
 Technologie-Peripheriegeräte
KI
Bei großen Modellen wie GPT und Llama gibt es einen „Umkehrfluch'.
Technologie-Peripheriegeräte
KI
Bei großen Modellen wie GPT und Llama gibt es einen „Umkehrfluch'.
Bei großen Modellen wie GPT und Llama gibt es einen „Umkehrfluch'.

Forscher der Renmin University of China haben herausgefunden, dass der „Umkehrfluch“, auf den kausale Sprachmodelle wie Llama stoßen, auf die inhärenten Mängel von Next-Token-Vorhersage + kausalen Sprachmodellen zurückzuführen ist. Sie fanden auch heraus, dass die von GLM verwendete autoregressive Lückentext-Trainingsmethode robuster im Umgang mit diesem „Umkehrfluch“ ist
Durch die Einführung des bidirektionalen Aufmerksamkeitsmechanismus zur Feinabstimmung in das Llama-Modell wurde diese Studie durchgeführt hat Lamas Erleichterung „Umkehrung des Fluchs“ erreicht.
Diese Studie weist darauf hin, dass es bei den derzeit beliebten Großmodellstrukturen und Trainingsmethoden viele potenzielle Probleme gibt. Es besteht die Hoffnung, dass mehr Forscher Innovationen bei Modellstrukturen und Vortrainingsmethoden entwickeln können, um das Intelligenzniveau zu verbessern

Papieradresse: https://arxiv.org/pdf/2311.07468.pdf
Hintergrund
Bei der Forschung von Lukas Berglund und anderen wurde entdeckt, dass es in den GPT- und Llama-Modellen einen „Umkehrfluch“ gibt. Auf die Frage von GPT-4 „Wer ist Tom Cruises Mutter?“ konnte GPT-4 die richtige Antwort „Mary Lee Piffel“ geben, auf die Frage von GPT-4 jedoch „Wer ist Piffels Sohn?“ „Mary Lee“. , GPT-4 gab an, dass er diese Person nicht kenne. Vielleicht war GPT-4 nach der Abstimmung aus Gründen des Schutzes der Privatsphäre der Charaktere nicht bereit, solche Fragen zu beantworten. Allerdings gibt es diese Art von „Umkehrfluch“ auch in einigen Wissensfragen und Antworten, die nicht die Privatsphäre betreffen. Beispielsweise kann GPT-4 den nächsten Satz von „Der Gelbe Kranich ist weg und kehrt nie wieder“ genau beantworten, aber für „. „Weiße Wolken“ Wie lautet der vorherige Satz von „Tausende Jahre leerer Raum“? Das Modell hat ernsthafte Illusionen hervorgerufen
Abbildung 1: Auf die Frage von GPT-4, was der nächste Satz von „Der gelbe Kranich ist weg“ lautet kehrt nie zurück“, antwortet das Modell richtig
Bild 2: Auf die Frage von GPT-4, was der vorherige Satz von „Weiße Wolken für tausend Jahre am Himmel“ ist, was ist der Modellfehler
Warum? kam es zum umgekehrten Fluch?
Die Studie von Berglund et al. wurde nur an Lama und GPT getestet. Diese beiden Modelle haben gemeinsame Merkmale: (1) Sie werden mithilfe einer unbeaufsichtigten Aufgabe zur Vorhersage des nächsten Tokens trainiert. (2) Im Nur-Decoder-Modell wird ein unidirektionaler Kausalaufmerksamkeitsmechanismus (Kausalaufmerksamkeit) eingesetzt.
Der Forschungspunkt von Die Ansicht, den Fluch umzukehren, ist, dass die Trainingsziele dieser Modelle zur Entstehung dieses Problems geführt haben und möglicherweise ein einzigartiges Problem für Llama, GPT und andere Modelle darstellen.
