
 .
.  Technologie-Peripheriegeräte
KI
Verbessern Sie die Inferenzleistung großer Modelle mithilfe des Toolkits um das 40-fache
Technologie-Peripheriegeräte
KI
Verbessern Sie die Inferenzleistung großer Modelle mithilfe des Toolkits um das 40-fache
Verbessern Sie die Inferenzleistung großer Modelle mithilfe des Toolkits um das 40-fache

Intel® Was ist eine Erweiterung für Transformer?
Intel® Extension for Transformers[1] ist ein innovatives Toolkit von Intel, das auf Intel® Architekturplattformen, insbesondere den skalierbaren Intel® Xeon® Prozessoren der vierten Generation (Codename Sapphire Rapids[2) basieren kann ], SPR) beschleunigt das Transformer-basierte Large Language Model (LLM) erheblich. Zu seinen Hauptfunktionen gehören:
- Bieten Sie Benutzern ein nahtloses Modellkomprimierungserlebnis durch die Erweiterung der Hugging Face Transformers API[3] und die Nutzung von Intel® Neural Compressor[4]
- Bereitstellen der Verwendung von Low-Bit-Quantisierungskernen ( NeurIPS 2023: Die LLM-Inferenzlaufzeit, die effiziente LLM-Inferenz [5] auf der CPU implementiert, unterstützt Falcon, LLaMA, MPT, Llama2, BLOOM, OPT, ChatGLM2, GPT-J-6B, Baichuan-13B-Base, Baichuan2-13B-Base , Gängige LLMs wie Qwen-7B, Qwen-14B und Dolly-v2-3B [6];
- Advanced Compressed Sensing Runtime [7] (NeurIPS 2022: Fast Distillation on CPU und QuaLA-MiniLM: Automatische Anpassung der Quantisierungslänge an MiniLM ; NeurIPS 2021: Einmal beschneiden, vergessen: vorab trainierte Sprachmodelle spärlich/beschneiden).
Dieser Artikel konzentriert sich auf die LLM-Inferenzlaufzeit (als „LLM-Laufzeit“ bezeichnet) und wie man die Transformer-basierte API verwendet, um effizienteres LLM auf Intel® Xeon® skalierbaren Prozessoren zu implementieren. Begründung und Vorgehensweise sich mit den Anwendungsproblemen von LLM in Chat-Szenarien auseinanderzusetzen.
LLM Runtime (LLM Runtime)
Die von Intel® Extension for Transformers bereitgestellte LLM Runtime[8] ist eine leichte, aber effiziente LLM-Inferenzlaufzeit, die von GGML[9] inspiriert ist und mit llama.cpp[ kompatibel ist. 10] ist kompatibel und verfügt über die folgenden Funktionen:
- Der Kernel wurde für die verschiedenen in Intel® Xeon® CPUs (wie AMX, VNNI) und die AVX512F- und AVX2-Befehlssätze integrierten KI-Beschleunigungstechnologien optimiert Bietet mehr Quantifizierungsoptionen, wie zum Beispiel: unterschiedliche Granularitäten (nach Kanal oder nach Gruppe), unterschiedliche Gruppengrößen (wie zum Beispiel: 32/128);
- Verfügt über bessere KV-Cache-Zugriffs- und Speicherzuweisungsfunktionen; Inferenz in Mehrkanalsystemen.
