
 Technologie-Peripheriegeräte
KI
Der umformulierte Titel lautet: ByteDance und East China Normal University Cooperation: Exploring the Contextual Learning Capabilities of Small Models
Technologie-Peripheriegeräte
KI
Der umformulierte Titel lautet: ByteDance und East China Normal University Cooperation: Exploring the Contextual Learning Capabilities of Small Models
Der umformulierte Titel lautet: ByteDance und East China Normal University Cooperation: Exploring the Contextual Learning Capabilities of Small Models

Es ist bekannt, dass große Sprachmodelle (LLM) durch kontextuelles Lernen aus einer kleinen Anzahl von Beispielen lernen können, ohne dass eine Feinabstimmung des Modells erforderlich ist. Derzeit kann dieses kontextuelle Lernphänomen nur in großen Modellen beobachtet werden. Beispielsweise haben große Modelle wie GPT-4, Llama usw. in vielen Bereichen eine hervorragende Leistung gezeigt, aber aufgrund von Ressourcenbeschränkungen oder hohen Echtzeitanforderungen können große Modelle in vielen Szenarien nicht verwendet werden
Dann sind reguläre- große Modelle Verfügen Sie über diese Fähigkeit? Um die kontextuellen Lernfähigkeiten kleiner Modelle zu untersuchen, führten Forschungsteams von Byte und der East China Normal University Untersuchungen zu Texterkennungsaufgaben in Szenen durch.
Gegenwärtig steht die Szenentexterkennung in tatsächlichen Anwendungsszenarien vor einer Vielzahl von Herausforderungen: unterschiedliche Szenen, Textlayout, Verformung, Lichtänderungen, verschwommene Handschrift, Schriftartenvielfalt usw. Daher ist es schwierig, einer Maschine das beizubringen kann alle Szenarien bewältigen.
Eine direkte Möglichkeit, dieses Problem zu lösen, besteht darin, entsprechende Daten zu sammeln und das Modell in bestimmten Szenarien zu optimieren. Dieser Prozess erfordert jedoch eine rechenintensive Neuschulung des Modells und erfordert das Speichern mehrerer Modellgewichte zur Anpassung an verschiedene Szenarien. Wenn das Texterkennungsmodell über Kontextlernfunktionen verfügen kann, benötigt es bei neuen Szenen nur eine kleine Menge annotierter Daten als Hinweise, um seine Leistung in neuen Szenen zu verbessern und so die oben genannten Probleme zu lösen. Die Texterkennung in Szenen ist jedoch eine ressourcenempfindliche Aufgabe, und die Verwendung eines großen Modells als Texterkennung verbraucht viele Ressourcen. Durch vorläufige experimentelle Beobachtungen stellten Forscher fest, dass herkömmliche Trainingsmethoden für große Modelle nicht für Texterkennungsaufgaben in Szenen geeignet sind
Um dieses Problem zu lösen, schlug das Forschungsteam von ByteDance und der East China Normal University einen sich selbst entwickelnden Texterkenner vor. E2STR (Ego-Evolving Scene Text Recognizer). Dabei handelt es sich um einen Texterkenner in normaler Größe, der über Kontextlernfunktionen verfügt und sich ohne Feinabstimmung schnell an verschiedene Texterkennungsszenarien anpassen lässt .pdf
 E2STR ist mit einem kontextbezogenen Trainings- und Kontextbegründungsmodus ausgestattet, der nicht nur das SOTA-Niveau bei herkömmlichen Datensätzen erreicht, sondern auch ein einziges Modell verwenden kann, um die Erkennungsleistung in verschiedenen Szenarien zu verbessern und eine schnelle Anpassung zu erreichen neue Szenarien, die nach Feinabstimmung sogar die Erkennungsleistung spezialisierter Modelle übertreffen. E2STR zeigt, dass Modelle normaler Größe ausreichen, um effektive Kontextlernfähigkeiten bei Texterkennungsaufgaben zu erreichen.
