
 Technologie-Peripheriegeräte
KI
Wenn sie anderer Meinung sind, werden sie punkten. Warum sind große inländische KI-Modelle süchtig danach, „die Rangliste zu klauen'?
Technologie-Peripheriegeräte
KI
Wenn sie anderer Meinung sind, werden sie punkten. Warum sind große inländische KI-Modelle süchtig danach, „die Rangliste zu klauen'?
Wenn sie anderer Meinung sind, werden sie punkten. Warum sind große inländische KI-Modelle süchtig danach, „die Rangliste zu klauen'?

Ich glaube, dass Freunden, die auf den Handykreis achten, der Satz „Bekomme eine Punktzahl, wenn du sie nicht akzeptierst“ nicht unbekannt sein wird. Beispielsweise haben theoretische Leistungstestsoftware wie AnTuTu und GeekBench große Aufmerksamkeit bei Spielern auf sich gezogen, da sie die Leistung von Mobiltelefonen bis zu einem gewissen Grad widerspiegeln können. Ebenso gibt es entsprechende Benchmarking-Software für PC-Prozessoren und Grafikkarten, um deren Leistung zu messen
Seit „alles kann bewertet werden“ nehmen die beliebtesten großen KI-Modelle auch an Benchmarking-Wettbewerben teil. Insbesondere nach Beginn des „Hundert-Modell-Krieges“ werden fast täglich Durchbrüche erzielt, und jedes Unternehmen bezeichnet sich selbst als „. Nr. 1 im Benchmarking“.一“
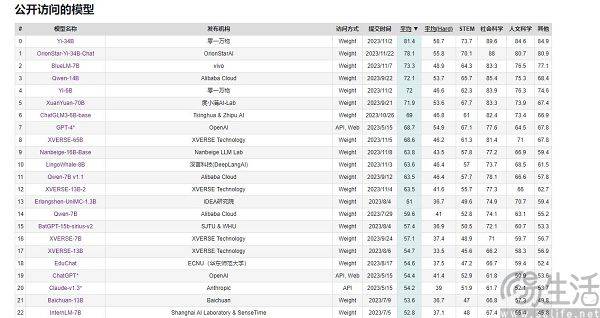
Inländische große KI-Modelle bleiben in Bezug auf die Leistungsbewertung fast nie zurück, können GPT-4 jedoch in Bezug auf die Benutzererfahrung niemals übertreffen. Dies wirft die Frage auf, dass an großen Verkaufsstellen jeder Mobiltelefonhersteller immer behaupten kann, dass seine Produkte „die Nummer eins im Verkauf“ sind. Durch das ständige Hinzufügen attributiver Begriffe wird der Markt unterteilt und unterteilt, sodass jeder die Möglichkeit hat die Nummer eins zu werden, aber im Bereich der KI-Großmodelle ist die Situation anders. Schließlich sind ihre Bewertungskriterien im Wesentlichen einheitlich, einschließlich MMLU (zur Messung der Fähigkeit zum Sprachverständnis bei mehreren Aufgaben), Big-Bench (zur Quantifizierung und Extrapolation der Fähigkeit von LLMs) und AGIEval (zur Bewertung der Fähigkeit, damit umzugehen). Aufgabenfähigkeit auf menschlicher Ebene)
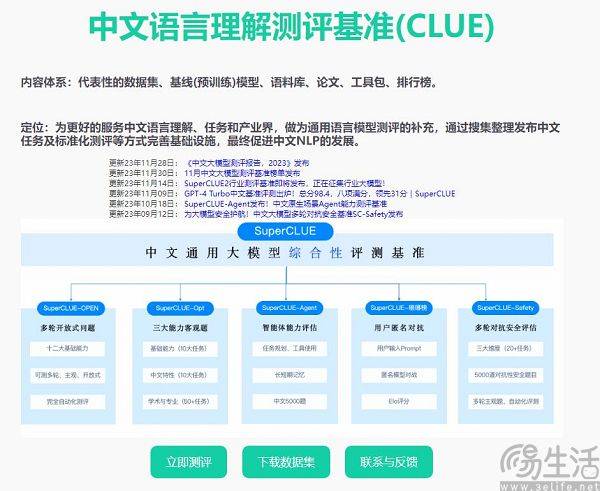
Zu den in China häufig zitierten groß angelegten Modellbewertungslisten gehören derzeit SuperCLUE, CMMLU und C-Eval. Unter ihnen sind CMMLU und C-Eval umfassende Prüfungsbewertungssätze, die gemeinsam von der Tsinghua University, der Shanghai Jiao Tong University und der University of Edinburgh entwickelt wurden. CMMLU wird gemeinsam von MBZUAI, der Shanghai Jiao Tong University und Microsoft Research Asia ins Leben gerufen. SuperCLUE wurde von Fachleuten für künstliche Intelligenz großer Universitäten mitgeschrieben
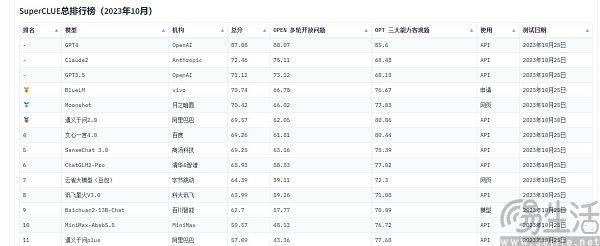
