
 Technologie-Peripheriegeräte
KI
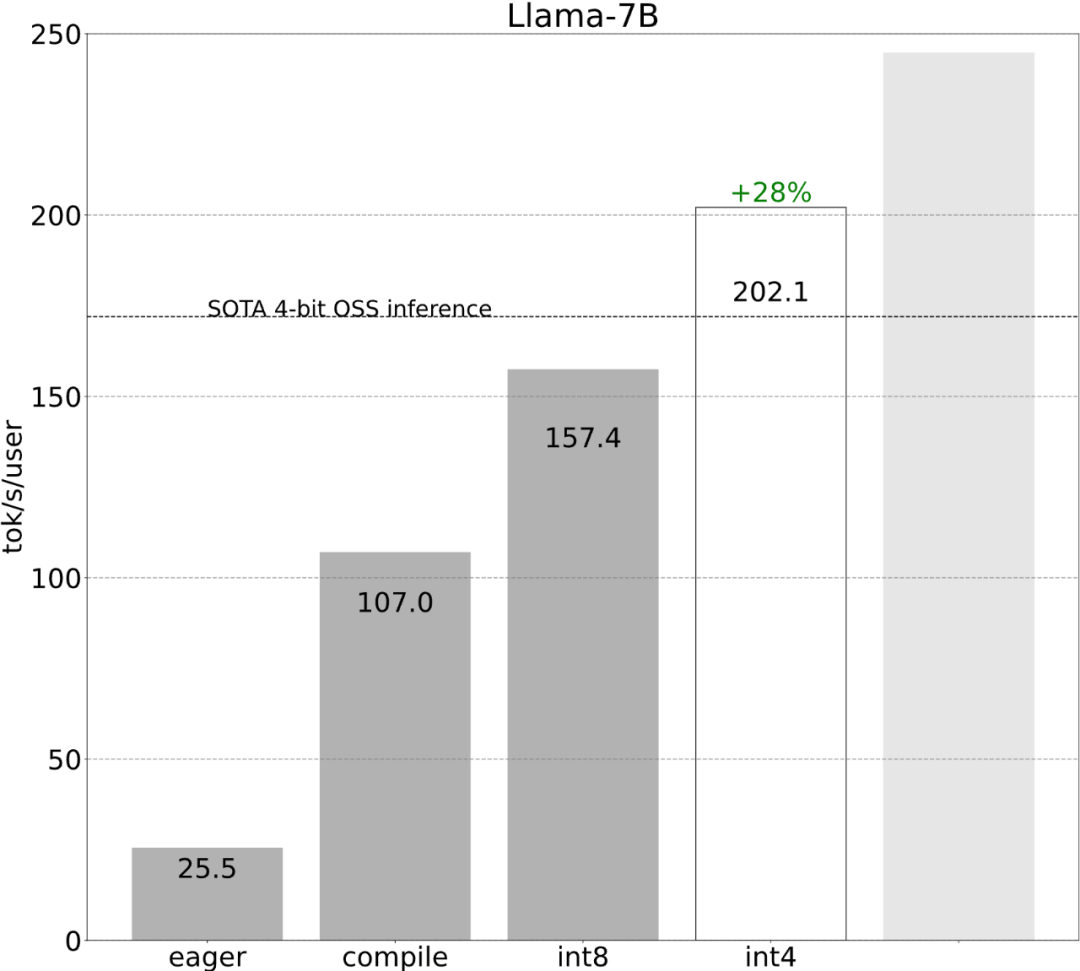
Mit weniger als 1.000 Codezeilen hat das PyTorch-Team Llama 7B zehnmal schneller gemacht
Technologie-Peripheriegeräte
KI
Mit weniger als 1.000 Codezeilen hat das PyTorch-Team Llama 7B zehnmal schneller gemacht
