
 Technologie-Peripheriegeräte
KI
FlashOcc: Neue Ideen für die Belegungsvorhersage, neue SOTA in Bezug auf Genauigkeit, Effizienz und Speichernutzung!
Technologie-Peripheriegeräte
KI
FlashOcc: Neue Ideen für die Belegungsvorhersage, neue SOTA in Bezug auf Genauigkeit, Effizienz und Speichernutzung!
FlashOcc: Neue Ideen für die Belegungsvorhersage, neue SOTA in Bezug auf Genauigkeit, Effizienz und Speichernutzung!

Originaltitel: FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Papierlink: https://arxiv.org/pdf/2311.12058.pdf
Autorenzugehörigkeit: Dalian University of Technology Houmo AI Ade Rider University

Idee für die Abschlussarbeit:
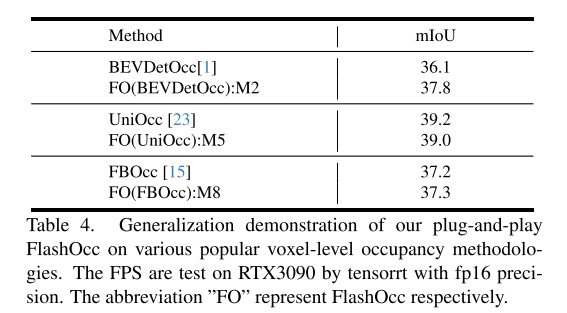
Die Belegungsvorhersage ist aufgrund ihrer Fähigkeit, Long-Tail-Defekte und komplexe Formlöschungen, die bei der 3D-Objekterkennung vorherrschen, zu einer Schlüsselkomponente autonomer Fahrsysteme geworden. Allerdings führt die Verarbeitung dreidimensionaler Darstellungen auf Voxelebene unweigerlich zu einem erheblichen Speicher- und Rechenaufwand, der den Einsatz bisheriger Methoden zur Belegungsvorhersage behindert. Entgegen dem Trend, Modelle größer und komplexer zu machen, argumentiert dieser Artikel, dass ein ideales Framework über verschiedene Chips hinweg einsetzbar sein und gleichzeitig eine hohe Genauigkeit beibehalten sollte. Zu diesem Zweck schlägt dieses Papier ein Plug-and-Play-Paradigma, FlashOCC, vor, um eine schnelle und speichereffiziente Belegungsvorhersage zu konsolidieren und gleichzeitig eine hohe Genauigkeit beizubehalten. Insbesondere führt unser FlashOCC zwei Verbesserungen durch, die auf modernen Methoden zur Vorhersage der Belegung auf Voxelebene basieren. Erstens bleiben Merkmale in BEV erhalten, was die Verwendung effizienter 2D-Faltungsschichten zur Merkmalsextraktion ermöglicht. Zweitens wird die Kanal-zu-Höhe-Transformation eingeführt, um die Ausgabeprotokolle von BEV in den 3D-Raum zu übertragen. In diesem Artikel wird FlashOCC auf verschiedene Basislinien zur Belegungsvorhersage des anspruchsvollen Occ3D-nuScenes-Benchmarks angewendet und umfangreiche Experimente durchgeführt, um seine Wirksamkeit zu überprüfen. Die Ergebnisse bestätigen, dass unser Plug-and-Play-Paradigma frühere Methoden auf dem neuesten Stand der Technik in Bezug auf Genauigkeit, Laufzeiteffizienz und Speicherkosten übertrifft und sein Einsatzpotenzial unter Beweis stellt. Der Code steht zur Nutzung zur Verfügung.
