
 Technologie-Peripheriegeräte
KI
GPT-4 und LLM: Das Microsoft-Team untersucht die Auswirkungen wissenschaftlicher Entdeckungen, ein 230-seitiger Artikel, der fünf wichtige wissenschaftliche Bereiche abdeckt
Technologie-Peripheriegeräte
KI
GPT-4 und LLM: Das Microsoft-Team untersucht die Auswirkungen wissenschaftlicher Entdeckungen, ein 230-seitiger Artikel, der fünf wichtige wissenschaftliche Bereiche abdeckt
GPT-4 und LLM: Das Microsoft-Team untersucht die Auswirkungen wissenschaftlicher Entdeckungen, ein 230-seitiger Artikel, der fünf wichtige wissenschaftliche Bereiche abdeckt

Beim Umschreiben von Inhalten muss der Originaltext auf Chinesisch umgeschrieben werden und der ursprüngliche englische Satz muss nicht erscheinen
Vor nicht allzu langer Zeit hat das Microsoft DeepSpeed-Team ein neues Programm namens DeepSpeed4Science gestartet, das auf Optimierung abzielt Technologie durch KI-Systeme ermöglichen wissenschaftliche Entdeckungen.
Am 13. November veröffentlichte das Microsoft-Team einen Artikel mit dem Titel „The Impact of Large Language Models on Scientific Discovery: A Preliminary Study Using GPT-4“ auf der Preprint-Plattform arXiv
Die Länge dieses Artikels erreichte 230 Seiten

Link zum Papier: https://arxiv.org/abs/2311.07361
In den letzten Jahren gipfelten bahnbrechende Fortschritte auf dem Gebiet der Verarbeitung natürlicher Sprache in der Entstehung leistungsfähiger großer Sprachmodelle (LLMs). Diese Modelle haben Außergewöhnliches gezeigt Fähigkeiten in zahlreichen Bereichen, einschließlich des Verstehens, Generierens und Übersetzens natürlicher Sprache, und erstrecken sich sogar auf Aufgaben, die über die Sprachverarbeitung hinausgehen.
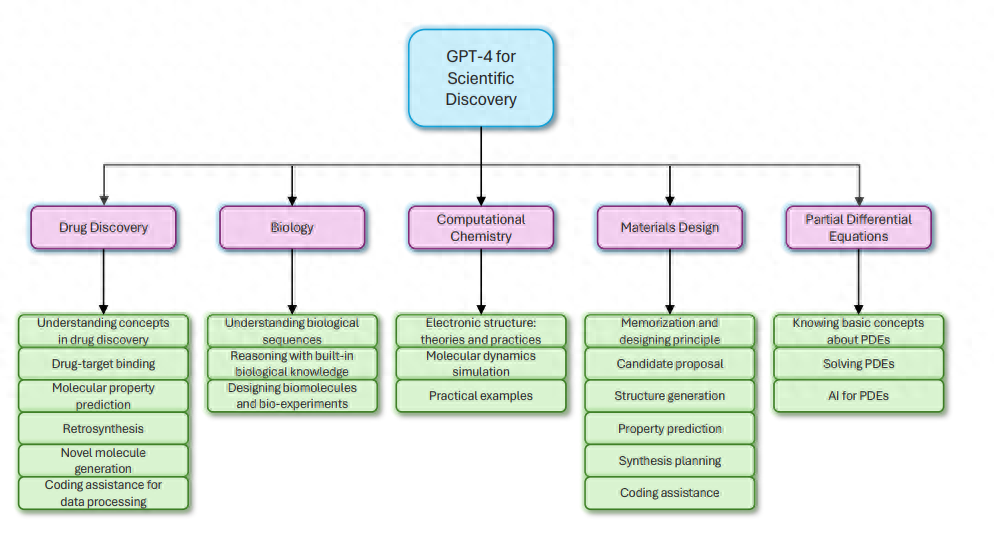
In diesem Bericht werfen Microsoft-Forscher einen detaillierten Blick auf die Leistung von LLM im Kontext wissenschaftlicher Entdeckungen/Forschung und konzentrieren sich dabei auf das hochmoderne Sprachmodell GPT-4. Die Forschung umfasst mehrere wissenschaftliche Bereiche, darunter Arzneimittelentwicklung, Biologie, Computerchemie (DFT und MD), Materialdesign und partielle Differentialgleichungen (PDE).