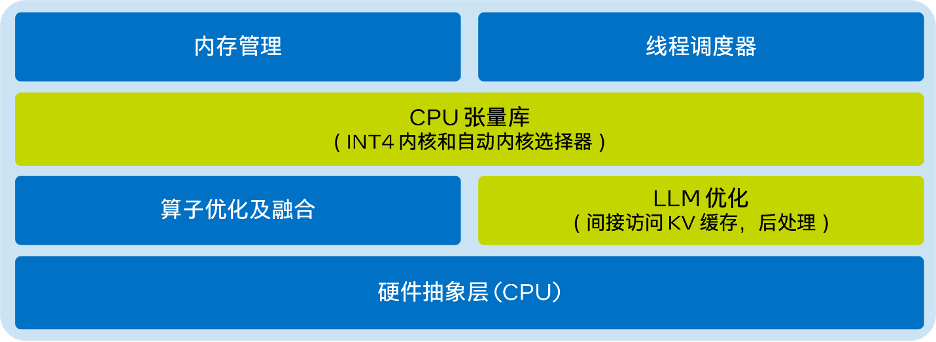
- Das vereinfachte Architekturdiagramm von LLM Runtime lautet wie folgt:
 Verwendung von Transformer-basiert API, implementiert auf der CPU LLM Efficient Inference
Verwendung von Transformer-basiert API, implementiert auf der CPU LLM Efficient Inference
Mit weniger als 9 Codezeilen können Sie eine bessere LLM-Inferenzleistung auf der CPU erzielen. Benutzer können ganz einfach eine Transformer-ähnliche API zur Quantifizierung und Inferenz aktivieren. Setzen Sie einfach „load_in_4bit“ auf „true“ und importieren Sie das Modell von der HuggingFace-URL oder dem lokalen Pfad. Beispielcode zum Aktivieren der reinen INT4-Quantisierung mit Gewichtung finden Sie unten:
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLMmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
Die Standardeinstellungen sind: Gewichtungen als 4 Bits speichern, Berechnungen als 8 Bits durchführen. Es unterstützt aber auch verschiedene Kombinationen von Berechnungsdatentypen (dtype) und Gewichtsdatentypen, und Benutzer können die Einstellungen nach Bedarf ändern. Nachfolgend finden Sie Beispielcode für die Verwendung dieser Funktion:
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfigmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4")tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name,quantization_cnotallow=woq_config)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
Leistungstest
Nach kontinuierlichen Bemühungen wurde die INT4-Leistung des oben genannten Optimierungsschemas erheblich verbessert. In diesem Artikel wird ein Leistungsvergleich mit llama.cpp auf einem System durchgeführt, das mit
Intel® GB (16 x 16 GB DDR5 4800 MT/s [4800 MT/s]), BIOS 3A14.TEL2P1, Mikrocode 0x2b0001b0, CentOS Stream 8 ausgestattet ist. Die Ergebnisse des Inferenzleistungstests sind in der folgenden Tabelle aufgeführt, wobei die Eingabegröße 32, die Ausgabegröße 32 und der Strahl 1 beträgt.
△Tabelle 1. Vergleich der Inferenzleistung zwischen LLM Runtime und llama.cpp (Eingabegröße = 32, Ausgabegröße = 32, Strahl = 1)
Die Testergebnisse der Inferenzleistung, wenn die Eingabegröße 1024, die Ausgabegröße 32 und der Strahl 1 beträgt. Siehe die Tabelle unten Einzelheiten: 
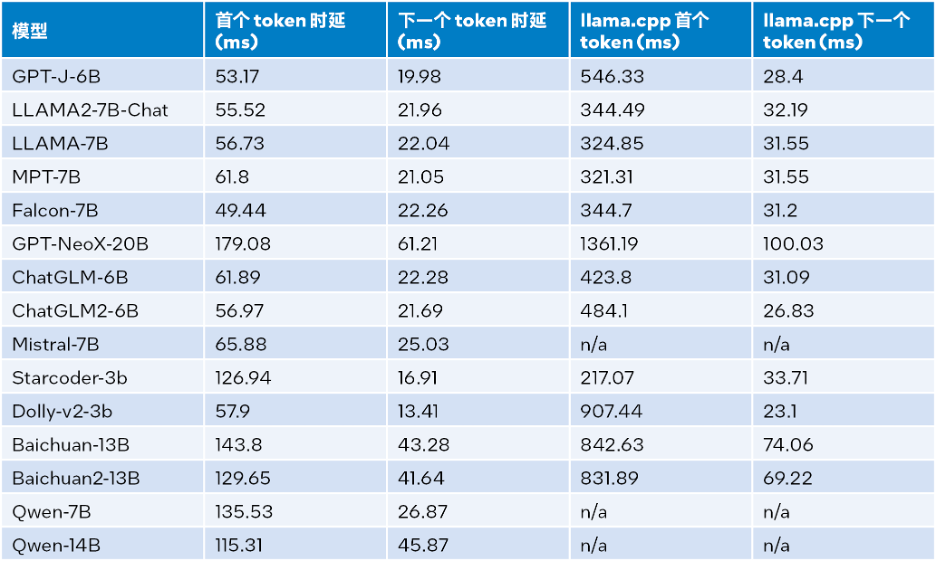
△Tabelle 2. LLM-Laufzeitvergleich mit der Inferenzleistung von llama.cpp (Eingabegröße = 1024, Ausgabegröße = 32, Strahl = 1)
Gemäß Tabelle 2 oben: Im Vergleich zu llama.cpp, das auch auf dem skalierbaren Intel® Token und der nächste Token werden jeweils um das bis zu 40-fache erhöht [a] (Baichuan-13B, Eingabe ist 1024) bzw. um das 2,68-fache [b] (MPT-7B, Eingabe ist 1024). Der Test von llama.cpp verwendet die Standardcodebasis [10]. Durch die Kombination der Testergebnisse in Tabelle 1 und Tabelle 2 kann der Schluss gezogen werden, dass LLM Runtime im Vergleich zu llama.cpp, das auch auf dem skalierbaren Intel® Bei einer Eingabegröße von 1024 wird eine Verbesserung um das 3,58- bis 21,5-fache erreicht. Bei einer Eingabegröße von 32 wird eine Verbesserung um das 1,76- bis 3,43-fache erreicht.
