

Die rasante Entwicklung großer Sprachmodelle in diesem Jahr hat dazu geführt, dass Modelle wie BERT jetzt als „kleine“ Modelle bezeichnet werden. Beim LLM-Wettbewerb für naturwissenschaftliche Prüfungen von Kaggle erreichten Spieler, die Deberta nutzten, den vierten Platz, was ein hervorragendes Ergebnis ist. Daher ist in einem bestimmten Bereich oder Bedarf nicht unbedingt ein großes Sprachmodell als beste Lösung erforderlich, und auch kleine Modelle haben ihren Platz. Daher stellen wir heute PubMedBERT vor, ein von Microsoft Research bei ACM im Jahr 2022 veröffentlichtes Papier. Dieses Modell trainiert BERT von Grund auf vor, indem es domänenspezifische Korpora verwendet. Das Folgende sind die wichtigsten Punkte des Papiers:
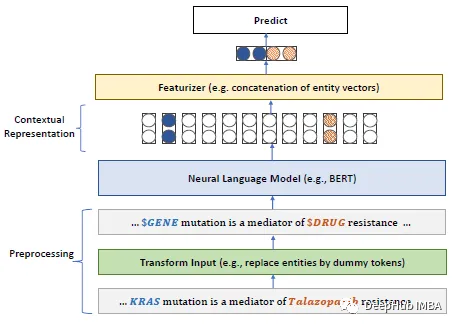 Für bestimmte Bereiche mit großen Mengen an unbeschriftetem Text, wie z. B. im biomedizinischen Bereich, ist das Vortraining von Sprachmodellen von Grund auf effektiver als das kontinuierliche Vortraining von Sprachmodellen für allgemeine Domänen. Zu diesem Zweck schlagen wir den Biomedical Language Understanding and Reasoning Benchmark (BLURB) für domänenspezifisches Vortraining vor.
Für bestimmte Bereiche mit großen Mengen an unbeschriftetem Text, wie z. B. im biomedizinischen Bereich, ist das Vortraining von Sprachmodellen von Grund auf effektiver als das kontinuierliche Vortraining von Sprachmodellen für allgemeine Domänen. Zu diesem Zweck schlagen wir den Biomedical Language Understanding and Reasoning Benchmark (BLURB) für domänenspezifisches Vortraining vor.
PubMedBERT
1, domänenspezifisches Vortraining. Untersuchungen zeigen, dass man bei Null anfangen kann -spezifisches Vortraining übertrifft das kontinuierliche Vortraining von Allzweck-Sprachmodellen deutlich, was zeigt, dass die vorherrschenden Annahmen, die dem Vortraining für gemischte Domänen zugrunde liegen, nicht immer zutreffen.
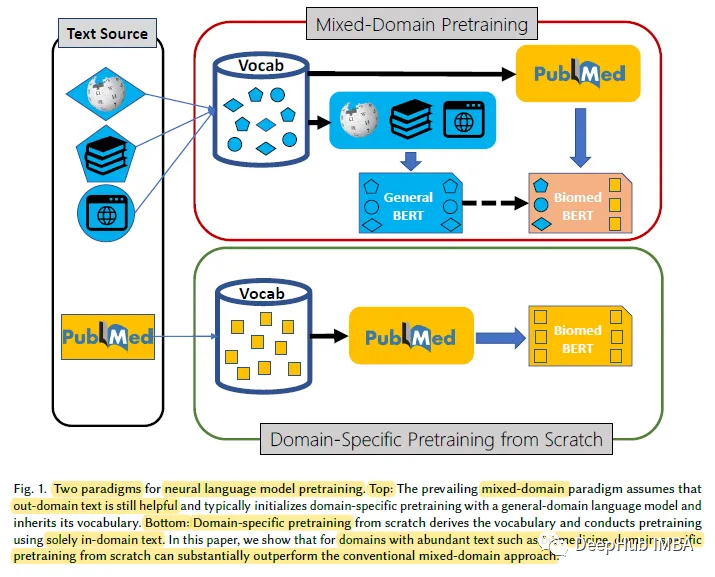
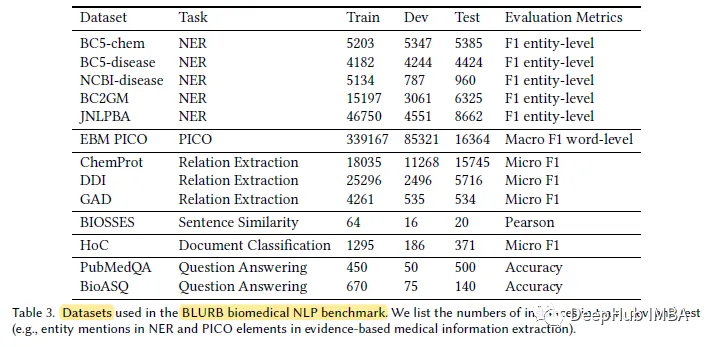
PubMedBERT übertrifft durchweg alle anderen BERT-Modelle bei den meisten Aufgaben der biomedizinischen Verarbeitung natürlicher Sprache (NLP), oft mit einem klaren Vorteil
Das obige ist der detaillierte Inhalt vonSpezifische vorab trainierte Modelle für den biomedizinischen NLP-Bereich: PubMedBERT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