Mit weniger als 1.000 Codezeilen hat das PyTorch-Team Llama 7B zehnmal schneller gemacht

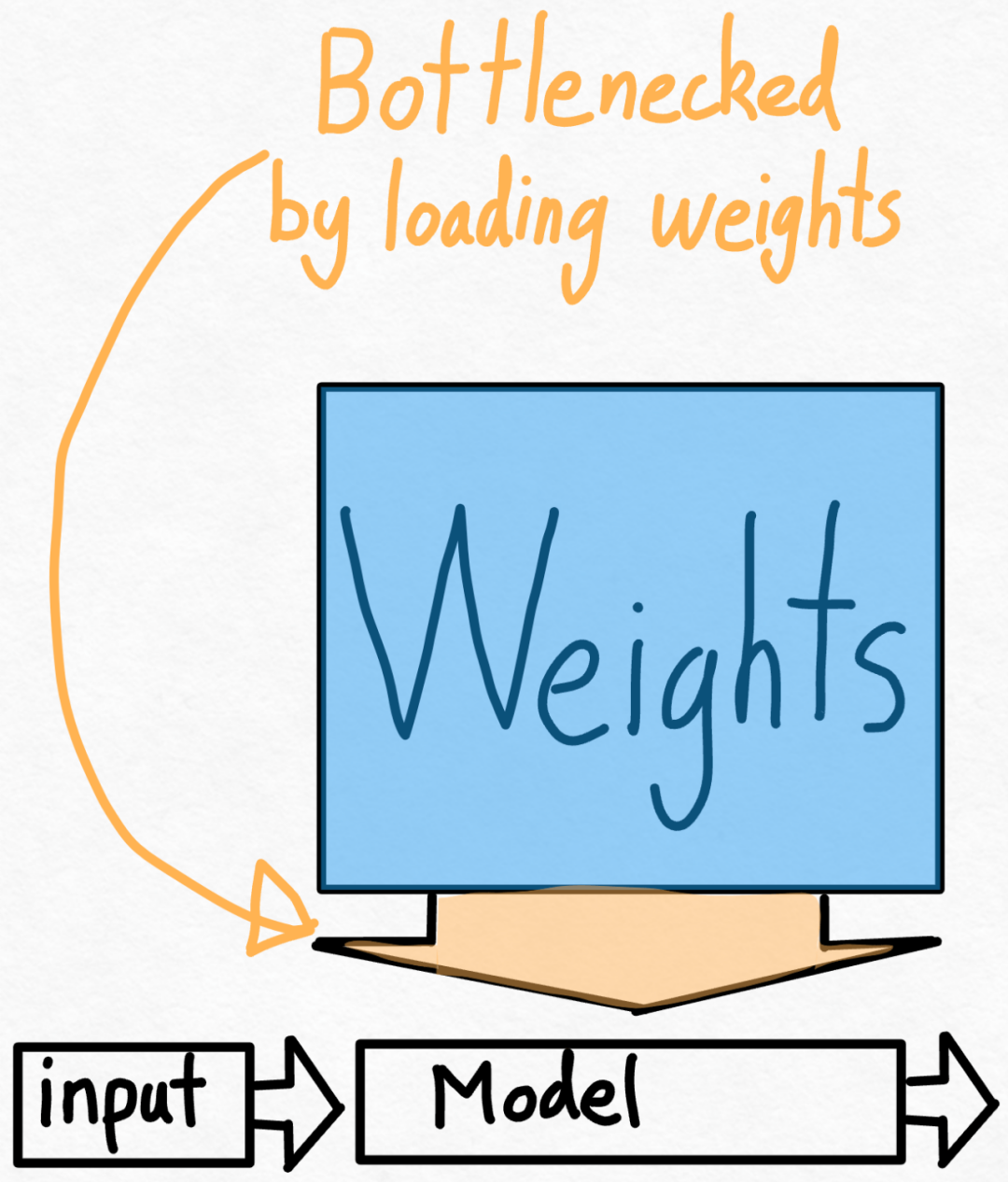
Das PyTorch-Team bringt Ihnen persönlich bei, wie Sie die Inferenz großer Modelle beschleunigen können.

