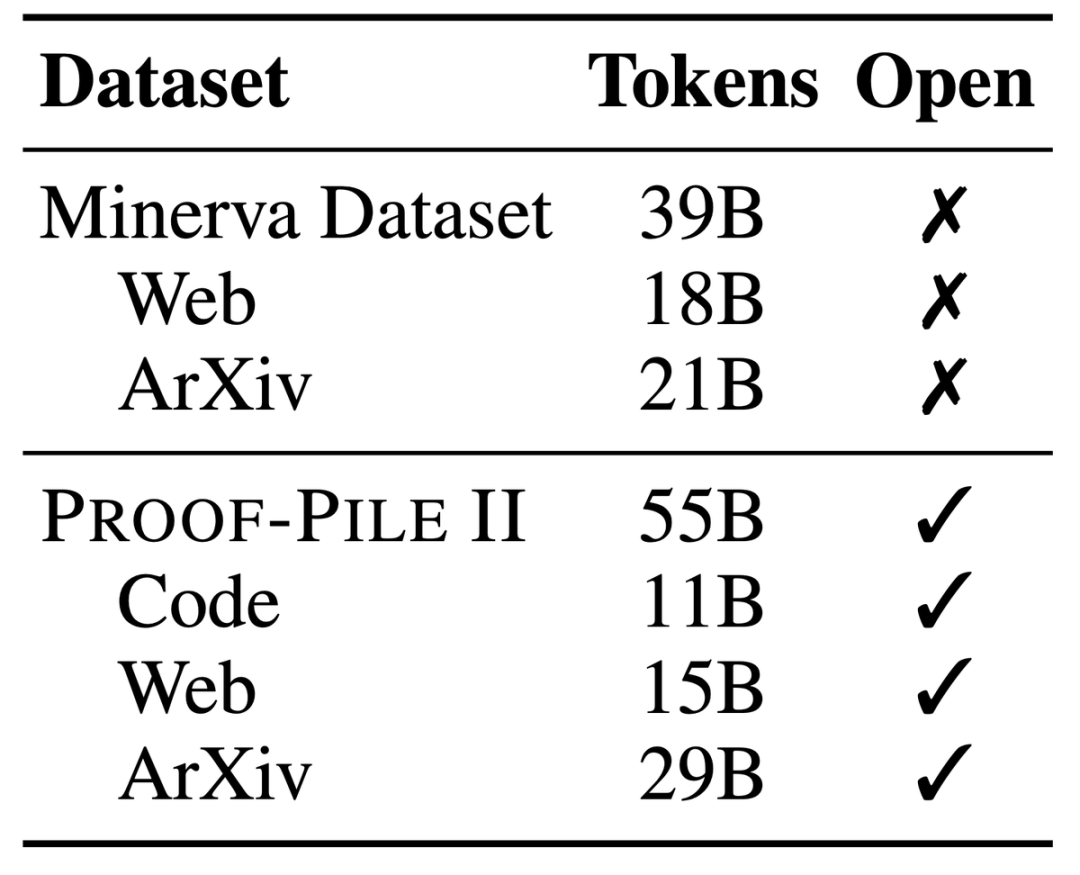
Mit 700 Millionen und 3,4 Milliarden Parametern schneidet es im MATH-Benchmark hervorragend ab und übertrifft alle bekannten Open-Source-Basismodelle.