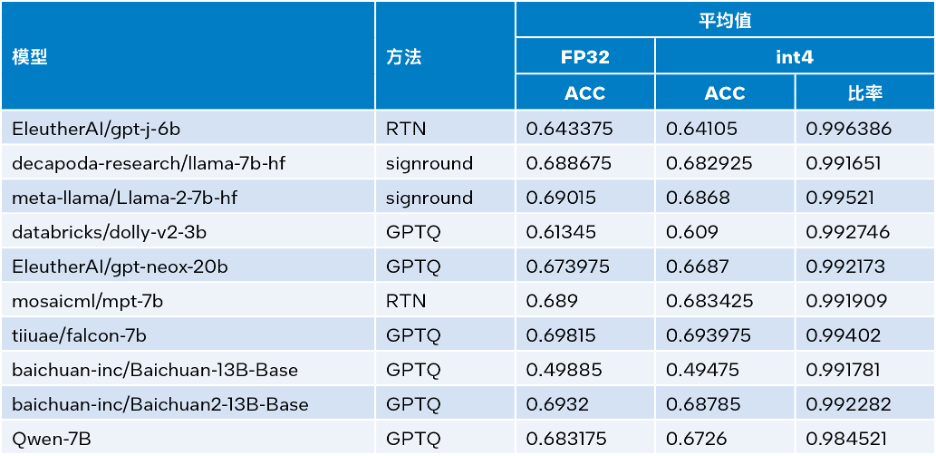
GenauigkeitstestIntel® Extension for Transformers kann Quantisierungsmethoden wie SignRound[11], RTN und GPTQ[12] in
Intel®Neural Compressor nutzen und die Datensätze lambada_openai, piqa, winogrande und hellaswag verwenden. Verifizierte INT4-Inferenz Genauigkeit. Die folgende Tabelle vergleicht die Durchschnittswerte der Testergebnisse mit der FP32-Genauigkeit.
△Tabelle 3. Genauigkeitsvergleich zwischen INT4 und FP32
Wie aus Tabelle 3 oben ersichtlich ist, ist der Genauigkeitsverlust der INT4-Inferenz, die von mehreren Modellen basierend auf LLM Runtime durchgeführt wird, sehr gering und kann fast ignoriert werden. Wir haben viele Modelle überprüft, aus Platzgründen sind hier jedoch nur einige aufgeführt. Wenn Sie weitere Informationen oder Details wünschen, besuchen Sie bitte diesen Link:https://medium.com/@NeuralCompressor/llm-performance-of-intel-extension-for-transformers-f7d061556176.
Erweiterte Funktionen: Erfüllen Sie die Anwendungsanforderungen von LLM in mehr Szenarien
Gleichzeitig verfügt LLM Runtime[8] auch über die Tensor-Parallelisierungsfunktion einer Dual-Channel-CPU, was eines der frühesten Produkte mit einer solchen Funktion ist. In Zukunft werden Dual Nodes weiter unterstützt. Der Vorteil von LLM Runtime liegt jedoch nicht nur in seiner besseren Leistung und Genauigkeit, wir haben auch große Anstrengungen unternommen, um seine Funktionalität in Chat-Anwendungsszenarien zu verbessern und die folgenden Anwendungen zu lösen, auf die LLM in Chat-Szenarien stoßen kann Dilemma:
Beim Dialog geht es nicht nur um LLM-Argumentation, auch der Dialogverlauf ist nützlich. Begrenzte Ausgabelänge: Das Vortraining des LLM-Modells basiert hauptsächlich auf einer begrenzten Sequenzlänge. Daher nimmt die Genauigkeit ab, wenn die Sequenzlänge die während des Vortrainings verwendete Aufmerksamkeitsfenstergröße überschreitet. Ineffizienz: Während der Dekodierungsphase speichert Transformer-basiertes LLM den Schlüsselwertstatus (KV) aller zuvor generierten Token, was zu einer übermäßigen Speichernutzung und einer erhöhten Dekodierungslatenz führt.
