

Nach dem beliebten Grounded SAM ist das Team des IDEA Research Institutemit einer neuen Arbeit zurück: einem neuen visuellen Prompt (Visual Prompt) Modell T-Re x, verwenden Sie Bilder, um Bilder zu erkennen, verwenden Sie es sofort nach dem Auspacken,  eröffnen Sie eine neue Welt der Erkennung offener Mengen!
eröffnen Sie eine neue Welt der Erkennung offener Mengen!
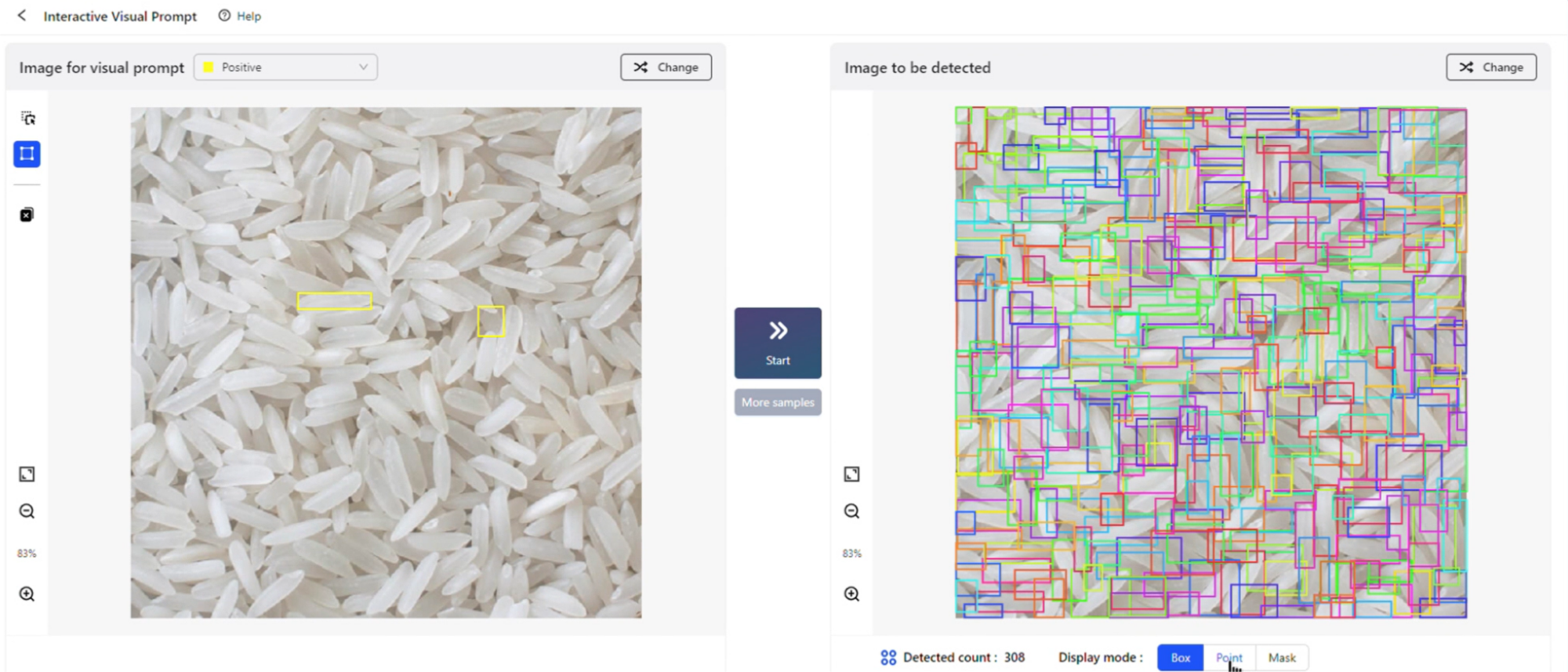
Rahmen ziehen, prüfen und fertigstellen! Auf der gerade zu Ende gegangenen IDEA-Konferenz 2023 demonstrierte Shen Xiangyang, Gründungsvorsitzender des IDEA Research Institute und ausländischer Akademiker der National Academy of Engineering, ein neues Zielerkennungserlebnis basierend auf visuellen Hinweisen und stellte das Modelllabor (Spielplatz) des neuen vor visuelle Hinweise Modell T-Rex), Interactive Visual Prompt (iVP), löste vor Ort eine Welle von Testhöhepunkten aus.