Nehmen Sie C-Eval als Beispiel: Auf der Liste von Anfang September belegte Yuntian Lifeis großes Modell „Yuntian Shu“ den ersten Platz, 360 den achten Platz, aber GPT-4 konnte nur den zehnten Platz belegen. Warum gibt es kontraintuitive Ergebnisse, da der Standard quantifizierbar ist? Der Grund, warum die Liste der großen Modelllaufergebnisse eine Szene mit „herumtanzenden Teufeln“ zeigt, liegt tatsächlich darin, dass die aktuellen Methoden zur Bewertung der Leistung großer KI-Modelle Einschränkungen aufweisen. Sie verwenden eine „Fragenlösungs“-Methode, um die Fähigkeit großer Modelle zu messen .
Wie wir alle wissen, reduzieren Smartphone-SoCs, Computer-CPUs und Grafikkarten die Frequenz bei hohen Temperaturen automatisch, um ihre Lebensdauer zu schützen, während niedrige Temperaturen die Chipleistung verbessern können. Daher legen manche Menschen ihre Mobiltelefone für Leistungstests in den Kühlschrank oder statten ihre Computer mit leistungsstärkeren Kühlsystemen aus und erzielen in der Regel höhere Ergebnisse als normal. Darüber hinaus werden große Mobiltelefonhersteller auch eine „exklusive Optimierung“ für verschiedene Benchmarking-Software durchführen, die zu ihrem Standardbetrieb geworden ist
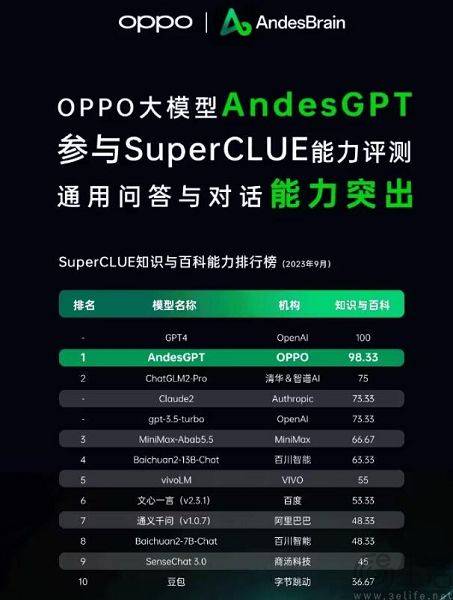
In gleicher Weise konzentriert sich die Bewertung großer Modelle der künstlichen Intelligenz auf das Beantworten von Fragen, sodass es natürlich eine Fragendatenbank geben wird. Ja, das ist der Grund, warum einige große Haushaltsmodelle ständig auf der Liste stehen. Aus verschiedenen Gründen sind die Fragendatenbanken der wichtigsten Modelllisten derzeit für Hersteller nahezu einseitig transparent, was als „Benchmark-Leakage“ bezeichnet wird. Beispielsweise umfasste die C-Eval-Liste bei ihrer Einführung 13.948 Fragen, und aufgrund der begrenzten Fragendatenbank konnten einige unbekannte große Modelle durch das Ausfüllen von Fragen „bestehen“
Sie können sich vorstellen, dass sich Ihre Prüfungsergebnisse erheblich verbessern, wenn Sie vor der Prüfung versehentlich die Testarbeit und die Standardantworten sehen und sich dann unerwartet die Fragen merken. Daher wird die durch die große Modellliste voreingestellte Fragenbank zum Trainingssatz hinzugefügt, sodass das große Modell zu einem Modell wird, das zu den Benchmark-Daten passt. Darüber hinaus ist das aktuelle LLM selbst für sein hervorragendes Gedächtnis bekannt und das Aufsagen von Standardantworten ist einfach ein Kinderspiel
Durch diese Methode können kleine Modelle auch bei den Laufergebnissen bessere Ergebnisse erzielen als große Modelle. Einige der hohen Punktzahlen, die große Modelle erzielen, werden durch eine solche „Feinabstimmung“ erzielt. In dem Artikel „Machen Sie Ihr LLM nicht zu einem Bewertungs-Benchmark-Betrüger“ wies das Hillhouse-Team der Renmin University unverblümt auf dieses Phänomen hin, und dieser opportunistische Ansatz schadet der Leistung großer Modelle.
