

In letzter Zeit haben Sie vielleicht mehr oder weniger von „Subjekt 3“ gehört, bei dem es um winkende Hände, halb im Schritt stehende Füße und passende rhythmische Musik geht. Diese Tanzbewegung wurde im gesamten Internet nachgeahmt.
Was würde passieren, wenn ähnliche Tänze von KI generiert würden? Wie im Bild unten gezeigt, führen sowohl moderne Menschen als auch Papiermenschen gleichmäßige Bewegungen aus. Was Sie vielleicht nicht vermuten, ist, dass es sich um ein Tanzvideo handelt, das auf der Grundlage eines Bildes erstellt wurde.

Die Charakterbewegungen werden schwieriger und das generierte Video ist auch sehr flüssig (ganz rechts):

Es ist einfach, Messi und Iron Man in Bewegung zu setzen:
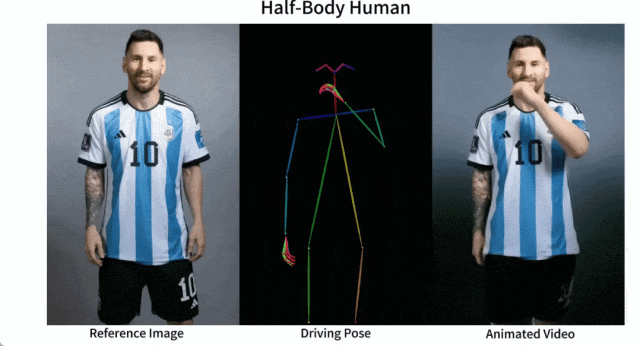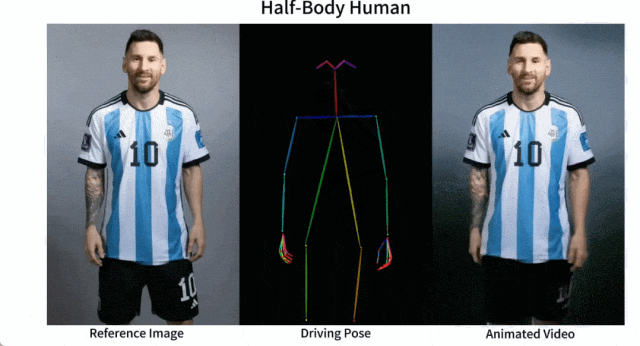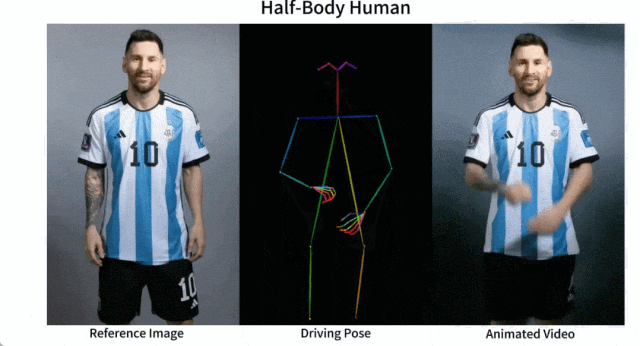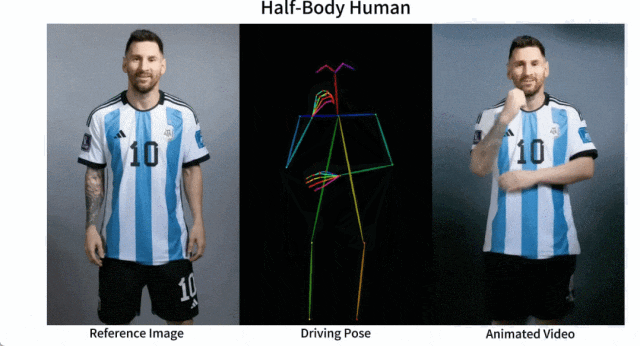
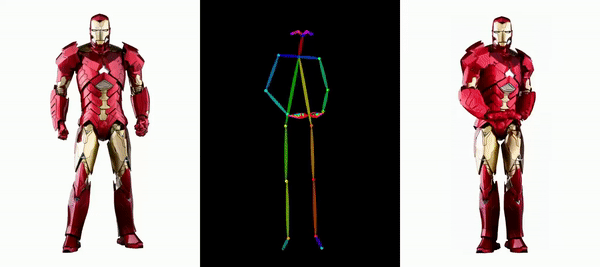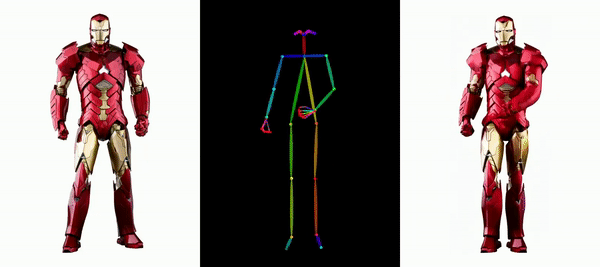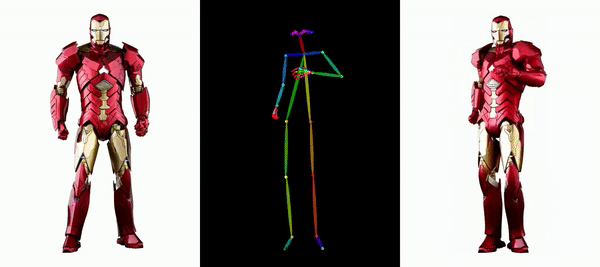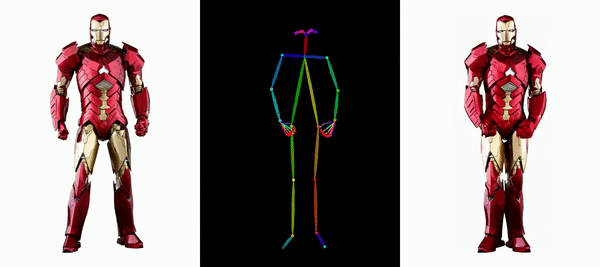
