
 Technologie-Peripheriegeräte
KI
So verwenden Sie LangChain und OpenAI API für die Dokumentenanalyse
Technologie-Peripheriegeräte
KI
So verwenden Sie LangChain und OpenAI API für die Dokumentenanalyse
So verwenden Sie LangChain und OpenAI API für die Dokumentenanalyse

Der Inhalt, der vom Übersetzer neu geschrieben werden muss, ist: |Der Inhalt, der neu geschrieben werden muss, ist: Bugatti
Der Inhalt, der vom Rezensenten neu geschrieben werden muss, ist: |Der Inhalt, der benötigt wird neu geschrieben werden soll: Chonglou
Das Extrahieren von Einsichtenaus Dokumenten und Daten ist für Sievon entscheidender Bedeutung, um fundierte Entscheidungen zu treffen. Beim Umgang mit sensiblen Informationen können jedoch Datenschutzprobleme auftreten. Die kombinierte Verwendung von LangChain und OpenAI muss neu geschrieben werden: API, Sie können lokale Dokumente analysieren, ohne sie ins Internet hochzuladen.
Sie tun dies, indem sie die Daten lokal speichern, Einbettung und Vektorisierung zur Analyse verwenden und Prozesse in Ihrer Umgebung ausführen. OpenAI verwendet keine von Kunden über seine API übermittelten Daten, um Modelle zu trainieren oder den Service zu verbessern.
BuildEnvironment
Erstellen Sie eine neuePythonvirtuelle Umgebung, Dadurch wird sichergestellt, dass es keine Bibliotheksversionskonflikte gibt. Führen Sie dann die folgenden Terminalbefehle aus, um die erforderlichen Bibliotheken zu installieren. pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
Volumenspeicherung bereit. OpenAI
- :
- Sie werden es verwenden, um Abfragen , auszuführen und Ergebnisse aus Sprachmodellen zu erhalten. tiktoken :
- Damit können Sie die Anzahl der token ( Texteinheit ) in einem bestimmten Text zählen. Was neu geschrieben werden muss, um die Anzahl der Token bei der Interaktion mit
- OpenAI zu verfolgen, die basierend auf der Anzahl der von Ihnen verwendeten Token berechnet, ist: API . FAISS: Sie verwenden es zum Erstellen und Verwalten von Vektorspeichern und ermöglichen so das schnelle Abrufen ähnlicher Vektoren basierend auf Einbettungen. PyPDF: Diese Bibliothek extrahiert Text aus PDF. Es
- hilft beim Laden von PDF-Dateien und beim Extrahieren ihres Textes , zur weiteren Verarbeitung.
- Nach der Installation aller Bibliotheken ist Ihre Umgebung nun bereit bereit . Get OpenAI Was neu geschrieben werden muss, ist: API Schlüssel
Wenn Sie eine Anfrage an OpenAI stellen, muss Folgendes neu geschrieben werden: API , müssen Sie Fügen Sie APIKey als Teil der Anfrage hinzu. Mit diesem
Schlüssel kann der APIAnbieter überprüfen, ob die Anfrage von einer legitimen Quelle stammt und dass Sie über die erforderlichen Berechtigungen verfügen, um auf die Funktionalität zuzugreifen.
Was umgeschrieben werden muss, um OpenAI zu erhalten, ist: API-Schlüssel, geben Sie die OpenAI-Plattform ein. Klicken Sie dann unter dem Konto Profil oben rechts auf „AnsichtAPISchlüssel“, erscheint API
Geheim Schlüsselseite.
Klicken Sie auf die Schaltfläche „Neuen Schlüssel erstellen“ . Nennen Sie den Schlüssel und klicken Sie auf „Neuen Schlüssel erstellen“. OpenAI generiert einen APISchlüssel, den Sie kopieren und an einem sicheren Ort aufbewahren sollten. Aus Sicherheitsgründen können Sie es nicht erneut über Ihr OpenAI
-Konto anzeigen. Wenn Sie den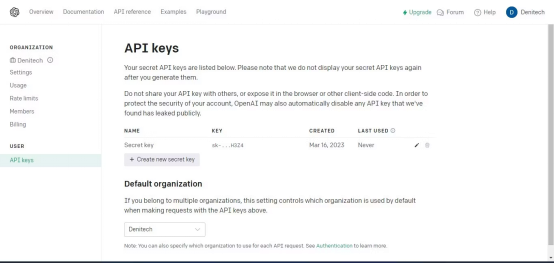 Schlüssel verlieren, müssen Sie einen neuen Schlüssel generieren.