Auf iVP können Benutzer persönlich das Erlebnis „Ein Bild sagt mehr als tausend Worte“ freischalten: Markieren Sie das gewünschte Objekt auf dem Bild, geben Sie dem Modell ein visuelles Beispiel, und das Modell erkennt dann alles ähnliche Objekte im Zielbild Beispiel. Der gesamte Prozess ist interaktiv und kann problemlos in wenigen Schritten abgeschlossen werden.
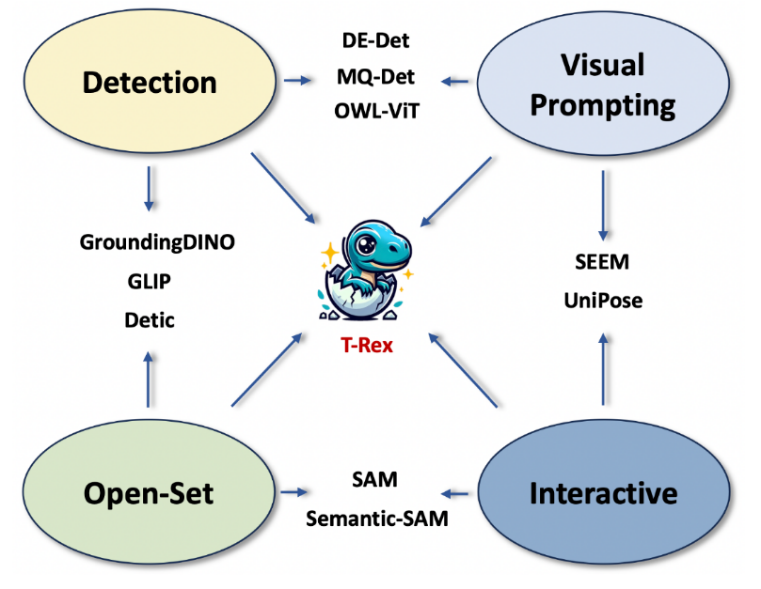
Grounded SAM (Grounding DINO + SAM), veröffentlicht vom IDEA Research Institute im April, erfreute sich auf Github großer Beliebtheit und hat bisher 11.000 Sterne gesammelt. Im Gegensatz zu Grounded SAM, das nur Textaufforderungen unterstützt, bietet das dieses Mal veröffentlichte T-Rex-Modell eine visuelle Aufforderungsfunktion, die sich auf die Schaffung einer starken Interaktion konzentriert.
T-Rex verfügt über starke sofort einsatzbereite Funktionen und kann Objekte erkennen, die das Modell während der Trainingsphase noch nie gesehen hat, ohne dass eine Neuschulung oder Feinabstimmung erforderlich ist. Dieses Modell kann nicht nur auf alle Detektionsaufgaben einschließlich der Zählung angewendet werden, sondern bietet auch neue Lösungen für intelligente interaktive Annotationsszenarien.
