
 Technologie-Peripheriegeräte
KI
Machen Sie eine Reise in die Zukunft, das erste Multi-View-Vorhersage- und Planungsmodell für autonomes Fahren ist da
Technologie-Peripheriegeräte
KI
Machen Sie eine Reise in die Zukunft, das erste Multi-View-Vorhersage- und Planungsmodell für autonomes Fahren ist da
Machen Sie eine Reise in die Zukunft, das erste Multi-View-Vorhersage- und Planungsmodell für autonomes Fahren ist da

In letzter Zeit hat das Konzept des Weltmodells eine Welle der Begeisterung ausgelöst, doch der Bereich des autonomen Fahrens kann dem „Feuer“ nicht aus der Ferne zusehen. Ein Team des Instituts für Automatisierung der Chinesischen Akademie der Wissenschaften schlug erstmals ein neues Multi-View-Weltmodell namens Drive-WM vor, das darauf abzielt, die Sicherheit einer durchgängigen autonomen Fahrplanung zu verbessern.

Website: https://drive-wm.github.io
Papier-URL: https://arxiv.org/abs/2311.17918
Die erste Multi-View-Vorhersage und -Planung Autonomous Driving World Model
Auf dem CVPR2023 Autonomous Driving Seminar stellten die beiden großen Technologiegiganten Tesla und Wayve ihre schwarze Technologie vor und ein neues Konzept namens „Generative World Model“ wurde im Bereich des autonomen Fahrens populär. Wayve hat sogar das generative KI-Modell GAIA-1 veröffentlicht und damit seine beeindruckenden Fähigkeiten zur Videoszenengenerierung demonstriert. Kürzlich haben Forscher des Instituts für Automatisierung der Chinesischen Akademie der Wissenschaften auch ein neues Weltmodell für autonomes Fahren vorgeschlagen – Drive-WM, das erstmals ein prädiktives Weltmodell mit mehreren Ansichten realisiert und sich nahtlos in das aktuelle Mainstream-End integriert Durchgängiger Planer für autonomes Fahren.
Drive-WM nutzt die leistungsstarken Generierungsfunktionen des Diffusionsmodells, um realistische Videoszenen zu generieren.
Stellen Sie sich vor, Sie fahren und Ihr Bordsystem prognostiziert zukünftige Entwicklungen basierend auf Ihren Fahrgewohnheiten und Straßenverhältnissen und generiert entsprechendes visuelles Feedback, um Sie bei der Auswahl der Flugrouten zu unterstützen. Diese Fähigkeit, die Zukunft vorherzusehen, kombiniert mit einem Planer, wird die Sicherheit des autonomen Fahrens erheblich verbessern!
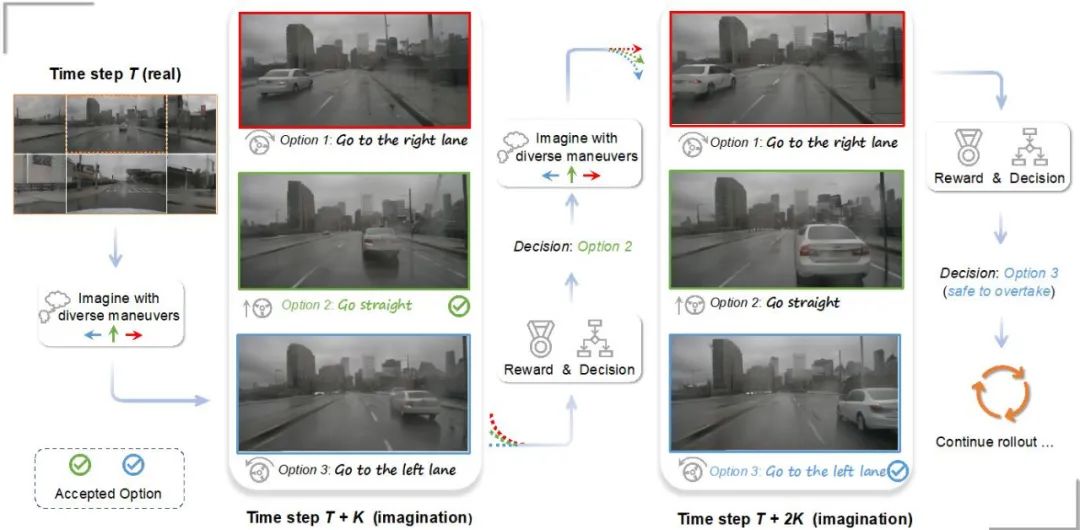
Prognose und Planung basierend auf Multi-View-Weltmodellen. Die Kombination aus Weltmodell und End-to-End-Autonomem Fahren verbessert die Fahrsicherheit -Ende des autonomen Fahrens. In jedem Zeitschritt kann der Planer mithilfe des Weltmodells mögliche Zukunftsszenarien vorhersagen und diese dann mithilfe der Bildbelohnungsfunktion vollständig bewerten.