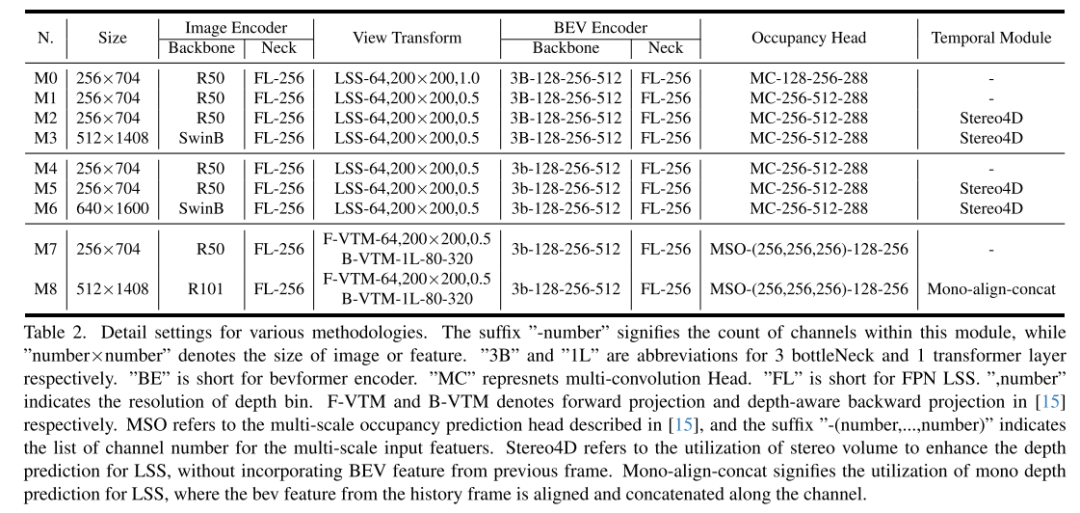
Netzwerkdesign:
Inspiriert von der Subpixel-Faltungstechnologie [26] ersetzen wir Bild-Upsampling durch Kanalneuanordnung, um eine Kanal-zu-Raum-Feature-Konvertierung zu erreichen. In dieser Studie zielen wir darauf ab, eine effiziente Konvertierung von Kanal-zu-Höhe-Funktionen zu erreichen. In Anbetracht der Entwicklung von BEV-Wahrnehmungsaufgaben, bei denen jedes Pixel in der BEV-Darstellung Informationen über das entsprechende Säulenobjekt in der Höhendimension enthält, nutzen wir intuitiv die Kanal-zu-Höhe-Transformation, um die BEV-Merkmale in 3D-Belegungsprotokolle auf Voxelebene umzuformen . Daher konzentriert sich unsere Forschung auf die generische und Plug-and-Play-Verbesserung vorhandener Modelle und nicht auf die Entwicklung neuartiger Modellarchitekturen, wie in Abbildung 1(a) dargestellt. Insbesondere verwenden wir in modernen Methoden direkt 2D-Faltungen anstelle von 3D-Faltungen und ersetzen die aus den 3D-Faltungsausgaben abgeleiteten Belegungsprotokolle durch Kanal-zu-Höhe-Transformationen von BEV-Level-Merkmalen, die durch 2D-Faltungen erhalten wurden. Diese Modelle erzielen nicht nur den besten Kompromiss zwischen Genauigkeit und Zeitverbrauch, sondern weisen auch eine hervorragende Einsatzkompatibilität auf.
