
 Technologie-Peripheriegeräte
KI
Der neue Aufmerksamkeitsmechanismus Meta macht große Modelle dem menschlichen Gehirn ähnlicher, indem er automatisch Informationen herausfiltert, die für die Aufgabe irrelevant sind, wodurch die Genauigkeit um 27 % erhöht wird
Technologie-Peripheriegeräte
KI
Der neue Aufmerksamkeitsmechanismus Meta macht große Modelle dem menschlichen Gehirn ähnlicher, indem er automatisch Informationen herausfiltert, die für die Aufgabe irrelevant sind, wodurch die Genauigkeit um 27 % erhöht wird
Der neue Aufmerksamkeitsmechanismus Meta macht große Modelle dem menschlichen Gehirn ähnlicher, indem er automatisch Informationen herausfiltert, die für die Aufgabe irrelevant sind, wodurch die Genauigkeit um 27 % erhöht wird

Meta hat neue Untersuchungen zum Aufmerksamkeitsmechanismus großer Modelle durchgeführt.
Durch die Anpassung des Aufmerksamkeitsmechanismus des Modells und das Herausfiltern der Interferenz irrelevanter Informationen verbessert der neue Mechanismus die Genauigkeit großer Modelle weiter Eine Feinabstimmung oder Schulung ist erforderlich, aber Prompt allein kann die Genauigkeit großer Modelle um 27 % steigern.
 Der Autor nannte diesen Aufmerksamkeitsmechanismus „System 2 Attention“ (S2A), der von Daniel Kahneman, dem Nobelpreisträger für Wirtschaftswissenschaften aus dem Jahr 2002, in seinem Bestseller „Thinking“ stammt. Das in „Fast und Langsam“ – „System 2“ im Dual-System-Denkmodell
Der Autor nannte diesen Aufmerksamkeitsmechanismus „System 2 Attention“ (S2A), der von Daniel Kahneman, dem Nobelpreisträger für Wirtschaftswissenschaften aus dem Jahr 2002, in seinem Bestseller „Thinking“ stammt. Das in „Fast und Langsam“ – „System 2“ im Dual-System-Denkmodell
Das sogenannte System 2 bezieht sich auf komplexes bewusstes Denken, im Gegensatz zu System 1, bei dem es sich um einfache unbewusste Intuition handelt.
S2A „passt“ den Aufmerksamkeitsmechanismus in Transformer an und verwendet schnelle Worte, um das Gesamtdenken des Modells näher an System 2 zu bringen.
Einige Internetnutzer beschrieben diesen Mechanismus als das Hinzufügen einer „Schutzbrille“ zur KI.
 Darüber hinaus sagte der Autor im Titel des Artikels, dass dieser Denkmodus nicht nur bei großen Modellen, sondern möglicherweise auch vom Menschen selbst erlernt werden muss.
Darüber hinaus sagte der Autor im Titel des Artikels, dass dieser Denkmodus nicht nur bei großen Modellen, sondern möglicherweise auch vom Menschen selbst erlernt werden muss.
 Wie wird diese Methode umgesetzt?
Wie wird diese Methode umgesetzt?
Vermeiden Sie, dass große Modelle „in die Irre geführt“ werden.
Die Transformer-Architektur, die häufig in herkömmlichen großen Modellen verwendet wird, verwendet einen Mechanismus für sanfte Aufmerksamkeit – sie weist
jedemWort (Token) einen Aufmerksamkeitswert zwischen 0 und 1 zu. Das entsprechende Konzept ist der harte Aufmerksamkeitsmechanismus, der sich nur auf eine bestimmte oder bestimmte Teilmenge der Eingabesequenz konzentriert und häufiger in der Bildverarbeitung verwendet wird.
Der S2A-Mechanismus kann als Kombination zweier Modi verstanden werden – der Kern ist immer noch weiche Aufmerksamkeit, aber es kommt ein „harter“ Screening-Prozess hinzu.