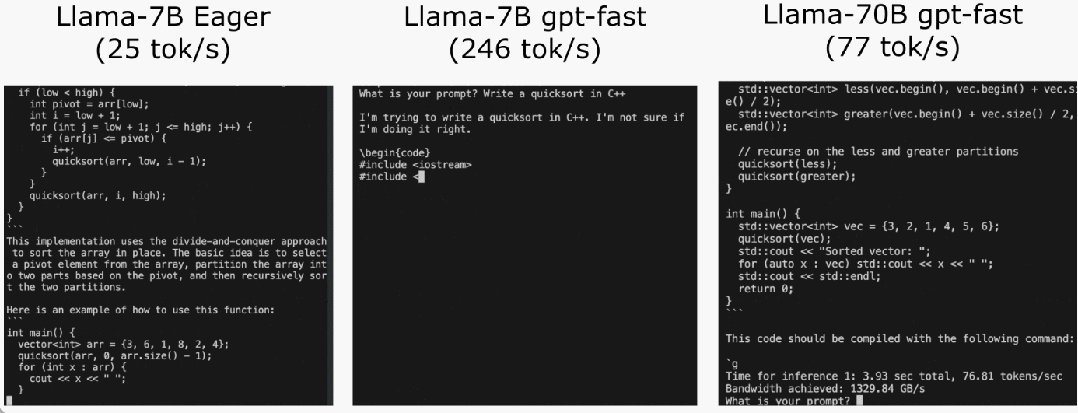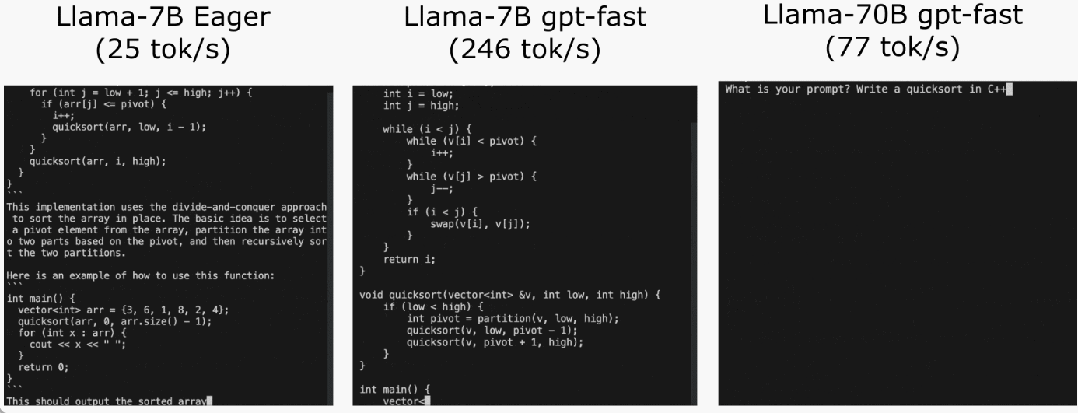