FlashOcc hat die 3D-Belegungsvorhersage in Echtzeit mit extrem hoher Genauigkeit erfolgreich abgeschlossen und stellt damit die besten bahnbrechenden Beiträge auf diesem Gebiet dar. Darüber hinaus zeigt es eine verbesserte Vielseitigkeit für den Einsatz auf verschiedenen Fahrzeugplattformen, da keine teure Merkmalsverarbeitung auf Voxelebene erforderlich ist und Ansichtstransformatoren oder 3D-Faltungsoperatoren (verformbar) vermieden werden. Wie in Abbildung 2 dargestellt, bestehen die Eingabedaten von FlashOcc aus Surround-Bildern, während die Ausgabe aus Ergebnissen zur Vorhersage dichter Belegung besteht. Obwohl sich FlashOcc in diesem Artikel auf die vielseitige Plug-and-Play-Verbesserung vorhandener Modelle konzentriert, kann es dennoch in fünf Grundmodule unterteilt werden: (1) 2D-Bildcodierer, der für das Extrahieren von Bildmerkmalen aus Bildern mit mehreren Kameras verantwortlich ist. (2) Ein Ansichtstransformationsmodul, das dabei hilft, Bildmerkmale der 2D-Wahrnehmungsansicht auf 3D-BEV-Darstellungen abzubilden. (3) BEV-Encoder, verantwortlich für die Verarbeitung der BEV-Funktionsinformationen. (4) Besetzen Sie das Vorhersagemodul, um die Segmentierungsbezeichnung jedes Voxels vorherzusagen. (5) Ein optionales zeitliches Fusionsmodul zur Integration historischer Informationen zur Verbesserung der Leistung.
