
 Technologie-Peripheriegeräte
KI
LCM: Neue Möglichkeit, qualitativ hochwertige Bilder deutlich schneller zu erzeugen
Technologie-Peripheriegeräte
KI
LCM: Neue Möglichkeit, qualitativ hochwertige Bilder deutlich schneller zu erzeugen
LCM: Neue Möglichkeit, qualitativ hochwertige Bilder deutlich schneller zu erzeugen

Autor丨Mike Young
Übersetzung: Die Sprache, um den Inhalt neu zu erstellen, ohne die ursprüngliche Bedeutung zu ändern, ist Chinesisch, der Originalsatz muss nicht erscheinen
Überprüfen Sie den Inhalt, es besteht keine Notwendigkeit, die ursprüngliche Bedeutung zu ändern Die Sprache muss ins Chinesische umgeschrieben werden, der Originalsatz muss nicht erscheinen.
Empfohlener 51CTO Technology Stack (WeChat-ID: blog51cto) Latent Consistency Model (LCM), KI wird die Umwandlung von Text in einen großen Durchbruch in der Grafik einleiten. Herkömmliche Methoden wie Latent Diffusion Models (LDM) eignen sich gut zur Generierung detaillierter, kreativer Bilder mithilfe von Texthinweisen, ihr fataler Nachteil ist jedoch ihre langsame Geschwindigkeit. Das Generieren eines einzelnen Bildes mit LDM kann Hunderte von Schritten erfordern, was für viele praktische Anwendungen zu langsam ist
Auf Chinesisch umgeschrieben:
LCM verändert das Spiel, indem es die Anzahl der Schritte reduziert, die zum Generieren eines Bildes erforderlich sind. Im Vergleich zu LDM, das Hunderte von Schritten zur mühsamen Generierung von Bildern erfordert, kann LCM in nur 1 bis 4 Schritten Ergebnisse ähnlicher Qualität erzielen. Um diese Effizienz zu erreichen, verfeinert LCM das vorab trainierte LDM in eine prägnantere Form und reduziert dadurch die erforderlichen Rechenressourcen und Zeit erheblich. Wir werden ein aktuelles Papier zur Funktionsweise des LDM-Modells analysieren. Das Papier stellt auch eine Innovation namens LCM-LoRA vor, ein universelles Beschleunigungsmodul für stabile Diffusion. Dieses Modul kann ohne zusätzliche Schulung in verschiedene Stable--Diffusion-feinabgestimmte Modelle eingesteckt werden. Es handelt sich um ein universell einsetzbares Tool, das eine Vielzahl von Bilderzeugungsaufgaben beschleunigen kann, was es zu einem potenziellen Werkzeug für die Nutzung von KI zur Erstellung von Bildern macht. Wir werden auch diesen Teil des Papiers analysieren.  1. Effizientes Training von LCM
1. Effizientes Training von LCM
Durch die Einführung von LoRA in den LCM-Extraktionsprozess reduzieren wir den Speicheraufwand der Extraktion erheblich, wodurch wir größere Datensätze mit begrenzten Ressourcen trainieren können, z SDXL und SSD-1B. Noch wichtiger ist, dass die durch das LCM-LoRA-Training erhaltenen LoRA-Parameter („Beschleunigungsvektoren“) direkt mit anderen LoRA-Parametern („Stilvektoren“) kombiniert werden können, die durch Feinabstimmung eines Datensatzes für einen bestimmten Stil erhalten werden. Ohne jegliches Training erhält das durch die lineare Kombination des Beschleunigungsvektors und des Stilvektors erhaltene Modell die Fähigkeit, mit einem Minimum an Abtastschritten Bilder eines bestimmten Malstils zu erzeugen.
2. Ergebnisse
Diese Studie zeigt erhebliche Fortschritte bei der Verwendung von KI zur Generierung von Bildern auf der Grundlage des latenten Konsistenzmodells (LCM). LCM zeichnet sich durch die Erstellung hochwertiger 512x512-Bilder in nur vier Schritten aus, eine deutliche Verbesserung gegenüber den Hunderten von Schritten, die bei herkömmlichen Modellen wie Latent Diffusion Models (LDM) erforderlich sind. Die Bilder zeichnen sich durch gestochen scharfe Details und realistische Texturen aus, was in den folgenden Beispielen besonders deutlich wird.