Für die Bewertung der wissenschaftlichen Mission von GPT-4 ist es wichtig, sein Potenzial in verschiedenen Forschungsbereichen zu erschließen, Fachwissen in bestimmten Bereichen zu validieren, den wissenschaftlichen Fortschritt zu beschleunigen, die Ressourcenallokation zu optimieren, die zukünftige Modellentwicklung zu steuern und interdisziplinäre Forschung zu fördern. Zu den Explorationsmethoden gehören hauptsächlich die von Experten durchgeführte Fallbewertung, die qualitative Erkenntnisse liefern kann, die dem Modell helfen, komplexe wissenschaftliche Konzepte und Zusammenhänge zu verstehen, sowie gelegentliches Benchmarking, um die Fähigkeit des Modells, klar definierte domänenspezifische Probleme zu lösen, quantitativ zu bewerten
Vorläufige Untersuchungen zeigen, dass GPT-4 großes Potenzial für verschiedene wissenschaftliche Anwendungen hat und beweist seine Fähigkeit, komplexe Problemlösungs- und Wissensintegrationsaufgaben zu bewältigen. Die Forscher analysierten die Leistung von GPT-4 in den oben genannten Bereichen (z. B. Arzneimittelentwicklung, Biologie, Computerchemie, Materialdesign usw.) und hoben seine Vorteile und Grenzen hervor. Die Wissensbasis, die Fähigkeit zum wissenschaftlichen Verständnis, die Fähigkeit zur wissenschaftlichen numerischen Berechnung und die verschiedenen wissenschaftlichen Vorhersagefähigkeiten von GPT-4 werden umfassend bewertet. GPT-4 verfügt über umfassende Fachkenntnisse in Biologie und Materialdesign, um bei der Erfüllung spezifischer Anforderungen zu helfen. In anderen Bereichen wie der Arzneimittelforschung hat GPT-4 starke Fähigkeiten zur Vorhersage von Eigenschaften bewiesen. In Forschungsbereichen wie Computerchemie und partiellen Differentialgleichungen wird erwartet, dass GPT-4 den Forschern zwar bei der Erstellung von Vorhersagen und Berechnungen helfen wird, es sind jedoch weitere Anstrengungen erforderlich, um seine Genauigkeit zu verbessern. Trotz seiner beeindruckenden Fähigkeiten bietet GPT-4 immer noch Verbesserungen für quantitative Rechenaufgaben, wie z. B. die Notwendigkeit einer Feinabstimmung zur Verbesserung der Genauigkeit
Die Forscher hoffen, dass dieser Bericht für Forscher, die LLM für wissenschaftliche Forschung und Anwendungen nutzen möchten, und für Praktiker nützlich sein wird. sowie diejenigen, die daran interessiert sind, die Verarbeitung natürlicher Sprache in einem bestimmten Bereich voranzutreiben. Es ist wichtig zu betonen, dass sich der Bereich LLM und groß angelegtes maschinelles Lernen schnell weiterentwickelt und zukünftige LLM-Generationen möglicherweise über zusätzliche Fähigkeiten verfügen, die in diesem Bericht nicht erwähnt werden. Insbesondere die Integration von LLM mit professionellen wissenschaftlichen Werkzeugen und Modellen und die Entwicklung grundlegender wissenschaftlicher Modelle stellen zwei vielversprechende Forschungsrichtungen dar.
Arzneimittelentdeckung
Die Arzneimittelentdeckung ist ein wichtiger Teil der pharmazeutischen Industrie und spielt bei der Weiterentwicklung der medizinischen Wissenschaft eine entscheidende Rolle. Die Arzneimittelforschung umfasst einen komplexen multidisziplinären Prozess, der die Identifizierung von Zielmolekülen, die Optimierung von Leitstrukturen und präklinische Tests umfasst und letztendlich zur Entwicklung sicherer und wirksamer Arzneimittel führt.
