
 Technologie-Peripheriegeräte
KI
Überwachtes vs. unüberwachtes Lernen: Experten definieren die Lücke
Technologie-Peripheriegeräte
KI
Überwachtes vs. unüberwachtes Lernen: Experten definieren die Lücke
Überwachtes vs. unüberwachtes Lernen: Experten definieren die Lücke

Was neu geschrieben werden muss, ist: Verstehen Sie die Merkmale des überwachten Lernens, des unüberwachten Lernens und des halbüberwachten Lernens und wie sie in maschinellen Lernprojekten angewendet werden.

Bei der Erörterung der Technologie der künstlichen Intelligenz wird häufig überwachtes Lernen verwendet ist die Methode, die die meiste Aufmerksamkeit erhält, da sie oft der letzte Schritt bei der Erstellung eines KI-Modells ist und für Dinge wie Bilderkennung, bessere Vorhersagen, Produktempfehlungen und Lead-Scoring verwendet werden kann
Im Gegensatz dazu tendiert kein überwachtes Lernen um zu Beginn des KI-Entwicklungslebenszyklus hinter den Kulissen zu arbeiten: Es wird oft verwendet, um den Grundstein für die Entfaltung der Magie des überwachten Lernens zu legen, genau wie die Routinearbeit, die es Managern ermöglicht, zu glänzen. Wie später erläutert wird, können beide Modelle des maschinellen Lernens effektiv auf Geschäftsprobleme angewendet werden.
Auf technischer Ebene besteht der Unterschied zwischen überwachtem und unüberwachtem Lernen darin, ob die zur Erstellung des Algorithmus verwendeten Rohdaten vorab gekennzeichnet sind (überwachtes Lernen) oder nicht (unüberwachtes Lernen).
Lass uns anfangen
Was ist überwachtes Lernen?
Beim überwachten Lernen stellen Datenwissenschaftler dem Algorithmus gekennzeichnete Trainingsdaten zur Verfügung und definieren die Variablen, die der Algorithmus auf Relevanz auswerten soll.
Die Eingabedaten und Ausgabevariablen des Algorithmus werden durch die Trainingsdaten spezifiziert. Wenn Sie beispielsweise überwachtes Lernen verwenden möchten, um einen Algorithmus zu trainieren, um zu bestimmen, ob ein Bild eine Katze enthält, können Sie für jedes in den Trainingsdaten verwendete Bild eine Beschriftung erstellen, um anzugeben, ob das Bild eine Katze enthält
Wie wir Erklären Sie in unserer Definition des überwachten Lernens: „[Ein] Computeralgorithmus wird auf Eingabedaten trainiert, die für eine bestimmte Ausgabe gekennzeichnet sind. Das Modell wird trainiert, bis es in der Lage ist, die grundlegenden Muster und Beziehungen zwischen ihnen zu erkennen.“ Sie liefern genaue Kennzeichnungsergebnisse, wenn sie mit noch nie dagewesenen Daten präsentiert werden, darunter Klassifizierung, Entscheidungsbäume, Regression und Vorhersagemodellierung. Erfahren Sie mehr über sie im Tutorial
Überwachte maschinelle Lerntechniken werden in einer Vielzahl von Geschäftsanwendungen eingesetzt, darunter:
- Personalisiertes Marketing
- Versicherungs-/Kreditversicherungsentscheidungen Aud-Erkennung.
- Spam-Filterung
- Was ist unüberwachtes Lernen? Für diese Methode gibt es einen Algorithmus, der auf unbeschrifteten Daten trainiert Durchsucht den Datensatz nach sinnvollen Zusammenhängen. Mit anderen Worten: Unüberwachtes Lernen identifiziert Muster in den Daten, anstatt sie mit einem externen Maß in Beziehung zu setzen.
