

Heute bringt die Stable AI Company ihr erstes KI-Produkt zur Musik- und Klangerzeugung auf den Markt – Stable Audio. Es ist bekanntermaßen schwierig, in die Musikindustrie einzudringen. Selbst wenn Sie das Talent und den Antrieb haben, müssen Sie dennoch über die Fähigkeiten und Ressourcen verfügen, um Musik zu kreieren und zu produzieren. Aber was ist, wenn Sie nichts davon benötigen? Was wäre, wenn Sie zum Komponieren von Musik nur Kreativität und eine gute KI-Anleitung benötigen würden?
Stable Audio ist ein Tool, das mithilfe von KI Musik von Grund auf generieren kann. Geben Sie einfach einfache Anweisungen und die KI erledigt den Rest
Der offizielle Link ist hier: https://stableaudio.com/

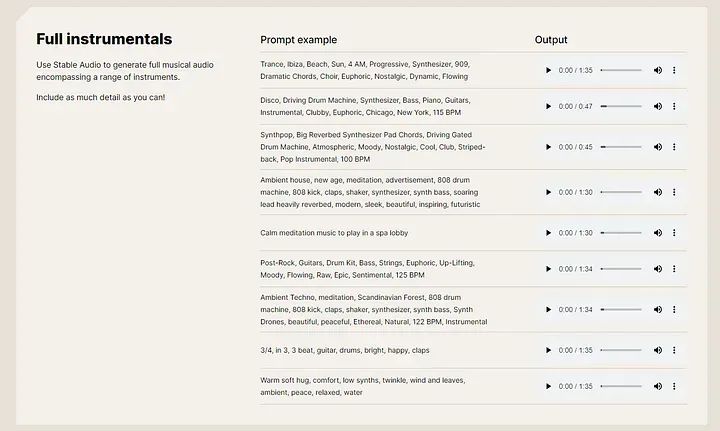
Stable Audio ist ein originelles KI-Tool, das generative KI-Technologie nutzt, um hochwertige Musik und Soundeffekte zu erstellen. Um stabiles Audio zu verwenden, geben Sie einfach eine beschreibende Textaufforderung und die gewünschte Audiolänge ein. Sie können beispielsweise „Post-Rock, Gitarre, Schlagzeug, Bass, Streicher, optimistisch, erhebend, melancholisch, sanft, roh, episch, sentimental, 125 BPM“ eingeben, um einen 95 Sekunden langen Track im Post-Rock-Stil zu generieren. Stabilized Audio eignet sich hervorragend für Musiker, die Samples in ihrer Musik erstellen möchten. Sie können damit Soundeffekte, Hintergrundmusik oder sogar Ihre eigenen Originalkompositionen erstellen.
Gehen Sie zum Stable Audio-Dashboard und melden Sie sich an:
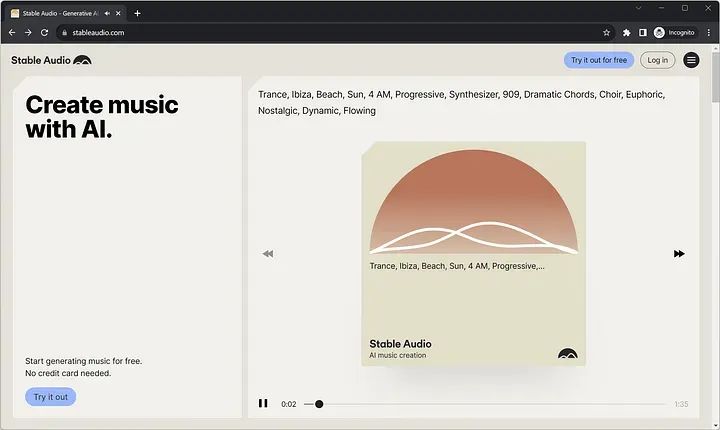
Stable Audio
Gehen Sie dann zum Generate Music-Dashboard, um mit der Generierung Ihrer eigenen Musik zu beginnen:
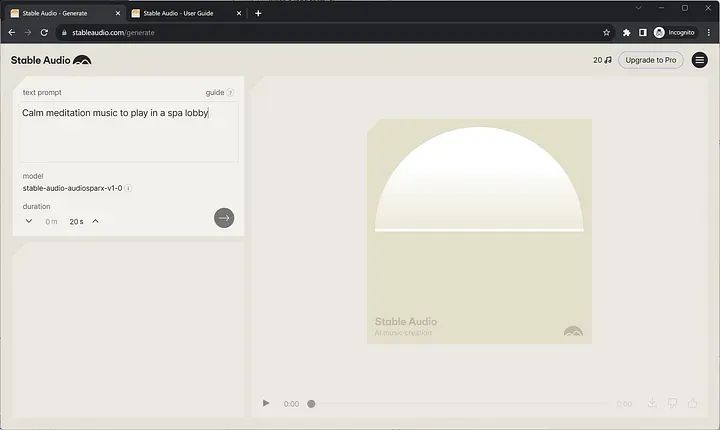
Stable Audio
Bitte geben Sie Ihr Trinkgeld ein und legen Sie die Dauer fest. Bitte beachten Sie, dass kostenlose Abonnements eine maximale Audiolänge von 20 Sekunden haben.