Bilder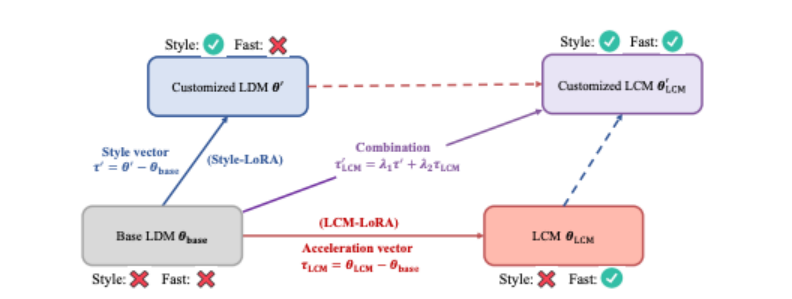 Abbildung 2. In der Arbeit heißt es: „Bilder, die mit latenten Kohärenzmodellen erstellt wurden, die aus verschiedenen vorab trainierten Diffusionsmodellen extrahiert wurden. Wir verwenden LCM-LoRA-SD-V1.5, um eine Auflösung von 512× 512 zu erzeugen.“ Bilder, verwenden Sie LCM-LoRA-SDXL und LCM-LoRA-SSD-1B, um Bilder mit einer Auflösung von 1024 x 1024 zu erzeugen. Sie zeigen die Fähigkeit, auf viel größere neuronale Netzwerkmodelle als bisher möglich zu skalieren, was ihre Anpassungsfähigkeit unter Beweis stellt. In den Beispielen im Papier (wie den Beispielen der Versionen LCM-LoRA-SD-V1.5 und LCM-LoRA-SSD-1B) wird die breite Anwendbarkeit des Modells in verschiedenen Datensätzen und praktischen Szenarien verdeutlicht
Abbildung 2. In der Arbeit heißt es: „Bilder, die mit latenten Kohärenzmodellen erstellt wurden, die aus verschiedenen vorab trainierten Diffusionsmodellen extrahiert wurden. Wir verwenden LCM-LoRA-SD-V1.5, um eine Auflösung von 512× 512 zu erzeugen.“ Bilder, verwenden Sie LCM-LoRA-SDXL und LCM-LoRA-SSD-1B, um Bilder mit einer Auflösung von 1024 x 1024 zu erzeugen. Sie zeigen die Fähigkeit, auf viel größere neuronale Netzwerkmodelle als bisher möglich zu skalieren, was ihre Anpassungsfähigkeit unter Beweis stellt. In den Beispielen im Papier (wie den Beispielen der Versionen LCM-LoRA-SD-V1.5 und LCM-LoRA-SSD-1B) wird die breite Anwendbarkeit des Modells in verschiedenen Datensätzen und praktischen Szenarien verdeutlicht
3 , Einschränkungen
Die aktuelle Version von LCM weist mehrere Einschränkungen auf. Das Wichtigste ist der zweistufige Trainingsprozess: Trainieren Sie zuerst das LDM und trainieren Sie dann damit das LCM. In zukünftigen Forschungen könnte eine direktere Methode des LDM-Trainings untersucht werden, bei der LDM möglicherweise nicht erforderlich ist. Der Artikel befasst sich hauptsächlich mit der bedingungslosen Bildgenerierung. Aufgaben zur bedingten Generierung (z. B. Text-zu-Bild-Synthese) erfordern möglicherweise mehr Arbeit.