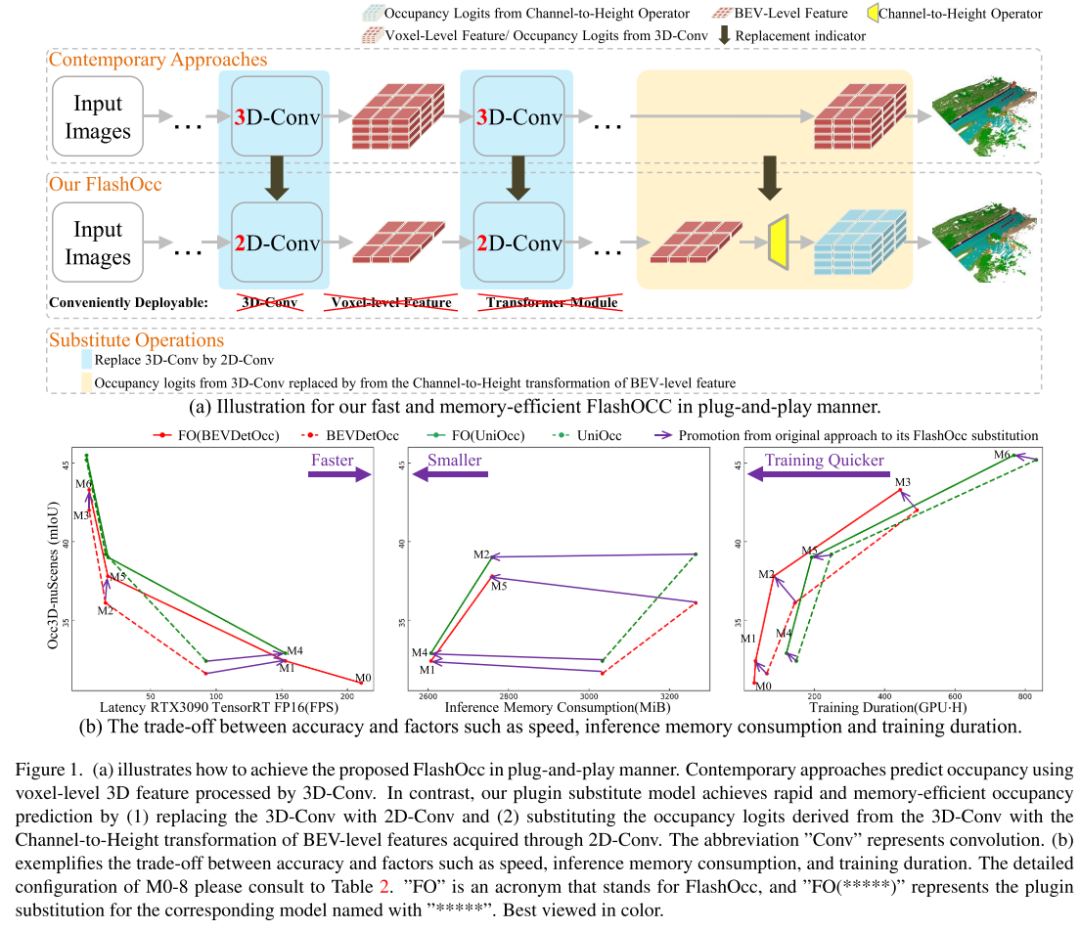
Abbildung 1.(a) zeigt, wie das vorgeschlagene FlashOcc per Plug-and-Play implementiert werden kann. Moderne Methoden nutzen 3D-Merkmale auf Voxelebene, die von 3D-Conv verarbeitet werden, um die Belegung vorherzusagen. Im Gegensatz dazu wird unser Plug-in-Ersatzmodell implementiert, indem (1) 3D-Conv durch 2D-Conv ersetzt wird und (2) die von 3D-Conv abgeleiteten Belegungsprotokolle durch eine schnelle und speichereffiziente Belegung von Kanal zu Höhe ersetzt werden Vorhersage von BEV-Level-Features, die über 2D-Conv erhalten wurden. Die Abkürzung „Conv“ steht für Convolution. (b) veranschaulicht den Kompromiss zwischen Genauigkeit und Faktoren wie Geschwindigkeit, Inferenzspeicherverbrauch und Trainingsdauer.
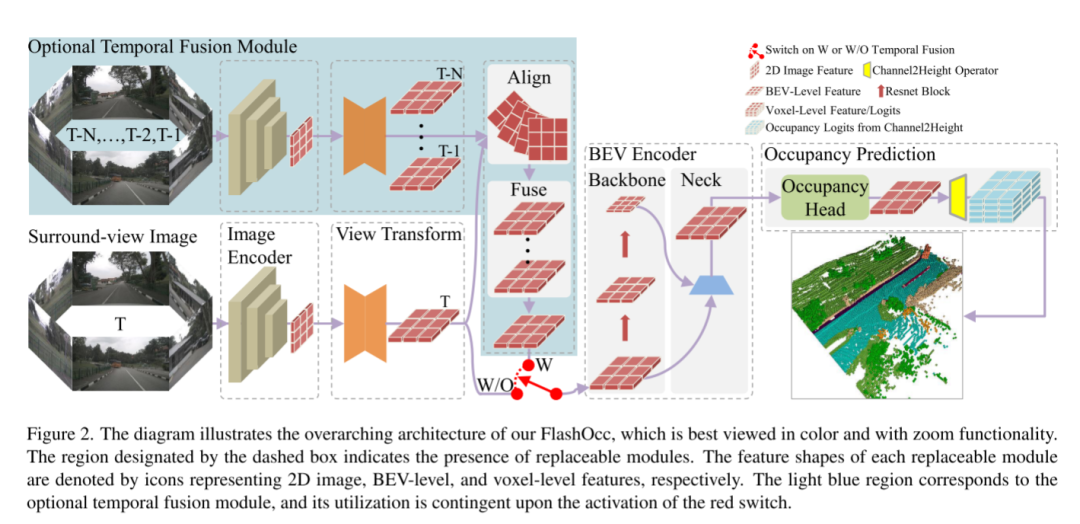
Abbildung 2. Diese Abbildung veranschaulicht die Gesamtarchitektur von FlashOcc und lässt sich am besten in Farbe mit Zoomfunktionen betrachten. Der durch das gestrichelte Kästchen gekennzeichnete Bereich zeigt das Vorhandensein austauschbarer Module an. Die Merkmalsform jedes austauschbaren Moduls wird durch Symbole dargestellt, die jeweils 2D-Bild-, BEV-Level- und Voxel-Level-Features darstellen. Der hellblaue Bereich entspricht dem optionalen Temporalfusionsmodul, dessen Nutzung von der Aktivierung des roten Schalters abhängt.