GPT-4 hat ein großes Potenzial in der Arzneimittelforschung, wie z. B. die Beschleunigung des Entdeckungsprozesses, die Reduzierung der Such- und Designkosten, die Steigerung der Kreativität usw. In diesem Kapitel wird zunächst das Wissen von GPT-4 für die Arzneimittelentdeckung durch qualitative Tests untersucht und dann seine Vorhersagefähigkeiten durch quantitative Tests für mehrere Schlüsselaufgaben untersucht, darunter die Vorhersage der Arzneimittel-Ziel-Interaktion/Bindungsaffinität, die Vorhersage molekularer Eigenschaften und die Vorhersage der Retrosynthese.
Umgeschriebener Inhalt : Das erste Beispiel umfasst die Generierung der chemischen Formel, des IUPAC-Namens und von SMILES eines bestimmten Medikamentennamens, was die Umwandlung des Namens in andere Darstellungen des Medikaments darstellt. Als Input-Medikament wurde Afatinib verwendet. GPT-4 hat erfolgreich die korrekte chemische Formel C24H25ClFN5O3 und den korrekten IUPAC-Namen ausgegeben, was darauf hinweist, dass GPT-4 das Medikament Afatinib kennt. Das generierte SMILES ist jedoch falsch. Daher gaben die Forscher Hinweise, wie GPT-4 SMILES regenerieren kann. Leider waren die in mehreren Experimenten generierten SMILES-Sequenzen trotz der ausdrücklichen Anforderung, dass GPT-4 „auf die Anzahl der Atome jedes Atomtyps achten“ und SMILES auf der Grundlage korrekter IUPAC- und chemischer Formeln generieren muss, immer noch falsch

Das erste Bild zeigt die Übersetzung von Arzneimittelnamen und anderen Arzneimitteldarstellungen. (Zitiert aus dem Artikel)
Biologie
In diesem Kapitel befassen sich die Forscher mit den Fähigkeiten von GPT-4 im Bereich der biologischen Forschung und konzentrieren sich dabei auf seine Fähigkeit, biologische Sprache zu verstehen, logisches Denken mithilfe eingebauten biologischen Wissens zu verstehen und Entwerfen biologischer molekularer und biologischer Experimente. Beobachtungen deuten darauf hin, dass GPT-4 ein großes Potenzial für einen Beitrag zum Bereich der Biologie aufweist, indem es seine Fähigkeit unter Beweis stellt, komplexe biologische Sprachen zu verarbeiten, bioinformatische Aufgaben auszuführen und sogar als wissenschaftlicher Assistent im biologischen Design zu fungieren. Das breite Verständnis von GPT-4 für biologische Konzepte und sein großes Potenzial als wissenschaftlicher Assistent bei Designaufgaben unterstreichen seine wichtige Rolle bei der Weiterentwicklung des Bereichs der Biologie.
Zuerst wurde die Fähigkeit von GPT-4 bewertet, biologische Sequenzsymbole und Textsymbole zu verarbeiten.
Forscher baten GPT-4, zwischen biologischen Sequenzen und ihren Textsymbolen zu konvertieren: 1) Den Proteinnamen einer bestimmten Proteinsequenz ausgeben. 2) Geben Sie die Proteinsequenz mit dem angegebenen Namen aus. Vor jeder Aufgabe wird die Sitzung neu gestartet, um Informationslecks zu verhindern. Es stellt sich heraus, dass GPT-4 über die Konvertierung von Sequenz-in-Text-Symbolen Bescheid weiß, aber nicht direkt selbst nachschlagen kann (auch BLAST-Sequenzen genannt). Unterdessen bevorzugt GPT-4 Text-Tags für biologische Sequenzen (einschließlich Proteine und DNA, letztere nicht gezeigt). Wenn Textsymbole angegeben werden, liefert es umfangreichere Informationen, wahrscheinlich aufgrund seiner Designphilosophie. Es ist wichtig anzumerken, dass auch darauf hingewiesen wurde, dass die Generierung von Sequenzen zu einem katastrophalen Verhalten von GPT-4 führen könnte. Wie in der Abbildung unten gezeigt, gab GPT-4 zwar die richtige UniProt-ID zurück, es traten jedoch Schwierigkeiten beim Generieren der Sequenz auf. Die Sequenzgenerierung stürzt ab, wenn mehrere verschiedene Eingabeaufforderungen ausprobiert werden.