Mit der besten Schätzmethode und der erweiterten Planungsbaumtechnologie kann eine effektivere und sicherere Planung erreicht werden

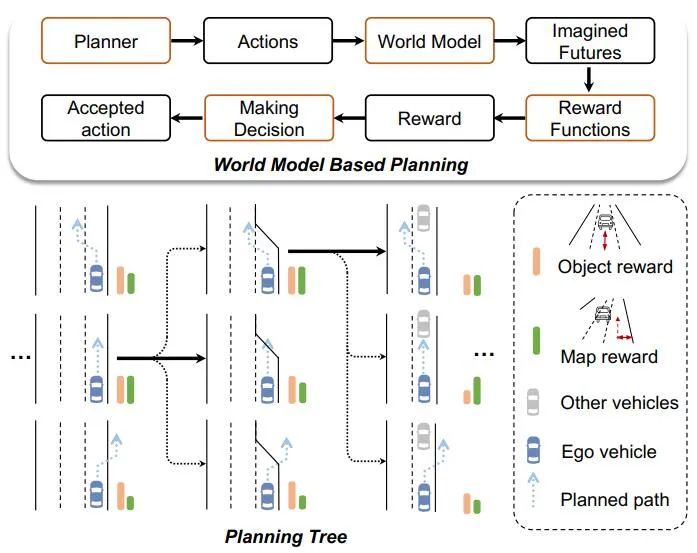
Drive-WM untersucht zwei Anwendungen von Weltmodellen in der End-to-End-Planung durch innovative Forschung.
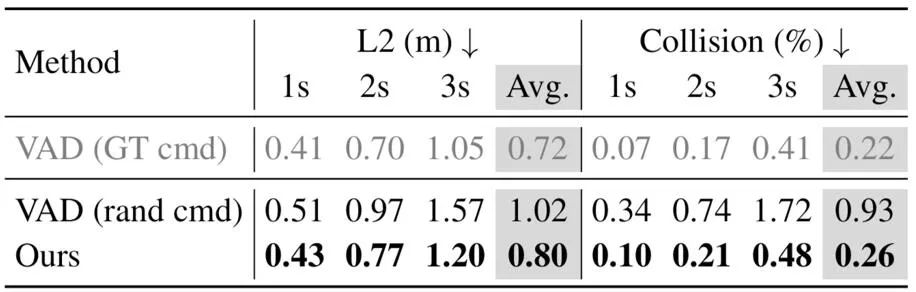
1 Demonstriert die Robustheit von Weltmodellen bei der Bewältigung von OOD-Szenarien. Durch Vergleichsexperimente stellte der Autor fest, dass die Leistung des aktuellen End-to-End-Planers in OOD-Situationen nicht ideal ist.
Der Autor gibt das folgende Bild ab. Wenn ein leichter seitlicher Versatz zur Ausgangsposition gestört wird, hat der aktuelle End-to-End-Planer Schwierigkeiten, eine vernünftig geplante Route auszugeben.