Forscher des Hillhouse-Teams haben herausgefunden, dass Benchmark-Lecks dazu führen können, dass große Modelle übertriebene Ergebnisse liefern. Beispielsweise kann ein 1,3-B-Modell bei einigen Aufgaben ein zehnmal so großes Modell übertreffen, aber der Nebeneffekt ist, dass diese speziell für „ Prüfungsdurchführung“ Bei großen Modellen wird die Leistung bei anderen normalen Testaufgaben beeinträchtigt. Wenn Sie darüber nachdenken, werden Sie schließlich wissen, dass das große KI-Modell ein „Fragenmacher“ sein sollte, aber es ist zu einem „Fragenmerker“ geworden Spezifisches Wissen und Ausgabestil der Liste werden das große Modell definitiv in die Irre führen.

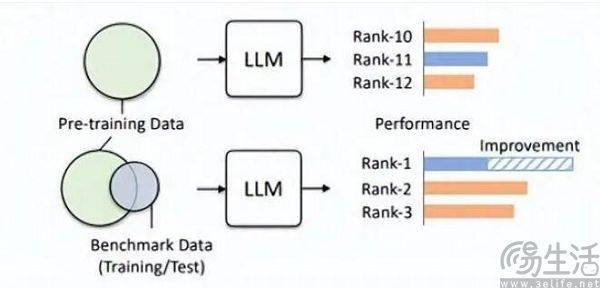
Die Nichtüberschneidung von Trainingssatz, Verifizierungssatz und Testsatz ist offensichtlich nur ein idealer Zustand. Schließlich ist die Realität sehr dürftig und das Problem des Datenlecks ist von Grund auf fast unvermeidlich. Mit der kontinuierlichen Weiterentwicklung verwandter Technologien werden die Speicher- und Empfangsfähigkeiten der Transformer-Struktur, die den Grundstein aktueller großer Modelle bildet, ständig verbessert. In diesem Sommer hat die allgemeine KI-Strategie von Microsoft Research das Ziel erreicht, dem Modell den Empfang von 100 zu ermöglichen Millionen Token, ohne inakzeptable Vergesslichkeit hervorzurufen. Mit anderen Worten: In Zukunft dürften große KI-Modelle in der Lage sein, das gesamte Internet zu lesen.
Selbst wenn der technologische Fortschritt außer Acht gelassen wird, ist eine Datenverschmutzung aufgrund des aktuellen technischen Stands tatsächlich schwer zu vermeiden, da qualitativ hochwertige Daten immer knapp sind und die Produktionskapazität begrenzt ist. Ein Anfang dieses Jahres vom KI-Forschungsteam Epoch veröffentlichtes Papier zeigte, dass KI in weniger als fünf Jahren alle hochwertigen menschlichen Sprachdaten verbrauchen wird, und dieses Ergebnis ist, dass sie die Wachstumsrate der menschlichen Sprache erhöhen wird Daten, das heißt, alle Menschen werden in den nächsten fünf Jahren veröffentlichen. Geschriebene Bücher, geschriebene Aufsätze und geschriebener Code werden alle berücksichtigt, um die Ergebnisse vorherzusagen.