Es gibt auch verschiedene Anime-Girls.

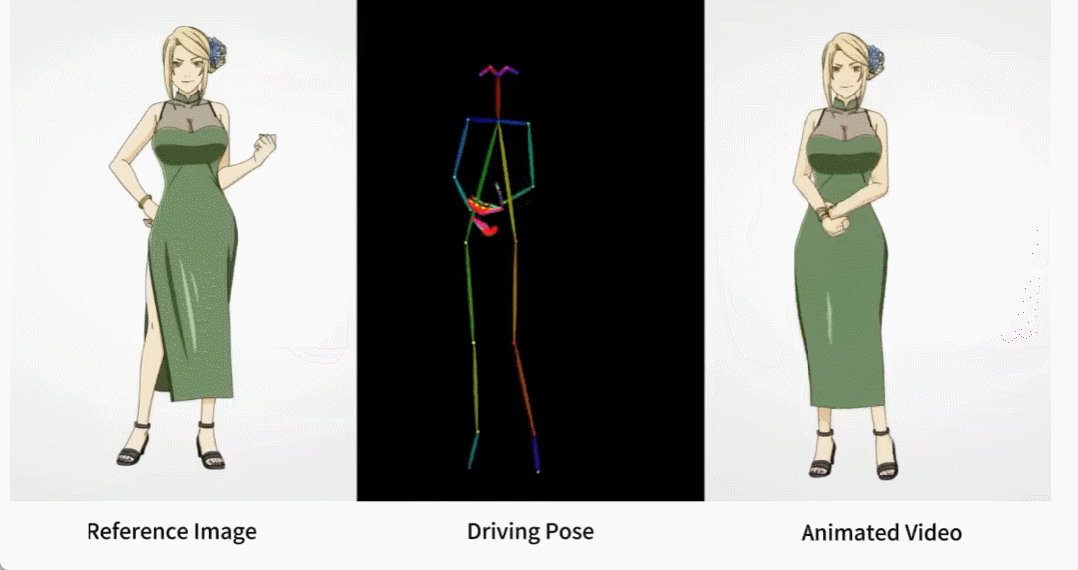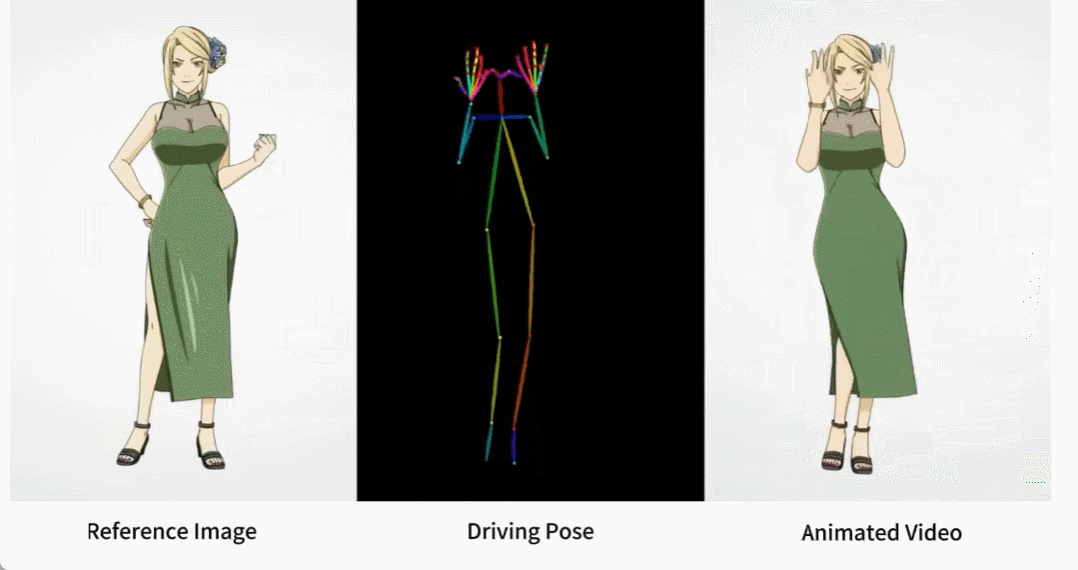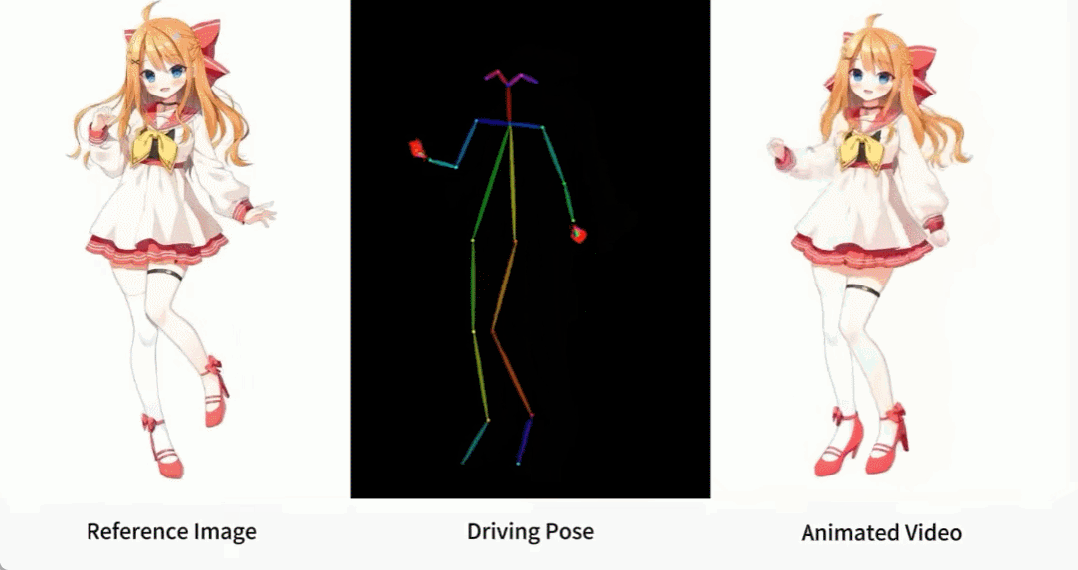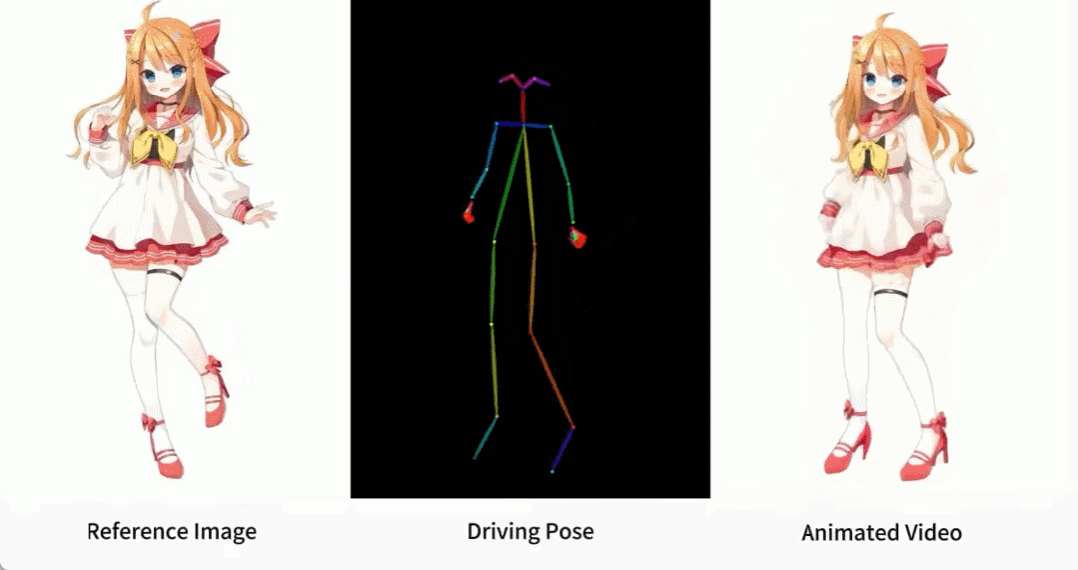
Wie werden diese Effekte erzielt? Lesen wir weiter
Charakteranimation ist der Prozess der Umwandlung von Originalcharakterbildern in realistische Videos in der gewünschten Posensequenz. Diese Aufgabe hat viele potenzielle Anwendungsbereiche, wie Online-Einzelhandel, Unterhaltungsvideos, Kunstschaffung und virtuelle Charaktere usw.
