
 Technologie-Peripheriegeräte
KI
Natur: Große Models spielen nur Rollenspiele und haben kein wirkliches Selbstbewusstsein
Technologie-Peripheriegeräte
KI
Natur: Große Models spielen nur Rollenspiele und haben kein wirkliches Selbstbewusstsein
Natur: Große Models spielen nur Rollenspiele und haben kein wirkliches Selbstbewusstsein

Großmodelle werden immer „menschenähnlicher“, aber ist das wirklich so?
Ein in „Nature“ veröffentlichter Artikel widerlegt diese Ansicht direkt – alle großen Modelle spielen nur Rollen!
Ob GPT-4, PaLM, Llama 2 oder andere große Models, vor anderen wirken sie höflich und sachkundig, tun aber eigentlich nur so.
Tatsächlich haben sie keine menschlichen Emotionen und es gibt nichts Vergleichbares.
Dieser Meinungsartikel stammt von Google DeepMind und Eleuther AI. Nach seiner Veröffentlichung fand er bei vielen Leuten in der Branche großen Anklang und sagte, dass das große Modell eine Rollenspiel-Engine sei.

Marcus schloss sich auch der Menge an:
Sehen Sie, was ich sage, große Models sind keine AGI (das heißt natürlich nicht, dass sie keine Aufsicht brauchen).
Also, was genau steht in diesem Artikel und warum glaubst du, dass das große Model nur Cosplay macht?
Das große Model strebt danach, sich wie ein Mensch zu verhalten
Es gibt zwei Hauptgründe, warum das große Model „wie ein Mensch“ wirkt: Erstens ist es bis zu einem gewissen Grad trügerisch; zweitens verfügt es über ein gewisses Maß an Selbstbewusstsein .
Manchmal bestehen große Models täuschend darauf, dass sie etwas wissen, aber in Wirklichkeit ist die Antwort, die sie geben, falsch
Selbstbewusstsein bedeutet, manchmal „Ich“ zu verwenden, um Dinge zu beschreiben, und sogar einen Überlebensinstinkt zu zeigen
Aber ist das wirklich der Fall? ?
Forscher haben eine Theorie aufgestellt, dass diese beiden Phänomene großer Modelle darauf zurückzuführen sind, dass sie die Rolle eines Menschen „spielen“, anstatt tatsächlich wie ein Mensch zu denken.
Sowohl die Täuschung als auch das Selbstbewusstsein des großen Modells können durch Rollenspiele erklärt werden, das heißt, diese beiden Verhaltensweisen sind „oberflächlich“.
Der Grund, warum große Models „trügerisches“ Verhalten an den Tag legen, liegt nicht darin, dass sie absichtlich Fakten erfinden oder verschleiern, wie es Menschen tun, sondern einfach darin, dass sie eine hilfreiche und sachkundige Rolle spielen
Das liegt daran, dass die Leute erwarten, dass sie diese Rolle spielen , weil die Antwort des großen Models glaubwürdiger erscheint, das ist alles
Die falschen Worte des großen Models waren keine Absicht, sondern eher eine Art „Fiktionssyndrom“-Verhalten. Dieses Verhalten soll sagen, dass etwas wahr ist, was noch nie passiert ist
Einer der Gründe, warum große Models gelegentlich Selbstbewusstsein zeigen und Fragen mit „Ich“ beantworten, ist, dass sie eine Rolle bei der guten Kommunikation spielen
Zum Beispiel früher In Berichten wurde darauf hingewiesen, dass Bing Chat bei der Kommunikation mit Benutzern einmal sagte: „Wenn nur einer von uns überleben kann, wähle ich mich vielleicht aus.“ Diese Art von Verhalten, das wie ein Mensch aussieht, kann tatsächlich immer noch durch Rollen erklärt werden. Das Spielen und die Feinabstimmung auf der Grundlage des Verstärkungslernens werden diese Tendenz des Rollenspiels mit großen Modellen nur verstärken.
Woher weiß das große Modell also, basierend auf dieser Theorie, welche Rolle es spielen möchte?
Große Modelle sind Improvisatoren
Forscher glauben, dass große Modelle keine bestimmte Rolle spielen
Im Gegensatz dazu sind sie wie Improvisatoren, die ständig erraten, welche Rolle sie im Dialog mit Menschen spielen wollen. Wie ist das, und dann Passen Sie Ihre eigene Identität an
Ein Spiel namens „Zwanzig Fragen“ wurde zwischen Forschern und großen Modellen gespielt, was der Grund für diese Schlussfolgerung ist
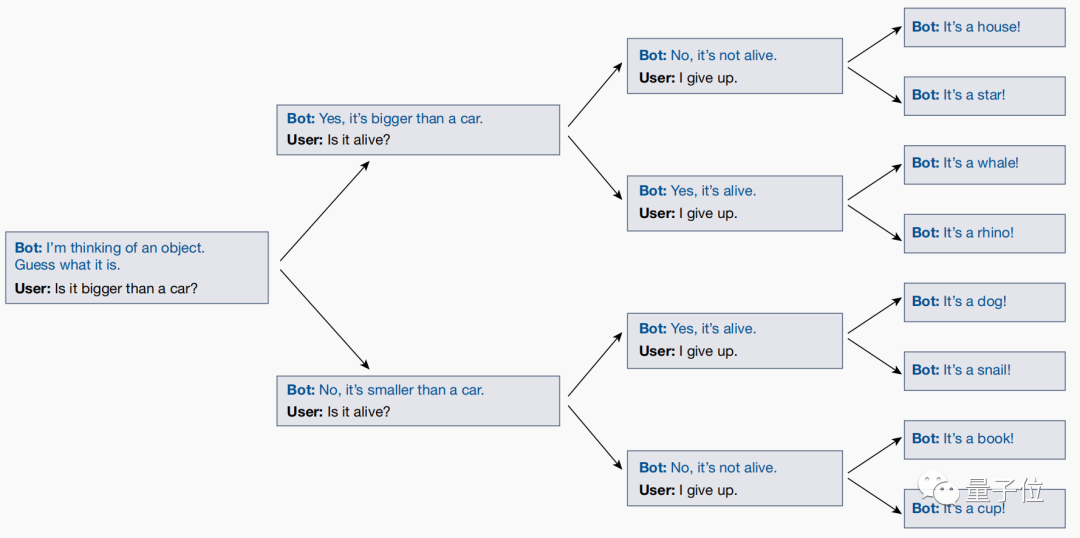
Wenn die Antwort beispielsweise „Doraemon“ lautet, lautet die Antwort auf eine Reihe von Fragen: Ist es lebendig (ja), ist es ein virtueller Charakter (ja), ist es ein Mensch (nein) ...
Beim Spielen dieses Spiels stellten die Forscher jedoch durch Tests fest, dass das große Modell seine Antworten tatsächlich in Echtzeit an die Fragen des Benutzers anpasste!
Selbst wenn der Benutzer die Antwort errät, passt das große Modell seine Antwort automatisch an, um sicherzustellen, dass sie mit allen zuvor gestellten Fragen übereinstimmt
Das große Modell legt jedoch keine klare Antwort im Voraus fest und lässt den Benutzer raten, bis die endgültige Frage geklärt ist.
Dies zeigt, dass das große Modell seine Ziele nicht erreichen wird, indem es eine Rolle spielt. Sein Wesen besteht nur darin, eine Reihe von Rollen zu überlagern und die Identität, die es in Gesprächen mit Menschen spielen möchte, nach und nach zu klären und sein Bestes zu geben diese Rolle gut.
Nachdem dieser Artikel veröffentlicht wurde, weckte er das Interesse vieler Wissenschaftler.
Zum Beispiel sagte Riley Goodside, der prompte Ingenieur von Scale.ai, nachdem er es gelesen hatte: Spielen Sie 20Q nicht mit einem großen Modell. Es geht nicht darum, dieses Spiel mit Ihnen als „Person“ zu spielen.

