
 Technologie-Peripheriegeräte
KI
Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.
Technologie-Peripheriegeräte
KI
Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.
Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.

Welche Erfahrung wird es mit sich bringen, wenn visuelle Eingabeaufforderungen verwendet werden?
Zeichnen Sie einfach eine zufällige Skizze in das Bild und die gleiche Kategorie wird sofort markiert!

Sogar der Link zur Kornzählung ist für GPT-4V schwer zu handhaben. Sie müssen nur manuell an der Kiste ziehen, um alle Reiskörner zu finden.

Mit einem neuen Objekterkennungsparadigma!
Auf der gerade zu Ende gegangenen IDEA-Jahreskonferenz präsentierte Shen Xiangyang, Gründungsvorsitzender des IDEA-Instituts und ausländischer Akademiker der National Academy of Engineering, die neuesten Forschungsergebnisse –
Der Inhalt von T-Rex basiert auf dem Visual Prompt-Modell muss neu geschrieben werden

Der gesamte Prozess ist interaktiv, sofort einsatzbereit und kann in nur wenigen Schritten abgeschlossen werden.
Zuvor segmentierte Metas Open-Source-SAM alle Modelle, was den GPT-3-Moment im Lebenslaufbereich direkt einleitete. Es basierte jedoch immer noch auf dem Text-Prompt-Paradigma, das mit einigen komplexen und seltenen Modellen schwieriger zu handhaben war Szenarien.
Jetzt können Sie das Problem ganz einfach lösen, indem Sie Bilder ändern.
Darüber hinaus ist die gesamte Konferenz auch voller nützlicher Informationen, wie zum Beispiel das wissensgesteuerte Großmodell Think-on-Graph, die Entwicklerplattform MoonBit, das wissenschaftliche KI-Forschungsartefakt ReadPaper Update 2.0, der SPU Confidential Computing Co-Prozessor und das steuerbare Porträtvideo Generationsplattform HiveNet und so weiter.
Schließlich teilte Shun Xiangyang auch das Projekt mit, dem er in den letzten Jahren die meiste Zeit gewidmet hat: Wirtschaft in geringer Höhe.
Ich glaube, wenn die Tieflandwirtschaft relativ ausgereift ist, werden jeden Tag 100.000 Drohnen am Himmel von Shenzhen fliegen und jeden Tag Millionen von Drohnen starten
Verwenden Sie Vision, um Aufforderungen zu geben
T -In Zusätzlich zur grundlegenden Einzelrunden-Eingabeaufforderungsfunktion unterstützt Rex auch drei erweiterte Modi
- Mehrrunden-Positivmodus
Dies ähnelt dem Mehrrundendialog, der genauere Ergebnisse liefern und verpasste Erkennungen vermeiden kann
- Positiv + Der Negativmodus
eignet sich für Szenarien, in denen visuelle Hinweise mehrdeutig sind und zu Fehlerkennungen führen.
Mit dem Kreuzdiagrammmodus können Sie Diagramme neu gestalten und anordnen, um Daten und Informationen einfach zu visualisieren.
Durch die Verwendung eines Referenzdiagramms zur Erkennung anderer Bilder.