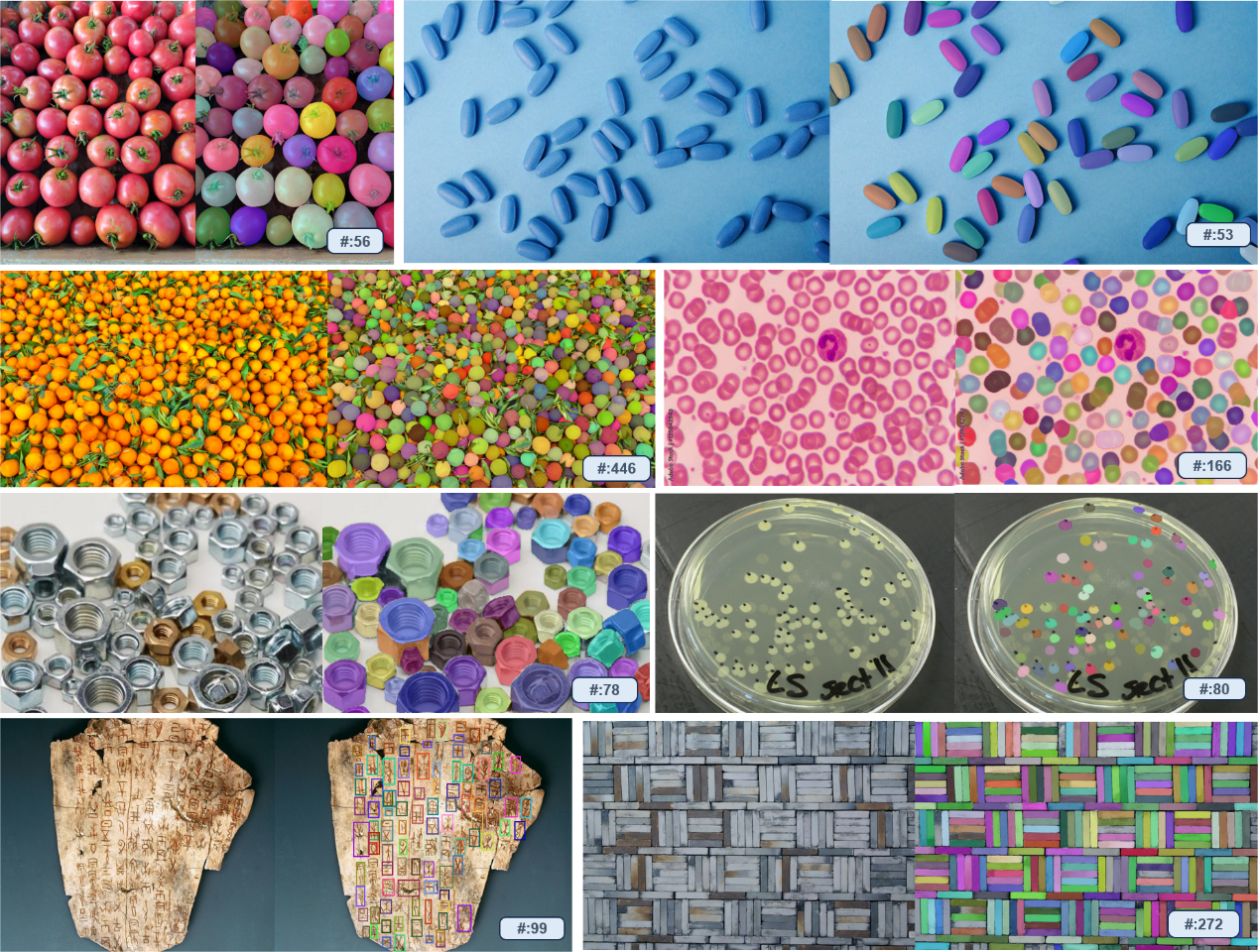
Das Team stellte fest, dass die Entwicklung der visuellen Eingabeaufforderungstechnologie auf der Beobachtung von Schmerzpunkten in realen Szenen beruhte. Einige Partner hoffen, visuelle Modelle zu verwenden, um die Anzahl der Waren auf Lastwagen zu zählen. Das Modell kann jedoch nicht jede Ware einzeln anhand von Textaufforderungen identifizieren. Der Grund dafür ist, dass Objekte in Industrieszenen im täglichen Leben selten und schwer mit Worten zu beschreiben sind. In diesem Fall sind visuelle Hinweise eindeutig ein effizienterer Ansatz. Gleichzeitig tragen intuitives visuelles Feedback und starke Interaktivität dazu bei, die Effizienz und Genauigkeit der Erkennung zu verbessern.
Basierend auf Erkenntnissen über die tatsächlichen Nutzungsanforderungen hat das Team T-Rex als ein Modell entworfen, das mehrere visuelle Hinweise akzeptieren kann und über die Fähigkeit verfügt, über Bilder hinweg Eingabeaufforderungen zu erteilen. Zusätzlich zum einfachsten Einzelrunden-Promptmodus unterstützt das aktuelle Modell auch die folgenden drei erweiterten Modi

 Offener Satz: nicht durch vordefinierte Kategorien eingeschränkt, mit der Fähigkeit, alle Objekte zu erkennen.