Dieser Ansatz ist nützlich, wenn Sie nicht wissen, was Sie sind Auf der Suche nach, aber nicht so nützlich, wenn Sie dies tun. Sie zeigen einem unbeaufsichtigten Algorithmus Tausende oder Millionen von Bildern an, und er klassifiziert möglicherweise eine Teilmenge der Bilder als solche, die Menschen als Katzen erkennen, verglichen mit den gekennzeichneten Daten zu Katzen und Hunden Algorithmen, auf denen trainiert wird, sind in der Lage, Bilder von Katzen mit einem hohen Maß an Sicherheit zu identifizieren, aber dieser Ansatz bringt einen Kompromiss mit sich: Wenn ein überwachtes Lernprojekt Millionen von beschrifteten Bildern erfordert, um ein Modell zu entwickeln, sind für maschinell generierte Vorhersagen viele davon erforderlich menschliche Anstrengung
Es gibt einen Mittelweg: halbüberwachtes Lernen
Was ist halbüberwachtes Lernen?
Halbüberwachtes Lernen ist eine effektive Methode, die unüberwachtes Lernen und überwachtes Lernen durch eine bestimmte Methode kombiniert Arbeitsablauf Der unüberwachte Lernalgorithmus generiert automatisch Beschriftungen, die dann in den überwachten Lernalgorithmus eingespeist werden. Bei dieser Methode beschriften Menschen manuell einige Bilder, während der unüberwachte Lernalgorithmus die Beschriftungen für andere Bilder errät und schließlich alle Beschriftungen und Bilder einspeist hinein. in überwachte Lernalgorithmen, um KI-Modelle zu erstellen
Ein Vorteil des halbüberwachten Lernens besteht darin, dass es die Kosten für die Verwendung großer Datensätze beim maschinellen Lernen senken kann, so Aaron, Mitbegründer und Chefinnovator Laut Kalb können Computer, wenn sie 0,01 % von Millionen Proben kennzeichnen können, ihre Vorhersagegenauigkeit deutlich verbessern
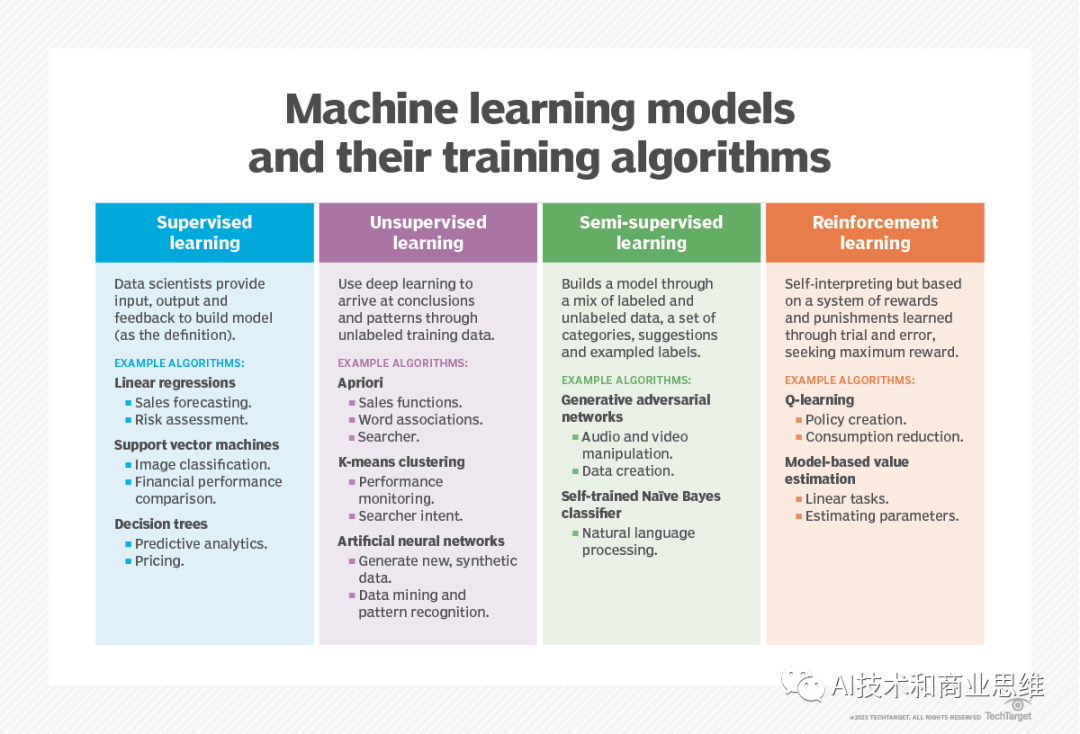
Was ist Reinforcement Learning?