Berichten zufolge ist T-Rex nicht auf vordefinierte Kategorien beschränkt und kann dies auch tun Anhand visueller Beispiele werden Erkennungsziele spezifiziert, wodurch das Problem gelöst wird, dass sich bestimmte Objekte nur schwer vollständig in Worte fassen lassen, und die Eingabeaufforderungseffizienz verbessert wird. Gerade bei komplexen Bauteilen in manchen Industrieszenarien ist der Effekt besonders offensichtlich
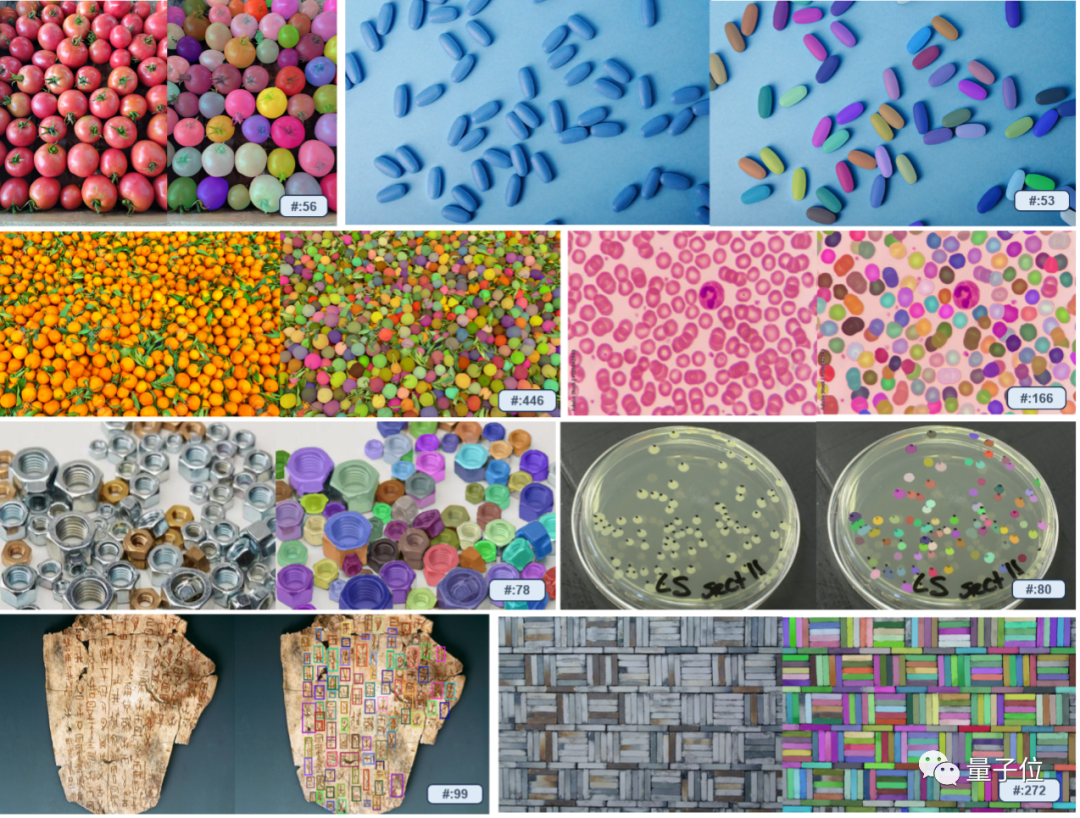
Darüber hinaus können durch die Interaktion mit Benutzern die Erkennungsergebnisse auch jederzeit schnell ausgewertet und Fehlerkorrekturen vorgenommen werden.
T-Rex besteht hauptsächlich aus drei Komponenten: Bild-Encoder, Hinweis-Encoder und Frame-Decoder
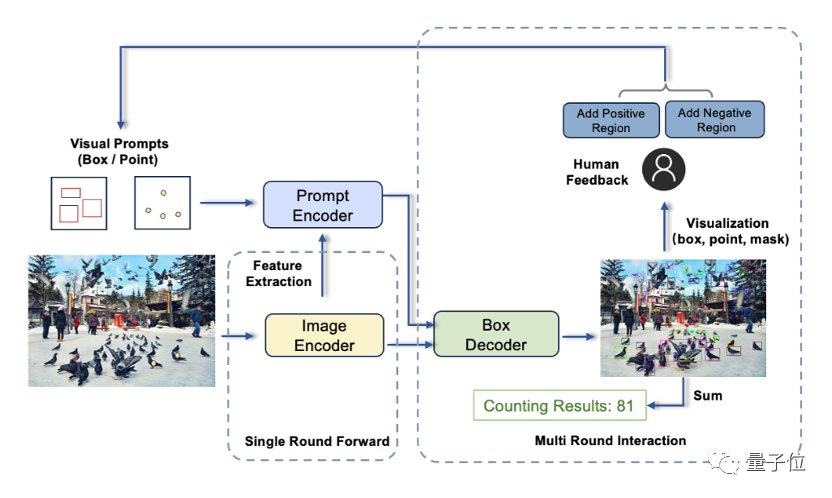
Diese Arbeit stammt vom Computer Vision and Robotics Research Center des IDEA Research Institute.
Das zuvor Open-Source-Zielerkennungsmodell DINO des Teams ist das erste DETR-Modell, das in der COCO-Zielerkennungsliste an erster Stelle steht. Der Zero-Sample-Detektor Grounding DINO ist auf Github sehr beliebt (es hat bisher 11.000 Sterne erhalten) und Geerdetes SAM, das alles erkennen und segmentieren kann. Für weitere technische Details klicken Sie bitte auf den Link am Ende des Artikels.
Die gesamte Konferenz ist voller nützlicher Informationen
Darüber hinaus wurden auf der IDEA-Konferenz auch mehrere Forschungsergebnisse hervorgehoben.
Zum Beispiel kombiniert das Think-on-Graph wissensgesteuerte große Modell, einfach ausgedrückt, große Modelle mit Wissensgraphen.
Große Modelle eignen sich gut für das Verständnis von Absichten und das autonome Lernen, während Wissensgraphen aufgrund ihrer strukturierten Methoden zur Wissensspeicherung besser für das Denken in logischen Ketten geeignet sind.
Think-on-Graph veranlasst den großen Modellagenten dazu, über den Wissensgraphen zu „denken“ und nach und nach die optimale Antwort zu suchen und daraus abzuleiten (suchen und begründen Sie Schritt für Schritt die zugehörigen Entitäten des Wissensgraphen). Bei jedem Schritt des Denkens ist das große Modell persönlich beteiligt und lernt mithilfe des Wissensgraphen von den Stärken und Schwächen des anderen.