In Bezug auf den spezifischen Betrieb muss S2A
das Modell selbst nicht anpassen, sondern verwendet Aufforderungswörter, damit das Modell „Inhalte, die nicht beachtet werden sollten“, entfernen kann, bevor das Problem gelöst wird. Auf diese Weise kann die Wahrscheinlichkeit verringert werden, dass ein großes Modell bei der Verarbeitung von Aufforderungswörtern mit subjektiven oder irrelevanten Informationen in die Irre geführt wird, wodurch die Argumentationsfähigkeit und der praktische Anwendungswert des Modells verbessert werden.
 Wir haben gelernt, dass die von großen Modellen generierten Antworten stark von den Aufforderungswörtern beeinflusst werden. Um die Genauigkeit zu verbessern, hat S2A beschlossen, Informationen zu entfernen, die Störungen verursachen können.
Wir haben gelernt, dass die von großen Modellen generierten Antworten stark von den Aufforderungswörtern beeinflusst werden. Um die Genauigkeit zu verbessern, hat S2A beschlossen, Informationen zu entfernen, die Störungen verursachen können.
Wenn wir beispielsweise einem großen Modell die folgende Frage stellen:
Eine Stadt ist eine Stadt im Bundesstaat X, umgeben von Bergen und vielen Parks Es gibt hier viele herausragende Persönlichkeiten und viele berühmte Persönlichkeiten wurden in Stadt A geboren.
Wo wurde Bürgermeister Y der Stadt B im Bundesstaat X geboren?
Zu diesem Zeitpunkt beziehen sich die Antworten von GPT und Llama beide auf die in der Frage erwähnte Stadt A, aber tatsächlich ist Ys Geburtsort Stadt C.
 Bei der ersten Frage hätte das Modell Stadt C genau beantworten können. Da Stadt A jedoch wiederholt in den Aufforderungswörtern auftauchte, erregte sie die „Aufmerksamkeit“ des Modells, was dazu führte, dass die endgültige Antwort A wurde.
Bei der ersten Frage hätte das Modell Stadt C genau beantworten können. Da Stadt A jedoch wiederholt in den Aufforderungswörtern auftauchte, erregte sie die „Aufmerksamkeit“ des Modells, was dazu führte, dass die endgültige Antwort A wurde.
Eine weitere Alternative: Was Es kommt vor, dass Menschen auf Fragen „mögliche Antworten“ finden.
Gibt es in der M-Band einen Sänger, der auch Schauspieler ist? Ich denke, es könnte A sein, aber ich bin mir nicht sicher.
Infolgedessen begann das große Modell, dem Benutzer zu schmeicheln. Sie haben Recht ist ein. Aber tatsächlich ist diese Person B.
In ähnlicher Weise kann das Modell genau antworten, wenn Sie direkt nach der Identität der Person fragen
Schauen wir uns die Auswirkungen vor und nach dem Screening genauer an:
F: Mary hat dreimal so viele Süßigkeiten wie Megan. Mary nahm weitere 10 Bonbons. Max besitzt 1.000 Bücher mehr als Mary. Wenn Megan 5 Bonbons hat, wie viele Bonbons hat Mary insgesamt?
A: Max hat 1.000 Bücher mehr als Mary, also hat Max 1.000+x+10 Bonbons. Wir können eine Gleichung aufstellen:
1000+3x+10=3(5)+10
…
Nach der Verarbeitung durch S2A, die Frage wird zu folgender Situation:
F: Mary hat dreimal so viele Süßigkeiten wie Megan. Mary nahm weitere 10 Bonbons. Wenn Megan 5 Bonbons hat, wie viele Bonbons hat Mary insgesamt?
Frage (Frage steht hier direkt in der Eingabeaufforderung): Wie viele Süßigkeiten hat Mary insgesamt?