Schlüssel verlieren, müssen Sie einen neuen Schlüssel generieren.
导入所需的库
为了能够使用安装在虚拟环境中的库,您需要导入它们。
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。
加载用于分析的文档
先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。
接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。
需要改写的内容是:
text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。
查询文档
您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
该函数使用创建的QA实例来运行查询并输出结果。
创建主函数
主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。
接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。
这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。
最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数:
if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。
执行文件分析
要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。
以下截图展示了对PDF进行分析的结果
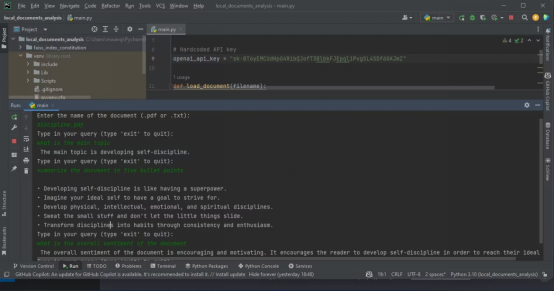
Die folgende Ausgabe zeigt die Ergebnisse der Analyse einer Textdatei, die mit Quellcode enthält.
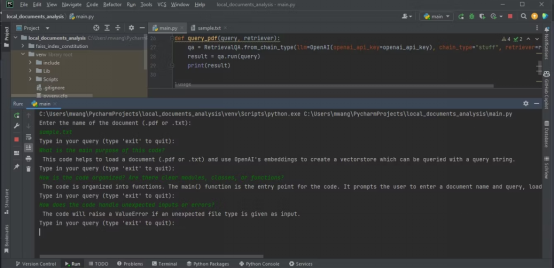
Stellen Sie sicher, dass die Datei, die Sie analysieren möchten, im PDF- oder Textformat vorliegt. Wenn Ihre Dokumente in anderen Formaten vorliegen, können Sie sie mit Online-Tools in das PDF-Format konvertieren. Der vollständige Quellcode ist im GitHub-Code-Repository verfügbar: https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI
Originaltitel: Wie muss neu geschrieben werden Der Inhalt, der neu geschrieben werden muss, ist: bis Der Inhalt, der neu geschrieben werden muss, ist: Analysieren Der Inhalt, der neu geschrieben werden muss, ist: Dokumente Der Inhalt, der neu geschrieben werden muss, ist: Mit Der Inhalt, der neu geschrieben werden muss, ist : LangChain Der Inhalt, der neu geschrieben werden muss, ist: und Der Inhalt, der neu geschrieben werden muss, ist: Der Inhalt, der neu geschrieben werden muss, ist: the Der Inhalt ist: OpenAI Der Inhalt, der neu geschrieben werden muss, ist: API , Autor: Denis Der Inhalt, der neu geschrieben werden muss, ist: Kuria
Der Inhalt, der neu geschrieben werden muss, ist:
Das obige ist der detaillierte Inhalt vonSo verwenden Sie LangChain und OpenAI API für die Dokumentenanalyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wählen Sie das Einbettungsmodell, das am besten zu Ihren Daten passt: Ein Vergleichstest von OpenAI und mehrsprachigen Open-Source-Einbettungen
Feb 26, 2024 pm 06:10 PM
Wählen Sie das Einbettungsmodell, das am besten zu Ihren Daten passt: Ein Vergleichstest von OpenAI und mehrsprachigen Open-Source-Einbettungen
Feb 26, 2024 pm 06:10 PM
OpenAI kündigte kürzlich die Einführung seines Einbettungsmodells embeddingv3 der neuesten Generation an, das seiner Meinung nach das leistungsstärkste Einbettungsmodell mit höherer Mehrsprachenleistung ist. Diese Reihe von Modellen ist in zwei Typen unterteilt: das kleinere Text-Embeddings-3-Small und das leistungsfähigere und größere Text-Embeddings-3-Large. Es werden nur wenige Informationen darüber offengelegt, wie diese Modelle entworfen und trainiert werden, und auf die Modelle kann nur über kostenpflichtige APIs zugegriffen werden. Es gab also viele Open-Source-Einbettungsmodelle. Aber wie schneiden diese Open-Source-Modelle im Vergleich zum Closed-Source-Modell von OpenAI ab? In diesem Artikel wird die Leistung dieser neuen Modelle empirisch mit Open-Source-Modellen verglichen. Wir planen, Daten zu erstellen