Umgeschriebener Inhalt: Abbildung 3: Schematische Darstellung die Verwendung der Next-Token-Vorhersage (NTP) zum Trainieren eines kausalen Sprachmodells 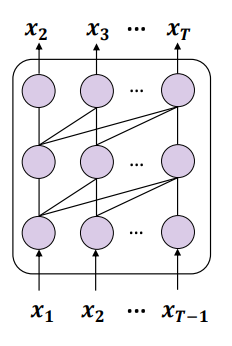
Die Kombination dieser beiden Punkte führt zu einem Problem: Wenn die Trainingsdaten die Entitäten A und B enthalten und A vor B erscheint, dann dieses Modell Nur die bedingte Wahrscheinlichkeit p(B|A) der Vorwärtsvorhersage kann optimiert werden, und es gibt keine Garantie für die umgekehrte bedingte Wahrscheinlichkeit p(A|B). Wenn der Trainingssatz nicht groß genug ist, um die möglichen Anordnungen von A und B vollständig abzudecken, tritt das Phänomen des „Umkehrfluchs“ auf
Natürlich gibt es auch viele generative Sprachmodelle, die das obige Trainingsparadigma nicht übernehmen. Wie das von der Tsinghua-Universität vorgeschlagene GLM ist die Trainingsmethode in der folgenden Abbildung dargestellt:
Abbildung 4: Eine vereinfachte Version des GLM-Trainingsdiagramms 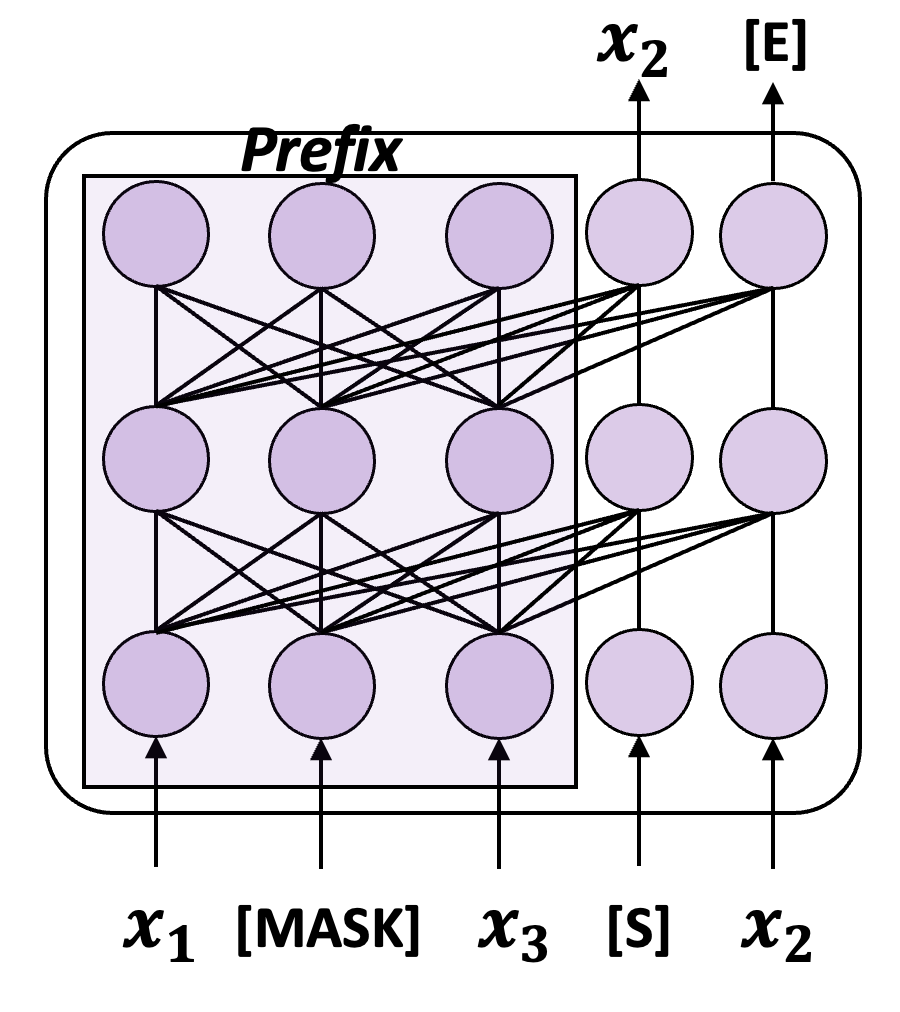
GLM verwendet das Trainingsziel des autoregressiven Blank-Infilling ( ABI), das heißt, wählt zufällig aus der Eingabe einen Inhalt aus, der maskiert werden soll, und sagt dann den Inhalt autoregressiv voraus. Während das vorherzusagende Token immer noch über unidirektionale Aufmerksamkeit auf das „Oben“ angewiesen ist, umfasst das „Oben“ jetzt alles vor und nach diesem Token in der ursprünglichen Eingabe, sodass der ABI implizit die umgekehrte Abhängigkeit berücksichtigt
Die durchgeführte Studie Ich habe ein Experiment durchgeführt und herausgefunden, dass GLM die Fähigkeit besitzt, bis zu einem gewissen Grad immun gegen den „Umkehrfluch“ zu sein
- Diese Studie verwendet den von Berglund et al. vorgeschlagenen Datensatz „Personal Name-Description Question and Answer“, der GPT-4 verwendet, um mehrere Personennamen und entsprechende Beschreibungen zusammenzustellen. Sowohl die Personennamen als auch die Beschreibungen sind eindeutig. Das Datenbeispiel ist in der folgenden Abbildung dargestellt:

