
 Technologie-Peripheriegeräte
KI
Ein Foto erzeugt ein Video. Mund öffnen, nicken, Emotionen, Wut, Trauer und Freude können durch Tippen gesteuert werden.
Technologie-Peripheriegeräte
KI
Ein Foto erzeugt ein Video. Mund öffnen, nicken, Emotionen, Wut, Trauer und Freude können durch Tippen gesteuert werden.
Ein Foto erzeugt ein Video. Mund öffnen, nicken, Emotionen, Wut, Trauer und Freude können durch Tippen gesteuert werden.

Kürzlich hat eine von Microsoft durchgeführte Studie gezeigt, wie flexibel die Videoverarbeitungssoftware PS ist
In dieser Studie gibt man der KI einfach ein Foto, und sie kann darüber hinaus ein Video der Personen auf dem Foto erstellen können die Mimik und Bewegungen der Charaktere durch Text gesteuert werden. Wenn der Befehl, den Sie beispielsweise geben, „Öffne deinen Mund“ lautet, öffnet die Figur im Video tatsächlich ihren Mund.

Wenn der Befehl, den Sie geben, „traurig“ ist, macht sie traurige Gesichtsausdrücke und Kopfbewegungen.
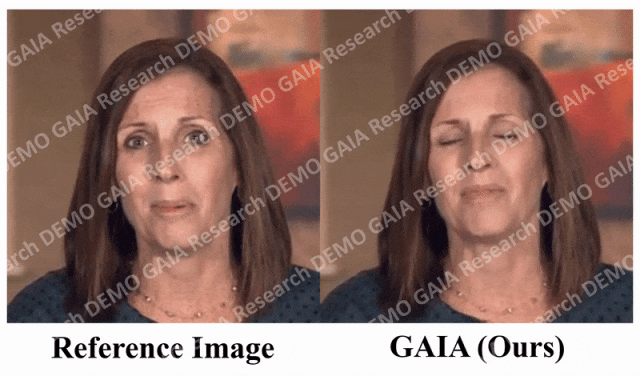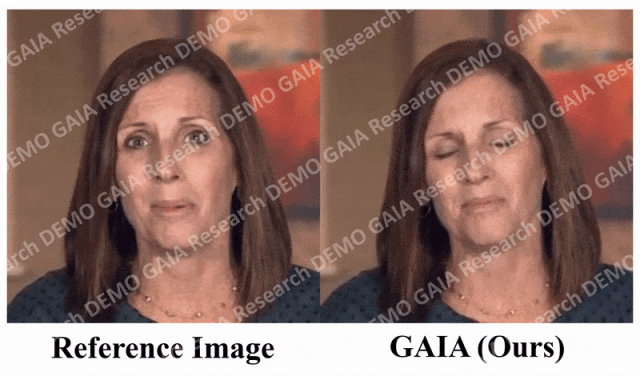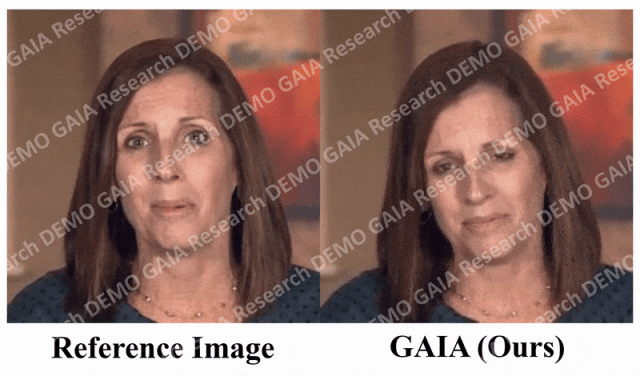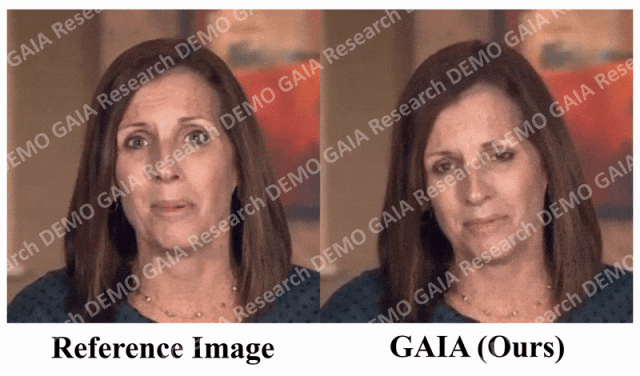
Beim Befehl „Überraschung“ werden die Stirnfalten des Avatars zusammengedrückt.