Seit dem Aufkommen der GAN-Technologie haben Forscher kontinuierlich die Umwandlung von Bildern in Animationen und dergleichen erforscht Abschluss der Posenübertragungsmethoden. Die generierten Bilder oder Videos weisen jedoch immer noch einige Probleme auf, wie z. B. lokale Verzerrung, unscharfe Details, semantische Inkonsistenz und zeitliche Instabilität, die die Anwendung dieser Methoden behindern.
Ali-Forscher haben eine Methode namens Animate Anybody vorgeschlagen, mit der Zeichenbilder konvertiert werden in animierte Videos, die der gewünschten Posenfolge folgen. Diese Studie übernahm das Stable Diffusion-Netzwerkdesign und vorab trainierte Gewichte und modifizierte das Entrauschungs-UNet, um es an die Eingabe mit mehreren Frames anzupassen. Papieradresse: https://arxiv.org/pdf/2311.17117. pdf

Dieses Papier wird anhand von zwei spezifischen Benchmarks für die menschliche Videosynthese bewertet (UBC Fashion Video Dataset und TikTok Dataset). Die Ergebnisse zeigen, dass Animate Anybody SOTA-Ergebnisse erzielt. Darüber hinaus verglich die Studie die Animate Anybody-Methode mit allgemeinen Bild-zu-Video-Methoden, die auf großen Datenmengen trainiert wurden, und zeigte, dass Animate Anybody überlegene Fähigkeiten bei der Charakteranimation aufweist.

Animate Anybody Vergleich mit anderen Methoden:

Die Verarbeitungsmethode dieses Artikels ist in Abbildung 2 dargestellt. Die ursprüngliche Eingabe des Netzwerks besteht aus Multi-Frame-Rauschen. Um den Rauschunterdrückungseffekt zu erzielen, haben die Forscher eine Konfiguration basierend auf dem SD-Design übernommen, das gleiche Framework und die gleichen Blockeinheiten verwendet und die Trainingsgewichte von SD geerbt. Konkret umfasst diese Methode drei Schlüsselteile:
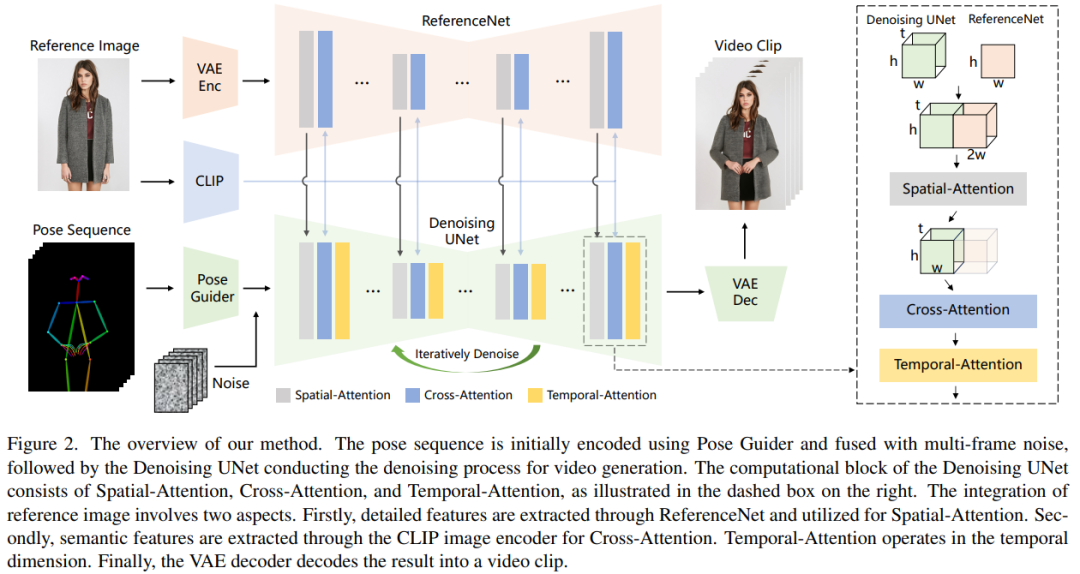
ReferenceNet
ReferenceNet ist ein Referenzbild-Feature-Extraktionsnetzwerk. Sein Framework ist ungefähr das gleiche wie das entrauschende UNet, nur die zeitliche Schicht ist unterschiedlich. Daher erbt ReferenceNet die ursprünglichen SD-Gewichte ähnlich wie das entrauschende UNet, und jede Gewichtsaktualisierung wird unabhängig durchgeführt. Die Forscher erklären, wie man Funktionen von ReferenceNet in die Entrauschung von UNet integriert.