E2STR ist mit einem kontextbezogenen Trainings- und Kontextbegründungsmodus ausgestattet, der nicht nur das SOTA-Niveau bei herkömmlichen Datensätzen erreicht, sondern auch ein einziges Modell verwenden kann, um die Erkennungsleistung in verschiedenen Szenarien zu verbessern und eine schnelle Anpassung zu erreichen neue Szenarien, die nach Feinabstimmung sogar die Erkennungsleistung spezialisierter Modelle übertreffen. E2STR zeigt, dass Modelle normaler Größe ausreichen, um effektive Kontextlernfähigkeiten bei Texterkennungsaufgaben zu erreichen.
Method
in Abbildung 1, das Training und der Inferenzprozess von E2STR sind gezeigt. Framework Der Zweck des Trainings des visuellen Encoders und des Sprachdecoders besteht darin, Texterkennungsfähigkeiten zu erhalten:
2. Kontexttraining
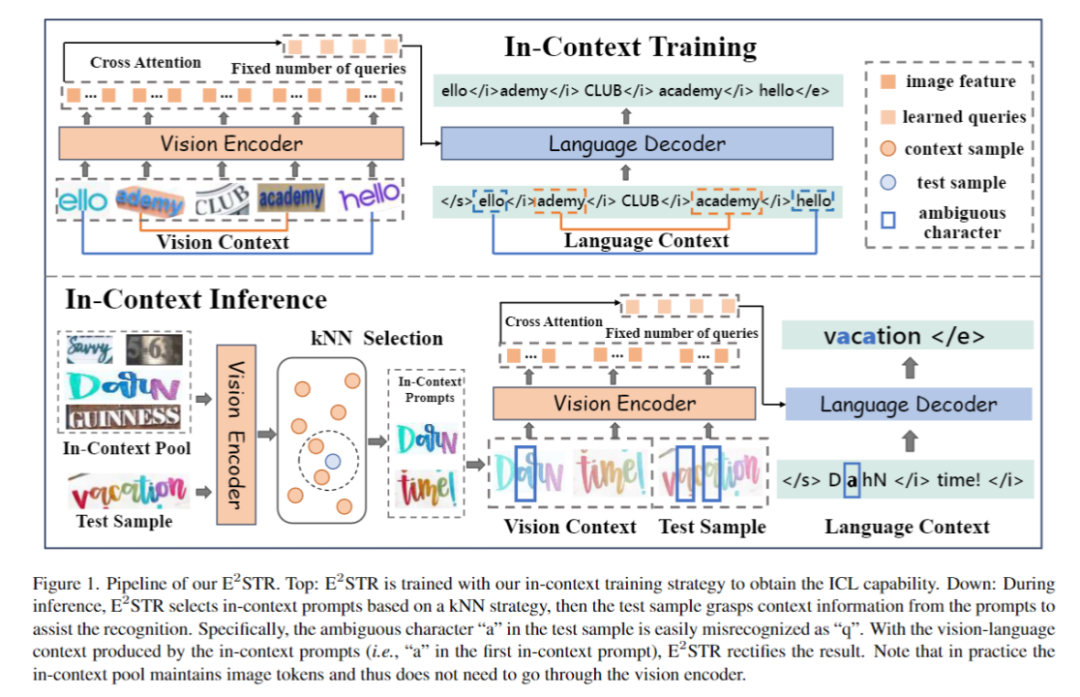
Kontexttrainingsphase E2STR wird gemäß dem vorgeschlagenen Kontexttrainingsparadigma weiter trainiert im Artikel. In dieser Phase lernt E2STR, die Zusammenhänge zwischen verschiedenen Stichproben zu verstehen, um aus kontextuellen Hinweisen Schlussfolgerungen zu ziehen.