Darüber hinaus können Sie auch eine Stimme bereitstellen, um die Mundform und Bewegungen der virtuellen Figur mit der Stimme zu synchronisieren. Alternativ können Sie dem Avatar ein Live-Video zur Nachahmung zur Verfügung stellen
Diese Forschung heißt GAIA (Generative AI for Avatar, generative AI für Avatare) und ihre Demo hat begonnen, sich in den sozialen Medien zu verbreiten. Viele Menschen bewundern seine Wirkung und hoffen, damit die Toten „auferstehen“ zu lassen.

Aber einige Leute befürchten, dass die kontinuierliche Weiterentwicklung dieser Technologien es schwieriger machen wird, Online-Videos zwischen echt und gefälscht zu unterscheiden oder dass sie von Kriminellen für Betrug missbraucht werden. Es scheint, dass die Betrugsbekämpfungsmaßnahmen weiter verbessert werden.
Was ist das Innovative an GAIA?
Zero-Sample-Technologie zur Erzeugung virtueller sprechender Charaktere zielt darauf ab, natürliche Videos basierend auf Sprache zu synthetisieren und sicherzustellen, dass die generierten Mundformen, Ausdrücke und Kopfhaltungen mit dem Sprachinhalt übereinstimmen. Frühere Forschungen erfordern in der Regel ein spezifisches Training oder die Abstimmung spezifischer Modelle für jeden virtuellen Charakter oder die Verwendung von Vorlagenvideos während der Inferenz, um qualitativ hochwertige Ergebnisse zu erzielen. In jüngster Zeit haben sich Forscher auf die Entwicklung und Verbesserung von Methoden zur Erzeugung sprechender Avatare ohne Aufnahme konzentriert, indem sie einfach ein Porträtbild des Ziel-Avatars als Referenz für das Erscheinungsbild verwenden. Diese Methoden verwenden jedoch normalerweise Domänenprioritäten wie Warping-basierte Bewegungsdarstellung und 3D Morphable Model (3DMM), um die Schwierigkeit der Aufgabe zu verringern. Solche Heuristiken sind zwar effektiv, können jedoch die Vielfalt einschränken und zu unnatürlichen Ergebnissen führen. Daher steht das direkte Lernen aus der Datenverteilung im Mittelpunkt zukünftiger Forschung
In diesem Artikel schlugen Forscher von Microsoft GAIA (Generative AI for Avatar) vor, das natürlich sprechende Menschen aus Sprache und einzelnen Porträtbildern synthetisieren kann. Domänenprioren werden während des Generierungsprozesses eliminiert.
Projektadresse: https://microsoft.github.io/GAIA/Details zu verwandten Projekten finden Sie unter diesem Link
Papierlink: https://arxiv.org/pdf/ 2311.15230 .pdf
Gaia enthüllt zwei wichtige Erkenntnisse:
-
Verwenden Sie die Stimme, um die Bewegung der virtuellen Figur zu steuern, während der Hintergrund und das Erscheinungsbild der virtuellen Figur während des gesamten Videos unverändert bleiben. Inspiriert davon trennt dieses Papier die Bewegung und das Erscheinungsbild jedes Bildes, wobei das Erscheinungsbild zwischen den Bildern geteilt wird, während die Bewegung für jedes Bild einzigartig ist. Um Bewegung aus Sprache vorherzusagen, kodiert dieser Artikel Bewegungssequenzen in latente Bewegungssequenzen und verwendet ein Diffusionsmodell, das von der Eingabesprache abhängt, um die latente Sequenz vorherzusagen Es gibt eine enorme Vielfalt an Gesichtsausdrücken und Kopfhaltungen, die einen umfangreichen und vielfältigen Datensatz erfordert. Daher wurde in dieser Studie ein hochwertiger sprechender Avatar-Datensatz gesammelt, der aus 16.000 einzigartigen Sprechern unterschiedlichen Alters, Geschlechts, Hauttyps und Sprechstils besteht, wodurch die Ergebnisse der Generierung natürlich und vielfältig wurden.