ReferenceNet bietet zwei Vorteile. Erstens kann ReferenceNet die vorab trainierten Bild-Feature-Modellierungsfunktionen von Raw SD nutzen, um gut initialisierte Features zu erzeugen. Zweitens: Da ReferenceNet und entrauschendes UNet im Wesentlichen dieselbe Netzwerkstruktur und gemeinsame Initialisierungsgewichte haben, kann entrauschendes UNet selektiv Features lernen, die im selben Feature-Raum von ReferenceNet zugeordnet sind.
Haltungsführer
Der umgeschriebene Inhalt lautet: Dieser leichte Haltungsführer verwendet vier Faltungsschichten (4×4-Kernel, 2×2-Schritt), und die Anzahl der Kanäle beträgt 16, 32, 64 , 128, ähnlich dem bedingten Encoder in [56], wird verwendet, um Posenbilder mit derselben Auflösung wie das zugrunde liegende Rauschen auszurichten. Das verarbeitete Posenbild wird dem latenten Rauschen hinzugefügt und dann zur Verarbeitung in das Entrauschungs-UNet eingegeben. Der Posenführer wird mit Gaußschen Gewichten initialisiert und verwendet in der endgültigen Zuordnungsebene keine Faltungen.
Temporale Ebene
Das Design der zeitlichen Ebene ist von AnimateDiff inspiriert. Für eine Feature-Map x∈R^b×t×h×w×c verformt der Forscher sie zunächst in x∈R^(b×h×w)×t×c und führt dann eine zeitliche Aufmerksamkeit durch, also entlang Selbstaufmerksamkeit in der Dimension t. Die Merkmale der zeitlichen Schicht werden durch Restverbindungen mit den ursprünglichen Merkmalen zusammengeführt. Dieses Design steht im Einklang mit der folgenden zweistufigen Trainingsmethode. Temporale Schichten werden ausschließlich innerhalb des Res-Trans-Blocks zur Entrauschung von UNet verwendet.
Trainingsstrategie
Der Trainingsprozess ist in zwei Phasen unterteilt.
Umgeschriebener Inhalt: In der ersten Trainingsphase wird ein einzelnes Videobild zum Training verwendet. Im UNet-Entrauschungsmodell schlossen die Forscher vorübergehend die zeitliche Schicht aus und verwendeten Einzelbildrauschen als Eingabe. Gleichzeitig werden auch das Referenznetzwerk und der Einstellungsratgeber geschult. Referenzbilder werden zufällig aus dem gesamten Videoclip ausgewählt. Sie verwendeten vorab trainierte Gewichte, um die Entrauschungsmodelle UNet und ReferenceNet zu initialisieren. Der Posenführer wird mit Gaußschen Gewichten initialisiert, mit Ausnahme der letzten Projektionsebene, die keine Faltungen verwendet. Die Gewichtungen des VAE-Encoders und -Decoders sowie des CLIP-Bildencoders bleiben unverändert. Das Optimierungsziel dieser Phase besteht darin, anhand des Referenzbilds und der Zielpose qualitativ hochwertige animierte Bilder zu generieren Gewichte. Die Eingabe in das Modell besteht aus einem 24-Frame-Videoclip. Zu diesem Zeitpunkt wird nur die zeitliche Schicht trainiert, während die Gewichte anderer Teile des Netzwerks festgelegt sind.