4. Wichtigste Erkenntnisse
Das Latent Consistency Model (LCM) hat einen wichtigen Schritt bei der schnellen Generierung qualitativ hochwertiger Bilder gemacht. Diese Modelle können in nur 1 bis 4 Schritten mit langsameren LDMs vergleichbare Ergebnisse liefern und möglicherweise die praktische Anwendung von Text-zu-Bild-Modellen revolutionieren. Obwohl es derzeit einige Einschränkungen gibt, insbesondere im Hinblick auf den Trainingsprozess und den Umfang der Generierungsaufgabe, stellt LCM einen erheblichen Fortschritt in der praktischen Bildgenerierung auf Basis neuronaler Netze dar. Die bereitgestellten Beispiele verdeutlichen das Potenzial dieser Modelle
5. LCM-LoRA als allgemeines Beschleunigungsmodul
Wie in der Einleitung erwähnt, ist das Papier in zwei Teile gegliedert. Im zweiten Teil geht es um die LCM-LoRA-Technologie, die in der Lage ist, vorab trainierte Modelle mit weniger Speicher zu verfeinern und dadurch die Effizienz zu verbessern Vorteile beider Hybridmodelle. Diese Integration ist besonders nützlich, um Bilder eines bestimmten Stils zu erstellen oder auf eine bestimmte Aufgabe zu reagieren. Wenn verschiedene Sätze von LoRA-Parametern ausgewählt und kombiniert werden, die jeweils auf einen einzigartigen Stil abgestimmt sind, erstellen die Forscher ein vielseitiges Modell, das Bilder mit einem Minimum an Schritten und ohne zusätzliches Training erzeugen kann.
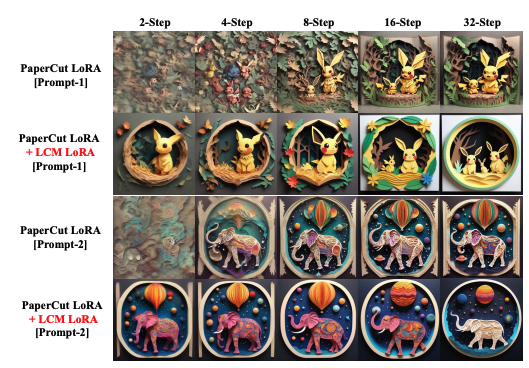
Dies haben sie in ihrer Forschung am Beispiel der Kombination von LoRA-Parametern, die auf bestimmte Malstile abgestimmt sind, mit LCM-LoRA-Parametern demonstriert. Diese Kombination ermöglicht die Erstellung von Bildern mit einer Auflösung von 1024 × 1024 und unterschiedlichen Stilen in unterschiedlichen Abtastschritten (z. B. 2-Schritte, 4-Schritte, 8-Schritte, 16-Schritte und 32-Schritte). Die Ergebnisse zeigen, dass diese kombinierten Parameter ohne weiteres Training qualitativ hochwertige Bilder erzeugen können, was die Effizienz und Vielseitigkeit des Modells unterstreicht
Bemerkenswert ist hier die Verwendung sogenannter „Speed-Up-Vektoren“ (τLCM). und „Stilvektor“ (τ), die beiden werden mithilfe spezifischer mathematischer Formeln kombiniert (λ1 und λ2 sind einstellbare Faktoren in diesen Formeln). Diese Kombination führt zu einem Modell, das schnell benutzerdefinierte Bilder generieren kann.
Abbildung 3 im Papier (siehe unten) demonstriert die Wirksamkeit dieses Ansatzes, indem sie die Ergebnisse eines bestimmten Stils von LoRA-Parametern in Kombination mit LCM-LoRA-Parametern zeigt. Dies zeigt die Fähigkeit des Modells, schnell und effizient Bilder mit unterschiedlichen Stilen zu generieren. Abbildung 3 Abbildung 3: mit nur wenigen Rechenressourcen. Die Technologie hat ein breites Anwendungsspektrum und wird voraussichtlich die Art und Weise, wie Bilder in Bereichen von digitaler Kunst bis hin zur automatisierten Inhaltserstellung generiert werden, revolutionieren
6. Fazit
Wir haben einen neuen Ansatz untersucht, das Latent Consistency Model (LCM). ), wird verwendet, um den Prozess der Generierung von Bildern aus Text zu beschleunigen. Im Gegensatz zu herkömmlichen latenten Diffusionsmodellen (LDM) kann LCM Bilder ähnlicher Qualität in nur 1 bis 4 Schritten anstelle von Hunderten von Schritten erzeugen. Diese deutliche Effizienzsteigerung wird durch die Verfeinerungsmethode erreicht, bei der vorab trainiertes LDM zum Trainieren des LCM verwendet wird, wodurch ein großer Rechenaufwand vermieden wird
 Darüber hinaus haben wir auch LCM-LoRA untersucht, eine Methode mit geringem Verbrauch -rank Adaptive (LoRA) Augmentationstechnik, die vorab trainierte Modelle verfeinert, um den Speicherbedarf zu reduzieren. Mit diesem Ensemble-Ansatz können spezifische Bildstile mit minimalen Rechenschritten erstellt werden, ohne dass zusätzliches Training erforderlich ist
Darüber hinaus haben wir auch LCM-LoRA untersucht, eine Methode mit geringem Verbrauch -rank Adaptive (LoRA) Augmentationstechnik, die vorab trainierte Modelle verfeinert, um den Speicherbedarf zu reduzieren. Mit diesem Ensemble-Ansatz können spezifische Bildstile mit minimalen Rechenschritten erstellt werden, ohne dass zusätzliches Training erforderlich ist
Zu den wichtigsten hervorgehobenen Ergebnissen gehört die Fähigkeit von LCM, in nur wenigen Schritten hochwertige 512x512- und 1024x1024-Bilder zu erstellen, während LDM Hunderte von Schritten erfordert. Die aktuelle Einschränkung besteht jedoch darin, dass LDM auf einem zweistufigen Schulungsprozess basiert, Sie benötigen also immer noch LDM, um loszulegen! Zukünftige Forschungen könnten diesen Prozess vereinfachen.
