
 Technologie-Peripheriegeräte
KI
Kleiner Maßstab, hohe Effizienz: DeepMind bringt multimodale Lösung Mirasol 3B auf den Markt
Technologie-Peripheriegeräte
KI
Kleiner Maßstab, hohe Effizienz: DeepMind bringt multimodale Lösung Mirasol 3B auf den Markt
Kleiner Maßstab, hohe Effizienz: DeepMind bringt multimodale Lösung Mirasol 3B auf den Markt

Eine der größten Herausforderungen beim multimodalen Lernen ist die Notwendigkeit, heterogene Modalitäten wie Text, Audio und Video zu kombinieren. Multimodale Modelle müssen Signale aus verschiedenen Quellen kombinieren. Diese Modalitäten weisen jedoch unterschiedliche Merkmale auf und lassen sich nur schwer in einem einzigen Modell kombinieren. Beispielsweise haben Video und Text unterschiedliche Abtastraten
Kürzlich hat das Forschungsteam von Google DeepMind das multimodale Modell in mehrere unabhängige, spezialisierte autoregressive Modelle entkoppelt, um sie entsprechend den Merkmalen verschiedener Modalitäten zu verarbeiten.
Konkret schlägt die Studie ein multimodales Modell namens Mirasol3B vor. Mirasol3B besteht aus zeitsynchronisierten autoregressiven Komponenten für Audio und Video sowie autoregressiven Komponenten für kontextuelle Modalitäten. Diese Modalitäten sind nicht unbedingt zeitlich ausgerichtet, sondern sequentiell angeordnet. Adresse des Papiers: https://arxiv.org/abs/2311.05698 Durch das Erlernen kompakterer Darstellungen, die Steuerung der Sequenzlänge von Audio-Video-Feature-Darstellungen und die Modellierung auf der Grundlage zeitlicher Korrespondenzen ist Mirasol3B in der Lage, die hohen Rechenanforderungen multimodaler Eingaben effektiv zu erfüllen.
 Einführung in die Methode
Einführung in die Methode
Mirasol3B ist ein multimodales Audio-Video-Text-Modell, bei dem die autoregressive Modellierung in autoregressive Komponenten für zeitlich ausgerichtete Modalitäten (z. B. Audio, Video) und autoregressive Komponenten für nicht autoregressive Komponenten von entkoppelt ist zeitlich ausgerichtete kontextuelle Modalitäten (z. B. Text). Mirasol3B verwendet Kreuzaufmerksamkeitsgewichte, um den Lernprozess dieser Komponenten zu koordinieren. Diese Entkopplung macht die Parameterverteilung innerhalb des Modells vernünftiger, weist den Modalitäten (Video und Audio) genügend Kapazität zu und macht das Gesamtmodell leichter.
Wie in Abbildung 1 dargestellt, besteht Mirasol3B aus zwei Hauptlernkomponenten: der autoregressiven Komponente und der Eingabekombinationskomponente. Unter anderem ist die autoregressive Komponente darauf ausgelegt, nahezu gleichzeitige multimodale Eingaben wie Video und Audio für zeitnahe Eingabekombinationen zu verarbeiten Ändern Sie die Sprache auf Chinesisch. Die Studie schlägt vor, die zeitlich ausgerichteten Modalitäten in Zeitabschnitte zu segmentieren und gemeinsame Audio-Video-Darstellungen in den Zeitabschnitten zu lernen. Konkret schlägt diese Forschung einen Mechanismus zum Lernen modaler Gelenkmerkmale namens „Combiner“ vor. „Combiner“ verschmilzt modale Merkmale innerhalb desselben Zeitraums, um eine kompaktere Darstellung zu generieren Empfangen Sie multimodale Eingaben mit unterschiedlichen Raten und erzielen Sie eine gute Leistung bei der Verarbeitung längerer Videos.
„Combiner“ erfüllt effektiv den Bedarf an einer effizienten und informativen modalen Darstellung. Es kann Ereignisse und Aktivitäten in Video- und anderen gleichzeitigen Modalitäten vollständig abdecken und kann in nachfolgenden autoregressiven Modellen verwendet werden, um langfristige Abhängigkeiten zu lernen.
Um Video- und Audiosignale zu verarbeiten und an längere Video-/Audioeingänge anzupassen, werden diese in (zeitlich grob synchronisierte) kleine Stücke geteilt und dann gemeinsame audiovisuelle Darstellungen durch „Combiner“ erlernt. . Die zweite Komponente verarbeitet Kontext oder zeitlich falsch ausgerichtete Signale wie globale Textinformationen, die oft noch kontinuierlich sind. Es ist außerdem autoregressiv und nutzt den kombinierten latenten Raum als Queraufmerksamkeitseingabe.
 Die Lernkomponente enthält Video und Audio und ihre Parameter sind 3B, während die Komponente ohne Audio 2,9B beträgt. Unter diesen werden die meisten Parameter in autoregressiven Audio- und Videomodellen verwendet. Mirasol3B verarbeitet normalerweise Videos mit 128 Bildern und kann aufgrund des Designs der Partition und der „Combiner“-Modellarchitektur auch längere Videos verarbeiten, indem mehr Bilder hinzugefügt oder die Größe und Anzahl der Blöcke usw. erhöht werden. Nur die Parameter werden leicht erhöht, wodurch das Problem gelöst wird, dass längere Videos mehr Parameter und größeren Speicher erfordern.