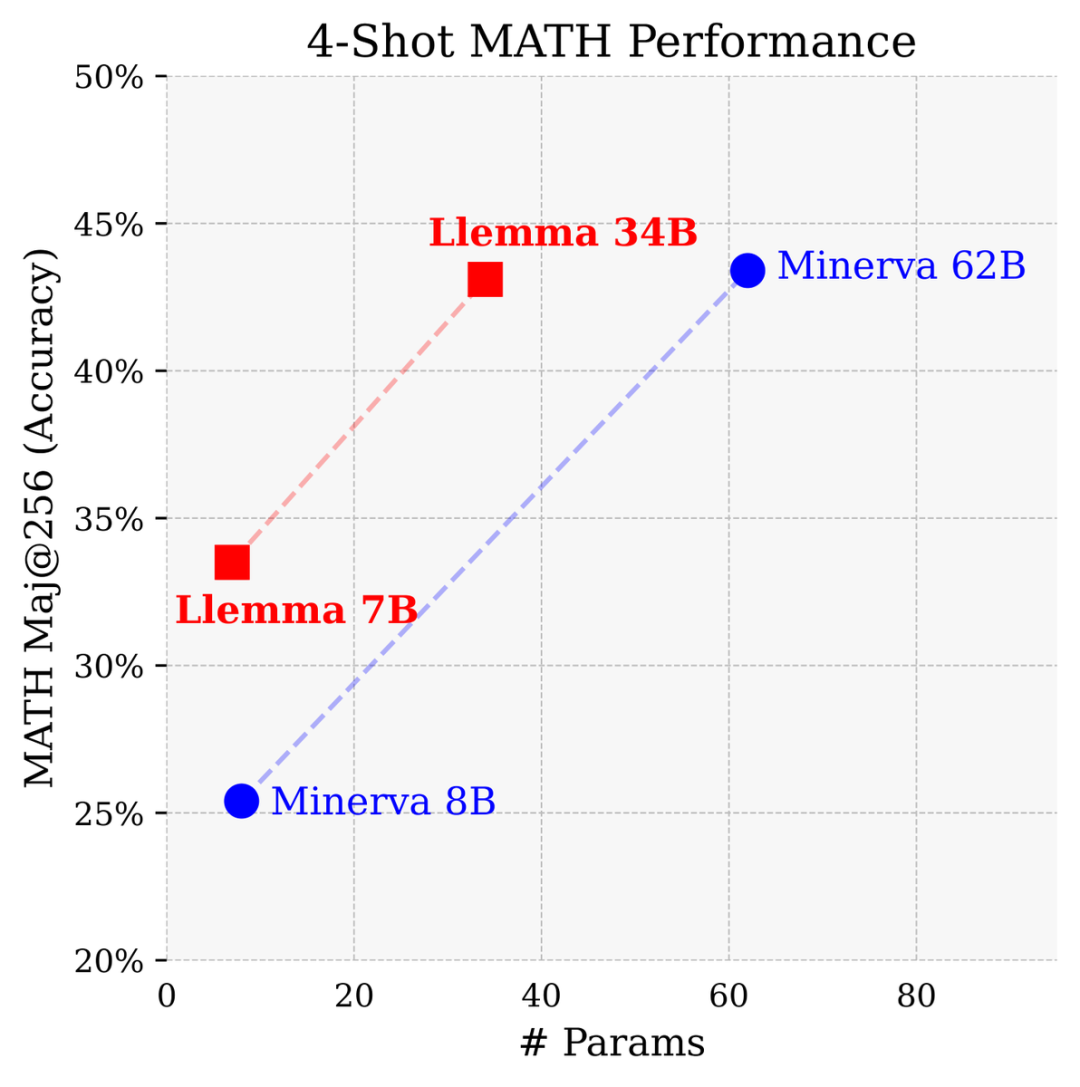
Im Vergleich zu einem geschlossenen Modell, das von Google Research speziell für Mathematik entwickelt wurde, erreichte Llemma 34B fast die gleiche Leistung mit der halben Anzahl von Parametern wie Minerva 62B.
Llemma übertrifft Minervas Leistung bei der Lösung von Problemen auf Parameterbasis. Es verwendet Rechenwerkzeuge und formale Theorembeweise, um unbegrenzte Möglichkeiten zur Lösung mathematischer Probleme bereitzustellen.
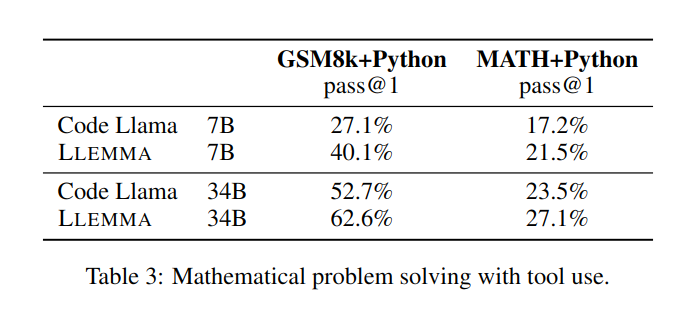
Es kann außerdem bequem Python-Interpreter und formale Beweiser verwenden demonstriert seine Fähigkeit, mathematische Probleme zu lösen
Aufgrund der besonderen Betonung formaler Beweisdaten war Algebraic Stack der erste Open Source, der die Fähigkeit demonstrierte, das Basismodell mit wenigen Schüssen zu beweisen

 Bild
Bild
Die Forscher teilten auch offen alle Trainingsdaten und den Code von LLEMMA. Im Gegensatz zu früheren mathematischen Modellen ist LLEMMA ein offenes und gemeinsam genutztes Open-Source-Modell, das der gesamten wissenschaftlichen Forschungsgemeinschaft die Tür öffnet.