LCM ist eine sehr clevere Innovation, insbesondere in Kombination mit LoRA im vorgeschlagenen LCM-LoRA-Modell. Sie bieten den Vorteil, qualitativ hochwertige Bilder schneller und effizienter zu erstellen, und ich denke, dass sie breite Anwendungsaussichten bei der Erstellung digitaler Inhalte haben.
Referenzlink: https://notes.aimodels.fyi/lcm-lora-a-new-method-for-generating-high-quality-images-much-faster/
Das obige ist der detaillierte Inhalt vonLCM: Neue Möglichkeit, qualitativ hochwertige Bilder deutlich schneller zu erzeugen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So löschen Sie den Verlauf der letzten Desktop-Hintergrundbilder in Windows 11
Apr 14, 2023 pm 01:37 PM
So löschen Sie den Verlauf der letzten Desktop-Hintergrundbilder in Windows 11
Apr 14, 2023 pm 01:37 PM
<p>Windows 11 verbessert die Personalisierung im System und ermöglicht es Benutzern, einen aktuellen Verlauf zuvor vorgenommener Desktop-Hintergrundänderungen anzuzeigen. Wenn Sie den Abschnitt „Personalisierung“ in der Anwendung „Windows-Systemeinstellungen“ aufrufen, werden Ihnen verschiedene Optionen angezeigt. Eine davon ist das Ändern des Hintergrundbilds. Aber jetzt ist es möglich, den neuesten Verlauf der auf Ihrem System eingestellten Hintergrundbilder anzuzeigen. Wenn Ihnen dies nicht gefällt und Sie den aktuellen Verlauf löschen oder löschen möchten, lesen Sie diesen Artikel weiter. Dort erfahren Sie mehr darüber, wie Sie dies mit dem Registrierungseditor tun. </p><h2>So verwenden Sie die Registrierungsbearbeitung
 So laden Sie das Windows Spotlight-Hintergrundbild auf den PC herunter
Aug 23, 2023 pm 02:06 PM
So laden Sie das Windows Spotlight-Hintergrundbild auf den PC herunter
Aug 23, 2023 pm 02:06 PM
Bei Fenstern kommt die Ästhetik nie zu kurz. Von den idyllischen grünen Feldern von XP bis zum blauen, wirbelnden Design von Windows 11 erfreuen Standard-Desktop-Hintergründe seit Jahren die Benutzer. Mit Windows Spotlight haben Sie jetzt jeden Tag direkten Zugriff auf wunderschöne, beeindruckende Bilder für Ihren Sperrbildschirm und Ihr Desktop-Hintergrundbild. Leider bleiben diese Bilder nicht hängen. Wenn Sie sich in eines der Windows-Spotlight-Bilder verliebt haben, möchten Sie vielleicht wissen, wie Sie sie herunterladen können, damit Sie sie für eine Weile als Hintergrund behalten können. Hier finden Sie alles, was Sie wissen müssen. Was ist WindowsSpotlight? Window Spotlight ist ein automatischer Hintergrund-Updater, der unter Personalisierung > in der App „Einstellungen“ verfügbar ist
 Wie verwende ich die Bildsemantiksegmentierungstechnologie in Python?