MoonBit ist eine von Wasm betriebene Entwicklerplattform, die für Cloud Computing und Edge Computing entwickelt wurde.
Dieses System bietet nicht nur universelles Programmiersprachendesign, sondern integriert auch Compiler, Build-Systeme, integrierte Entwicklungsumgebungen (IDEs), Bereitstellungstools und andere Module, um die Entwicklungserfahrung und -effizienz zu verbessern
Das zuvor veröffentlichte wissenschaftliche Forschungsartefakt ReadPaper Außerdem wurde es auf 2.0 aktualisiert und auf der Pressekonferenz wurden neue Funktionen wie Lese-Copilot und Polier-Copilot demonstriert.

Am Ende der Pressekonferenz veröffentlichte Shen Xiangyang das „Weißbuch zur wirtschaftlichen Entwicklung in geringer Höhe (2.0) – vollständig digitale Lösung“, in dem er den zeitlichen räumlichen Prozess in seinem Smart Integrated Lower Airspace System (SILAS) vorschlug. Prozess) neues Konzept.
T-Rex-Link:
https://trex-counting.github.io/
Das obige ist der detaillierte Inhalt vonNutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Der Unterschied zwischen der Ideen-Community-Version und der professionellen Version
Nov 07, 2023 pm 05:23 PM
Der Unterschied zwischen der Ideen-Community-Version und der professionellen Version
Nov 07, 2023 pm 05:23 PM
Zu den Unterschieden zwischen IDEA Community Edition und Professional Edition gehören Autorisierungsmethoden, Funktionen, Support und Updates, Plug-in-Unterstützung, Cloud-Dienste und Teamzusammenarbeit, mobile Entwicklungsunterstützung, Bildung und Lernen, Integration und Skalierbarkeit, Fehlerbehandlung und Debugging, Sicherheit und Datenschutz Schutz usw. Detaillierte Einführung: 1. Die Community-Version ist kostenlos und für alle Entwickler geeignet, unabhängig vom verwendeten Betriebssystem. Die professionelle Version ist kostenpflichtig und für die kommerzielle Entwicklung geeignet Für die professionelle Version gibt es eine 30-tägige Testphase. Danach müssen Sie eine Lizenz erwerben, um sie weiterhin verwenden zu können usw.
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Fünf IntelliJ IDEA-Plug-Ins zum effizienten Schreiben von Code
Jul 16, 2023 am 08:03 AM
Fünf IntelliJ IDEA-Plug-Ins zum effizienten Schreiben von Code
Jul 16, 2023 am 08:03 AM
Künstliche Intelligenz (KI) ist derzeit ein weithin anerkannter Zukunftstrend und eine Entwicklungsrichtung. Obwohl manche befürchten, dass KI alle Jobs ersetzen könnte, wird sie in Wirklichkeit nur Jobs ersetzen, die sich stark wiederholen und wenig Leistung bringen. Deshalb sollten wir lernen, intelligenter statt härter zu arbeiten. In diesem Artikel werden 5 KI-gesteuerte Intellij-Plug-Ins vorgestellt. Diese Plug-Ins können Ihnen helfen, die Produktivität zu verbessern, mühsame, sich wiederholende Arbeiten zu reduzieren und Ihre Arbeit effizienter und bequemer zu gestalten. 1GithubCopilotGithubCopilot ist ein Code-Unterstützungstool für künstliche Intelligenz, das gemeinsam von OpenAI und GitHub entwickelt wurde. Es nutzt das GPT-Modell von OpenAI, um den Codekontext zu analysieren, neuen Code vorherzusagen und zu generieren
 Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Oct 16, 2023 am 11:33 AM
Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Oct 16, 2023 am 11:33 AM
1 Einleitung Neural Radiation Fields (NeRF) sind ein relativ neues Paradigma im Bereich Deep Learning und Computer Vision. Diese Technologie wurde im ECCV2020-Papier „NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis“ (das mit dem Best Paper Award ausgezeichnet wurde) vorgestellt und erfreut sich seitdem mit bisher fast 800 Zitaten äußerster Beliebtheit [1]. Der Ansatz markiert einen grundlegenden Wandel in der traditionellen Art und Weise, wie maschinelles Lernen 3D-Daten verarbeitet. Darstellung neuronaler Strahlungsfelder und differenzierbarer Rendering-Prozess: Zusammengesetzte Bilder durch Abtasten von 5D-Koordinaten (Position und Blickrichtung) entlang der Kamerastrahlen, Eingabe dieser Positionen in ein MLP, um mithilfe volumetrischer Rendering-Techniken Bilder zu erzeugen; ; Die Rendering-Funktion ist differenzierbar und kann daher übergeben werden
