

Stabile Videoverbreitung ist da, Codegewicht ist online

Stability AI, ein bekanntes KI-Zeichenunternehmen, ist endlich in die KI-generierte Videobranche eingestiegen.
Diesen Dienstag wurde Stable Video Diffusion, ein auf stabiler Diffusion basierendes Videogenerierungsmodell, eingeführt, und die KI-Community startete sofort eine Diskussion
Viele Leute sagten: „Wir haben endlich gewartet.“
Projektlink: https://github.com/Stability-AI/generative-models
Jetzt können Sie vorhandene statische Bilder verwenden, um ein paar Sekunden Video zu generieren
basierend auf Stabilität Das ursprüngliche Stable Diffusion-Graphmodell von AI, Stable Video Diffusion, hat sich zu einem der wenigen Videogenerierungsmodelle im Open-Source- oder kommerziellen Bereich entwickelt.


Aber es ist noch nicht für alle verfügbar. Stable Video Diffusion hat die Registrierung für die Benutzerwarteliste eröffnet (https://stability.ai/contact).
Laut Einleitung kann Stable Video Propagation leicht an eine Vielzahl nachgelagerter Aufgaben angepasst werden, einschließlich der Multi-View-Synthese aus einem einzelnen Bild durch Feinabstimmung an Multi-View-Datensätzen. Stable AI gab an, dass verschiedene Modelle geplant sind, um dieses Fundament aufzubauen und zu erweitern, ähnlich dem Ökosystem, das auf stabiler Diffusion basiert


über stabiles Video, das sich mit 3 bis 30 Mal pro Sekunde ausbreiten kann. Anpassbarer Rahmen Bildrate generiert Videos mit 14 und 25 Bildern
In externen Bewertungen bestätigte Stability AI, dass diese Modelle führende Closed-Source-Modelle in der Benutzerpräferenzforschung übertrafen:

Stability AI Es wird betont, dass Stabil Die Videoverbreitung ist derzeit nicht für reale oder direkte kommerzielle Anwendungen geeignet und das Modell wird auf der Grundlage von Benutzereinblicken und Feedback zu Sicherheit und Qualität verbessert.

Papieradresse: https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
Stabile Videoübertragung ist A Mitglied der stabilen KI-Open-Source-Modellfamilie. Nun scheint es, dass ihre Produkte mehrere Modalitäten wie Bilder, Sprache, Audio, 3D und Code abdecken, was ihr Engagement für die Verbesserung der künstlichen Intelligenz voll und ganz unter Beweis stellt Als Diffusionsmodell für hochauflösende Videos hat das Videodiffusionsmodell die SOTA-Ebene von Text-zu-Video oder Bild-zu-Video erreicht. Kürzlich wurden latente Diffusionsmodelle, die für die 2D-Bildsynthese trainiert wurden, in generative Videomodelle umgewandelt, indem zeitliche Schichten eingefügt und an kleinen, hochwertigen Videodatensätzen verfeinert wurden. Allerdings variieren die Trainingsmethoden in der Literatur stark, und die Fachwelt muss sich noch auf eine einheitliche Strategie für die Kuratierung von Videodaten einigen
In dem Artikel „Stable Video Diffusion“ identifiziert und bewertet Stability AI drei verschiedene Phasen für ein erfolgreiches Training latenter Videos Diffusionsmodelle: Text-zu-Bild-Vortraining, Video-Vortraining und hochwertige Video-Feinabstimmung. Sie zeigen auch die Bedeutung sorgfältig vorbereiteter Datensätze vor dem Training für die Generierung hochwertiger Videos und beschreiben einen systematischen Kurationsprozess zum Trainieren eines starken Basismodells, einschließlich Untertiteln und Filterstrategien.
Stabilitäts-KI untersucht in dem Artikel auch die Auswirkungen der Feinabstimmung des Basismodells auf hochwertige Daten und trainiert ein Text-zu-Video-Modell, das mit der Closed-Source-Videogenerierung vergleichbar ist. Das Modell bietet eine leistungsstarke Bewegungsdarstellung für nachgelagerte Aufgaben wie die Bild-zu-Video-Generierung und die Anpassungsfähigkeit an kamerabewegungsspezifische LoRA-Module. Darüber hinaus ist das Modell auch in der Lage, einen leistungsstarken 3D-Vorgang mit mehreren Ansichten bereitzustellen, der als Grundlage für ein Diffusionsmodell mit mehreren Ansichten verwendet werden kann. Das Modell generiert mehrere Ansichten eines Objekts in einer Feed-Forward-Methode, die nur erforderlich ist geringer Bedarf an Rechenleistung und Leistung Übertrifft auch bildbasierte Methoden .

