

Das Ausführen großer generativer KI-Modelle wie Stable Diffusion auf Mobiltelefonen und anderen mobilen Geräten ist zu einem Hotspot in der Branche geworden, bei dem die Generierungsgeschwindigkeit das Haupthindernis darstellt.
Kürzlich wurde in einem Artikel von Google „MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices“ die schnellste Text-to-Image-Generierung auf Mobilgeräten vorgeschlagen, die auf dem iPhone 15 Pro nur 0,2 Sekunden dauert. Das Papier stammt vom selben Team wie UFOGen. Während es ein ultrakleines Diffusionsmodell erstellt, übernimmt es auch die derzeit beliebte Diffusions-GAN-Technologieroute zur Sampling-Beschleunigung.

Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/abs/2311.16567
Das Folgende ist das von MobileDiffusion in einem Schritt generierte Ergebnis.

Wie wird MobileDiffusion optimiert?
Lassen Sie uns zunächst mit dem Problem beginnen und untersuchen, warum eine Optimierung notwendig ist
Die derzeit beliebteste Technologie zur Text-zu-Bild-Generierung basiert auf dem Diffusionsmodell. Aufgrund der starken grundlegenden Bilderzeugungsfähigkeiten und Robustheit des vorab trainierten Modells bei nachgelagerten Feinabstimmungsaufgaben haben wir die hervorragende Leistung von Diffusionsmodellen in Bereichen wie Bildbearbeitung, steuerbare Generierung, personalisierte Generierung und Videogenerierung gesehen
Als Basismodell sind jedoch auch seine Mängel offensichtlich, die vor allem zwei Aspekte betreffen: Erstens führt die große Anzahl von Parametern des Diffusionsmodells zu einer langsamen Berechnungsgeschwindigkeit, insbesondere wenn die Ressourcen begrenzt sind, und zweitens erfordert das Diffusionsmodell viele Parameter. Die Stichprobenerhebung erfordert mehrere Schritte, was zusätzlich zu einer langsamen Schlussfolgerung führt. Am Beispiel des mit Spannung erwarteten Stable Diffusion 1.5 (SD) enthält sein Basismodell fast 1 Milliarde Parameter. Wir haben das Modell quantisiert und die Inferenz auf dem iPhone 15 Pro durchgeführt, was fast 80 Sekunden dauerte. Solche teuren Ressourcenanforderungen und eine langsame Benutzererfahrung schränken die Anwendungsszenarien auf dem mobilen Endgerät erheblich ein
Um die oben genannten Probleme zu lösen, optimiert MobileDiffusion Punkt-zu-Punkt. (1) Als Reaktion auf das Problem der großen Modellgröße haben wir hauptsächlich viele Experimente und Optimierungen an der Kernkomponente UNet durchgeführt, einschließlich der Platzierung rechenintensiver Faltungsvereinfachungs- und Aufmerksamkeitsoperationen auf niedrigeren Schichten sowie der gezielten Betriebsoptimierung mobiler Geräte, z Aktivierungsfunktionen usw. (2) Als Reaktion auf das Problem, dass Diffusionsmodelle eine mehrstufige Probenahme erfordern, erforscht und praktiziert MobileDiffusion einstufige Inferenztechnologien wie progressive Destillation und das aktuell hochmoderne UFOGen.