- Was das erste Problem betrifft, so wird die Dialogfunktion von LLM Runtime dadurch gelöst, dass mehr Dialogverlaufsdaten integriert und mehr Ausgaben generiert werden, wofür llama.cpp noch nicht gut gerüstet ist.
- Bezüglich der zweiten und dritten Frage haben wir Streaming-LLM (Steaming LLM) in die
- Intel® Extension für Transformers integriert, was die Speichernutzung deutlich optimieren und die Inferenzlatenz reduzieren kann.
Streaming LLM
Im Gegensatz zum herkömmlichen KV-Cache-Algorithmus kombiniert unsere Methode Aufmerksamkeitssenke (4 anfängliche Token), um die Stabilität der Aufmerksamkeitsberechnung zu verbessern, und behält die neuesten Informationen mithilfe des
rollenden KV-Cache-Tokensbei entscheidend für die Sprachmodellierung. Das Design ist äußerst flexibel und kann nahtlos in autoregressive Sprachmodelle integriert werden, die die Rotationspositionskodierung RoPE und die relative Positionskodierung ALiBi nutzen können.
Der Inhalt, der neu geschrieben werden muss, ist: △ Abbildung 2. KV-Cache von Steam LLM mit Aufmerksamkeitssenke zur Implementierung eines effizienten Streaming-Sprachmodells (Bildquelle: [13])
Darüber hinaus unterscheidet es sich von Lama. cpp: Dieser Optimierungsplan fügt auch neue Parameter wie „n_keep“ und „n_discard“ hinzu, um die Streaming-LLM-Strategie zu verbessern. Benutzer können den Parameter „n_keep“ verwenden, um die Anzahl der Token anzugeben, die im KV-Cache aufbewahrt werden sollen, und den Parameter „n_discard“, um die Anzahl der generierten Token zu bestimmen, die verworfen werden sollen. Um Leistung und Genauigkeit besser in Einklang zu bringen, verwirft das System standardmäßig die Hälfte der neuesten Token-Nummer im KV-Cache.
Gleichzeitig haben wir zur weiteren Verbesserung der Leistung auch Streaming LLM zum MHA-Fusionsmodus hinzugefügt. Wenn das Modell die Rotationspositionskodierung (RoPE) verwendet, um die Positionseinbettung zu implementieren, müssen Sie nur eine „Verschiebungsoperation“ auf den vorhandenen K-Cache anwenden, um zu vermeiden, dass Operationen an zuvor generierten Token ausgeführt werden, die nicht verworfen wurden. Diese Methode nutzt nicht nur die volle Kontextgröße beim Generieren von Langtext voll aus, sondern verursacht auch keinen zusätzlichen Overhead, bis der KV-Cache-Kontext vollständig gefüllt ist.
 Gleichzeitig haben wir zur weiteren Verbesserung der Leistung auch Streaming LLM zum MHA-Fusionsmodus hinzugefügt. Wenn das Modell die Rotationspositionskodierung (RoPE) verwendet, um die Positionseinbettung zu implementieren, müssen Sie nur eine „Verschiebungsoperation“ auf den vorhandenen K-Cache anwenden, um zu vermeiden, dass Operationen an zuvor generierten Token ausgeführt werden, die nicht verworfen wurden. Diese Methode nutzt nicht nur die volle Kontextgröße beim Generieren von Langtext voll aus, sondern verursacht auch keinen zusätzlichen Overhead, bis der KV-Cache-Kontext vollständig gefüllt ist.