Basierend auf den beiden oben genannten Erkenntnissen schlägt dieses Papier das GAIA-Framework vor, das aus einem Variational Autoencoder (VAE) (oranges Modul) und einem Diffusionsmodell (blaue und grüne Module) besteht.
VAEs Hauptfunktion besteht darin, Bewegung und Aussehen aufzuschlüsseln. Es besteht aus zwei Encodern (Bewegungsencoder und Erscheinungsencoder) und einem Decoder. Während des Trainings ist die Eingabe in den Bewegungsencoder das aktuelle Bild der Gesichtsmarkierungen, während die Eingabe in den Erscheinungsencoder ein zufällig abgetastetes Bild im aktuellen Videoclip ist Optimierter Decoder zur Rekonstruktion des aktuellen Frames. Sobald Sie die trainierte VAE erhalten, erhalten Sie die potenziellen Aktionen (d. h. die Ausgabe des Bewegungsencoders) für alle Trainingsdaten Videoclips Bewegungslatenzsequenz, wodurch Erscheinungsinformationen für den Generierungsprozess bereitgestellt werden
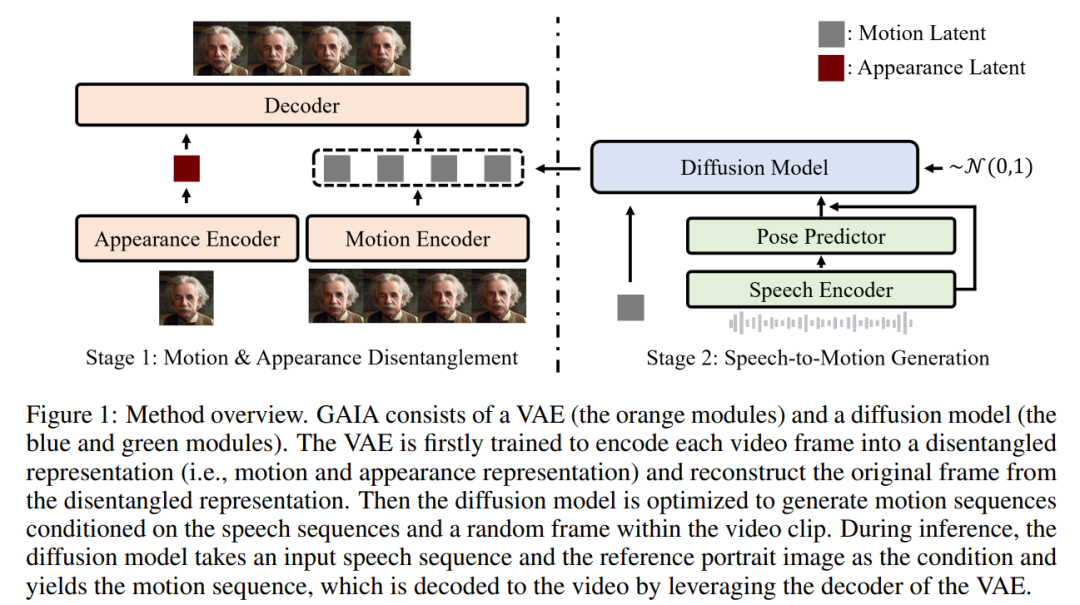 Im Inferenzprozess verwendet das Diffusionsmodell bei gegebenem Referenzporträtbild des virtuellen Zielcharakters das Bild und die eingegebene Sprachsequenz als Bedingungen für die Generierung einer Bewegungslatenzsequenz, die dem Sprachinhalt entspricht. Die erzeugte latente Bewegungssequenz und das Referenzporträtbild werden dann durch einen VAE-Decoder geleitet, um die gesprochene Videoausgabe zu synthetisieren.