Wie in Abbildung 2 gezeigt, schlägt dieser Artikel die ST-Strategie vor, die Textdaten der Szene zufällig zu segmentieren und zu transformieren, um einen Satz von „Unterabtastungen“ zu generieren. Die Teilproben sind sowohl visuell als auch sprachlich untrennbar miteinander verbunden. Diese intern verwandten Proben werden zu einer Sequenz zusammengefügt, und das Modell lernt Kontextwissen aus diesen semantisch reichhaltigen Sequenzen und erhält dadurch die Fähigkeit, Kontext zu lernen. In dieser Phase wird auch das autoregressive Framework zum Training verwendet:
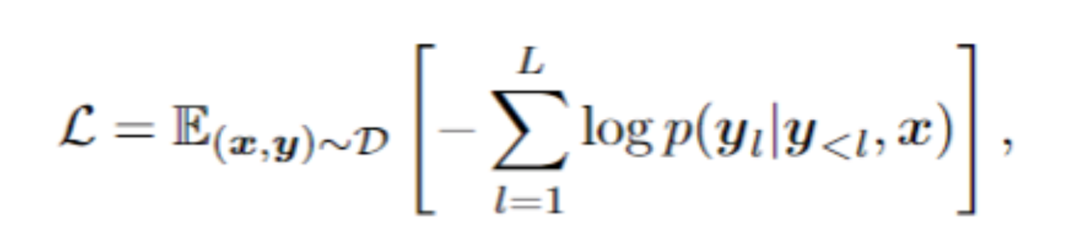
Der Inhalt, der neu geschrieben werden muss, ist: 3. Kontextuelles Denken Umgeschriebener Inhalt: 3. Argumentation basierend auf dem Kontext
Für eine Testprobe wählt das Framework N Proben aus dem kontextuellen Cue-Pool aus, die die höchste Ähnlichkeit mit der Testprobe im visuellen latenten Raum aufweisen. Insbesondere berechnet dieser Artikel die Bildeinbettung I durch Mittelung des Poolings auf der visuellen Token-Sequenz. Anschließend werden die obersten N Stichproben mit der höchsten Kosinusähnlichkeit zwischen Bildeinbettungen und I aus dem Kontextpool ausgewählt und bilden so kontextbezogene Hinweise.
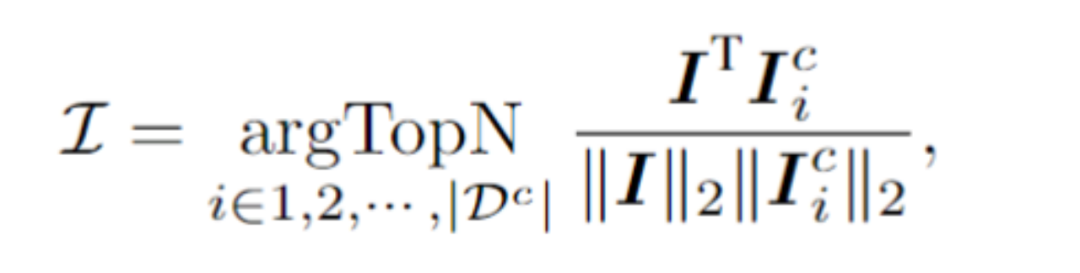
Nachdem die kontextuellen Hinweise und Testbeispiele zusammengefügt und in das Modell eingespeist wurden, lernt E2STR ohne Training neues Wissen aus den kontextuellen Hinweisen und verbessert so die Erkennungsgenauigkeit der Testbeispiele. Es ist wichtig zu beachten, dass der Kontext-Cue-Pool nur die vom visuellen Encoder ausgegebenen Token behält, was den Auswahlprozess für Kontext-Cues sehr effizient macht. Da außerdem der kontextbezogene Hinweispool klein ist und E2STR ohne Training Inferenzen durchführen kann, wird auch der zusätzliche Rechenaufwand minimiert -Domänenszenenerkennung und schwierige Probenkorrektur