Jun 06, 2023 am 08:03 AM
Wie verwende ich die Bildsemantiksegmentierungstechnologie in Python?
Jun 06, 2023 am 08:03 AM
Mit der kontinuierlichen Weiterentwicklung der Technologie der künstlichen Intelligenz hat sich die Bildsemantiksegmentierungstechnologie zu einer beliebten Forschungsrichtung im Bereich der Bildanalyse entwickelt. Bei der semantischen Bildsegmentierung segmentieren wir verschiedene Bereiche in einem Bild und klassifizieren jeden Bereich, um ein umfassendes Verständnis des Bildes zu erreichen. Python ist eine bekannte Programmiersprache. Aufgrund seiner leistungsstarken Datenanalyse- und Datenvisualisierungsfähigkeiten ist es die erste Wahl auf dem Gebiet der Technologieforschung im Bereich der künstlichen Intelligenz. In diesem Artikel wird die Verwendung der Bildsemantiksegmentierungstechnologie in Python vorgestellt. 1. Vorkenntnisse werden vertieft
 iOS 17: So verwenden Sie das Zuschneiden mit einem Klick in Fotos
Sep 20, 2023 pm 08:45 PM
iOS 17: So verwenden Sie das Zuschneiden mit einem Klick in Fotos
Sep 20, 2023 pm 08:45 PM
Mit der iOS 17-Fotos-App erleichtert Apple das Zuschneiden von Fotos nach Ihren Vorgaben. Lesen Sie weiter, um zu erfahren, wie. Bisher umfasste das Zuschneiden eines Bildes in der Fotos-App in iOS 16 mehrere Schritte: Tippen Sie auf die Bearbeitungsoberfläche, wählen Sie das Zuschneidewerkzeug aus und passen Sie dann den Zuschnitt mithilfe einer Pinch-to-Zoom-Geste oder durch Ziehen an den Ecken des Zuschneidewerkzeugs an. In iOS 17 hat Apple diesen Vorgang dankenswerterweise vereinfacht, sodass beim Vergrößern eines ausgewählten Fotos in Ihrer Fotobibliothek automatisch eine neue Schaltfläche „Zuschneiden“ in der oberen rechten Ecke des Bildschirms angezeigt wird. Wenn Sie darauf klicken, wird die vollständige Zuschneideoberfläche mit der Zoomstufe Ihrer Wahl angezeigt, sodass Sie den gewünschten Teil des Bildes zuschneiden, das Bild drehen, umkehren, das Bildschirmverhältnis anwenden oder Markierungen verwenden können
 So ändern Sie die Größe von Bildern stapelweise mit PowerToys unter Windows
Aug 23, 2023 pm 07:49 PM
So ändern Sie die Größe von Bildern stapelweise mit PowerToys unter Windows
Aug 23, 2023 pm 07:49 PM
Wer täglich mit Bilddateien arbeitet, muss diese oft in der Größe anpassen, um sie an die Anforderungen seiner Projekte und Aufgaben anzupassen. Wenn Sie jedoch zu viele Bilder verarbeiten müssen, kann die Größenänderung einzelner Bilder viel Zeit und Mühe kosten. In diesem Fall kann ein Tool wie PowerToys nützlich sein, um unter anderem die Größe von Bilddateien mit dem Bild-Resizer-Dienstprogramm stapelweise zu ändern. Hier erfahren Sie, wie Sie Ihre Image Resizer-Einstellungen einrichten und mit PowerToys mit der Stapelgrößenänderung von Bildern beginnen. So ändern Sie die Größe von Bildern stapelweise mit PowerToys PowerToys ist ein All-in-One-Programm mit einer Vielzahl von Dienstprogrammen und Funktionen, die Ihnen helfen, Ihre täglichen Aufgaben zu beschleunigen. Eines seiner Dienstprogramme sind Bilder
 Verwenden Sie 2D-Bilder, um einen 3D-menschlichen Körper zu erstellen. Sie können jede Kleidung tragen und Ihre Bewegungen ändern.
Apr 11, 2023 pm 02:31 PM
Verwenden Sie 2D-Bilder, um einen 3D-menschlichen Körper zu erstellen. Sie können jede Kleidung tragen und Ihre Bewegungen ändern.