Im Inferenzprozess verwendet das Diffusionsmodell bei gegebenem Referenzporträtbild des virtuellen Zielcharakters das Bild und die eingegebene Sprachsequenz als Bedingungen für die Generierung einer Bewegungslatenzsequenz, die dem Sprachinhalt entspricht. Die erzeugte latente Bewegungssequenz und das Referenzporträtbild werden dann durch einen VAE-Decoder geleitet, um die gesprochene Videoausgabe zu synthetisieren.
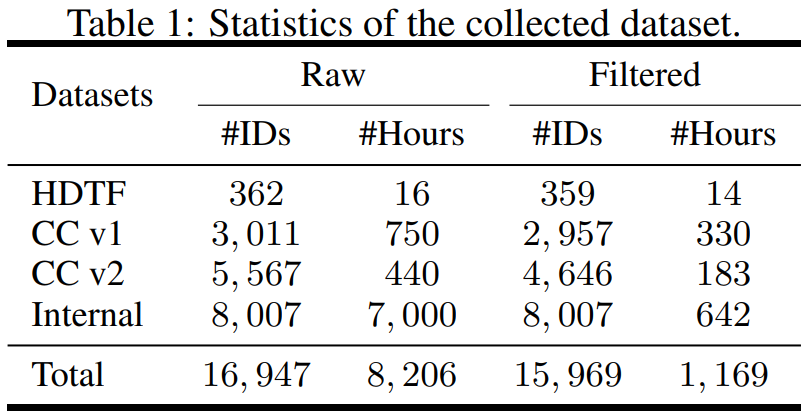
Die Studie ist in Bezug auf Daten strukturiert und sammelt Datensätze aus verschiedenen Quellen, einschließlich High-Definition Talking Face Dataset (HDTF) und Casual Conversation Datasets v1&v2 (CC v1&v2). Zusätzlich zu diesen drei Datensätzen wurde im Rahmen der Untersuchung auch ein umfangreicher interner sprechender Avatar-Datensatz mit 7.000 Stunden Video und 8.000 Sprecher-IDs erfasst. Die statistische Übersicht über den Datensatz ist in Tabelle 1 dargestellt.
Um die erforderlichen Informationen zu erhalten, schlägt der Artikel mehrere automatische Filterstrategien vor, um die Qualität der Trainingsdaten sicherzustellen:
Lippe erstellen Bewegungen sichtbar, die Vorderrichtung des Avatars sollte zur Kamera zeigen;
Um die Stabilität zu gewährleisten, sollten die Gesichtsbewegungen im Video fließend sein und nicht schnell verwackeln
- In diesem Artikel werden VAE- und Diffusionsmodelle anhand gefilterter Daten trainiert. Aus den experimentellen Ergebnissen hat dieses Papier drei wichtige Schlussfolgerungen gezogen:
- GAIA ist in der Lage, virtuelle Charaktere ohne Stichprobe zu erzeugen, mit überlegener Leistung in Bezug auf Natürlichkeit, Vielfalt, Lippensynchronisationsqualität und visuelle Qualität. Laut subjektiver Bewertung der Forscher übertraf GAIA alle Basismethoden deutlich GAIA ist ein allgemeines und flexibles Framework, das verschiedene Anwendungen ermöglicht, einschließlich der steuerbaren Erzeugung sprechender Avatare und der Erzeugung von Avataren mit Textbefehlen.