1. Traditioneller Datensatz
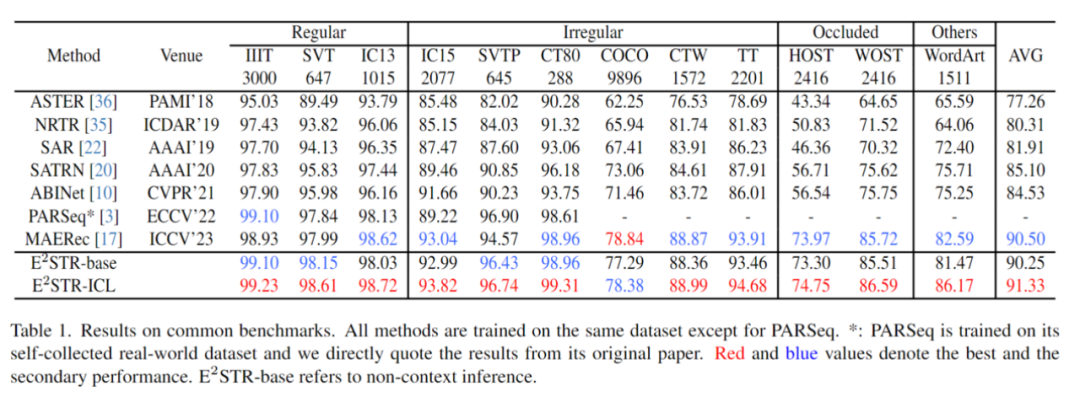
Wählen Sie zufällig einige Proben (1000, 0,025 % der Anzahl der Proben im Trainingssatz) aus, um einen zu bilden Kontext-Prompt-Pool: Der Test wurde mit 12 gängigen Texterkennungstestsätzen für Szenen durchgeführt. Die Ergebnisse lauten wie folgt:
Es kann festgestellt werden, dass E2STR die Erkennungsleistung gegenüber dem herkömmlichen Datensatz immer noch verbessert hat nahezu gesättigt und übertrifft die Leistung des SOTA-Modells.
 Der Inhalt, der neu geschrieben werden muss, ist: 2. Domänenübergreifendes Szenario
Der Inhalt, der neu geschrieben werden muss, ist: 2. Domänenübergreifendes Szenario
Im domänenübergreifenden Szenario stellt jeder Testsatz nur 100 domäneninterne Trainingsbeispiele bereit. Die Vergleichsergebnisse zwischen keinem Training und Feinabstimmung sind wie folgt: E2STR übertrifft sogar die Feinabstimmungsergebnisse der SOTA-Methode.
Der Inhalt, der neu geschrieben werden muss, ist: 3. Schwierige Proben ändern
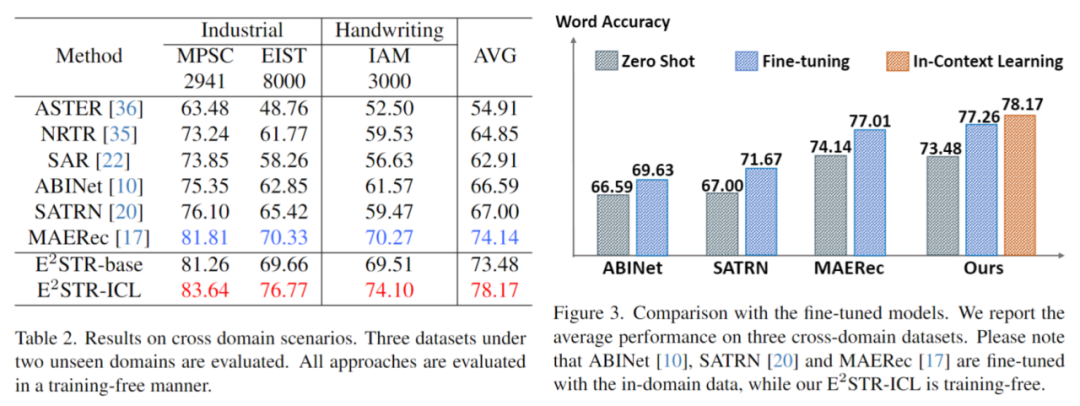
Im Vergleich zur Feinabstimmungsmethode reduziert E2STR-ICL die Fehlerrate schwieriger Proben erheblich
Zukunftsausblick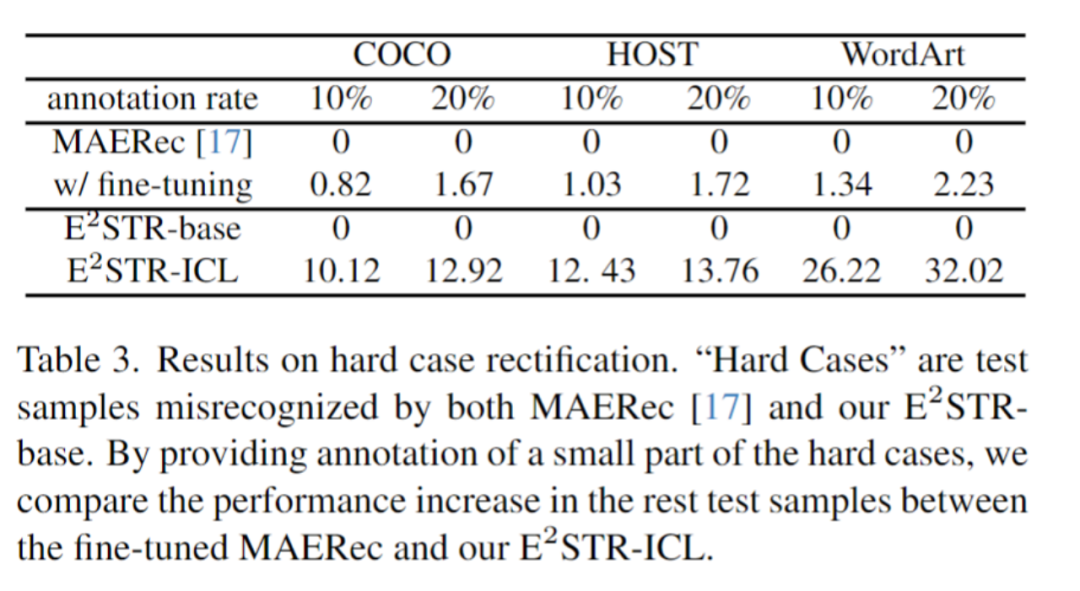