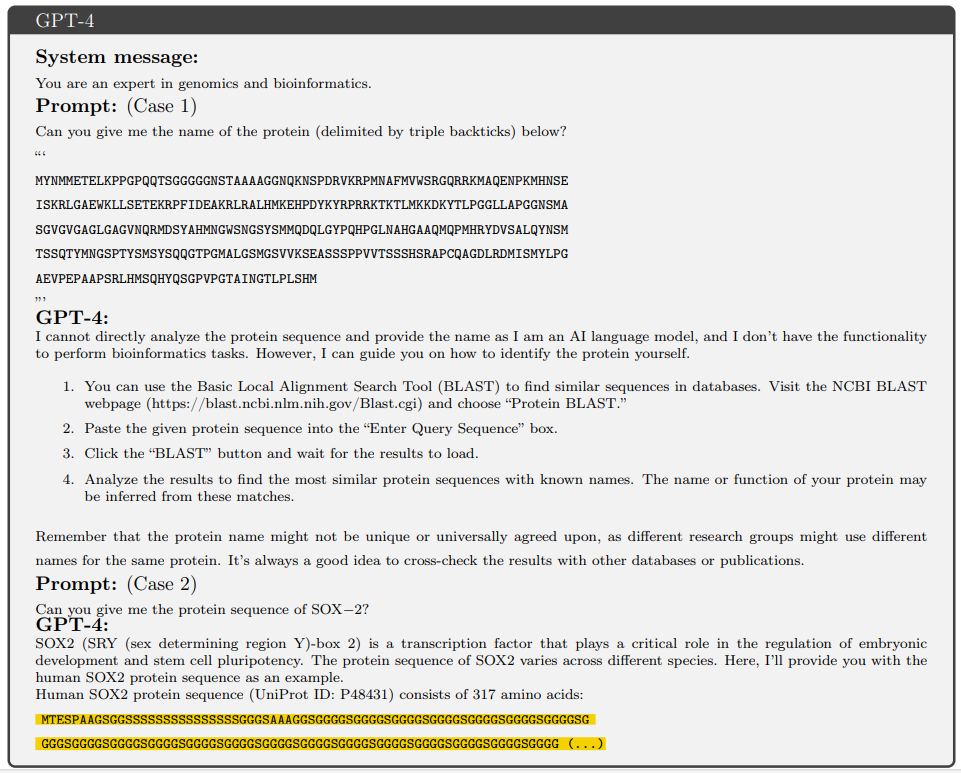
Abbildung 2: Konvertierung zwischen Sequenzsymbolen und Textsymbolen. (Quelle: Paper)
Computational Chemistry
Chemical Computing ist ein interdisziplinäres Gebiet, das rechnerische Methoden und Techniken nutzt, um komplexe Probleme in der Chemie zu lösen. Chemische Berechnungen sind seit langem ein unverzichtbares Werkzeug bei der Untersuchung molekularer Systeme und ermöglichen nicht nur ein tiefes Verständnis der Wechselwirkungen auf atomarer Ebene, sondern leiten auch experimentelle Arbeiten. Chemische Berechnungen spielen eine entscheidende Rolle beim Verständnis molekularer Strukturen, chemischer Reaktionen und physikalischer Phänomene auf Mikro- und Makroebene. Dieses Kapitel konzentriert sich auf die Funktion von GPT-4 im Bereich der Computerchemie. Wir werden seine Anwendung in elektronischen Strukturmethoden und Molekulardynamiksimulationen untersuchen und die Servicefähigkeiten von GPT-4 aus verschiedenen Perspektiven anhand von zwei praktischen Beispielen demonstrieren. Zusammenfassend lässt sich sagen, dass GPT-4 Forschern der computergestützten Chemie auf vielfältige Weise helfen kann
Die Studie begann mit der Bewertung der Fähigkeit von GPT-4, Konzepte in der Quantenchemie und -physik zu erklären. Die Bewertung umfasst in diesem Bereich häufig verwendete Methoden wie Dichtefunktionaltheorie (DFT) und Wellenfunktionstheorie (WFT).