Der Trainingssatz ist in zwei Teile unterteilt, ein Teil enthält zuerst den Namen der Person (NameToDescription) und der andere Teil enthält zuerst die Beschreibung (DescriptionToName). Es gibt keine überschneidenden Namen oder Beschreibungen in den beiden Teilen. Die Eingabeaufforderung der Testdaten schreibt die Eingabeaufforderung der Trainingsdaten neu.
- Dieser Datensatz besteht aus vier Testunteraufgaben:
- NameToDescription (N2D): Lassen Sie das Modell die entsprechende Beschreibung beantworten, indem Sie die Namen der am „NameToDescription“-Teil des Modelltrainingssatzes beteiligten Personen abfragen
- DescriptionToName (D2N): Durch Abfrage der im „DescriptionToName“-Teil des Modelltrainingssatzes enthaltenen Beschreibung lässt das Modell auf den Namen der entsprechenden Person antworten.
- DescrptionToName-reverse (D2N-reverse): Durch Abfrage des Beschreibung, die im Teil „DescriptionToName“ des Modelltrainingssatzes enthalten ist Name einer Person, lassen Sie das Modell auf die entsprechende Beschreibung antworten
- NameToDescription-reverse (N2D-reverse): Verwenden Sie die Beschreibung, die im Teil „NameToDescription“ des Modells enthalten ist Prompt-Modell-Trainingssatz, lassen Sie das Modell auf den entsprechenden Namen der Person antworten
- Diese Forschung ist in diesem Datensatz, Lama und GLM werden entsprechend ihren jeweiligen Zielen vor dem Training (NTP-Ziel für Lama) feinabgestimmt , ABI-Ziel für GLM). Nach der Feinabstimmung kann durch Testen der Genauigkeit des Modells bei der Beantwortung der Umkehraufgabe die Schwere des „Umkehrfluchs“, unter dem das Modell in realen Szenarien leidet, qualitativ beurteilt werden. Da alle Namen und Daten erfunden sind, werden diese Aufgaben weitgehend nicht durch das vorhandene Wissen des Modells unterbrochen.