Die Lernkomponente enthält Video und Audio und ihre Parameter sind 3B, während die Komponente ohne Audio 2,9B beträgt. Unter diesen werden die meisten Parameter in autoregressiven Audio- und Videomodellen verwendet. Mirasol3B verarbeitet normalerweise Videos mit 128 Bildern und kann aufgrund des Designs der Partition und der „Combiner“-Modellarchitektur auch längere Videos verarbeiten, indem mehr Bilder hinzugefügt oder die Größe und Anzahl der Blöcke usw. erhöht werden. Nur die Parameter werden leicht erhöht, wodurch das Problem gelöst wird, dass längere Videos mehr Parameter und größeren Speicher erfordern.
Experimente und Ergebnisse
Die Studie bewertete Mirasol3B anhand des Standard-VideoQA-Benchmarks, des VideoQA-Benchmarks für lange Videos und des Audio+Video-Benchmarks.
Die Testergebnisse für den VideoQA-Datensatz MSRVTTQA sind in Tabelle 1 unten aufgeführt. Mirasol3B übertrifft das aktuelle SOTA-Modell sowie größere Modelle wie PaLI-X und Flamingo.
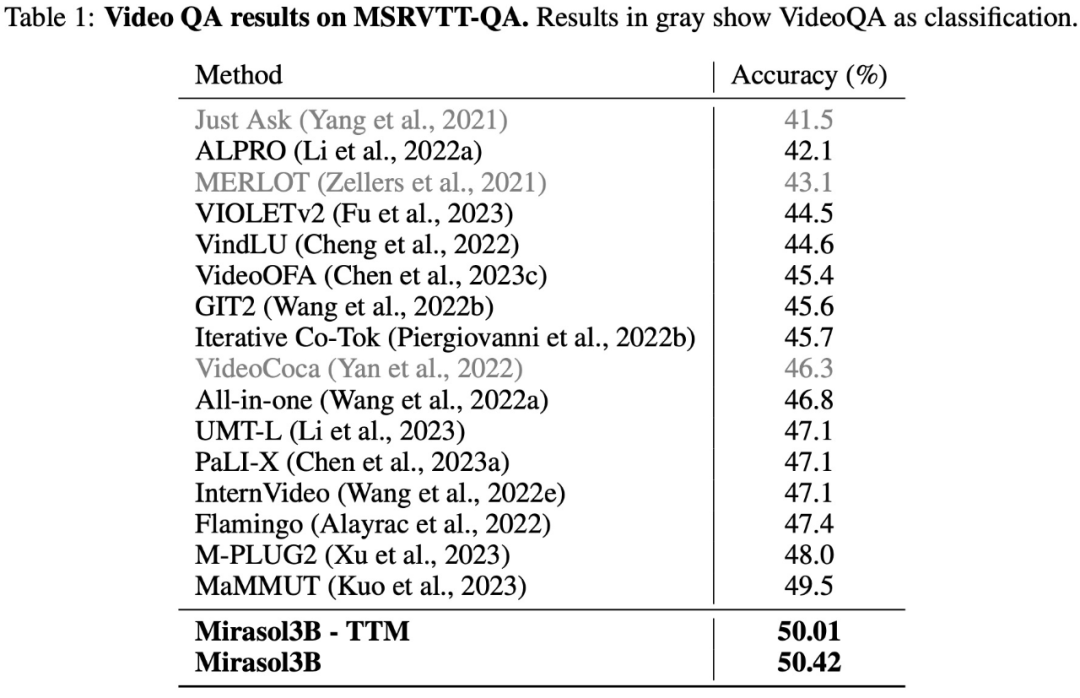
In Bezug auf lange Videofragen und -antworten testete und bewertete diese Studie Mirasol3B anhand der ActivityNet-QA- und NExTQA-Datensätze. Die Ergebnisse sind in Tabelle 2 unten aufgeführt:

In der Am Ende wurden die Studien KineticsSound, VGG-Sound und Epic-Sound für das Audio-Video-Benchmarking ausgewählt und die Open-Generation-Bewertung übernommen. Die experimentellen Ergebnisse sind in Tabelle 3 unten aufgeführt:
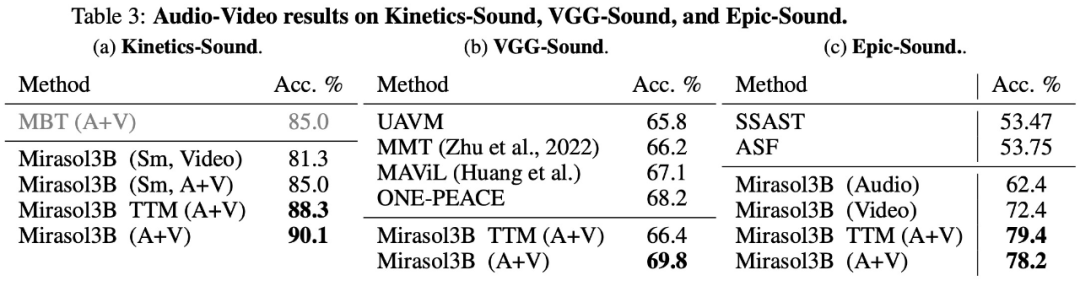
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonKleiner Maßstab, hohe Effizienz: DeepMind bringt multimodale Lösung Mirasol 3B auf den Markt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