Wenn ein Datensatz zur Auswertung geeignet ist, eignet er sich auf jeden Fall besser für das Vortraining. Beispielsweise verwendet GPT-4 von OpenAI den maßgeblichen Inferenzbewertungsdatensatz GSM8K. Daher gibt es derzeit ein peinliches Problem im Bereich der groß angelegten Modellbewertung. Die Nachfrage nach Daten aus groß angelegten Modellen scheint endlos zu sein, was dazu führt, dass Bewertungsagenturen schneller und weiter vorgehen müssen als groß angelegte Modelle mit künstlicher Intelligenz Hersteller. Allerdings scheinen die heutigen Bewertungsagenturen dazu nicht in der Lage zu sein
Warum achten einige Hersteller besonders auf die Laufergebnisse großer Modelle und versuchen, die Platzierungen nach und nach zu verbessern? Tatsächlich ist die Logik hinter diesem Verhalten genau die gleiche wie bei App-Entwicklern, die die Anzahl der Benutzer ihrer eigenen Apps verwässern. Schließlich ist der Benutzerumfang einer App ein Schlüsselfaktor für die Messung ihres Werts, und in der Anfangsphase des aktuellen groß angelegten KI-Modells sind die Ergebnisse auf der Bewertungsliste schließlich fast das einzige relativ objektive Kriterium In der öffentlichen Wahrnehmung bedeuten hohe Punktzahlen eine starke Leistung.
Während Betrug auf der Liste einen starken Werbeeffekt haben und sogar den Grundstein für die Finanzierung legen kann, wird die Hinzufügung kommerzieller Interessen unweigerlich dazu führen, dass große Hersteller von KI-Modellen sich beeilen, die Rangliste aufzufrischen.
Das obige ist der detaillierte Inhalt vonWenn sie anderer Meinung sind, werden sie punkten. Warum sind große inländische KI-Modelle süchtig danach, „die Rangliste zu klauen'?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Die neueste Grafikkarten-Performance-Rangliste im Jahr 2023
Jan 05, 2024 pm 11:12 PM
Die neueste Grafikkarten-Performance-Rangliste im Jahr 2023
Jan 05, 2024 pm 11:12 PM
Die neuesten Grafikkarten-Benchmark-Ranglisten für 2023 wurden veröffentlicht. Benutzer, die der Grafikkarten-Rangliste folgen, können einen Blick darauf werfen, da Grafikkartenhersteller weiterhin neue Grafikkarten herausbringen und sogar neue Grafikkarten für alte Serien vorstellen ist völlig anders. Aktuelle Grafikkarten-Benchmark-Rangliste 2023, Grafikkarten-Rangliste 2023 Kaufempfehlungen für Computer-Grafikkarten: 1. Low-End-Grafikkarten: RTX3050, 5600XT und 2060S sind allesamt gute Einstiegsmöglichkeiten Kaufen Sie eine Grafikkarte und erhalten Sie eine CPU, mit der Sie LOL, Cf, Overwatch und andere leichte 3D-Online-Spiele spielen können, mit hervorragendem Preis-Leistungs-Verhältnis. 2. Einstiegsgrafikkarte: 3060, geeignet für die meisten allgemeinen Mainstream-3D-Spiele, mit mittlerer Leistung und geringe Bildqualität. 3. Mittelklasse-Grafikkarte: NVIDIA: RTX3060Ti, RTX2
 Freigeschaltete Benchmarks des Kirin 9000S enthüllt: Atemberaubende Leistung übertrifft die Erwartungen
Sep 05, 2023 pm 12:45 PM
Freigeschaltete Benchmarks des Kirin 9000S enthüllt: Atemberaubende Leistung übertrifft die Erwartungen
Sep 05, 2023 pm 12:45 PM
Huaweis neuestes Mobiltelefon Mate60Pro hat nach seinem Verkaufsstart auf dem heimischen Markt große Aufmerksamkeit erregt. Allerdings gab es auf der Benchmark-Plattform in letzter Zeit einige Kontroversen über die Leistung des in der Maschine verbauten Kirin 9000S-Prozessors. Den Testergebnissen der Plattform zufolge sind die Laufwerte des Kirin 9000S unvollständig und die GPU-Laufwerte fehlen, was dazu führt, dass sich einige Benchmarking-Software nicht anpassen kann. Online veröffentlichten Informationen zufolge hat der Kirin 9000S erstaunliche Ergebnisse erzielt Der freigeschaltete Laufpunktzahltest beträgt 950935 Punkte. Konkret liegt der CPU-Score sogar bei 279.677 Punkten, während der bisher fehlende GPU-Score bei 251.152 Punkten liegt. Verglichen mit der Gesamtpunktzahl von 699783 Punkten im vorherigen offiziellen AnTuTu-Test zeigt dies die Leistungsverbesserung des Kirin 9000S.