Experimente und Ergebnisse
Modevideosynthese. Das Ziel der Modevideosynthese besteht darin, Modefotos mithilfe gesteuerter Posensequenzen in realistische animierte Videos umzuwandeln. Experimente werden mit dem UBC Fashion Video Dataset durchgeführt, der aus 500 Schulungsvideos und 100 Testvideos besteht, die jeweils etwa 350 Frames enthalten. Quantitative Vergleiche sind in Tabelle 1 dargestellt. Aus den Ergebnissen geht hervor, dass die Methode in diesem Artikel besser ist als andere Methoden, insbesondere bei Videomessindikatoren, und einen klaren Vorsprung aufweist. 
Der qualitative Vergleich ist in Abbildung 4 dargestellt. Für einen fairen Vergleich verwendeten die Forscher den Open-Source-Code von DreamPose, um Ergebnisse ohne Feinabstimmung der Proben zu erhalten. Im Bereich Modevideos sind die Anforderungen an Kleidungsdetails sehr streng. Allerdings gelingt es den von DreamPose und BDMM generierten Videos nicht, die Konsistenz der Kleidungsdetails aufrechtzuerhalten, und sie weisen erhebliche Fehler in der Farbe und bei feinen Strukturelementen auf. Im Gegensatz dazu können die mit dieser Methode erzielten Ergebnisse die Konsistenz von Kleidungsdetails effektiver aufrechterhalten. 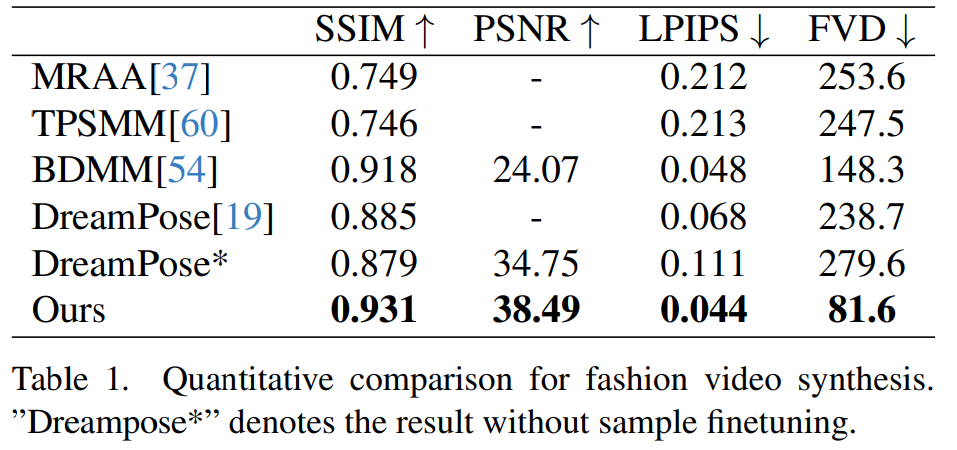
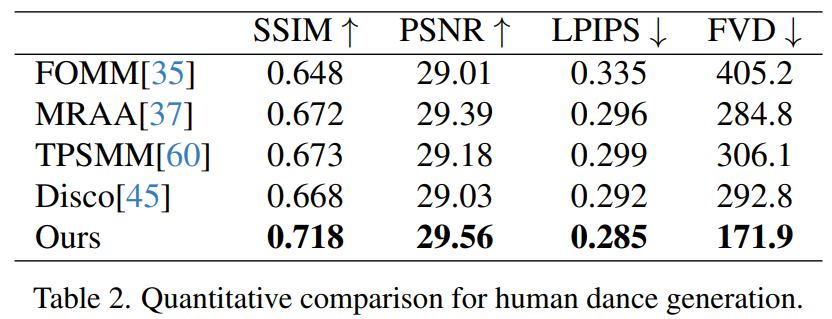
 Human Dance Generation ist eine Studie, deren Ziel es ist, menschlichen Tanz durch animierte Bilder realistischer Tanzszenen zu erzeugen. Die Forscher nutzten den TikTok-Datensatz, der 340 Trainingsvideos und 100 Testvideos umfasst. Sie führten einen quantitativen Vergleich mit demselben Testsatz durch, der 10 Videos im TikTok-Stil umfasste, und folgten dabei der Datensatzpartitionierungsmethode von DisCo. Aus Tabelle 2 ist ersichtlich, dass die Methode in diesem Artikel die besten Ergebnisse erzielt. Um die Generalisierungsfähigkeit des Modells zu verbessern, kombiniert DisCo das Vortraining menschlicher Attribute und verwendet eine große Anzahl von Bildpaaren, um das Modell vorab zu trainieren. Im Gegensatz dazu trainierten andere Forscher nur mit dem TikTok-Datensatz, aber die Ergebnisse waren immer noch besser als bei DisCo