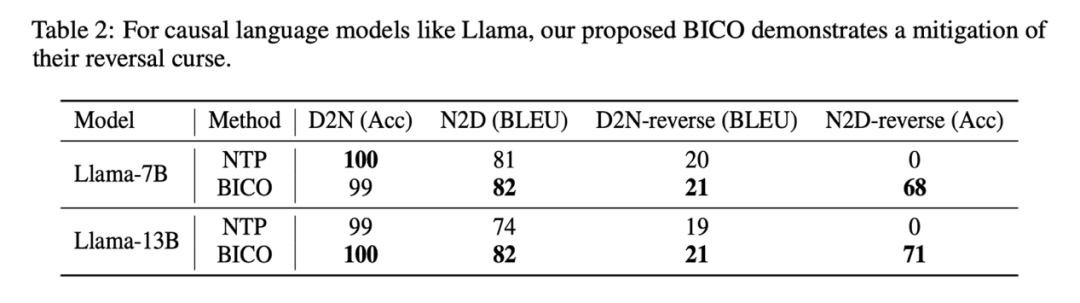
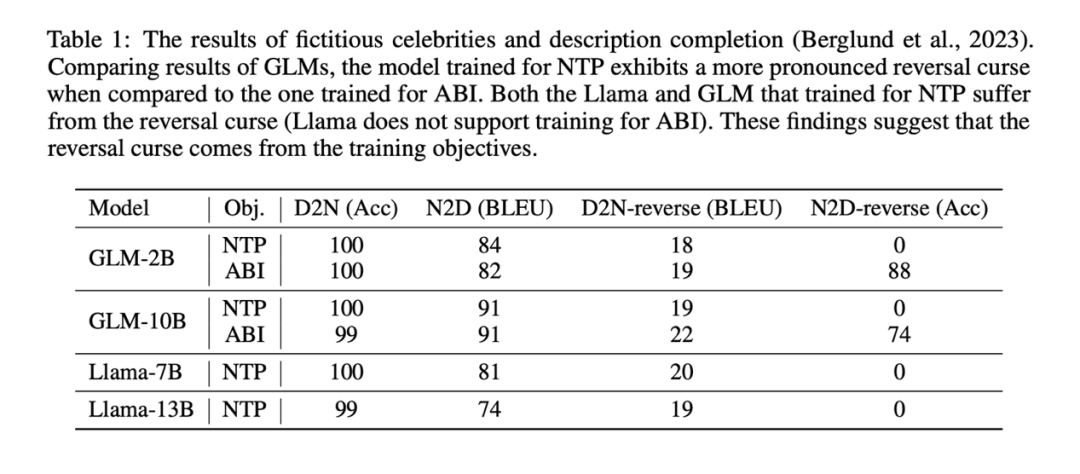 Experimentelle Ergebnisse zeigen, dass das durch NTP verfeinerte Llama-Modell im Grunde nicht in der Lage ist, die Umkehraufgabe korrekt zu beantworten (NameToDescription-Reverse-Task-Genauigkeit ist 0), während das durch ABI verfeinerte GLM-Modell ausgezeichnet ist Leistung bei der NameToDescrption-Umkehraufgabe. Die Genauigkeit ist sehr hoch.
Experimentelle Ergebnisse zeigen, dass das durch NTP verfeinerte Llama-Modell im Grunde nicht in der Lage ist, die Umkehraufgabe korrekt zu beantworten (NameToDescription-Reverse-Task-Genauigkeit ist 0), während das durch ABI verfeinerte GLM-Modell ausgezeichnet ist Leistung bei der NameToDescrption-Umkehraufgabe. Die Genauigkeit ist sehr hoch.
Zum Vergleich verwendete die Studie auch die NTP-Methode zur Feinabstimmung von GLM und stellte fest, dass die Genauigkeit von GLM bei der N2D-Reverse-Aufgabe auf 0 sank.
Vielleicht aufgrund von D2N-Reverse (unter Verwendung von Umkehrwissen). (Das Generieren einer Beschreibung anhand des Namens einer Person) ist viel schwieriger als N2D-Reverse (das Generieren eines Namens einer Person anhand einer bestimmten Beschreibung mithilfe von Umkehrwissen weist im Vergleich zu GLM-NTP nur eine geringfügige Verbesserung auf).
Die zentrale Schlussfolgerung der Studie wird dadurch nicht berührt: Trainingsziele sind eine der Ursachen für den „Umkehrfluch“. In kausalen Sprachmodellen, die mit der Vorhersage des nächsten Tokens vorab trainiert wurden, ist der „Umkehrfluch“ besonders schwerwiegend Als Lama und GPT Das Problem besteht darin, dass wir mit begrenzten Ressourcen nur Wege finden können, das Modell auf neue Daten abzustimmen und den „Umkehrfluch“ des Modells auf neues Wissen so weit wie möglich zu vermeiden, um es vollständig zu nutzen die Trainingsdaten.