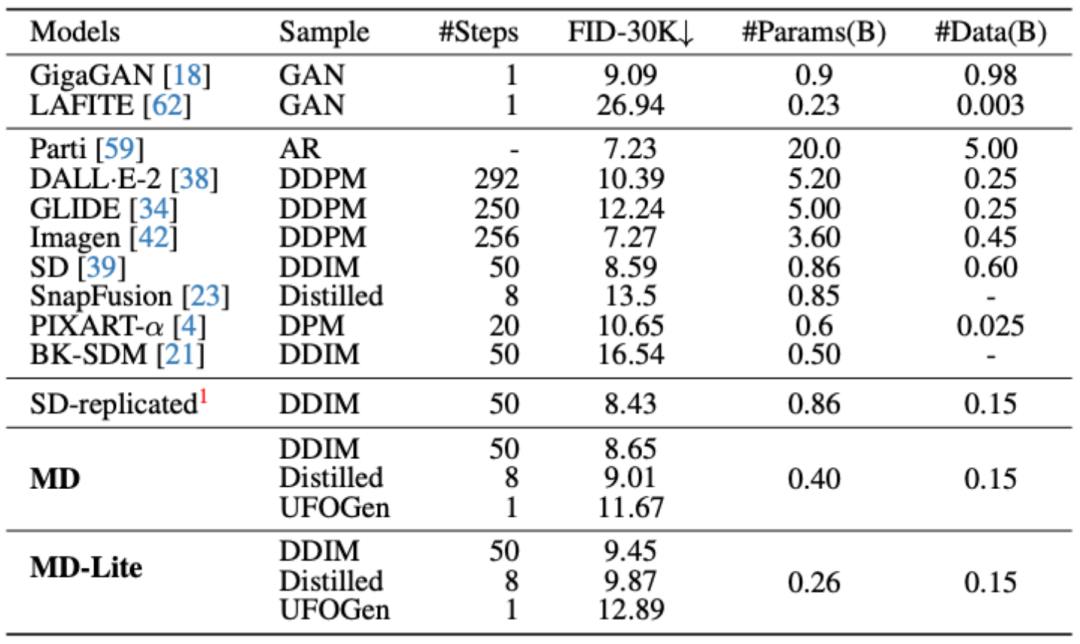
MobileDiffusion ist auf Basis des derzeit beliebtesten SD 1.5 UNet in der Open-Source-Community optimiert. Nach jedem Optimierungsvorgang wird gleichzeitig der Leistungsverlust im Vergleich zum ursprünglichen UNet-Modell gemessen. Die Messindikatoren umfassen zwei häufig verwendete Metriken: FID und CLIP.
Gesamtplanung
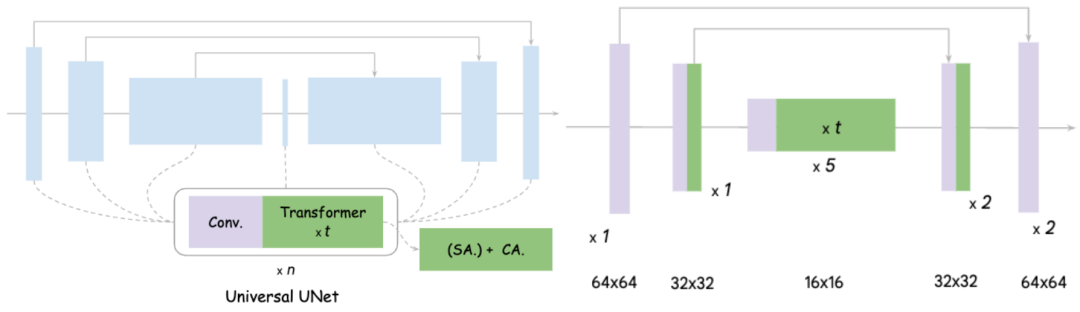
Auf der linken Seite des Bildes ist das Designdiagramm des ursprünglichen UNet zu sehen. Es ist im Wesentlichen zu erkennen, dass es Faltung und Transformer enthält und Transformer selbst- enthält. Aufmerksamkeits-Force-Mechanismus und Cross-Attention-Mechanismus
Die Kernideen von MobileDiffusion für die UNet-Optimierung sind in zwei Punkte unterteilt: 1) Optimierung der Faltung Wie wir alle wissen, ist die Faltung im hochauflösenden Funktionsraum sehr zeitaufwändig Die Anzahl der Parameter ist groß, hier bezieht es sich auf die vollständige Faltung 2) Verbesserung der Aufmerksamkeitseffizienz. Wie bei der Faltung ist auch bei hoher Aufmerksamkeit die Berechnung der Länge des gesamten Merkmalsraums erforderlich. Die Komplexität der Selbstaufmerksamkeit hängt direkt von der abgeflachten Länge des Merkmalsraums ab, und die Kreuzaufmerksamkeit ist ebenfalls proportional zur Länge des Raums.