Während des Experiments verglich die Studie GAIA mit drei leistungsstarken Basislinien, darunter FOMM, HeadGAN und Face-vid2vid. Die Ergebnisse sind in Tabelle 2 dargestellt: VAE in GAIA erzielt konsistente Verbesserungen gegenüber früheren videogesteuerten Basislinien und zeigt, dass GAIA Erscheinungsbild- und Bewegungsdarstellungen erfolgreich zerlegt.
Sprachgesteuerte Ergebnisse. Die sprachgesteuerte Erzeugung sprechender Avatare wird durch die Vorhersage von Bewegungen aus der Sprache erreicht. Tabelle 3 und Abbildung 2 bieten quantitative und qualitative Vergleiche von GAIA mit den Methoden MakeItTalk, Audio2Head und SadTalker.
Aus den Daten geht hervor, dass GAIA in Bezug auf die subjektive Bewertung alle Basismethoden bei weitem übertrifft. Genauer gesagt, wie in Abbildung 2 gezeigt, hängen die Generierungsergebnisse von Basismethoden normalerweise stark vom Referenzbild ab, selbst wenn das Referenzbild geschlossene Augen oder eine ungewöhnliche Kopfhaltung aufweist. Im Gegensatz dazu zeigt GAIA bei verschiedenen Referenzbildern eine gute Leistung. Robust und erzeugt Ergebnisse mit höherer Natürlichkeit, hoher Lippensynchronisation, besserer visueller Qualität und Bewegungsvielfalt. Der Sync-D-Score von 8,528 liegt nahe am echten Video-Score (8,548), was darauf hinweist, dass das generierte Video eine hervorragende Lippensynchronisation aufweist. Die Studie erzielte mit dem Ausgangswert vergleichbare FID-Werte, die möglicherweise durch unterschiedliche Kopfhaltungen beeinflusst wurden, da die Studie ergab, dass das Modell ohne Diffusionstraining bessere FID-Werte erzielte, wie in Tabelle 6 aufgeführt
Das obige ist der detaillierte Inhalt vonEin Foto erzeugt ein Video. Mund öffnen, nicken, Emotionen, Wut, Trauer und Freude können durch Tippen gesteuert werden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Laut Nachrichten vom 3. Juni sendet Microsoft aktiv Vollbildbenachrichtigungen an alle Windows 10-Benutzer, um sie zu einem Upgrade auf das Betriebssystem Windows 11 zu ermutigen. Dabei handelt es sich um Geräte, deren Hardwarekonfigurationen das neue System nicht unterstützen. Seit 2015 hat Windows 10 fast 70 % des Marktanteils eingenommen und seine Dominanz als Windows-Betriebssystem fest etabliert. Der Marktanteil liegt jedoch weit über dem Marktanteil von 82 %, und der Marktanteil übersteigt den von Windows 11, das 2021 erscheinen wird, bei weitem. Obwohl Windows 11 seit fast drei Jahren auf dem Markt ist, ist die Marktdurchdringung immer noch langsam. Microsoft hat angekündigt, den technischen Support für Windows 10 nach dem 14. Oktober 2025 einzustellen, um sich stärker darauf zu konzentrieren
 Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Laut Nachrichten dieser Website vom 14. August veröffentlichte Microsoft während des heutigen August-Patch-Dienstags kumulative Updates für Windows 11-Systeme, darunter das Update KB5041585 für 22H2 und 23H2 sowie das Update KB5041592 für 21H2. Nachdem das oben genannte Gerät mit dem kumulativen Update vom August installiert wurde, sind die mit dieser Site verbundenen Versionsnummernänderungen wie folgt: Nach der Installation des 21H2-Geräts wurde die Versionsnummer auf Build22000.314722H2 erhöht. Die Versionsnummer wurde auf Build22621.403723H2 erhöht. Nach der Installation des Geräts wurde die Versionsnummer auf Build22631.4037 erhöht. Die Hauptinhalte des KB5041585-Updates für Windows 1121H2 sind wie folgt: Verbesserung: Verbessert
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