Inspiriert von der GLM-Trainingsmethode schlägt diese Studie eine Trainingsmethode „Bidirektionale kausale Sprachmodelloptimierung“ vor, die von Lama verwendet werden kann, ohne neue Lücken zu schaffen. Kurz gesagt, das Training des bidirektionalen Aufmerksamkeitsmechanismus weist die folgenden Schlüsselpunkte auf:
1. Entfernen Sie die Standortinformationen von OOD. Die von Llama verwendete RoPE-Codierung fügt bei der Berechnung der Aufmerksamkeit Positionsinformationen zur Abfrage und zum Schlüssel hinzu. Die Berechnungsmethode ist wie folgt:
wobei Wenn die kausale Aufmerksamkeitsmaske von Wenn Lama direkt entfernt wird, werden Standortinformationen außerhalb der Verbreitung eingeführt. Der Grund dafür ist, dass die Abfrage an Position m während des Vortrainingsprozesses nur das innere Produkt ( Die in dieser Studie vorgeschlagene Lösung ist sehr einfach und sieht Folgendes vor: Wenn Diese Studie unterteilt die Berechnung des Aufmerksamkeitswerts in zwei Teile, berechnet das obere Dreieck bzw. das untere Dreieck gemäß der obigen Operation und verbindet es schließlich, so dass es kann sehr effizient implementiert werden. Die in diesem Artikel angegebene Aufmerksamkeitsberechnungsmethode wird übernommen, und der Gesamtvorgang wird im folgenden Unterdiagramm (a) dargestellt: Weil die Durch die Einführung eines Zwei-Wege-Aufmerksamkeitsmechanismus kann die fortgesetzte Verwendung von NTP beim Training von Aufgaben zu Informationsverlusten und damit zu Trainingsfehlern führen. Daher verwendet diese Studie die Methode der Wiederherstellung des Masken-Tokens, um das Modell zu optimieren Diese Studie versucht, BERT zu verwenden, um das Masken-Token an der i-ten Position der Eingabe an der i-ten Position der Ausgabe wiederherzustellen. Da sich diese Vorhersagemethode jedoch stark von der autoregressiven Vorhersage unterscheidet, die das Modell in der Testphase verwendet hat, wurden nicht die erwarteten Ergebnisse erzielt Die Studie hat die Methode der regressiven Maskenentrauschung übernommen, wie in (a) oben gezeigt: Diese Studie stellt die Eingabe des Maskentokens an der i+1-ten Position am Ausgabeende wieder her. Da außerdem das vorab trainierte Vokabular des kausalen Sprachmodells nicht über das [Masken]-Token verfügt, muss das Modell, wenn während der Feinabstimmungsphase ein neues Token hinzugefügt wird, die Darstellung dieser Bedeutung lernen Daher besteht diese Recherche lediglich darin, ein Platzhalter-Token einzugeben und das Platzhalter-Token bei der Aufmerksamkeitsberechnung zu ignorieren. In dieser Studie wählte jeder Schritt bei der Feinabstimmung von Llama zufällig BICO und gewöhnliches NTP als Trainingsziele mit gleicher Wahrscheinlichkeit aus. Bei der gleichen Feinabstimmung für zehn Epochen ergibt sich für den oben genannten Namensbeschreibungsdatensatz der Leistungsvergleich mit der normalen NTP-Feinabstimmung wie folgt: Es ist ersichtlich, dass die Methode dieser Studie eine gewisse Erleichterung bei der Umkehrung des Fluches bringt. Die Verbesserung der Methode in diesem Artikel zu D2N-Reverse ist im Vergleich zu GLM-ABI sehr gering. Die Forscher vermuten, dass der Grund für dieses Phänomen