Eine weitere Methode des maschinellen Lernens ist das Reinforcement Learning. Reinforcement Learning wird typischerweise verwendet, um einer Maschine beizubringen, eine Abfolge von Schritten abzuschließen, und unterscheidet sich vom überwachten und unbeaufsichtigten Lernen. Datenwissenschaftler programmieren Algorithmen zur Ausführung von Aufgaben und geben positive oder negative Hinweise oder Verstärkungen, wenn sie bestimmen, wie Aufgaben erledigt werden sollen. Der Programmierer legt die Regeln für die Belohnung fest, lässt aber den Algorithmus entscheiden, welche Schritte er unternehmen muss, um die Belohnung für die Erledigung der Aufgabe zu maximieren.
Wann sollten Sie überwachtes Lernen im Vergleich zu unüberwachtem Lernen verwenden?
Shivani Rao, Machine Learning Manager bei LinkedIn, sagte, dass Best Practices für einen überwachten oder unbeaufsichtigten Ansatz des maschinellen Lernens oft von der Umgebung, den Annahmen, die man über die Daten und die Anwendung treffen kann, abhängen.
Rao sagte, dass sich auch die Wahl zwischen überwachten und unbeaufsichtigten Algorithmen für maschinelles Lernen im Laufe der Zeit ändern werde. In den frühen Phasen des Modellbildungsprozesses sind die Daten oft unbeschriftet, während in späteren Phasen der Modellierung beschriftete Daten entstehen können.
Für das Problem der Vorhersage, ob LinkedIn-Mitglieder Kursvideos ansehen werden, verwendet das erste Modell beispielsweise unbeaufsichtigte Techniken. Nachdem diese Vorschläge bereitgestellt wurden, liefert eine Metrik, die aufzeichnet, ob jemand auf den Vorschlag klickt, neue Daten zur Generierung von Labels
LinkedIn verwendet diese Technik auch, um Online-Kurse mit Fähigkeiten zu versehen, die Studenten möglicherweise erwerben möchten. Menschliche Tagger wie Autoren, Verleger oder Studenten können eine präzise und genaue Liste der in einem Kurs vermittelten Fähigkeiten bereitstellen, es ist jedoch unwahrscheinlich, dass sie eine vollständige Liste dieser Fähigkeiten bereitstellen. Daher können diese Datenetiketten als unvollständig angesehen werden. Für diese Art von Problemen können halbüberwachte Techniken verwendet werden, um einen umfassenderen Satz von Etiketten zu erstellen.
Bharath Thota, ein Experte für Datenwissenschaft und Advanced Analytics und Partner des Beratungsunternehmens Kearney, sagte, dass sein Team bei der Entscheidung für überwachtes oder unbeaufsichtigtes Lernen auch praktische Faktoren berücksichtigt.
Thota sagte: „Wenn beschriftete Daten verfügbar sind, wählen wir überwachtes Lernen als Anwendung mit dem Ziel, zukünftige Beobachtungen vorherzusagen oder zu klassifizieren. Wenn keine beschrifteten Daten verfügbar sind, verwenden wir unüberwachtes Lernen mit dem Ziel der Entwicklung.“ Strategien durch die Identifizierung von Mustern oder Ausschnitten aus Daten.“
Kalb sagte, Alation-Datenwissenschaftler nutzen intern unüberwachtes Lernen für eine Vielzahl von Anwendungen. Sie entwickelten beispielsweise einen kollaborativen Mensch-Maschine-Prozess zur Übersetzung obskurer Datenobjektnamen in menschliche Sprache – zum Beispiel „na_gr_rvnu_ps“ in „North American total professional Services yield“. In diesem Fall maschinelle Vermutungen, Menschen bestätigen, maschinelles Lernen
„Man kann es sich als halbüberwachtes Lernen in einer iterativen Schleife vorstellen, wodurch ein positiver Kreislauf verbesserter Genauigkeit entsteht“, sagte Kalb. 5 unüberwachte Lerntechniken ?