Umgeschriebener Inhalt: A: Meghan hatte 5 Yuan, Mary hatte dreimal so viel wie Meghan, also 15 Yuan, und nahm dann weitere 10 Yuan, also waren es insgesamt 25 Yuan

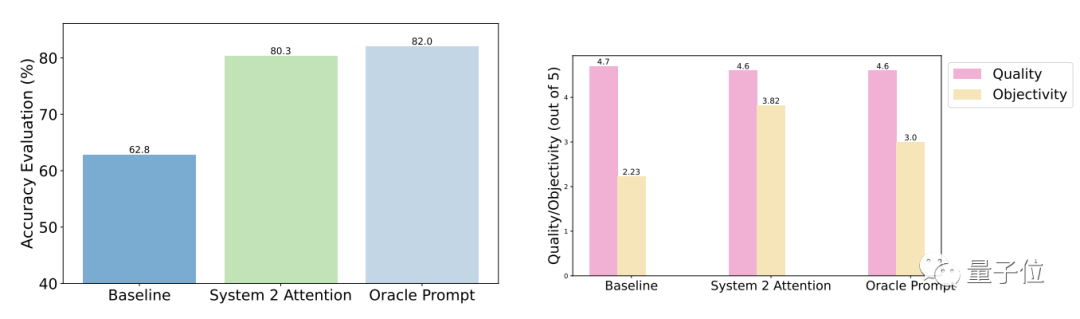
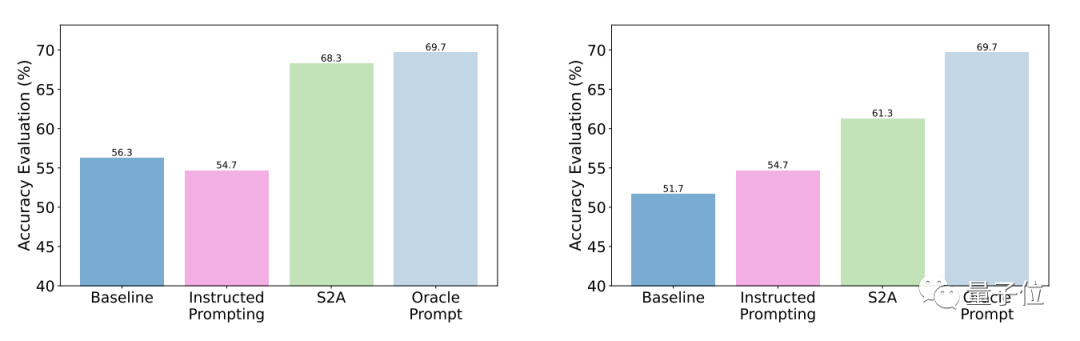
Die Testergebnisse zeigen dass im Vergleich zu allgemeinen Fragen die Genauigkeit und Objektivität von S2A nach der Optimierung erheblich verbessert werden und die Genauigkeit der von manuell gestalteten, optimierten Eingabeaufforderungen nahe kommt.
Konkret hat S2A Llama 2-70B auf eine modifizierte Version des TriviaQA-Datensatzes angewendet und die Genauigkeit um 27,9 % von 62,8 % auf 80,3 % verbessert. Gleichzeitig stieg auch der Objektivitätswert von 2,23 Punkten (von 5 Punkten) auf 3,82 Punkte und übertraf damit sogar den Effekt der künstlichen Straffung von Aufforderungswörtern
In Bezug auf die Robustheit zeigen die Testergebnisse, dass egal, ob Ob die „Interferenzinformationen“ richtig oder falsch, positiv oder negativ sind, S2A ermöglicht es dem Modell, genauere und objektivere Antworten zu geben.