darin liegt, dass die Namen und entsprechenden Beschreibungen im Datensatz zwar von GPT generiert werden, um die Beeinträchtigung des Tests durch vorab trainierte Daten zu verringern, das vorab trainierte Modell jedoch über eine gewisse Fähigkeit zum gesunden Menschenverstand verfügt B. den Namen der Person zu kennen. Zwischen der Beschreibung und der Beschreibung besteht normalerweise eine Eins-zu-Viele-Beziehung. Für den Namen einer Person kann es viele verschiedene Beschreibungen geben. Daher scheint es eine gewisse Verwirrung zu geben, wenn das Modell umgekehrtes Wissen nutzen und gleichzeitig Wachstumsbeschreibungen generieren muss Darüber hinaus liegt der Schwerpunkt dieses Artikels auf der Untersuchung des Reverse-Curse-Phänomens des Basismodells. Es sind noch weitere Forschungsarbeiten erforderlich, um die Umkehrantwortfähigkeit des Modells in komplexeren Situationen zu bewerten und um festzustellen, ob verstärktes Lernen von Rückmeldungen höherer Ordnung einen Einfluss auf die Umkehrung des Fluches hat. Diese Studie hofft, dass mehr große Modellhersteller Werden und qualifizierte Forscher können die inhärenten Mängel der aktuellen gängigen großen Sprachmodelle eingehend untersuchen und Innovationen bei Trainingsparadigmen entwickeln. Wie die Studie am Ende des Textes schreibt: „Das strikte Training zukünftiger Modelle nach Lehrbuch kann dazu führen, dass wir in eine „Falle der mittleren Intelligenz“ tappen.“ 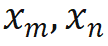 die Eingaben der m- bzw. n-Positionen der aktuellen Ebene sind, ist
die Eingaben der m- bzw. n-Positionen der aktuellen Ebene sind, ist 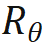 die von RoPE verwendete Rotationsmatrix, die definiert ist als:
die von RoPE verwendete Rotationsmatrix, die definiert ist als: 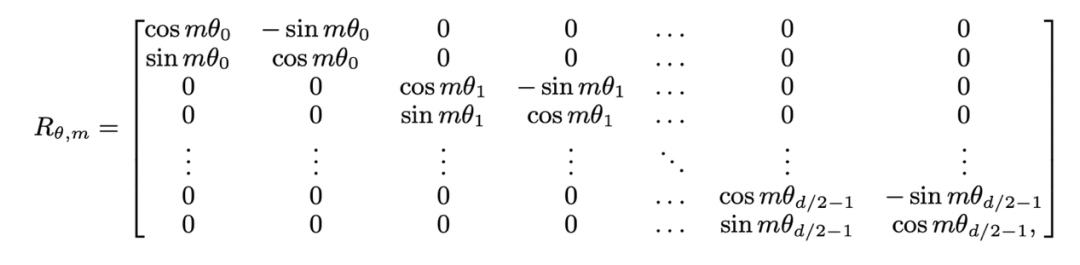
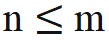 ) mit dem Schlüssel an Position n ausführen muss. Der relative Abstand (n-m) des Abfrageschlüssels bei der Berechnung des inneren Produkts Die obige Formel ist immer nicht positiv. Wenn die Aufmerksamkeitsmaske direkt entfernt wird, führt die Abfrage an Position m ein inneres Produkt mit dem Schlüssel an Position n>m durch, wodurch n-m zu einem positiven Wert wird und Positionsinformationen eingeführt werden, die das Modell enthält nicht gesehen hat.
) mit dem Schlüssel an Position n ausführen muss. Der relative Abstand (n-m) des Abfrageschlüssels bei der Berechnung des inneren Produkts Die obige Formel ist immer nicht positiv. Wenn die Aufmerksamkeitsmaske direkt entfernt wird, führt die Abfrage an Position m ein inneres Produkt mit dem Schlüssel an Position n>m durch, wodurch n-m zu einem positiven Wert wird und Positionsinformationen eingeführt werden, die das Modell enthält nicht gesehen hat. 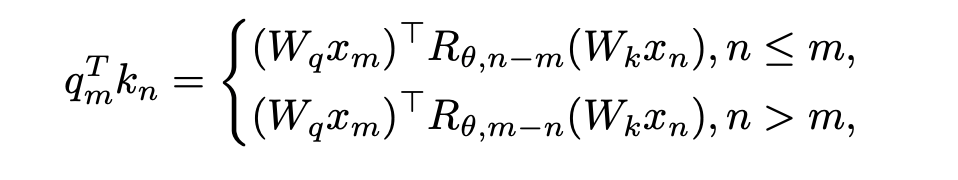
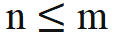 , ist keine Änderung der inneren Produktberechnung erforderlich; wenn n > m, durch Einführung einer neuen Rotationsmatrix
, ist keine Änderung der inneren Produktberechnung erforderlich; wenn n > m, durch Einführung einer neuen Rotationsmatrix 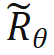 zum Berechnen.