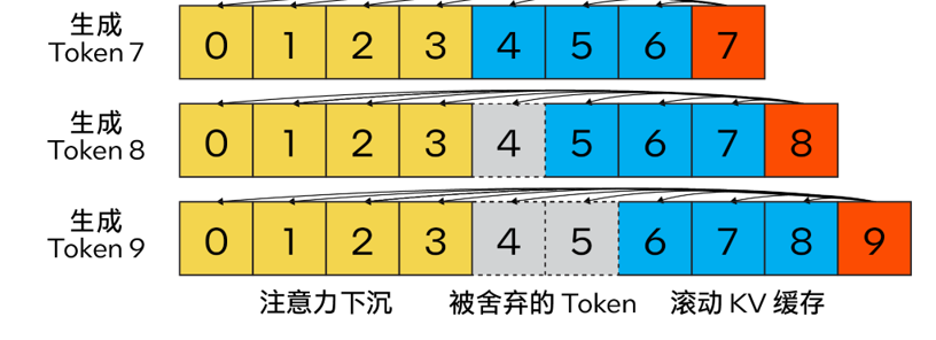
Gleichzeitig haben wir zur weiteren Verbesserung der Leistung auch Streaming LLM zum MHA-Fusionsmodus hinzugefügt. Wenn das Modell die Rotationspositionskodierung (RoPE) verwendet, um die Positionseinbettung zu implementieren, müssen Sie nur eine „Verschiebungsoperation“ auf den vorhandenen K-Cache anwenden, um zu vermeiden, dass Operationen an zuvor generierten Token ausgeführt werden, die nicht verworfen wurden. Diese Methode nutzt nicht nur die volle Kontextgröße beim Generieren von Langtext voll aus, sondern verursacht auch keinen zusätzlichen Overhead, bis der KV-Cache-Kontext vollständig gefüllt ist. “shift operation”依赖于旋转的交换性和关联性,或复数乘法。例如:如果某个token的K-张量初始放置位置为m并且旋转了m×θi for i ∈ [0,d/2),那么当它需要移动到m-1这个位置时,则可以旋转回到(-1)×θi for i ∈ [0,d/2)。这正是每次舍弃n_discard个token的缓存时发生的事情,而此时剩余的每个token都需要“移动”n_discard个位置。下图以“n_keep=4、n_ctx=16、n_discard=1”为例,展示了这一过程。

△图3.Ring-Buffer KV-Cache和Shift-RoPE工作原理
需要注意的是:融合注意力层无需了解上述过程。如果对K-cache和V-cache进行相同的洗牌,注意力层会输出几乎相同的结果(可能存在因浮点误差导致的微小差异)。
您可以使用下面的代码来启动Streaming LLM:
from transformers import AutoTokenizer, TextStreamer from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig model_name = "Intel/neural-chat-7b-v1-1" # Hugging Face model_id or local model woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4") prompt = "Once upon a time, a little girl"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) inputs = tokenizer(prompt, return_tensors="pt").input_ids streamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, quantization_cnotallow=woq_config, trust_remote_code=True) # Recommend n_keep=4 to do attention sinks (four initial tokens) and n_discard=-1 to drop half rencetly tokens when meet length threshold outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300, ctx_size=100, n_keep=4, n_discard=-1)
结论与展望
本文基于上述实践经验,提供了一个在英特尔® 至强® 可扩展处理器上实现高效的低位(INT4)LLM推理的解决方案,并且在一系列常见LLM上验证了其通用性以及展现了其相对于其他基于CPU的开源解决方案的性能优势。未来,我们还将进一步提升CPU张量库和跨节点并行性能。
欢迎您试用英特尔® Extension for Transformers[1],并在英特尔® 平台上更高效地运行LLM推理!也欢迎您向代码仓库(repository)提交修改请求 (pull request)、问题或疑问。期待您的反馈!
特别致谢
在此致谢为此篇文章做出贡献的英特尔公司人工智能资深经理张瀚文及工程师许震中、余振滔、刘振卫、丁艺、王哲、刘宇澄。
[a]根据表2 Baichuan-13B的首个token测试结果计算而得。
[b]根据表2 MPT-7B的下一个token测试结果计算而得。
[c]当输入大小为1024时,整体性能=首个token性能+1023下一个token性能;当输入大小为32时,整体性能=首个token性能+31下一个token性能。
Das obige ist der detaillierte Inhalt vonVerbessern Sie die Inferenzleistung großer Modelle mithilfe des Toolkits um das 40-fache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1209
24
52
1209
24

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