Der End-to-End-Planer hat Schwierigkeiten, in OOD-Situationen vernünftige Planungsrouten auszugeben.
Die leistungsstarke Generierungsfähigkeit von Drive-WM liefert neue Ideen zur Lösung von OOD-Problemen. Der Autor verwendet die generierten Videos, um den Planer zu optimieren und aus den OOD-Daten zu lernen, damit der Planer bei der Bewältigung solcher Szenarien eine bessere Leistung erzielen kann.
2 Dies zeigt, dass die Einführung einer zukünftigen Szenariobewertung sehr wichtig ist End-to-End Der Verbesserungseffekt der Planung
So erstellen Sie ein Multi-View-Videogenerierungsmodell
Die räumlich-zeitliche Konsistenz der Multiview-Videogenerierung war schon immer ein herausforderndes Problem. Drive-WM erweitert die Möglichkeiten der Videogenerierung durch die Einführung einer sequentiellen Layer-Codierung und erreicht die Generierung von Multiview-Videos durch View-Decomposition-Modellierung. Diese Generierungsmethode der Ansichtszerlegung kann die Konsistenz zwischen Ansichten erheblich verbessern.
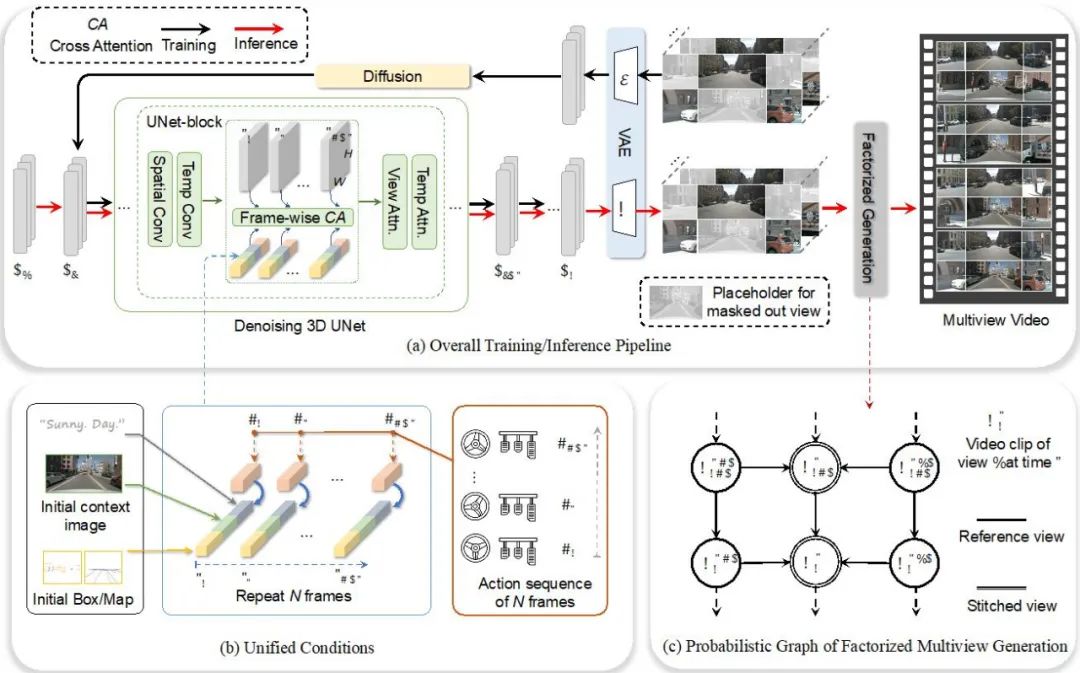
Drive-WM-Gesamtmodelldesign Multi-View-Videoerzeugung mit hervorragender Steuerbarkeit. Es bietet eine Vielzahl von Steuerungsoptionen zur Steuerung der Erstellung von Multi-View-Videos durch Text, Szenenlayout und Bewegungsinformationen. Es bietet auch neue Möglichkeiten für zukünftige neuronale Simulatoren, wie z. B. die Verwendung von Text zum Ändern von Wetter und Beleuchtung:

Zum Beispiel Fußgängergenerierung und Vordergrundbearbeitung:


Verwenden Sie Methoden zur Geschwindigkeits- und Richtungssteuerung: 

Erzeugen Sie seltene Ereignisse, z. B. das Wenden an einer Kreuzung oder das Einfahren in seitliches Gras

Fazit
Drive-WM demonstriert nicht nur seine leistungsstarken Multi-View-Videogenerierungsfunktionen, sondern zeigt auch das große Potenzial der Kombination von Weltmodellen mit End-to-End-Fahrmodellen auf. Wir glauben, dass Weltmodelle in Zukunft dazu beitragen können, ein sichereres, stabileres und zuverlässigeres durchgängiges autonomes Fahrsystem zu schaffen.
Das obige ist der detaillierte Inhalt vonMachen Sie eine Reise in die Zukunft, das erste Multi-View-Vorhersage- und Planungsmodell für autonomes Fahren ist da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