Offener Satz: nicht durch vordefinierte Kategorien eingeschränkt, mit der Fähigkeit, alle Objekte zu erkennen.
iVP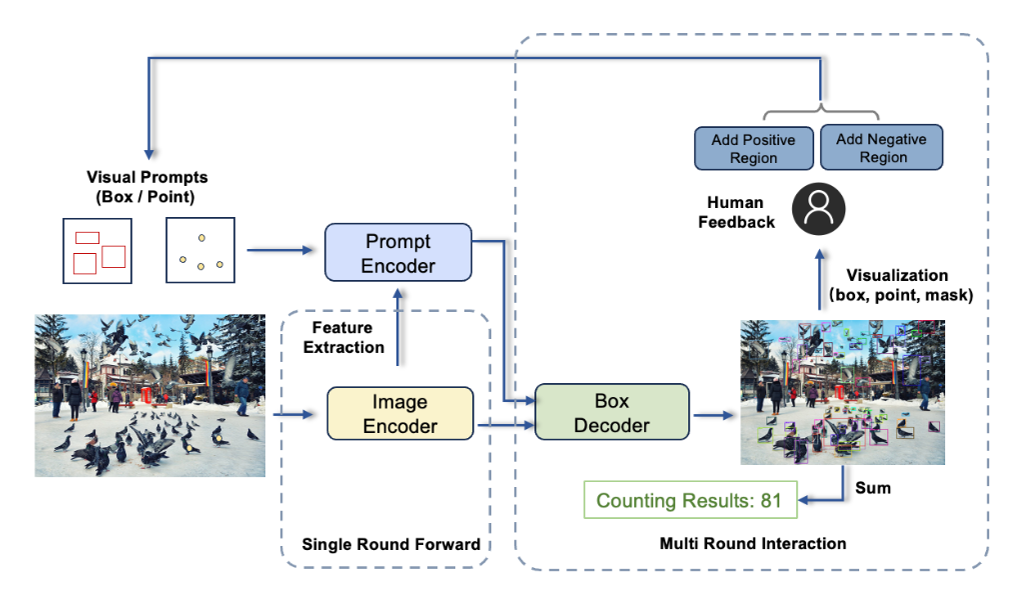
https://deepdataspace.com/playground/ivp
Github-Link: trex-counting.github.io
Diese Arbeit stammt vom Computer Vision and Robotics Research Center des IDEA Institute. Das bisherige Open-Source-Zielerkennungsmodell DINO war das erste DETR-Modell, das den ersten Platz in der COCO-Zielerkennungsrankings erreichte; der sehr beliebte Zero-Shot-Detektor Grounding DINO auf Github kann auch jedes Objekt erkennen und segmentieren die Arbeit dieses Teams
Das obige ist der detaillierte Inhalt vonDas IDEA Research Institute hat eine neue Technologie eingeführt und das T-Rex-Modell veröffentlicht, mit dem Benutzer direkt auf dem Bild „Prompt'-Eingabeaufforderungen auswählen können. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 js ruft die aktuelle Uhrzeit ab
js ruft die aktuelle Uhrzeit ab
 Wie lautet der chinesische Name der Fil-Münze?
Wie lautet der chinesische Name der Fil-Münze?
 So lösen Sie das Problem, dass der PHPStudy-Port belegt ist
So lösen Sie das Problem, dass der PHPStudy-Port belegt ist
 So lösen Sie das Problem eines ungültigen Datenbankobjektnamens
So lösen Sie das Problem eines ungültigen Datenbankobjektnamens
 So ändern Sie C-Sprachsoftware auf Chinesisch
So ändern Sie C-Sprachsoftware auf Chinesisch
 Thunder-Mitgliedschaftspatch
Thunder-Mitgliedschaftspatch
 Was tun, wenn die PHP-Deserialisierung fehlschlägt?
Was tun, wenn die PHP-Deserialisierung fehlschlägt?
 Überprüfen Sie den Status der belegten Ports in Windows
Überprüfen Sie den Status der belegten Ports in Windows
 Der Kern der Computersystemsoftware
Der Kern der Computersystemsoftware



![Erste Schritte mit der praktischen PHP-Entwicklung: Schnelle PHP-Erstellung [Small Business Forum]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)






![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