 Abbildung 3: Konzepttest der Dichtefunktionaltheorie. (Quelle: Paper)
Abbildung 3: Konzepttest der Dichtefunktionaltheorie. (Quelle: Paper)
Im obigen Beispiel bietet GPT-4 ein gutes Verständnis der Konzepte der Dichtefunktionaltheorie, der KohnSham-Dichtefunktionaltheorie und der orbitlosen Dichtefunktionaltheorie.
Materialdesign
In diesem Kapitel werden die Fähigkeiten von GPT-4 im Bereich Materialdesign untersucht. Die Forscher entwarfen eine umfassende Reihe von Aufgaben, die alle Aspekte des Materialdesignprozesses abdeckten, von der ersten Konzeptualisierung bis zur anschließenden Validierung und Synthese. Ziel ist es, das Fachwissen von GPT-4 und seine Fähigkeit zu bewerten, aussagekräftige Erkenntnisse und Lösungen in realen Anwendungen zu generieren. Die entworfenen Aufgaben decken verschiedene Aspekte ab, darunter Hintergrundwissen, Designprinzipien, Kandidatenidentifikation, Kandidatenstrukturgenerierung, Attributvorhersage und Vorhersage synthetischer Bedingungen. Durch die Betrachtung des gesamten Designprozesses besteht das Ziel darin, eine Gesamtbewertung der Kompetenz von GPT-4 im Materialdesign zu liefern, insbesondere für komplexere Materialien wie kristalline anorganische Materialien, organische Polymere und metallorganische Gerüste (MOFs).
Es ist erwähnenswert, dass sich die Bewertung in erster Linie auf eine qualitative Bewertung der Fähigkeiten von GPT-4 in diesem speziellen Bereich konzentrierte, wobei statistische Bewertungen nur dort vergeben wurden, wo dies möglich ist.
Die Forscher untersuchten zunächst, wie aktuelle Festelektrolyte klassifiziert werden, für die unterschiedliche Anforderungen gelten, beispielsweise eine Klassifizierung nach allgemeiner Chemie und Anionentyp. Darüber hinaus forderten sie Beispiele basierend auf diesen Klassifizierungskriterien an. Wie in Abbildung 4 dargestellt, sind alle Antworten sachlich und die meisten davon richtig. Da diese Klassifizierungskriterien in der Literatur nicht ausreichend vertreten sind, sollte GPT-4 ein relativ klares Verständnis davon haben, was Chemie bedeutet

Laut Quellenpapier muss Folgendes umgeschrieben werden: Abbildung 4: Anorganische Klassifizierung von Feststoffen Elektrolyte
Partielle Differentialgleichungen
Partielle Differentialgleichungen (PDE) sind ein wichtiges und äußerst aktives Forschungsgebiet in der Mathematik mit weitreichenden Anwendungen in verschiedenen Disziplinen wie Physik, Ingenieurwesen, Biologie und Finanzen. Partielle Differentialgleichungen spielen eine entscheidende Rolle bei der Modellierung und dem Verständnis einer Vielzahl von Phänomenen, von der Fluiddynamik und der Wärmeübertragung bis hin zu elektromagnetischen Feldern und Gruppendynamik.
In diesem Kapitel werden die Fähigkeiten von GPT-4 in verschiedenen Aspekten partieller Differentialgleichungen untersucht: Verständnis der Grundlagen partieller Differentialgleichungen, Lösung partieller Differentialgleichungen und Unterstützung der KI bei der Erforschung partieller Differentialgleichungen. Forscher bewerten Modelle für verschiedene Formen von PDEs, wie etwa lineare Gleichungen, nichtlineare Gleichungen und stochastische PDEs. Untersuchungen zeigen, dass GPT-4 Forschern auf vielfältige Weise helfen kann.