Die Forscher versuchten, den Modellgedächtniseffekt zu quantifizieren, und stellten überraschenderweise fest, dass Llemma für Probleme, die im Trainingssatz auftraten, nicht genauer wurde. Da der Code und die Daten öffentlich verfügbar sind, ermutigen die Forscher andere, ihre Analyse zu replizieren und zu erweitern
Trainingsdaten und experimentelle Konfiguration
LLEMMA ist ein großes Sprachmodell für Mathematik, das weiterhin auf Proof-Pile-2 basierend auf Code Llama vorab trainiert wird. Proof-Pile-2 ist ein gemischter Datensatz, der wissenschaftliche Arbeiten, Webseitendaten mit mathematischem Inhalt und mathematischen Code enthält. Der Codeteil von AlgebraicStack enthält 11 Milliarden Datensätze. Es deckt numerische, symbolische und formale Mathematik ab und wird öffentlich veröffentlicht
Jedes Modell in LLEMMA wird durch Code Llama initialisiert. Das Code-Llama-Modell ist ein reines Decoder-Sprachmodell, das von Llama 2 initialisiert wird. Für das 7B-Modell führte der Autor ein Training mit 200B-Markern durch, während der Autor für das 34B-Modell ein Training mit 50B-Markern durchführte Llama Setzen Sie das Vortraining fort und führen Sie einige wenige Bewertungen von LLEMMA für mehrere mathematische Problemlösungsaufgaben wie MATH und GSM8k durch. 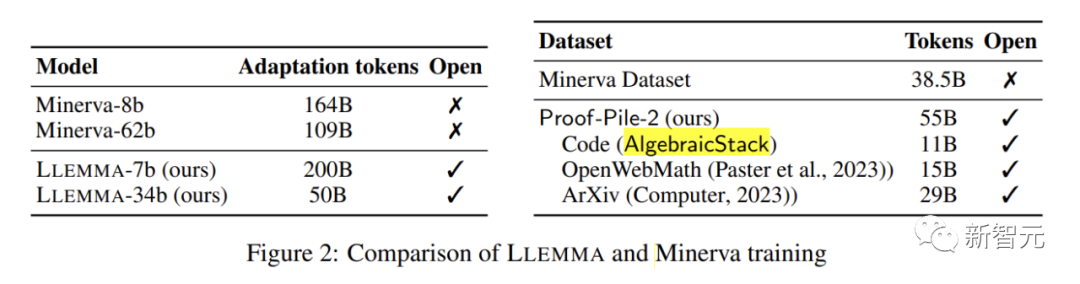
Forscher fanden heraus, dass LLEMMA diese Aufgaben deutlich verbesserte und sich an verschiedene Problemtypen und Schwierigkeiten anpassen konnte.
LLEMMA 34B zeigt leistungsfähigere mathematische Fähigkeiten als andere offene Grundmodelle bei extrem schwierigen mathematischen Problemen.
Bei mathematischen Benchmarks übertrifft LLEMMA weiterhin Proof-Pile-2. Vortraining verbessert die Leistung bei wenigen Schüssen zu fünf Mathe-Benchmarks.