Experimente haben gezeigt, dass das Verschieben aller 16 Transformer von UNet auf die innere Schicht mit der niedrigsten Feature-Auflösung und das Entfernen einer Faltung in jeder Schicht keine offensichtlichen Auswirkungen auf die Leistung hat. Der erzielte Effekt ist: MobileDiffusion reduziert die ursprünglichen 22 Faltungen und 16 Transformer auf nur 11 Faltungen und etwa 12 Transformer, und diese Aufmerksamkeit wird alle auf Feature-Maps mit niedriger Auflösung durchgeführt. Dadurch wird die Effizienz erheblich verbessert, was zu einer Effizienzsteigerung von 40 % und einer Parameterscherung von 40 % führt. Das endgültige Modell ist rechts abgebildet. Das Folgende ist ein Vergleich mit anderen Modellen:

Der Inhalt, der neu geschrieben werden muss, ist: Mikrodesign
Hier werden nur einige neuartige Designs vorgestellt, die interessierte Leser lesen können Haupttext, wird detaillierter vorgestellt.
Entkopplung von Selbstaufmerksamkeit und Kreuzaufmerksamkeit
Transformer im traditionellen UNet enthält sowohl Selbstaufmerksamkeit als auch Kreuzaufmerksamkeit. MobileDiffusion platziert die gesamte Selbstaufmerksamkeit auf der Feature-Map mit der niedrigsten Auflösung, behält jedoch eine Queraufmerksamkeit bei In der mittleren Schicht wurde festgestellt, dass dieses Design nicht nur die Recheneffizienz verbessert, sondern auch die Qualität von Modellzeichnungen gewährleistet Die Funktion ist sehr schwierig. Es ist schwierig, eine Parallelverarbeitung durchzuführen, und die Effizienz ist gering. MobileDiffusion schlägt eine neue Methode vor, bei der die Softmax-Funktion direkt an die Relu-Funktion angepasst (feinabgestimmt) wird, da die Relu-Funktion für die Aktivierung jedes Datenpunkts effizienter ist. Überraschenderweise verbesserten sich die Metriken des Modells mit nur etwa 10.000 Feinabstimmungsschritten und die Qualität der generierten Bilder blieb erhalten. Daher liegen die Vorteile der Relu-Funktion im Vergleich zur Softmax-Funktion auf der Hand. Diese Technologie hat sich durch Arbeiten wie MobileNet als äußerst effektiv erwiesen, insbesondere auf der mobilen Seite, wird jedoch in generativen Modellen im Allgemeinen selten verwendet. MobileDiffusion-Experimente ergaben, dass die trennbare Faltung die Parameter sehr effektiv reduziert, insbesondere wenn sie in der innersten Schicht von UNet platziert wird. Die Analyse beweist, dass es keinen Verlust an Modellqualität gibt.
Probenoptimierung
Zu den derzeit beliebtesten Methoden zur Probenoptimierung gehören die progressive Destillation und UFOGen, mit denen 8 Schritte bzw. 1 Schritt erreicht werden können. Um zu beweisen, dass diese Stichprobenmethoden auch nach einer extremen Vereinfachung des Modells noch wirksam sind, führte MobileDiffusion eine experimentelle Verifizierung dieser beiden Methoden durchDie optimierte Stichprobenziehung wurde mit dem Basismodell verglichen, und es ist ersichtlich, dass die 8 Schritte nach der Stichprobenoptimierung und 1-Schritt-Modellindikatoren wurden erheblich verbessert Geschwindigkeit aktuell Das Plotten dauert nur 0,2 Sekunden!
Downstream-Task-Test
MobileDiffusion untersuchte Downstream-Aufgaben, einschließlich ControlNet/Plugin und LoRA Finetune. Wie aus der folgenden Abbildung ersichtlich ist, behält MobileDiffusion nach der Modell- und Stichprobenoptimierung weiterhin hervorragende Modell-Feinabstimmungsfunktionen bei.
Zusammenfassung
Das obige ist der detaillierte Inhalt vonBilder können auf Mobiltelefonen in 0,2 Sekunden gerendert werden. Google entwickelt das schnellste mobile Verbreitungsmodell MobileDiffusion. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