Konkret erfordert das erfolgreiche Training dieses Modells die folgenden drei Phasen:
Phase 1: Bild-Vortraining. Dieser Artikel betrachtet das Bild-Vortraining als die erste Stufe der Trainingspipeline und baut das anfängliche Modell auf Stable Diffusion 2.1 auf, wodurch das Videomodell mit einer leistungsstarken visuellen Darstellung ausgestattet wird. Um den Effekt des Bildvortrainings zu analysieren, werden in diesem Artikel auch zwei identische Videomodelle trainiert und verglichen. Die Ergebnisse aus Abbildung 3a zeigen, dass das vorab trainierte Bildmodell sowohl hinsichtlich der Qualität als auch der Cue-Verfolgung bevorzugt wird.
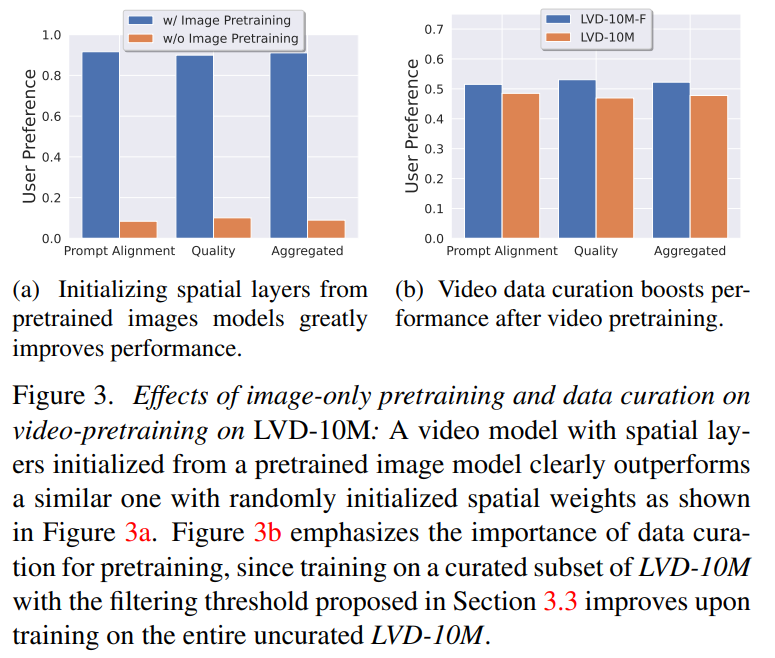
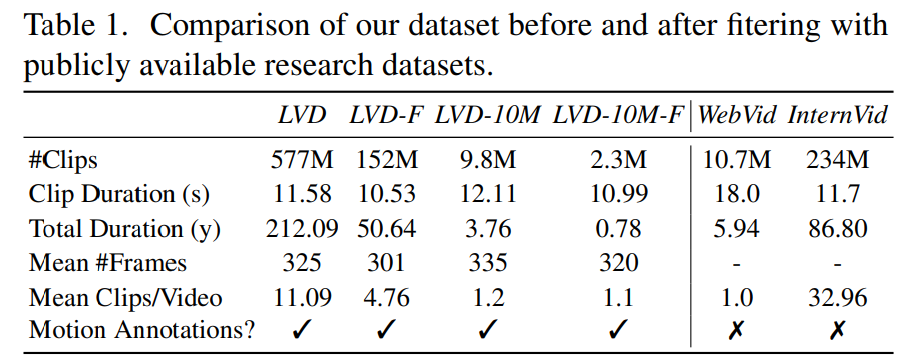
Phase 2: Video-Datensatz vor dem Training. Dieser Artikel basiert auf menschlichen Vorlieben als Signalen, um geeignete Datensätze vor dem Training zu erstellen. Der in diesem Artikel erstellte Datensatz ist LVD (Large Video Dataset), der aus 580 Millionen Paaren kommentierter Videoclips besteht.
Weitere Untersuchungen ergaben, dass der generierte Datensatz einige Beispiele enthielt, die die Leistung des endgültigen Videomodells beeinträchtigen könnten. Daher verwenden wir in diesem Artikel einen dichten optischen Fluss, um den Datensatz mit Anmerkungen zu versehen
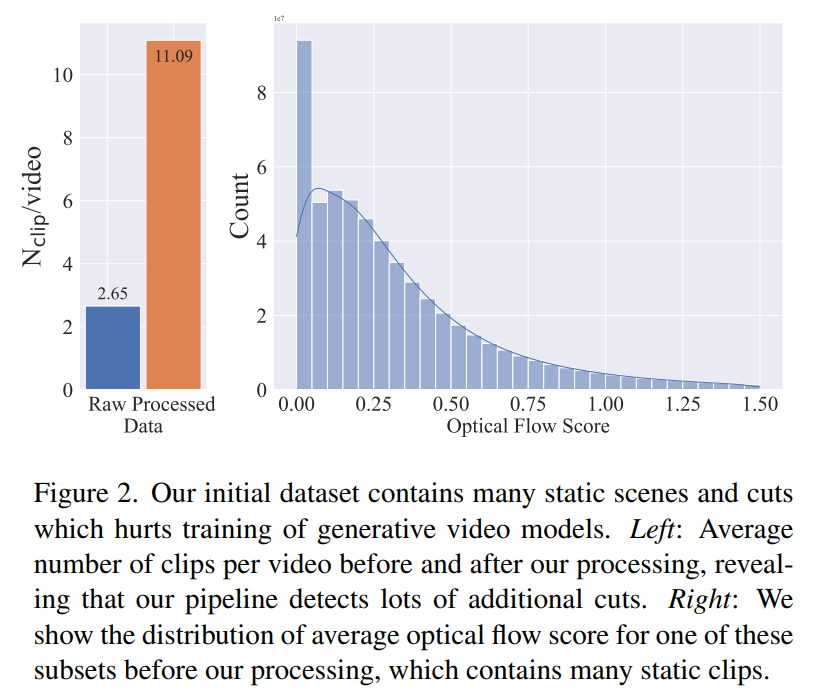