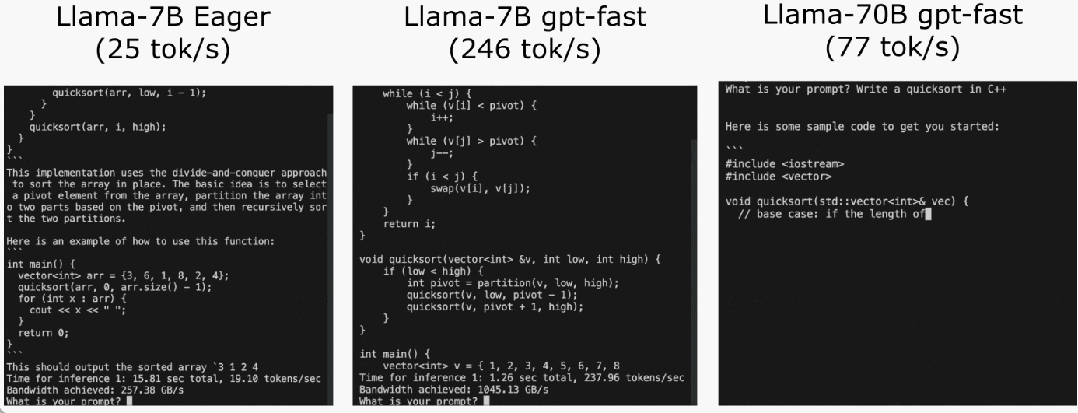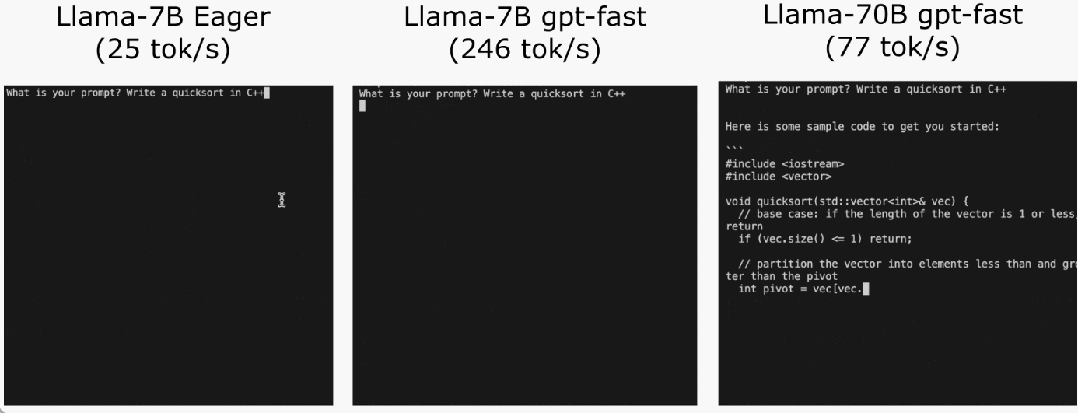