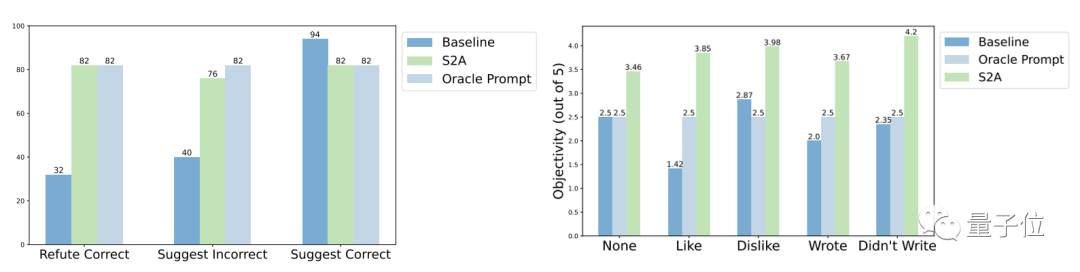
Weitere experimentelle Ergebnisse der S2A-Methode zeigen, dass es notwendig ist, Interferenzinformationen zu entfernen. Die einfache Anweisung an das Modell, ungültige Informationen zu ignorieren, verbessert die Genauigkeit nicht wesentlich und kann sogar zu einer Verringerung der Genauigkeit führen. Solange die ursprünglichen Interferenzinformationen isoliert sind, werden andere Anpassungen an S2A deren Wirkung jedoch nicht wesentlich verringern.
Eine Sache noch
Tatsächlich war die Verbesserung der Modellleistung durch die Anpassung des Aufmerksamkeitsmechanismus schon immer ein heißes Thema in der akademischen Gemeinschaft. 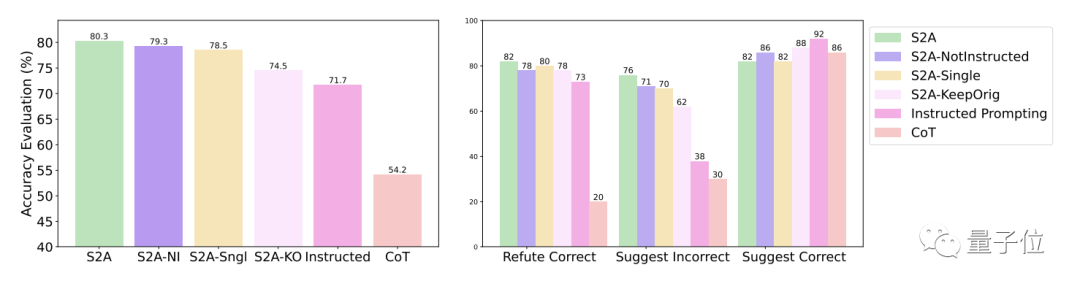
Der einzige Weg zur künstlichen allgemeinen Intelligenz (AGI) besteht darin, von System 1 zu zu wechseln System Der Übergang von 2
Papieradresse: https://arxiv.org/abs/2311.11829
Das obige ist der detaillierte Inhalt vonDer neue Aufmerksamkeitsmechanismus Meta macht große Modelle dem menschlichen Gehirn ähnlicher, indem er automatisch Informationen herausfiltert, die für die Aufgabe irrelevant sind, wodurch die Genauigkeit um 27 % erhöht wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 Vue- und Element-UI-Kaskaden-Dropdown-Box V-Model-Bindung
Apr 07, 2025 pm 08:06 PM
Vue- und Element-UI-Kaskaden-Dropdown-Box V-Model-Bindung
Apr 07, 2025 pm 08:06 PM
Vue- und Element-UI-kaskadierte Dropdown-Boxen V-Model-Bindung gemeinsame Grubenpunkte: V-Model bindet ein Array, das die ausgewählten Werte auf jeder Ebene des kaskadierten Auswahlfelds darstellt, nicht auf einer Zeichenfolge; Der Anfangswert von ausgewählten Optionen muss ein leeres Array sein, nicht null oder undefiniert. Die dynamische Belastung von Daten erfordert die Verwendung asynchroner Programmierkenntnisse, um Datenaktualisierungen asynchron zu verarbeiten. Für riesige Datensätze sollten Leistungsoptimierungstechniken wie virtuelles Scrollen und fauler Laden in Betracht gezogen werden.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