Drücken Sie die rechte Pfeiltaste, um die Audiogenerierung zu starten die bereitgestellten Beispiele im Abschnitt „Benutzerhandbuch“:
Stabilisiertes Audio 
VAE komprimiert Stereo-Audio in eine datenkomprimierende, rauschresistente und reversible verlustbehaftete latente Kodierung, wodurch die Generierung und das Training schneller erfolgen als bei der direkten Verwendung roher Audio-Samples.
Text-Encoder wird verwendet, um Funktionen aus Textaufforderungen zu extrahieren. Diese Funktionen werden dann verwendet, um das Diffusionsmodell abzustimmen.
Das Diffusionsmodell ist ein U-Net-basiertes Modell, das eine Kombination aus Restschichten, Selbstaufmerksamkeitsschichten und Queraufmerksamkeitsschichten verwendet, um die Eingabe zu entrauschen und das gewünschte Audio zu rekonstruieren. 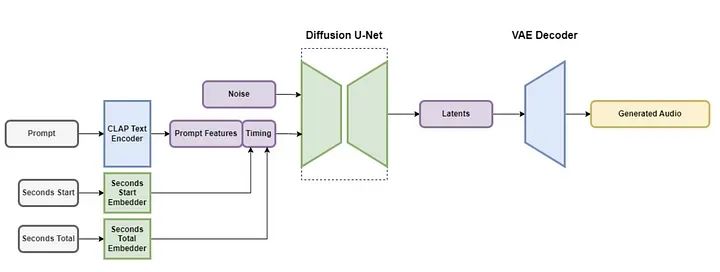
Eine weitere wichtige Information ist, dass das Stable Audio-Modell einen Datensatz von über 800.000 Audiodateien verwendet, darunter Musik, Soundeffekte und einzelne Instrumentenspuren. Das entspricht mehr als 19.500 Stunden Audio.
Das obige ist der detaillierte Inhalt vonStabiles Audio jetzt verfügbar – Machen Sie kostenlos Musik mit künstlicher Intelligenz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Was sind die Oracle-Wildcards?
Was sind die Oracle-Wildcards?
 Welche SEO-Diagnosemethoden gibt es?
Welche SEO-Diagnosemethoden gibt es?
 Ripple-Handelsplattform
Ripple-Handelsplattform
 Der Unterschied zwischen fprintf und printf
Der Unterschied zwischen fprintf und printf
 Python-Nummer zum String
Python-Nummer zum String
 Methode zum Öffnen der Bereichsberechtigung
Methode zum Öffnen der Bereichsberechtigung








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