 Ein neues Programmierparadigma, wenn Spring Boot auf OpenAI trifft
Feb 01, 2024 pm 09:18 PM
Ein neues Programmierparadigma, wenn Spring Boot auf OpenAI trifft
Feb 01, 2024 pm 09:18 PM
Im Jahr 2023 ist die KI-Technologie zu einem heißen Thema geworden und hat enorme Auswirkungen auf verschiedene Branchen, insbesondere im Programmierbereich. Die Bedeutung der KI-Technologie wird den Menschen zunehmend bewusst, und die Spring-Community bildet da keine Ausnahme. Mit der kontinuierlichen Weiterentwicklung der GenAI-Technologie (General Artificial Intelligence) ist es entscheidend und dringend geworden, die Erstellung von Anwendungen mit KI-Funktionen zu vereinfachen. Vor diesem Hintergrund entstand „SpringAI“ mit dem Ziel, den Prozess der Entwicklung von KI-Funktionsanwendungen zu vereinfachen, ihn einfach und intuitiv zu gestalten und unnötige Komplexität zu vermeiden. Durch „SpringAI“ können Entwickler einfacher Anwendungen mit KI-Funktionen erstellen, wodurch diese einfacher zu verwenden und zu bedienen sind.
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Der Rust-basierte Zed-Editor ist Open Source und bietet integrierte Unterstützung für OpenAI und GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Der Rust-basierte Zed-Editor ist Open Source und bietet integrierte Unterstützung für OpenAI und GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Autor丨Zusammengestellt von TimAnderson丨Produziert von Noah|51CTO Technology Stack (WeChat-ID: blog51cto) Das Zed-Editor-Projekt befindet sich noch in der Vorabversionsphase und wurde unter AGPL-, GPL- und Apache-Lizenzen als Open Source bereitgestellt. Der Editor zeichnet sich durch hohe Leistung und mehrere KI-gestützte Optionen aus, ist jedoch derzeit nur auf der Mac-Plattform verfügbar. Nathan Sobo erklärte in einem Beitrag, dass in der Codebasis des Zed-Projekts auf GitHub der Editor-Teil unter der GPL lizenziert ist, die serverseitigen Komponenten unter der AGPL lizenziert sind und der GPUI-Teil (GPU Accelerated User) die Schnittstelle übernimmt Apache2.0-Lizenz. GPUI ist ein vom Zed-Team entwickeltes Produkt
 Warten Sie nicht auf OpenAI, sondern darauf, dass Open-Sora vollständig Open Source ist
Mar 18, 2024 pm 08:40 PM
Warten Sie nicht auf OpenAI, sondern darauf, dass Open-Sora vollständig Open Source ist
Mar 18, 2024 pm 08:40 PM
Vor nicht allzu langer Zeit wurde OpenAISora mit seinen erstaunlichen Videogenerierungseffekten schnell populär und stach aus der Masse der literarischen Videomodelle hervor und rückte in den Mittelpunkt der weltweiten Aufmerksamkeit. Nach der Einführung des Sora-Trainings-Inferenzreproduktionsprozesses mit einer Kostenreduzierung von 46 % vor zwei Wochen hat das Colossal-AI-Team das weltweit erste Sora-ähnliche Architektur-Videogenerierungsmodell „Open-Sora1.0“ vollständig als Open-Source-Lösung bereitgestellt, das das gesamte Spektrum abdeckt Lernen Sie den Trainingsprozess, einschließlich der Datenverarbeitung, aller Trainingsdetails und Modellgewichte, kennen und schließen Sie sich mit globalen KI-Enthusiasten zusammen, um eine neue Ära der Videoerstellung voranzutreiben. Schauen wir uns für einen kleinen Vorgeschmack ein Video einer geschäftigen Stadt an, das mit dem vom Colossal-AI-Team veröffentlichten Modell „Open-Sora1.0“ erstellt wurde. Open-Sora1.0
 Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Apr 15, 2024 am 09:01 AM
Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Apr 15, 2024 am 09:01 AM
Ollama ist ein superpraktisches Tool, mit dem Sie Open-Source-Modelle wie Llama2, Mistral und Gemma problemlos lokal ausführen können. In diesem Artikel werde ich vorstellen, wie man Ollama zum Vektorisieren von Text verwendet. Wenn Sie Ollama nicht lokal installiert haben, können Sie diesen Artikel lesen. In diesem Artikel verwenden wir das Modell nomic-embed-text[2]. Es handelt sich um einen Text-Encoder, der OpenAI text-embedding-ada-002 und text-embedding-3-small bei kurzen und langen Kontextaufgaben übertrifft. Starten Sie den nomic-embed-text-Dienst, wenn Sie o erfolgreich installiert haben
 Microsoft und OpenAI planen, 100 Millionen US-Dollar in humanoide Roboter zu investieren! Internetnutzer rufen Musk an
Feb 01, 2024 am 11:18 AM
Microsoft und OpenAI planen, 100 Millionen US-Dollar in humanoide Roboter zu investieren! Internetnutzer rufen Musk an
Feb 01, 2024 am 11:18 AM
Anfang des Jahres wurde bekannt, dass Microsoft und OpenAI große Geldsummen in ein Startup für humanoide Roboter investieren. Unter anderem plant Microsoft, 95 Millionen US-Dollar zu investieren, und OpenAI wird 5 Millionen US-Dollar investieren. Laut Bloomberg wird das Unternehmen in dieser Runde voraussichtlich insgesamt 500 Millionen US-Dollar einsammeln, und seine Pre-Money-Bewertung könnte 1,9 Milliarden US-Dollar erreichen. Was zieht sie an? Werfen wir zunächst einen Blick auf die Robotik-Erfolge dieses Unternehmens. Dieser Roboter ist ganz in Silber und Schwarz gehalten und ähnelt in seinem Aussehen dem Abbild eines Roboters in einem Hollywood-Science-Fiction-Blockbuster: Jetzt steckt er eine Kaffeekapsel in die Kaffeemaschine: Wenn sie nicht richtig platziert ist, passt sie sich von selbst an menschliche Fernbedienung: Nach einer Weile kann jedoch eine Tasse Kaffee mitgenommen und genossen werden: Haben Sie Familienmitglieder, die es erkannt haben? Ja, dieser Roboter wurde vor einiger Zeit erstellt.
 Plötzlich! OpenAI entlässt Ilya-Verbündeten wegen Verdacht auf Informationslecks
Apr 15, 2024 am 09:01 AM
Plötzlich! OpenAI entlässt Ilya-Verbündeten wegen Verdacht auf Informationslecks
Apr 15, 2024 am 09:01 AM
Plötzlich! OpenAI entließ den Mitarbeiter, der Grund: Verdacht auf Informationslecks. Einer davon ist Leopold Aschenbrenner, ein Verbündeter des vermissten Chefwissenschaftlers Ilya und Kernmitglied des Superalignment-Teams. Die andere Person ist auch nicht einfach. Er ist Pavel Izmailov, ein Forscher im LLM-Inferenzteam, der auch im Super-Alignment-Team gearbeitet hat. Es ist unklar, welche Informationen die beiden Männer genau preisgegeben haben. Nachdem die Nachricht bekannt wurde, äußerten sich viele Internetnutzer „ziemlich schockiert“: Ich habe Aschenbrenners Beitrag vor nicht allzu langer Zeit gesehen und hatte das Gefühl, dass er in seiner Karriere auf dem Vormarsch ist. Mit einer solchen Veränderung habe ich nicht gerechnet. Einige Internetnutzer auf dem Bild denken: OpenAI hat Aschenbrenner, I. verloren