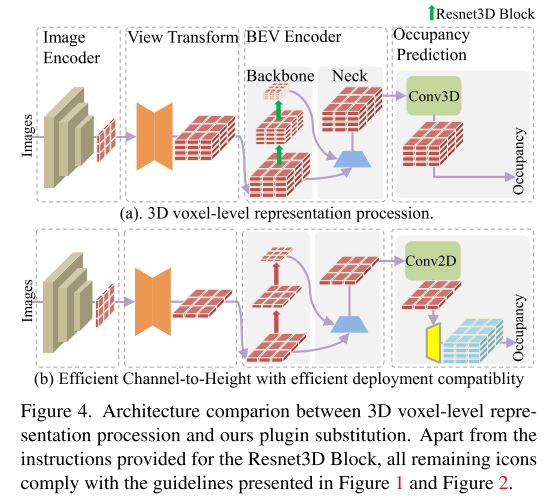
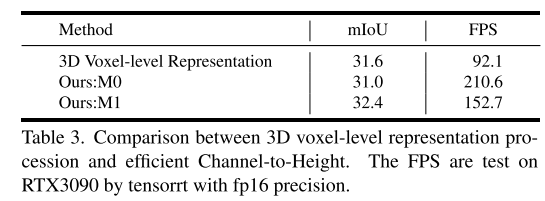
Abbildung 4 zeigt den Architekturvergleich zwischen der 3D-Darstellungsverarbeitung auf Voxelebene und dem in diesem Artikel vorgeschlagenen Plug-in-Ersatz
 Zusammenfassung:
Zusammenfassung: 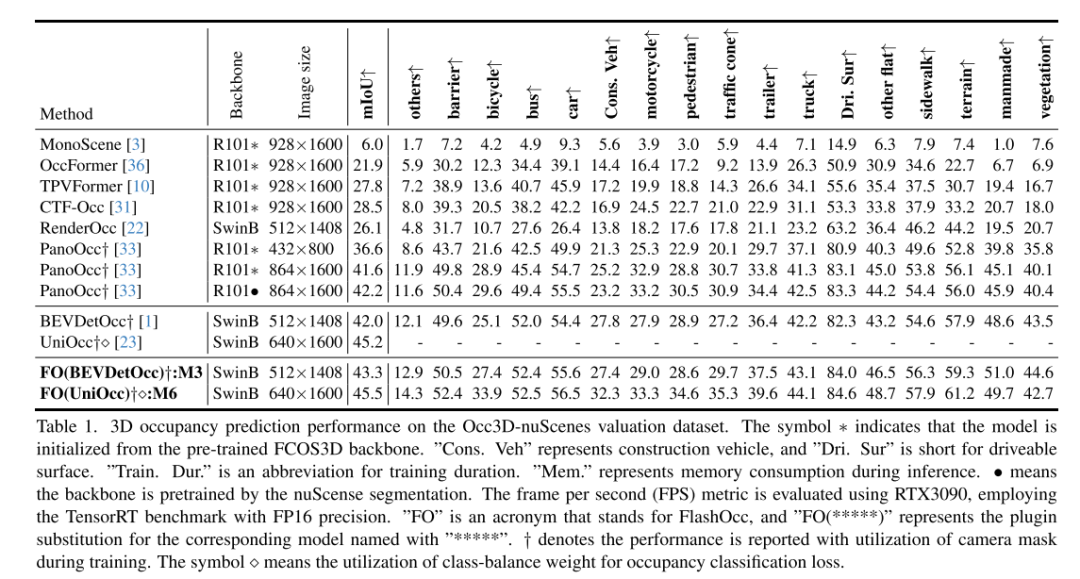
 Originallink: https://mp.weixin.qq.com/s/JDPlWj8FnZffJZc9PIsvXQ
Originallink: https://mp.weixin.qq.com/s/JDPlWj8FnZffJZc9PIsvXQ
Das obige ist der detaillierte Inhalt vonFlashOcc: Neue Ideen für die Belegungsvorhersage, neue SOTA in Bezug auf Genauigkeit, Effizienz und Speichernutzung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