Die Verbesserung von LLEMMA 34B ist 20 Prozentpunkte höher als bei Code Llama bei GSM8k und 13 Prozentpunkte höher bei MATH. Darüber hinaus übertrifft LLEMMA 7B auch das proprietäre Minerva-Modell ähnlicher Größe, was beweist, dass das Vortraining auf Proof-Pile-2 die mathematischen Problemlösungsfähigkeiten großer Modelle bei der Lösung mathematischer Probleme effektiv verbessern kann Bei Verwendung von Computertools wie Python schneidet LLEMMA sowohl bei MATH+Python- als auch bei GSM8k+Python-Aufgaben besser ab als Code Llama
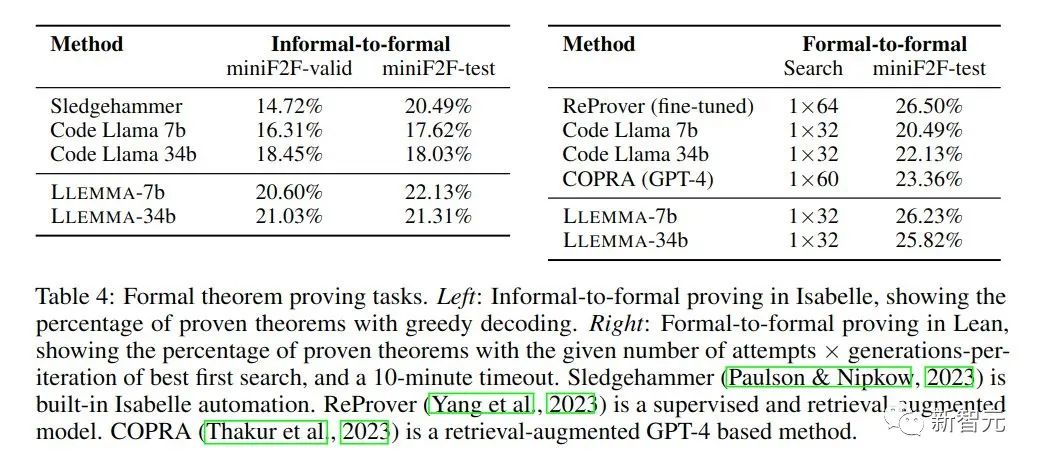
Bei mathematischen Beweisaufgaben zeichnet sich LLEMMA aus. In diesem Fall wird ein formaler Beweis erstellt und anschließend von einem Beweisassistenten verifiziert.
Formal-zu-formaler Beweis bedeutet, eine formale Aussage zu beweisen, indem eine Reihe von Beweisschritten (Strategien) generiert werden. Die Ergebnisse zeigen, dass ein kontinuierliches Vortraining von LLEMMA auf Proof-Pile-2 die Leistung dieser beiden formalen Theorembeweisaufgaben in wenigen Schritten verbessert. 
LLEMMA verfügt nicht nur über eine beeindruckende Leistung, sondern erschließt auch revolutionäre Datensätze und demonstriert erstaunliche Fähigkeiten zur Problemlösung.
Der Geist des Open-Source-Sharings markiert eine neue Ära in der Welt der Mathematik. Die Zukunft der Mathematik ist da und jeder von uns Mathematikbegeisterten, Forschern und Pädagogen wird davon profitieren. 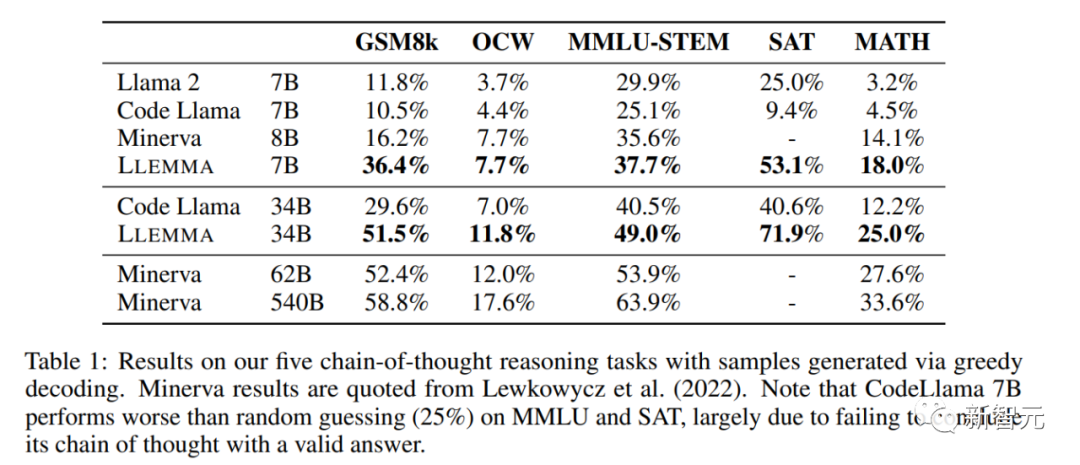
Die Entstehung von LLEMMA bietet uns beispiellose Werkzeuge, um die Lösung mathematischer Probleme effizienter und innovativer zu gestalten.
Darüber hinaus wird das Konzept des offenen Teilens auch eine tiefere Zusammenarbeit zwischen der globalen wissenschaftlichen Forschungsgemeinschaft fördern und gemeinsam den wissenschaftlichen Fortschritt fördern.
Das obige ist der detaillierte Inhalt vonPrinceton Open-Source-34B-Mathematikmodell: Parameter werden halbiert, die Leistung ist mit Google Minerva vergleichbar und 55 Milliarden Token werden für professionelles Datentraining verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