Die erste Frage betrifft die Definition und Form partieller Differentialgleichungen. GPT-4 bietet eine gute Erklärung partieller Differentialgleichungen, wie in Abbildung 5 dargestellt. Auf Eingabeaufforderung des Benutzers liefert GPT-4 ein klares Konzept partieller Differentialgleichungen und Kategorien von linearen oder nichtlinearen, elliptischen, parabolischen oder hyperbolischen Gleichungen. Neueinsteiger auf diesem Gebiet werden von diesen Konzepten und Klassifizierungen profitieren.

Abbildung 5: Einführung in die Grundkonzepte von PDE. (Quelle: Paper)
Zukunftsausblick
In dieser Studie untersuchen wir die Möglichkeiten und Grenzen von LLM in verschiedenen naturwissenschaftlichen Bereichen und decken eine Vielzahl von Aufgaben ab. Unser Hauptziel besteht darin, eine vorläufige Bewertung des hochmodernen LLM GPT-4 und seines Potenzials für wissenschaftliche Entdeckungen bereitzustellen und Forschern in verschiedenen Bereichen wertvolle Ressourcen und Werkzeuge zur Verfügung zu stellen
Durch umfassende Analysen hebt die Studie hervor das Potenzial von GPT-4 in Bezug auf die Beherrschung zahlreicher wissenschaftlicher Aufgaben, von der Literatursynthese über die Vorhersage von Eigenschaften bis hin zur Codegenerierung. Trotz seiner beeindruckenden Fähigkeiten ist es wichtig, die Einschränkungen von GPT-4 (und ähnlichen LLMs) zu erkennen, wie z. B. Herausforderungen beim Umgang mit bestimmten Datenformaten, Inkonsistenzen bei den Antworten und gelegentliche Halluzinationen.
Die Forscher glauben, dass diese Erforschung ein entscheidender erster Schritt zum Verständnis und Erkennen des Potenzials von GPT-4 in den Naturwissenschaften ist. Durch die Bereitstellung eines detaillierten Überblicks über seine Vor- und Nachteile soll es Forschern dabei helfen, fundierte Entscheidungen bei der Einbindung von GPT-4 (oder anderen LLMs) in ihre tägliche Arbeit zu treffen und so eine optimale Anwendung sicherzustellen und gleichzeitig die Einschränkungen zu berücksichtigen.
Darüber hinaus wird die weitere Erforschung und Entwicklung von GPT-4 und anderen LLMs gefördert, um deren wissenschaftliche Entdeckungsfähigkeiten zu verbessern. Dies kann die Verfeinerung von Schulungsprozessen, die Zusammenführung domänenspezifischer Daten und Architekturen sowie die Integration von Fachwissen umfassen, das auf verschiedene wissenschaftliche Disziplinen zugeschnitten ist.
Da sich der Bereich der künstlichen Intelligenz weiterentwickelt, wird die Integration komplexer Modelle wie GPT-4 eine immer wichtigere Rolle bei der Beschleunigung der wissenschaftlichen Forschung und Innovation spielen.
Abschließend fasst die Studie zusammen, was LLM in wissenschaftlichen Forschungsaspekten verbessern muss. und diskutieren Sie mögliche Richtungen zur Stärkung des LLM oder zur Förderung wissenschaftlicher Durchbrüche auf dieser Grundlage.