Darüber hinaus wendet dieser Artikel auch die optische Zeichenerkennung an, um Clips mit einer großen Textmenge zu bereinigen. Schließlich verwenden wir CLIP-Einbettungen, um das erste, mittlere und letzte Bild jedes Clips mit Anmerkungen zu versehen. Die folgende Tabelle enthält einige Statistiken des LVD-Datensatzes:
Phase 3: Hochwertige Feinabstimmung. Um die Auswirkungen des Video-Vortrainings auf die Endphase zu analysieren, werden in diesem Artikel drei Modelle verfeinert, die sich nur in der Initialisierung unterscheiden. Abbildung 4e zeigt die Ergebnisse.

Sieht aus, als wäre das ein guter Anfang. Wann können wir KI nutzen, um direkt einen Film zu generieren?
Das obige ist der detaillierte Inhalt vonStabile Videoverbreitung ist da, Codegewicht ist online. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laraveleloquent-Modellab Abruf: Das Erhalten von Datenbankdaten Eloquentorm bietet eine prägnante und leicht verständliche Möglichkeit, die Datenbank zu bedienen. In diesem Artikel werden verschiedene eloquente Modellsuchtechniken im Detail eingeführt, um Daten aus der Datenbank effizient zu erhalten. 1. Holen Sie sich alle Aufzeichnungen. Verwenden Sie die Methode All (), um alle Datensätze in der Datenbanktabelle zu erhalten: UseApp \ Models \ post; $ posts = post :: all (); Dies wird eine Sammlung zurückgeben. Sie können mit der Foreach-Schleife oder anderen Sammelmethoden auf Daten zugreifen: foreach ($ postas $ post) {echo $ post->
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