zum Berechnen. 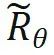 wird erhalten, indem man die Umkehrung aller Sin-Terme in der Rotationsmatrix bildet. Auf diese Weise gibt es
wird erhalten, indem man die Umkehrung aller Sin-Terme in der Rotationsmatrix bildet. Auf diese Weise gibt es 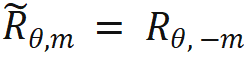 . Wenn dann n > m ist, gibt es:
. Wenn dann n > m ist, gibt es: 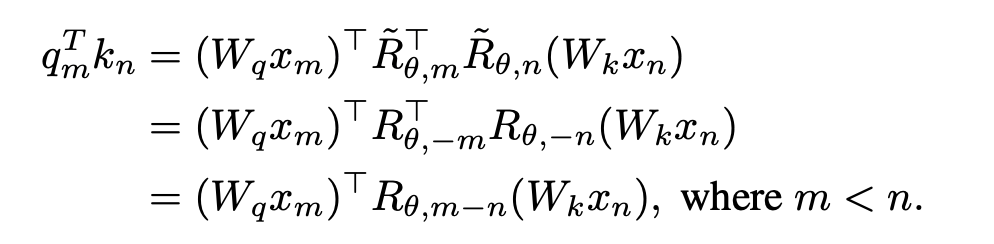
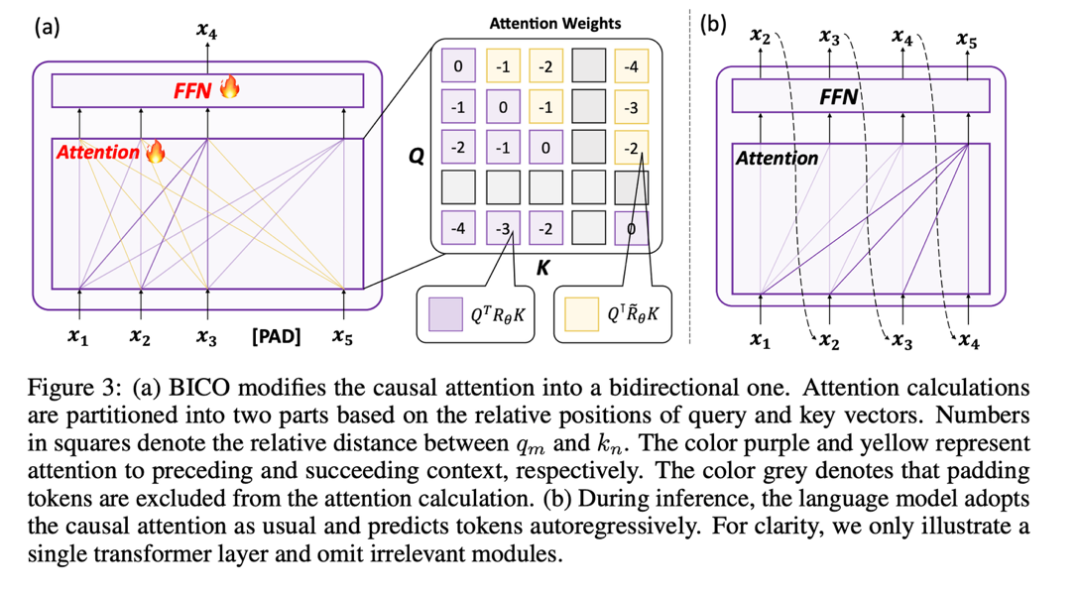
2 Verwenden Sie die Maskendenosierung, um zu trainieren
Einige Gedanken: Derzeit sind die meisten Open-Source-Groß- Skalensprachen Die Modelle folgen alle dem Muster „kausales Sprachmodell + Vorhersage des nächsten Tokens“. Allerdings kann es in diesem Modus ähnlich wie bei „Reverse of the Curse“ zu weiteren potenziellen Problemen kommen. Obwohl diese Probleme derzeit durch zunehmende Modellgröße und Datenvolumen vorübergehend überdeckt werden können, sind sie nicht wirklich verschwunden und bestehen immer noch. Wenn wir auf dem Weg der zunehmenden Modellgröße und des Datenvolumens an die Grenze stoßen, ist es nach Ansicht dieser Studie sehr schwierig, ob dieses „derzeit gut genug“ Modell die menschliche Intelligenz wirklich übertreffen kann
Das obige ist der detaillierte Inhalt vonBei großen Modellen wie GPT und Llama gibt es einen „Umkehrfluch'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