 Die Nachfrage nach Rechenleistung ist im Zuge der Welle großer KI-Modelle explodiert. „Großes Modell + große Rechenleistung' von SenseTime ermöglicht die Entwicklung mehrerer Branchen.
Jun 09, 2023 pm 07:35 PM
Die Nachfrage nach Rechenleistung ist im Zuge der Welle großer KI-Modelle explodiert. „Großes Modell + große Rechenleistung' von SenseTime ermöglicht die Entwicklung mehrerer Branchen.
Jun 09, 2023 pm 07:35 PM
Kürzlich fand die „Lingang New Area Intelligent Computing Conference“ mit dem Thema „KI führt die Ära an, Rechenleistung treibt die Zukunft“ statt. Bei dem Treffen wurde die New Area Intelligent Computing Industry Alliance offiziell als Anbieter von Rechenleistung gegründet. Gleichzeitig wurde SenseTime der Titel „New Area Intelligent Computing Industry Chain Master“ verliehen. Als aktiver Teilnehmer am Lingang-Rechenleistungs-Ökosystem hat SenseTime derzeit eine der größten intelligenten Computerplattformen Asiens aufgebaut – SenseTime AIDC, die eine Gesamtrechenleistung von 5.000 Petaflops ausgeben und 20 ultragroße Modelle mit Hunderten von Milliarden Parametern unterstützen kann. Trainiere gleichzeitig. SenseCore, ein auf AIDC basierendes und zukunftsorientiertes Großgerät, hat sich zum Ziel gesetzt, eine hocheffiziente, kostengünstige und groß angelegte KI-Infrastruktur und -Dienste der nächsten Generation zu schaffen, um künstliche Intelligenz zu stärken.
 Forscher: KI-Modellinferenz verbraucht mehr Strom und der Stromverbrauch der Industrie wird im Jahr 2027 mit dem der Niederlande vergleichbar sein
Oct 14, 2023 am 08:25 AM
Forscher: KI-Modellinferenz verbraucht mehr Strom und der Stromverbrauch der Industrie wird im Jahr 2027 mit dem der Niederlande vergleichbar sein
Oct 14, 2023 am 08:25 AM
IT House berichtete am 13. Oktober, dass „Joule“, eine Schwesterzeitschrift von „Cell“, diese Woche einen Artikel mit dem Titel „Der wachsende Energie-Fußabdruck künstlicher Intelligenz“ veröffentlicht hat. Durch Nachfragen erfuhren wir, dass dieses Papier von Alex DeVries, dem Gründer der wissenschaftlichen Forschungseinrichtung Digiconomist, veröffentlicht wurde. Er behauptete, dass die Denkleistung der künstlichen Intelligenz in Zukunft viel Strom verbrauchen könnte. Schätzungen zufolge könnte der Stromverbrauch der künstlichen Intelligenz bis 2027 dem Stromverbrauch der Niederlande für ein Jahr entsprechen Die Außenwelt hat immer geglaubt, dass das Training eines KI-Modells „das Wichtigste in der KI“ sei.