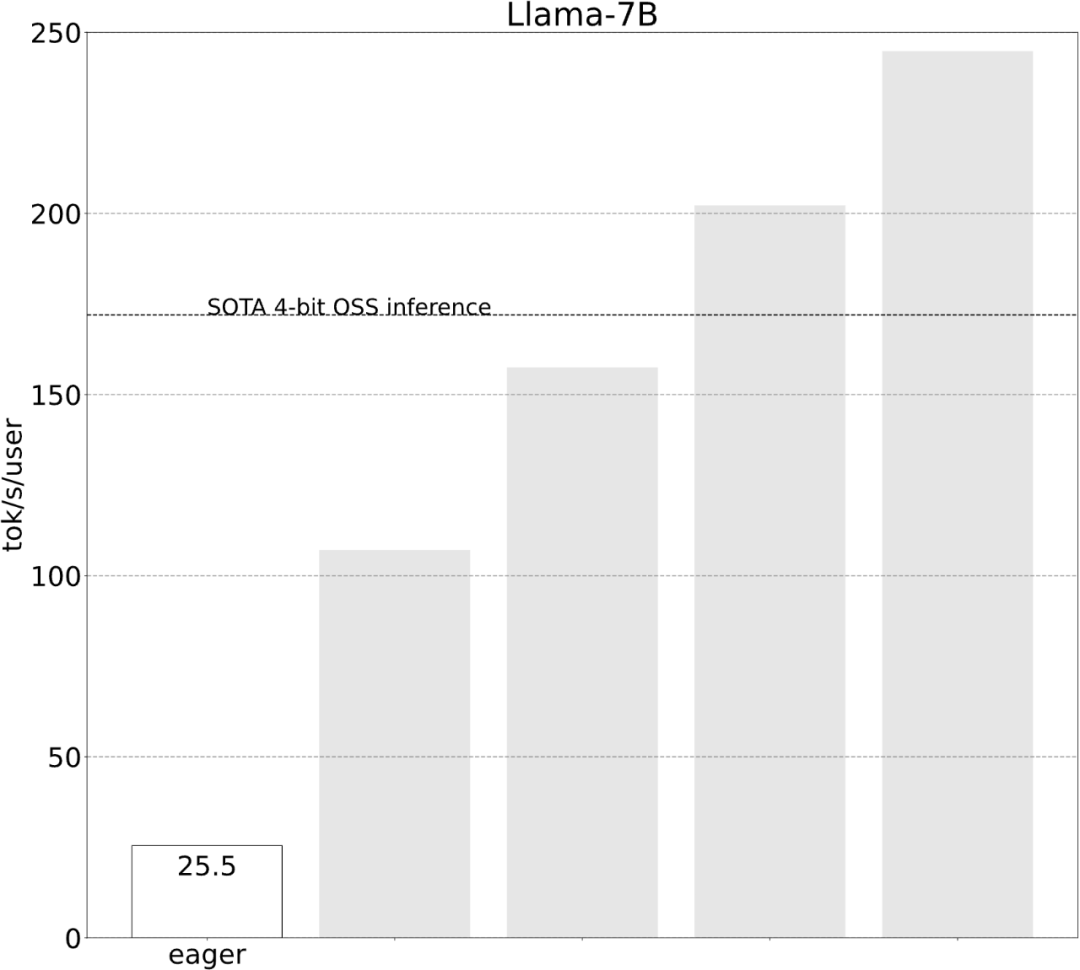
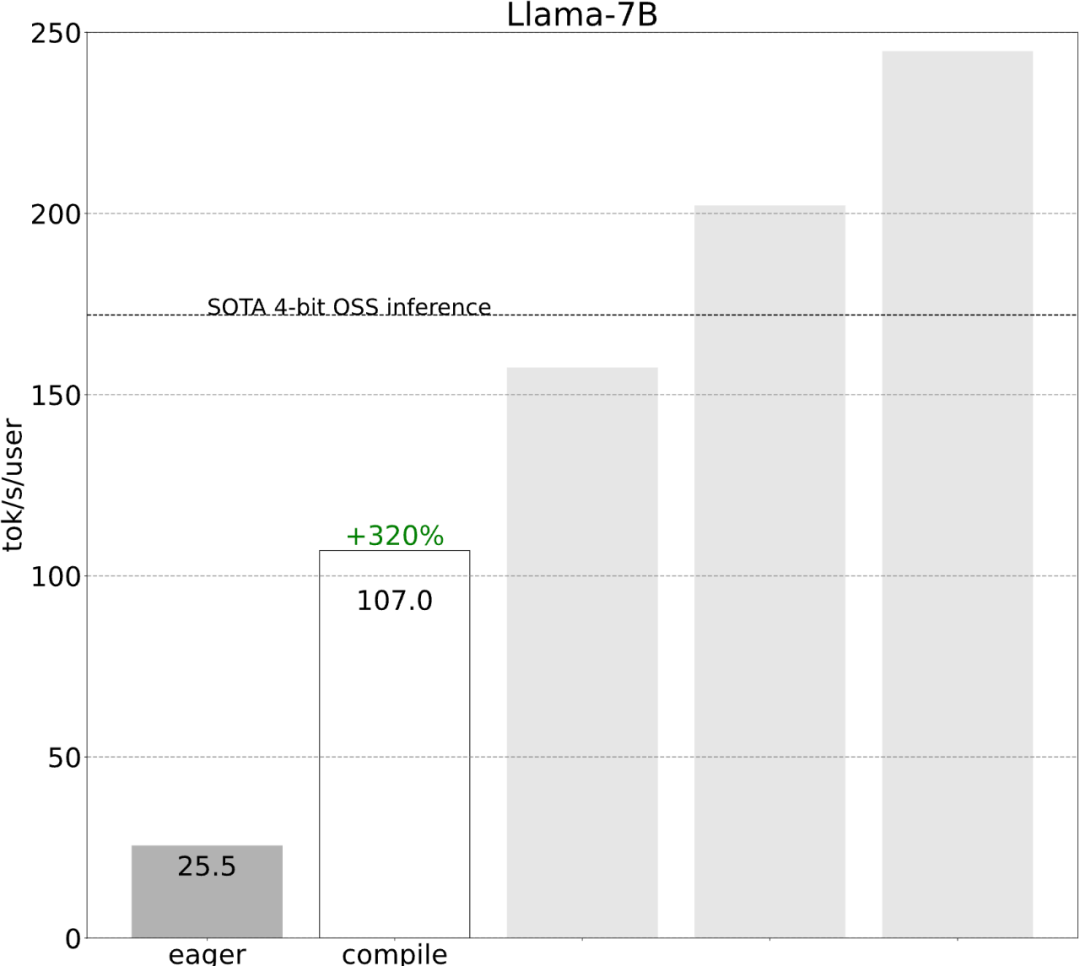