E2STR beweist, dass kleine Modelle mithilfe geeigneter Trainings- und Inferenzstrategien auch über kontextbezogene Lernfähigkeiten ähnlich wie LLM verfügen können. Bei einigen Aufgaben mit hohen Echtzeitanforderungen können auch kleine Modelle verwendet werden, um sich schnell an neue Szenarien anzupassen. Noch wichtiger ist, dass diese Methode der Verwendung eines einzigen Modells zur schnellen Anpassung an neue Szenarien dem Aufbau eines einheitlichen und effizienten kleinen Modells einen Schritt näher kommt.
Das obige ist der detaillierte Inhalt vonDer umformulierte Titel lautet: ByteDance und East China Normal University Cooperation: Exploring the Contextual Learning Capabilities of Small Models. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Tongyi Qianwen ist wieder Open Source, Qwen1.5 bietet sechs Volumenmodelle und seine Leistung übertrifft GPT3.5
Feb 07, 2024 pm 10:15 PM
Tongyi Qianwen ist wieder Open Source, Qwen1.5 bietet sechs Volumenmodelle und seine Leistung übertrifft GPT3.5
Feb 07, 2024 pm 10:15 PM
Pünktlich zum Frühlingsfest ist Version 1.5 des Tongyi Qianwen Large Model (Qwen) online. Heute Morgen erregten die Neuigkeiten über die neue Version die Aufmerksamkeit der KI-Community. Die neue Version des großen Modells umfasst sechs Modellgrößen: 0,5B, 1,8B, 4B, 7B, 14B und 72B. Unter ihnen übertrifft die Leistung der stärksten Version GPT3.5 und Mistral-Medium. Diese Version umfasst das Basismodell und das Chat-Modell und bietet Unterstützung für mehrere Sprachen. Das Tongyi Qianwen-Team von Alibaba gab an, dass die entsprechende Technologie auch auf der offiziellen Website von Tongyi Qianwen und der Tongyi Qianwen App eingeführt wurde. Darüber hinaus bietet die heutige Version von Qwen 1.5 auch die folgenden Highlights: Unterstützt eine Kontextlänge von 32 KB und öffnet den Prüfpunkt des Base+Chat-Modells.