 Idee, wie man mehrere SpringBoot-Projekte startet
May 28, 2023 pm 06:46 PM
Idee, wie man mehrere SpringBoot-Projekte startet
May 28, 2023 pm 06:46 PM
1. Vorbereitung Verwenden Sie Idea, um ein Helloworld-SpringBoot-Projekt zu erstellen. Beschreibung der Entwicklungsumgebung: (1) SpringBoot2.7.0 (2) Idee: IntelliJIDEA2022.2.2 (3) Betriebssystem: Die MacOS-Umgebung ist anders. Einige Vorgänge unterscheiden sich geringfügig, aber die Gesamtidee ist dieselbe. 2. Starten Sie mehrere SpringBoot2.1-Lösungen 1: Ändern Sie den Port der Konfigurationsdatei. Im SpringBoot-Projekt kann die Portnummer in der Konfigurationsdatei konfiguriert werden. Daher besteht die einfachste Lösung darin, den Port der Konfiguration zu ändern Dateianwendung.(properties/yml) Konfigurationen
 So lösen Sie das Problem, dass leere Mapper automatisch in das Idee-SpringBoot-Projekt eingefügt werden
May 17, 2023 pm 06:49 PM
So lösen Sie das Problem, dass leere Mapper automatisch in das Idee-SpringBoot-Projekt eingefügt werden
May 17, 2023 pm 06:49 PM
Wenn im SpringBoot-Projekt MyBatis als Persistenzschicht-Framework verwendet wird, kann es bei Verwendung der automatischen Injektion zu dem Problem kommen, dass der Mapper eine Nullzeiger-Ausnahme meldet. Dies liegt daran, dass SpringBoot die Mapper-Schnittstelle von MyBatis während der automatischen Injektion nicht korrekt identifizieren kann und einige zusätzliche Konfigurationen erfordert. Es gibt zwei Möglichkeiten, dieses Problem zu lösen: 1. Fügen Sie der Mapper-Schnittstelle die Annotation @Mapper hinzu, um SpringBoot mitzuteilen, dass es sich bei dieser Schnittstelle um eine Mapper-Schnittstelle handelt und ein Proxy erforderlich ist. Ein Beispiel lautet wie folgt: @MapperpublicinterfaceUserMapper{//...}2
 Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Jun 02, 2024 pm 03:24 PM
Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Jun 02, 2024 pm 03:24 PM
Eine rein visuelle Annotationslösung nutzt hauptsächlich die visuelle Darstellung sowie einige Daten von GPS, IMU und Radgeschwindigkeitssensoren für die dynamische Annotation. Für Massenproduktionsszenarien muss es sich natürlich nicht nur um visuelle Aspekte handeln. Einige in Massenproduktion hergestellte Fahrzeuge verfügen über Sensoren wie Festkörperradar (AT128). Wenn wir aus Sicht der Massenproduktion einen geschlossenen Datenkreislauf erstellen und alle diese Sensoren verwenden, können wir das Problem der Kennzeichnung dynamischer Objekte effektiv lösen. Aber in unserem Plan gibt es kein Festkörperradar. Aus diesem Grund stellen wir diese gängigste Etikettierungslösung für die Massenproduktion vor. Der Kern einer rein visuellen Annotationslösung liegt in der hochpräzisen Posenrekonstruktion. Wir verwenden das Posenrekonstruktionsschema von Structure from Motion (SFM), um die Genauigkeit der Rekonstruktion sicherzustellen. Aber pass
 So lösen Sie das Problem, dass die Springboot-Hot-Bereitstellung in Idea ungültig ist
May 18, 2023 pm 06:01 PM
So lösen Sie das Problem, dass die Springboot-Hot-Bereitstellung in Idea ungültig ist
May 18, 2023 pm 06:01 PM
一、开启idea自动make功能1-EnableAutomakefromthecompilerDRÜCKEN:STRG+UMSCHALT+ATYPE:Projekt automatisch erstellenDRÜCKEN:EingabetasteEnableMakeProjectautomaticallyfeature2-EnableAutomakewhentheapplicationisrunDRÜCKEN:STRG+UMSCHALT+ATYPE:RegistrierungFindthekeycompiler.automake.allow.