Human Dance Generation ist eine Studie, deren Ziel es ist, menschlichen Tanz durch animierte Bilder realistischer Tanzszenen zu erzeugen. Die Forscher nutzten den TikTok-Datensatz, der 340 Trainingsvideos und 100 Testvideos umfasst. Sie führten einen quantitativen Vergleich mit demselben Testsatz durch, der 10 Videos im TikTok-Stil umfasste, und folgten dabei der Datensatzpartitionierungsmethode von DisCo. Aus Tabelle 2 ist ersichtlich, dass die Methode in diesem Artikel die besten Ergebnisse erzielt. Um die Generalisierungsfähigkeit des Modells zu verbessern, kombiniert DisCo das Vortraining menschlicher Attribute und verwendet eine große Anzahl von Bildpaaren, um das Modell vorab zu trainieren. Im Gegensatz dazu trainierten andere Forscher nur mit dem TikTok-Datensatz, aber die Ergebnisse waren immer noch besser als bei DisCo
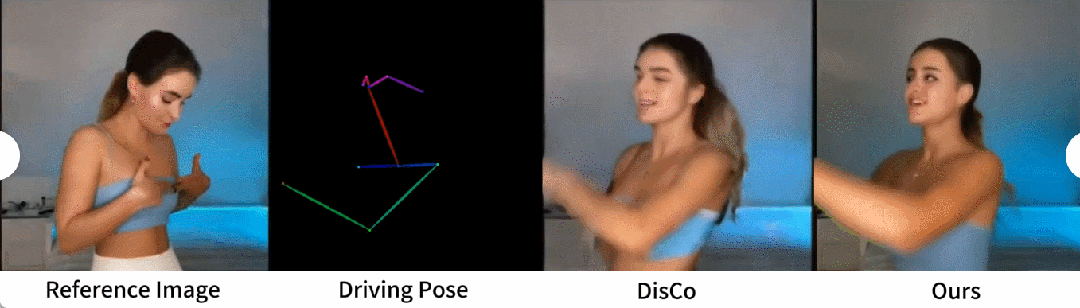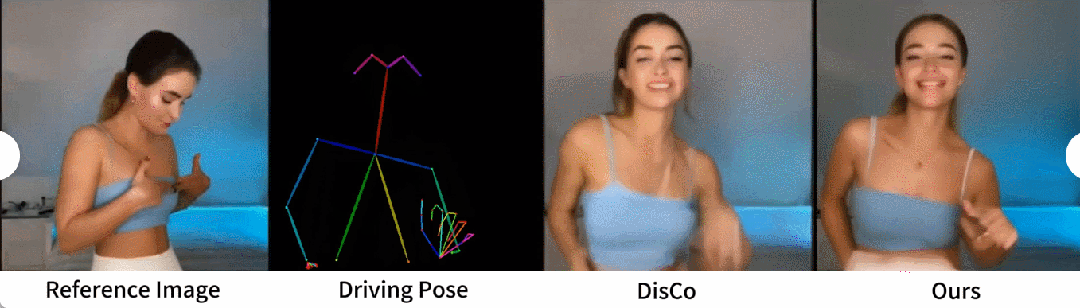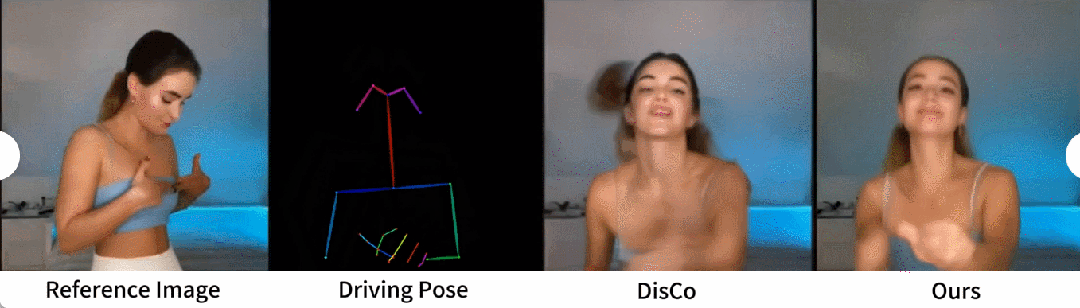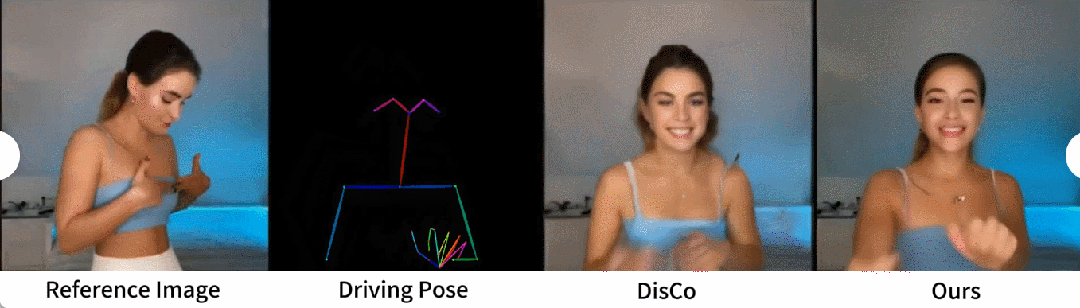
 Ein qualitativer Vergleich mit DisCo ist in Abbildung 5 dargestellt. Angesichts der Komplexität der Szene erfordert der Ansatz von DisCo den zusätzlichen Einsatz von SAM zur Generierung menschlicher Vordergrundmasken. Im Gegensatz dazu zeigt unsere Methode, dass das Modell auch ohne explizites Erlernen menschlicher Masken die Vordergrund-Hintergrund-Beziehung aus der Bewegung des Subjekts ohne vorherige menschliche Segmentierung erfassen kann. Darüber hinaus zeichnet sich das Modell in komplexen Tanzsequenzen durch die Wahrung der visuellen Kontinuität während der gesamten Handlung aus und zeigt eine größere Robustheit im Umgang mit unterschiedlichen Charakterauftritten.
Ein qualitativer Vergleich mit DisCo ist in Abbildung 5 dargestellt. Angesichts der Komplexität der Szene erfordert der Ansatz von DisCo den zusätzlichen Einsatz von SAM zur Generierung menschlicher Vordergrundmasken. Im Gegensatz dazu zeigt unsere Methode, dass das Modell auch ohne explizites Erlernen menschlicher Masken die Vordergrund-Hintergrund-Beziehung aus der Bewegung des Subjekts ohne vorherige menschliche Segmentierung erfassen kann. Darüber hinaus zeichnet sich das Modell in komplexen Tanzsequenzen durch die Wahrung der visuellen Kontinuität während der gesamten Handlung aus und zeigt eine größere Robustheit im Umgang mit unterschiedlichen Charakterauftritten.