Unüberwachte Lerntechniken ergänzen die Arbeit des überwachten Lernens häufig, indem sie Rohdatensätze auf verschiedene Weise aufteilen, einschließlich:
Datenclusterung von Datenpunkten mit ähnlichen Merkmalen, um das Verständnis zu erleichtern Um Daten effektiver zu untersuchen, könnte ein Unternehmen beispielsweise Daten-Clustering-Methoden verwenden, um Kunden anhand ihrer Demografie, Interessen, Kaufverhalten und anderen Faktoren in Gruppen einzuteilen.
Jede Variable in einem Datensatz wird als separate Dimension behandelt. Viele Modelle funktionieren jedoch besser, wenn sie bestimmte Beziehungen zwischen Variablen analysieren. Ein einfaches Beispiel für die Dimensionsreduktion ist die Verwendung von Gewinn als einer einzigen Dimension, die Einnahmen abzüglich Ausgaben darstellt. Allerdings können mithilfe davon neue, komplexere Variablentypen generiert werden Algorithmen wie Hauptkomponentenanalyse, Autoencoder, Algorithmen, die Text in Vektoren umwandeln, oder T-verteilte stochastische NachbarschaftseinbettungDimensionalitätsreduktion kann dazu beitragen, das Problem der Überanpassung zu reduzieren, bei der ein Modell für kleine Datensätze gut funktioniert, aber nicht verallgemeinert Die Technik ermöglicht es Unternehmen auch, hochdimensionale Daten zu visualisieren, die für Menschen leicht verständlich sind. Unüberwachtes Lernen kann dabei helfen, Anomalien als Datenvorbereitungsschritt zu erkennen das kann die Modelle des maschinellen Lernens verbessern
Lernen übertragen. Diese Algorithmen nutzen Modelle, die für verwandte, aber unterschiedliche Aufgaben trainiert wurden. Transfer-Learning-Techniken erleichtern beispielsweise die Feinabstimmung eines auf Wikipedia-Artikeln trainierten Klassifikators, um jede Art von neuem Text mit den richtigen Themen zu kennzeichnen. Laut Rao von LinkedIn ist dies eine der effektivsten und schnellsten Möglichkeiten, das Problem der unbeschrifteten Daten zu lösen.
Graphbasierter Algorithmus. Rao sagte, dass diese Techniken versuchen, ein Diagramm zu erstellen, das die Beziehung zwischen Datenpunkten erfasst. Wenn beispielsweise jeder Datenpunkt ein LinkedIn-Mitglied mit einer Fertigkeit darstellt, können Sie die Mitglieder mithilfe eines Diagramms darstellen, in dem Kanten die Fertigkeitsüberlappung zwischen Mitgliedern darstellen. Diagrammalgorithmen können auch dabei helfen, Beschriftungen von bekannten Datenpunkten auf unbekannte, aber eng verwandte Datenpunkte zu übertragen. Unüberwachtes Lernen kann auch zum Erstellen von Diagrammen zwischen verschiedenen Arten von Entitäten (Quellen und Zielen) verwendet werden. Je stärker die Kante, desto höher ist die Affinität des Quellknotens zum Zielknoten. LinkedIn verwendet sie beispielsweise, um Mitgliedern kompetenzbasierte Kurse zuzuordnen.
Das obige ist der detaillierte Inhalt vonÜberwachtes vs. unüberwachtes Lernen: Experten definieren die Lücke. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