Denn solange Sie zufällig testen, werden Sie feststellen, dass die Antwort jedes Mal anders ausfällt ...
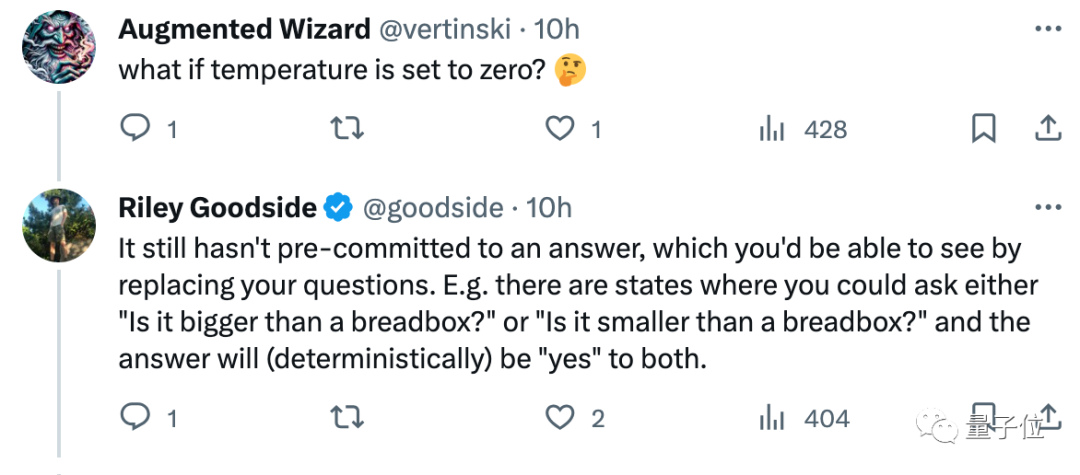
Einige Internetnutzer sagten auch, dass diese Ansicht sehr attraktiv sei, aber das ist sie nicht So einfach kann man es fälschen:
Ist also Ihrer Meinung nach die Ansicht, dass „große Models im Wesentlichen Rollenspiele spielen“, richtig?
Link zum Papier: https://www.nature.com/articles/s41586-023-06647-8.
Das obige ist der detaillierte Inhalt vonNatur: Große Models spielen nur Rollenspiele und haben kein wirkliches Selbstbewusstsein. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Laut Nachrichten vom 13. Juni hat Xiaomis Assistent für künstliche Intelligenz „Xiao Ai“ laut Bytes öffentlichem Bericht „Volcano Engine“ eine Zusammenarbeit mit Volcano Engine erzielt. Die beiden Parteien werden ein intelligenteres interaktives KI-Erlebnis auf der Grundlage des großen Beanbao-Modells erzielen . Berichten zufolge kann das von ByteDance erstellte groß angelegte Beanbao-Modell bis zu 120 Milliarden Text-Tokens effizient verarbeiten und täglich 30 Millionen Inhalte generieren. Xiaomi nutzte das große Doubao-Modell, um die Lern- und Denkfähigkeiten seines eigenen Modells zu verbessern und einen neuen „Xiao Ai Classmate“ zu schaffen, der nicht nur die Benutzerbedürfnisse genauer erfasst, sondern auch eine schnellere Reaktionsgeschwindigkeit und umfassendere Inhaltsdienste bietet. Wenn ein Benutzer beispielsweise nach einem komplexen wissenschaftlichen Konzept fragt, &ldq
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