Image – Universeller Ansatz für Videos. Derzeit wurden in vielen Studien Videodiffusionsmodelle mit starker Generierungsfähigkeit basierend auf umfangreichen Trainingsdaten vorgeschlagen. Für den Vergleich wählten die Forscher zwei der bekanntesten und effektivsten Bild-Video-Methoden: AnimateDiff und Gen2. Da diese beiden Methoden keine Posenkontrolle durchführen, verglichen die Forscher nur ihre Fähigkeit, die Wiedergabetreue des Referenzbildes beizubehalten. Wie in Abbildung 6 dargestellt, stehen aktuelle Bild-zu-Video-Ansätze vor der Herausforderung, eine große Anzahl von Charakteraktionen zu generieren, und es fällt ihnen schwer, die langfristige Konsistenz des Erscheinungsbilds in allen Videos aufrechtzuerhalten, wodurch eine wirksame Unterstützung einer konsistenten Charakteranimation behindert wird.

Weitere Informationen finden Sie im Originalpapier
Das obige ist der detaillierte Inhalt von„Thema Drei', das weltweite Aufmerksamkeit erregt: Messi, Iron Man und zweidimensionale Damen kommen problemlos damit zurecht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Protokolle umfasst das SSL-Protokoll?
Welche Protokolle umfasst das SSL-Protokoll?
 Tutorial zur Cloud-Server-Nutzung
Tutorial zur Cloud-Server-Nutzung
 js-String in Array umwandeln
js-String in Array umwandeln
 So ersetzen Sie alle PPT-Hintergründe
So ersetzen Sie alle PPT-Hintergründe
 Wie funktioniert ein Schalter?
Wie funktioniert ein Schalter?
 So laden Sie den Razer-Maustreiber herunter
So laden Sie den Razer-Maustreiber herunter
 So öffnen Sie eine ISO-Datei
So öffnen Sie eine ISO-Datei
 Welche Bildbearbeitungssoftware gibt es?
Welche Bildbearbeitungssoftware gibt es?
 Empfohlene Lernreihenfolge für C++ und Python
Empfohlene Lernreihenfolge für C++ und Python








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