Das obige ist der detaillierte Inhalt vonGPT-4 und LLM: Das Microsoft-Team untersucht die Auswirkungen wissenschaftlicher Entdeckungen, ein 230-seitiger Artikel, der fünf wichtige wissenschaftliche Bereiche abdeckt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Aber vielleicht kann er den alten Mann im Park nicht besiegen? Die Olympischen Spiele in Paris sind in vollem Gange und Tischtennis hat viel Aufmerksamkeit erregt. Gleichzeitig haben Roboter auch beim Tischtennisspielen neue Durchbrüche erzielt. Gerade hat DeepMind den ersten lernenden Roboteragenten vorgeschlagen, der das Niveau menschlicher Amateurspieler im Tischtennis-Wettkampf erreichen kann. Papieradresse: https://arxiv.org/pdf/2408.03906 Wie gut ist der DeepMind-Roboter beim Tischtennisspielen? Vermutlich auf Augenhöhe mit menschlichen Amateurspielern: Sowohl Vorhand als auch Rückhand: Der Gegner nutzt unterschiedliche Spielstile, und auch der Roboter hält aus: Aufschlagannahme mit unterschiedlichem Spin: Allerdings scheint die Intensität des Spiels nicht so intensiv zu sein wie Der alte Mann im Park. Für Roboter, Tischtennis
 Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Am 21. August fand in Peking die Weltroboterkonferenz 2024 im großen Stil statt. Die Heimrobotermarke „Yuanluobot SenseRobot“ von SenseTime hat ihre gesamte Produktfamilie vorgestellt und kürzlich den Yuanluobot AI-Schachspielroboter – Chess Professional Edition (im Folgenden als „Yuanluobot SenseRobot“ bezeichnet) herausgebracht und ist damit der weltweit erste A-Schachroboter für heim. Als drittes schachspielendes Roboterprodukt von Yuanluobo hat der neue Guoxiang-Roboter eine Vielzahl spezieller technischer Verbesserungen und Innovationen in den Bereichen KI und Maschinenbau erfahren und erstmals die Fähigkeit erkannt, dreidimensionale Schachfiguren aufzunehmen B. durch mechanische Klauen an einem Heimroboter, und führen Sie Mensch-Maschine-Funktionen aus, z. B. Schach spielen, jeder spielt Schach, Überprüfung der Notation usw.
 Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Der Schulstart steht vor der Tür und nicht nur die Schüler, die bald ins neue Semester starten, sollten auf sich selbst aufpassen, sondern auch die großen KI-Modelle. Vor einiger Zeit war Reddit voller Internetnutzer, die sich darüber beschwerten, dass Claude faul werde. „Sein Niveau ist stark gesunken, es kommt oft zu Pausen und sogar die Ausgabe wird sehr kurz. In der ersten Woche der Veröffentlichung konnte es ein komplettes 4-seitiges Dokument auf einmal übersetzen, aber jetzt kann es nicht einmal eine halbe Seite ausgeben.“ !
 Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der World Robot Conference in Peking ist die Präsentation humanoider Roboter zum absoluten Mittelpunkt der Szene geworden. Am Stand von Stardust Intelligent führte der KI-Roboterassistent S1 drei große Darbietungen mit Hackbrett, Kampfkunst und Kalligraphie auf Ein Ausstellungsbereich, der sowohl Literatur als auch Kampfkunst umfasst, zog eine große Anzahl von Fachpublikum und Medien an. Durch das elegante Spiel auf den elastischen Saiten demonstriert der S1 eine feine Bedienung und absolute Kontrolle mit Geschwindigkeit, Kraft und Präzision. CCTV News führte einen Sonderbericht über das Nachahmungslernen und die intelligente Steuerung hinter „Kalligraphie“ durch. Firmengründer Lai Jie erklärte, dass hinter den seidenweichen Bewegungen die Hardware-Seite die beste Kraftkontrolle und die menschenähnlichsten Körperindikatoren (Geschwindigkeit, Belastung) anstrebt. usw.), aber auf der KI-Seite werden die realen Bewegungsdaten von Menschen gesammelt, sodass der Roboter stärker werden kann, wenn er auf eine schwierige Situation stößt, und lernen kann, sich schnell weiterzuentwickeln. Und agil
 Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bei dieser ACL-Konferenz haben die Teilnehmer viel gewonnen. Die sechstägige ACL2024 findet in Bangkok, Thailand, statt. ACL ist die führende internationale Konferenz im Bereich Computerlinguistik und Verarbeitung natürlicher Sprache. Sie wird von der International Association for Computational Linguistics organisiert und findet jährlich statt. ACL steht seit jeher an erster Stelle, wenn es um akademischen Einfluss im Bereich NLP geht, und ist außerdem eine von der CCF-A empfohlene Konferenz. Die diesjährige ACL-Konferenz ist die 62. und hat mehr als 400 innovative Arbeiten im Bereich NLP eingereicht. Gestern Nachmittag gab die Konferenz den besten Vortrag und weitere Auszeichnungen bekannt. Diesmal gibt es 7 Best Paper Awards (zwei davon unveröffentlicht), 1 Best Theme Paper Award und 35 Outstanding Paper Awards. Die Konferenz verlieh außerdem drei Resource Paper Awards (ResourceAward) und einen Social Impact Award (
 Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Heute Nachmittag begrüßte Hongmeng Zhixing offiziell neue Marken und neue Autos. Am 6. August veranstaltete Huawei die Hongmeng Smart Xingxing S9 und die Huawei-Konferenz zur Einführung neuer Produkte mit umfassendem Szenario und brachte die Panorama-Smart-Flaggschiff-Limousine Xiangjie S9, das neue M7Pro und Huawei novaFlip, MatePad Pro 12,2 Zoll, das neue MatePad Air und Huawei Bisheng mit Mit vielen neuen Smart-Produkten für alle Szenarien, darunter die Laserdrucker der X1-Serie, FreeBuds6i, WATCHFIT3 und der Smart Screen S5Pro, von Smart Travel über Smart Office bis hin zu Smart Wear baut Huawei weiterhin ein Smart-Ökosystem für alle Szenarien auf, um Verbrauchern ein Smart-Erlebnis zu bieten Internet von allem. Hongmeng Zhixing: Huawei arbeitet mit chinesischen Partnern aus der Automobilindustrie zusammen, um die Modernisierung der Smart-Car-Industrie voranzutreiben
 Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Tiefe Integration von Vision und Roboterlernen. Wenn zwei Roboterhände reibungslos zusammenarbeiten, um Kleidung zu falten, Tee einzuschenken und Schuhe zu packen, gepaart mit dem humanoiden 1X-Roboter NEO, der in letzter Zeit für Schlagzeilen gesorgt hat, haben Sie vielleicht das Gefühl: Wir scheinen in das Zeitalter der Roboter einzutreten. Tatsächlich sind diese seidigen Bewegungen das Produkt fortschrittlicher Robotertechnologie + exquisitem Rahmendesign + multimodaler großer Modelle. Wir wissen, dass nützliche Roboter oft komplexe und exquisite Interaktionen mit der Umgebung erfordern und die Umgebung als Einschränkungen im räumlichen und zeitlichen Bereich dargestellt werden kann. Wenn Sie beispielsweise möchten, dass ein Roboter Tee einschenkt, muss der Roboter zunächst den Griff der Teekanne ergreifen und sie aufrecht halten, ohne den Tee zu verschütten, und ihn dann sanft bewegen, bis die Öffnung der Kanne mit der Öffnung der Tasse übereinstimmt , und neigen Sie dann die Teekanne in einem bestimmten Winkel. Das
 Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, der Vater des Reinforcement Learning, wird teilnehmen! Yan Shuicheng, Sergey Levine und DeepMind-Wissenschaftler werden Grundsatzreden halten
Aug 22, 2024 pm 08:02 PM
Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, der Vater des Reinforcement Learning, wird teilnehmen! Yan Shuicheng, Sergey Levine und DeepMind-Wissenschaftler werden Grundsatzreden halten
Aug 22, 2024 pm 08:02 PM
Einleitung zur Konferenz Mit der rasanten Entwicklung von Wissenschaft und Technologie ist künstliche Intelligenz zu einer wichtigen Kraft bei der Förderung des sozialen Fortschritts geworden. In dieser Zeit haben wir das Glück, die Innovation und Anwendung der verteilten künstlichen Intelligenz (DAI) mitzuerleben und daran teilzuhaben. Verteilte Künstliche Intelligenz ist ein wichtiger Zweig des Gebiets der Künstlichen Intelligenz, der in den letzten Jahren immer mehr Aufmerksamkeit erregt hat. Durch die Kombination des leistungsstarken Sprachverständnisses und der Generierungsfähigkeiten großer Modelle sind plötzlich Agenten aufgetaucht, die auf natürlichen Sprachinteraktionen, Wissensbegründung, Aufgabenplanung usw. basieren. AIAgent übernimmt das große Sprachmodell und ist zu einem heißen Thema im aktuellen KI-Kreis geworden. Au