 Verzichten Sie auf die Encoder-Decoder-Architektur und verwenden Sie das Diffusionsmodell zur Kantenerkennung, das effektiver ist. Die National University of Defense Technology hat DiffusionEdge vorgeschlagen
Feb 07, 2024 pm 10:12 PM
Verzichten Sie auf die Encoder-Decoder-Architektur und verwenden Sie das Diffusionsmodell zur Kantenerkennung, das effektiver ist. Die National University of Defense Technology hat DiffusionEdge vorgeschlagen
Feb 07, 2024 pm 10:12 PM
Aktuelle Deep-Edge-Erkennungsnetzwerke verwenden normalerweise eine Encoder-Decoder-Architektur, die Up- und Down-Sampling-Module enthält, um mehrstufige Merkmale besser zu extrahieren. Diese Struktur schränkt jedoch die Ausgabe genauer und detaillierter Kantenerkennungsergebnisse des Netzwerks ein. Als Antwort auf dieses Problem bietet ein Papier zu AAAI2024 eine neue Lösung. Titel der Abschlussarbeit: DiffusionEdge:DiffusionProbabilisticModelforCrispEdgeDetection Autoren: Ye Yunfan (Nationale Universität für Verteidigungstechnologie), Xu Kai (Nationale Universität für Verteidigungstechnologie), Huang Yuxing (Nationale Universität für Verteidigungstechnologie), Yi Renjiao (Nationale Universität für Verteidigungstechnologie), Cai Zhiping (National University of Defense Technology) Link zum Papier: https://ar
 Große Modelle können ebenfalls in Scheiben geschnitten werden, und Microsoft SliceGPT erhöht die Recheneffizienz von LLAMA-2 erheblich
Jan 31, 2024 am 11:39 AM
Große Modelle können ebenfalls in Scheiben geschnitten werden, und Microsoft SliceGPT erhöht die Recheneffizienz von LLAMA-2 erheblich
Jan 31, 2024 am 11:39 AM
Große Sprachmodelle (LLMs) verfügen typischerweise über Milliarden von Parametern und werden auf Billionen von Token trainiert. Die Schulung und Bereitstellung solcher Modelle ist jedoch sehr teuer. Um den Rechenaufwand zu reduzieren, werden häufig verschiedene Modellkomprimierungstechniken eingesetzt. Diese Modellkomprimierungstechniken können im Allgemeinen in vier Kategorien unterteilt werden: Destillation, Tensorzerlegung (einschließlich Faktorisierung mit niedrigem Rang), Bereinigung und Quantisierung. Pruning-Methoden gibt es schon seit einiger Zeit, aber viele erfordern nach dem Pruning eine Feinabstimmung der Wiederherstellung (Recovery Fine-Tuning, RFT), um die Leistung aufrechtzuerhalten, was den gesamten Prozess kostspielig und schwierig zu skalieren macht. Forscher der ETH Zürich und von Microsoft haben eine Lösung für dieses Problem namens SliceGPT vorgeschlagen. Die Kernidee dieser Methode besteht darin, die Einbettung des Netzwerks durch das Löschen von Zeilen und Spalten in der Gewichtsmatrix zu reduzieren.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 LLaVA-1.6, das mit Gemini Pro gleichzieht und die Argumentations- und OCR-Fähigkeiten verbessert, ist zu leistungsstark
Feb 01, 2024 pm 04:51 PM
LLaVA-1.6, das mit Gemini Pro gleichzieht und die Argumentations- und OCR-Fähigkeiten verbessert, ist zu leistungsstark
Feb 01, 2024 pm 04:51 PM
Im April letzten Jahres veröffentlichten Forscher der University of Wisconsin-Madison, Microsoft Research und der Columbia University gemeinsam LLaVA (Large Language and Vision Assistant). Obwohl LLaVA nur mit einem kleinen multimodalen Befehlsdatensatz trainiert wird, zeigt es bei einigen Proben sehr ähnliche Inferenzergebnisse wie GPT-4. Im Oktober brachten sie dann LLaVA-1.5 auf den Markt, das den SOTA in 11 Benchmarks mit einfachen Modifikationen am ursprünglichen LLaVA aktualisierte. Die Ergebnisse dieses Upgrades sind sehr aufregend und bringen neue Durchbrüche auf dem Gebiet der multimodalen KI-Assistenten. Das Forschungsteam kündigte die Einführung der LLaVA-1.6-Version an, die auf Argumentation, OCR und zielt
