
 Technologie-Peripheriegeräte
KI
Jensen Huang, CEO von NVIDIA: Die Welle der künstlichen Intelligenz zeichnet sich ab und die Branche läutet einen neuen Ausgangspunkt ein
Technologie-Peripheriegeräte
KI
Jensen Huang, CEO von NVIDIA: Die Welle der künstlichen Intelligenz zeichnet sich ab und die Branche läutet einen neuen Ausgangspunkt ein
Jensen Huang, CEO von NVIDIA: Die Welle der künstlichen Intelligenz zeichnet sich ab und die Branche läutet einen neuen Ausgangspunkt ein

[CNMO News] Der Inhalt, der kürzlich neu geschrieben werden muss, lautet: Jensen Huang, CEO von NVIDIA, sagte, dass die Welt am Anfang der Welle der künstlichen Intelligenz (KI) stehe, und er sei zuversichtlich. Er geht davon aus, dass die Wachstumsdynamik von Rechenzentren bis ins Jahr 2025 anhalten wird, und betonte, dass das Unternehmen seine Chip-Lieferkette erweitert, um dieser wachsenden Nachfrage gerecht zu werden.

Huang Renxun
Laut CNMO-Berichten äußerte Huang Jenxun im Mai dieses Jahres in einer Universitätsrede seine Ansichten zur künstlichen Intelligenz. Er sagte, dass künstliche Intelligenz große Chancen für Unternehmen mit sich bringt, die ihre Wettbewerbsfähigkeit schnell anpassen und nutzen können, während Unternehmen, die künstliche Intelligenz nicht sinnvoll nutzen, mit dem Niedergang rechnen müssen. Er vergleicht die aktuelle Situation mit den frühen Stadien von Personalcomputern, Netzwerken, mobilen Geräten und Cloud-Technologie, glaubt jedoch, dass die Auswirkungen der künstlichen Intelligenz grundlegender sind und dass jede Ebene der Datenverarbeitung neu geschrieben wird

Der Inhalt, der neu geschrieben werden muss, ist: NVIDIA
Huang Renxun wies darauf hin, dass künstliche Intelligenz die Art und Weise, wie wir Software schreiben und ausführen, verändert hat und in jeder Hinsicht eine Chance zur Erneuerung der Computerindustrie darstellt. Er prognostiziert, dass die Industrie in den nächsten zehn Jahren neue Computer mit künstlicher Intelligenz einsetzen wird, um traditionelle Computer im Wert von Billionen Dollar zu ersetzen
Huang Jen-Hsuns Ansichten spiegeln den Optimismus der Technologiebranche hinsichtlich der Zukunft der KI wider und offenbaren das enorme Potenzial und den Einfluss der KI. Mit der Entwicklung der Technologie wird die Anwendung von KI immer weiter verbreitet. Von selbstfahrenden Autos über intelligente Häuser bis hin zu medizinischen Diagnosen und Finanztransaktionen nimmt der Einfluss von KI ständig zu. Dies bringt natürlich auch einige Herausforderungen mit sich, darunter die Frage, wie die Sicherheit und Fairness der KI gewährleistet werden kann und wie mit den daraus resultierenden Beschäftigungsproblemen umgegangen werden soll.Das obige ist der detaillierte Inhalt vonJensen Huang, CEO von NVIDIA: Die Welle der künstlichen Intelligenz zeichnet sich ab und die Branche läutet einen neuen Ausgangspunkt ein. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Die Veröffentlichung der Xiaomi Mi Watch S4 Sport mit einem einteiligen Titangehäuse wurde offiziell für den 19. Juli angekündigt
Jul 18, 2024 am 12:52 AM
Die Veröffentlichung der Xiaomi Mi Watch S4 Sport mit einem einteiligen Titangehäuse wurde offiziell für den 19. Juli angekündigt
Jul 18, 2024 am 12:52 AM
Am 16. Juli gab Lei Jun, CEO von Xiaomi, eine Ankündigung heraus: Am 19. Juli, diesen Freitagabend, um 19 Uhr werde ich die 5. „Lei Jun-Jahresvorlesung“ zum Thema „Mut“ halten und über die Besonderheiten des Bauens sprechen ein Auto und das. Eine Geschichte von mehr als drei Jahren voller Höhen und Tiefen. Anschließend begannen die Xiaomi-Beamten, viele neue Produkte aufzuwärmen. Laut CNMO wird Xiaomis erste professionelle Sport-Smartwatch, S4Sport, ebenfalls am 19. Juli offiziell veröffentlicht. Die Xiaomi Mi Watch S4Sport wurde am 19. Juli offiziell angekündigt. Laut der offiziellen Einführung hat die Xiaomi Mi Watch S4Sport bahnbrechende Designinnovationen vorgenommen: Das einteilige Titangehäuse mit Saphirglasmaterialien auf der Vorder- und Rückseite gewährleistet nicht nur die Haltbarkeit der Uhr, sondern verleiht ihr auch eine hochwertige Textur und Optik
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
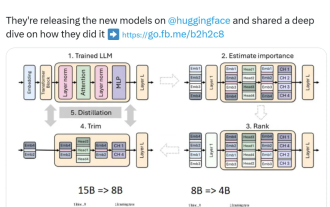 Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Aug 16, 2024 pm 04:42 PM
Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Aug 16, 2024 pm 04:42 PM
Der Aufstieg kleiner Modelle. Letzten Monat veröffentlichte Meta die Modellreihe Llama3.1, zu der das bisher größte Modell von Meta, das 405B-Modell, und zwei kleinere Modelle mit Parameterbeträgen von 70 Milliarden bzw. 8 Milliarden gehören. Llama3.1 gilt als der Beginn einer neuen Ära von Open Source. Obwohl die Modelle der neuen Generation leistungsstark sind, erfordern sie bei der Bereitstellung immer noch große Mengen an Rechenressourcen. Daher hat sich in der Branche ein weiterer Trend herausgebildet, der darin besteht, kleine Sprachmodelle (SLM) zu entwickeln, die bei vielen Sprachaufgaben eine ausreichende Leistung erbringen und zudem sehr kostengünstig in der Bereitstellung sind. Kürzlich haben Untersuchungen von NVIDIA gezeigt, dass durch strukturierte Gewichtsbereinigung in Kombination mit Wissensdestillation nach und nach kleinere Sprachmodelle aus einem zunächst größeren Modell gewonnen werden können. Turing-Preisträger, Meta Chief A
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