Apr 11, 2023 pm 02:31 PM
Dank der differenzierbaren Darstellung durch NeRF haben neuere generative 3D-Modelle beeindruckende Ergebnisse auf stationären Objekten erzielt. Allerdings stellt die 3D-Generierung in einer komplexeren und verformbareren Kategorie wie dem menschlichen Körper immer noch große Herausforderungen dar. In diesem Artikel wird eine effiziente kombinierte NeRF-Darstellung des menschlichen Körpers vorgeschlagen, die eine hochauflösende (512 x 256) 3D-Generierung des menschlichen Körpers ohne den Einsatz hochauflösender Modelle ermöglicht. EVA3D hat bestehende Lösungen bei vier umfangreichen Datensätzen zum menschlichen Körper deutlich übertroffen, und der Code ist Open Source. Papiername: EVA3D: Compositional 3D Human Generation from 2D image Collections Papieradresse: http
 Neue Perspektive auf die Bilderzeugung: Diskussion NeRF-basierter Generalisierungsmethoden
Apr 09, 2023 pm 05:31 PM
Neue Perspektive auf die Bilderzeugung: Diskussion NeRF-basierter Generalisierungsmethoden
Apr 09, 2023 pm 05:31 PM
Die Erzeugung neuer perspektivischer Bilder (NVS) ist ein Anwendungsgebiet der Computer Vision. Im SuperBowl-Spiel von 1998 demonstrierte die RI NVS mit Multikamera-Stereovision (MVS). Damals wurde diese Technologie auf einen Sportfernsehsender übertragen Vereinigte Staaten, aber es wurde am Ende nicht kommerzialisiert; die britische BBC Broadcasting Company investierte in Forschung und Entwicklung dafür, aber es wurde nicht wirklich kommerzialisiert. Im Bereich des bildbasierten Renderings (IBR) gibt es einen Zweig der NVS-Anwendungen, nämlich das Tiefenbild-basierte Rendering (DBIR). Darüber hinaus musste das 3D-Fernsehen, das im Jahr 2010 sehr beliebt war, auch binokulare stereoskopische Effekte aus monokularen Videos erzielen, doch aufgrund der Unausgereiftheit der Technologie wurde es letztendlich nicht populär. Zu diesem Zeitpunkt begann man bereits mit der Erforschung von Methoden, die auf maschinellem Lernen basieren, wie z
 Entfernen Sie Hautunreinheiten und Falten mit einem Klick: Detaillierte Interpretation des hochauflösenden Porträt-Hautschönheitsmodells ABPN der DAMO Academy
Apr 12, 2023 pm 12:25 PM
Entfernen Sie Hautunreinheiten und Falten mit einem Klick: Detaillierte Interpretation des hochauflösenden Porträt-Hautschönheitsmodells ABPN der DAMO Academy
Apr 12, 2023 pm 12:25 PM
Mit der rasanten Entwicklung der digitalen Kulturindustrie wird die Technologie der künstlichen Intelligenz zunehmend im Bereich der Bildbearbeitung und -verschönerung eingesetzt. Unter diesen ist die Hautverschönerung von Porträts zweifellos eine der am weitesten verbreiteten und gefragtesten Technologien. Herkömmliche Schönheitsalgorithmen nutzen filterbasierte Bildbearbeitungstechnologie, um automatisierte Hauterneuerungs- und Hautunreinheiten-Entfernungseffekte zu erzielen, und werden häufig in sozialen Netzwerken, Live-Übertragungen und anderen Szenarien eingesetzt. In der professionellen Fotobranche mit hohen Schwellenwerten sind manuelle Retuschierer jedoch aufgrund der hohen Anforderungen an Bildauflösung und Qualitätsstandards immer noch die wichtigste Produktionskraft bei der Schönheitsretusche von Porträts und erledigen Aufgaben wie Hautglättung, Entfernung von Hautunreinheiten, Aufhellung usw. Serie arbeiten. Normalerweise beträgt die durchschnittliche Bearbeitungszeit für die Hautverschönerung eines hochauflösenden Porträts durch einen professionellen Retuschierer 1-2 Minuten. In Bereichen wie Werbung, Film und Fernsehen, die eine höhere Präzision erfordern, ist dieser Vorgang erforderlich