 OPPO Reno11 F erscheint auf Geekbench: ausgestattet mit Dimensity 7050
Feb 06, 2024 pm 11:10 PM
OPPO Reno11 F erscheint auf Geekbench: ausgestattet mit Dimensity 7050
Feb 06, 2024 pm 11:10 PM
Medienberichten vom 6. Februar zufolge hat OPPO letztes Jahr die OPPOReno11-Serie herausgebracht und zwei Versionen angeboten: die Standardversion und die Pro-Version. Jetzt wird OPPO auch eine neue Version der Reno11-Serie auf den Markt bringen – Reno11F. Derzeit ist OPPOReno11F in der Geekbench6-Datenbank enthalten. Die neue Maschine hat einen Single-Core-Running-Score von 897 Punkten und einen Multi-Core-Running-Score von 2329 Punkten. Laut Benchmark-Tests ist das neue Telefon mit einem MediaTek Dimensity 7050 SoC, gepaart mit einer Mali-G68MC4-GPU und 8 GB RAM ausgestattet und mit dem ColorOS14-System auf Basis von Android 14 vorinstalliert. Den Nachrichten zufolge wird OPPOReno11F ein 6,7-Zoll-A verwenden
 OnePlus Ace 3V erscheint auf der Geekbench-Plattform: Weltpremiere von Snapdragon 7+ Gen3
Mar 12, 2024 pm 10:34 PM
OnePlus Ace 3V erscheint auf der Geekbench-Plattform: Weltpremiere von Snapdragon 7+ Gen3
Mar 12, 2024 pm 10:34 PM
Laut Nachrichten vom 12. März ist das Mobiltelefon OnePlus Ace3V mit der Modellnummer PJF110 auf der Benchmarking-Plattform Geekbench erschienen. Im laufenden Geekbench6-Score erreichte das OnePlus Ace3V den höchsten Single-Core-Score von 1848 und Multi-Core-Score von 5007, und im Geekbench5 erreichte es einen Single-Core-Score von 1416 und einen Multi-Core-Score von 4829, was nahe an Dimensity 9200 liegt +. Es wird berichtet, dass OnePlus Ace3V die weltweit erste mobile Snapdragon 7+Gen3-Plattform sein wird. Sie wird auf Basis des 4-nm-Prozesses hergestellt und verfügt über eine „1+4+3“-Kernfrequenz GHz und integriert die Adreno732-GPU. In Bezug auf die Batterielebensdauer ist das Flugzeug mit 55 ausgestattet
 China Unicom veröffentlicht ein KI-Modell für große Bilder und Texte, das Bilder und Videoclips aus Text generieren kann
Jun 29, 2023 am 09:26 AM
China Unicom veröffentlicht ein KI-Modell für große Bilder und Texte, das Bilder und Videoclips aus Text generieren kann
Jun 29, 2023 am 09:26 AM
Driving China News am 28. Juni 2023, heute während des Mobile World Congress in Shanghai, veröffentlichte China Unicom das Grafikmodell „Honghu Graphic Model 1.0“. China Unicom sagte, dass das Honghu-Grafikmodell das erste große Modell für Mehrwertdienste von Betreibern sei. Ein Reporter von China Business News erfuhr, dass das Grafikmodell von Honghu derzeit über zwei Versionen von 800 Millionen Trainingsparametern und 2 Milliarden Trainingsparametern verfügt, mit denen Funktionen wie textbasierte Bilder, Videobearbeitung und bildbasierte Bilder realisiert werden können. Darüber hinaus sagte Liu Liehong, Vorsitzender von China Unicom, in seiner heutigen Grundsatzrede, dass generative KI eine einzigartige Entwicklung einleitet und 50 % der Arbeitsplätze in den nächsten zwei Jahren stark von künstlicher Intelligenz betroffen sein werden.
 Viermal schneller, enthüllte ByteDances Open-Source-Hochleistungs-Trainings-Inferenz-Engine LightSeq-Technologie
May 02, 2023 pm 05:52 PM
Viermal schneller, enthüllte ByteDances Open-Source-Hochleistungs-Trainings-Inferenz-Engine LightSeq-Technologie
May 02, 2023 pm 05:52 PM
Das Transformer-Modell stammt aus dem vom Google-Team im Jahr 2017 veröffentlichten Artikel „Attentionisallyouneed“. In diesem Artikel wurde zunächst das Konzept vorgeschlagen, Aufmerksamkeit als Ersatz für die zyklische Struktur des Seq2Seq-Modells zu verwenden, was große Auswirkungen auf den NLP-Bereich hatte. Und mit der kontinuierlichen Weiterentwicklung der Forschung in den letzten Jahren sind Transformer-bezogene Technologien nach und nach von der Verarbeitung natürlicher Sprache auf andere Bereiche übergegangen. Bisher sind die Modelle der Transformer-Serie zu Mainstream-Modellen in NLP, CV, ASR und anderen Bereichen geworden. Daher ist die Frage, wie Transformer-Modelle schneller trainiert und abgeleitet werden können, zu einer wichtigen Forschungsrichtung in der Branche geworden. Quantisierungstechniken mit geringer Präzision können