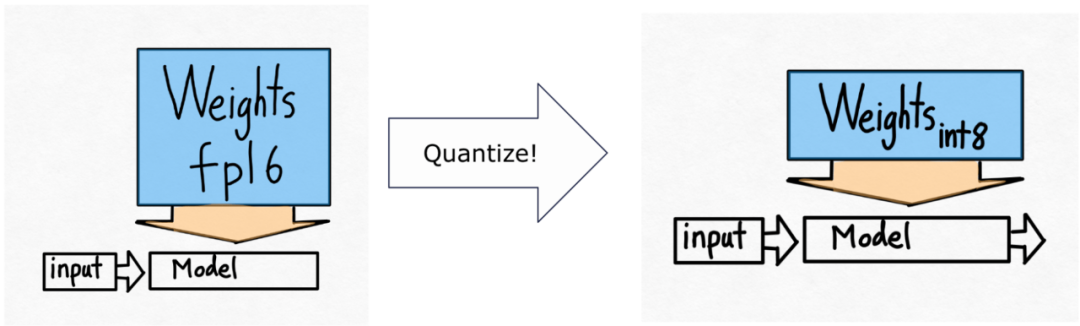
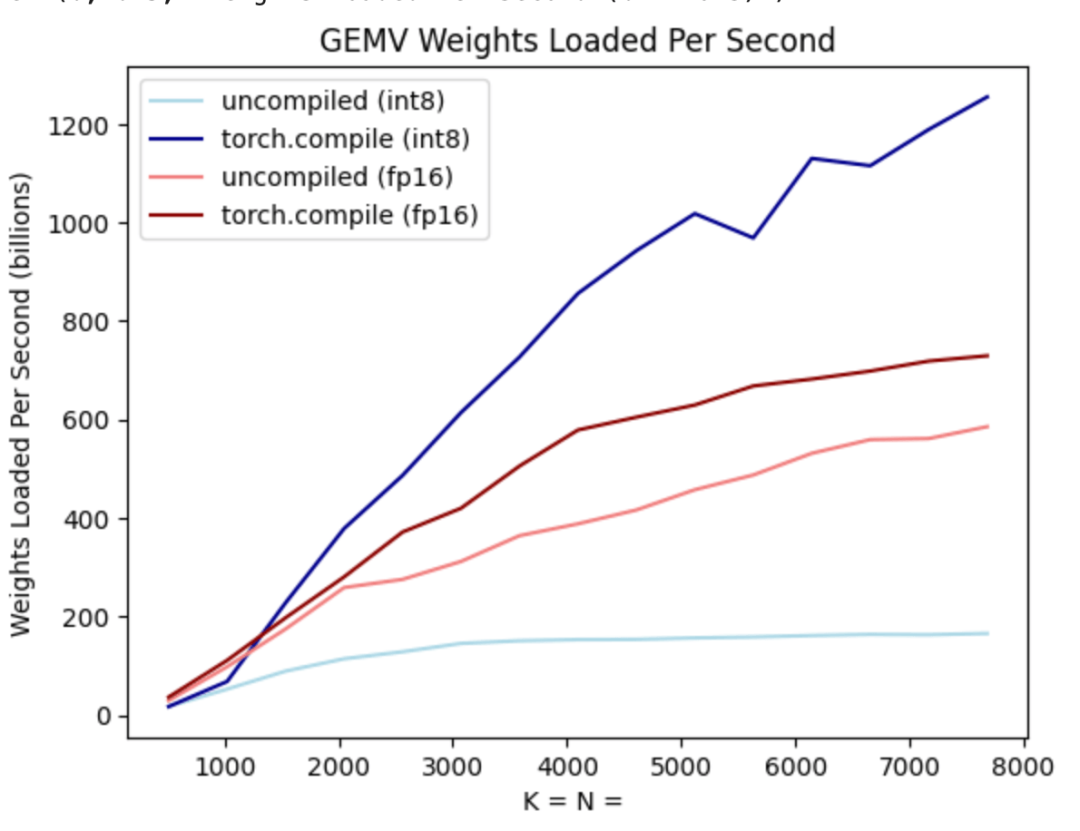
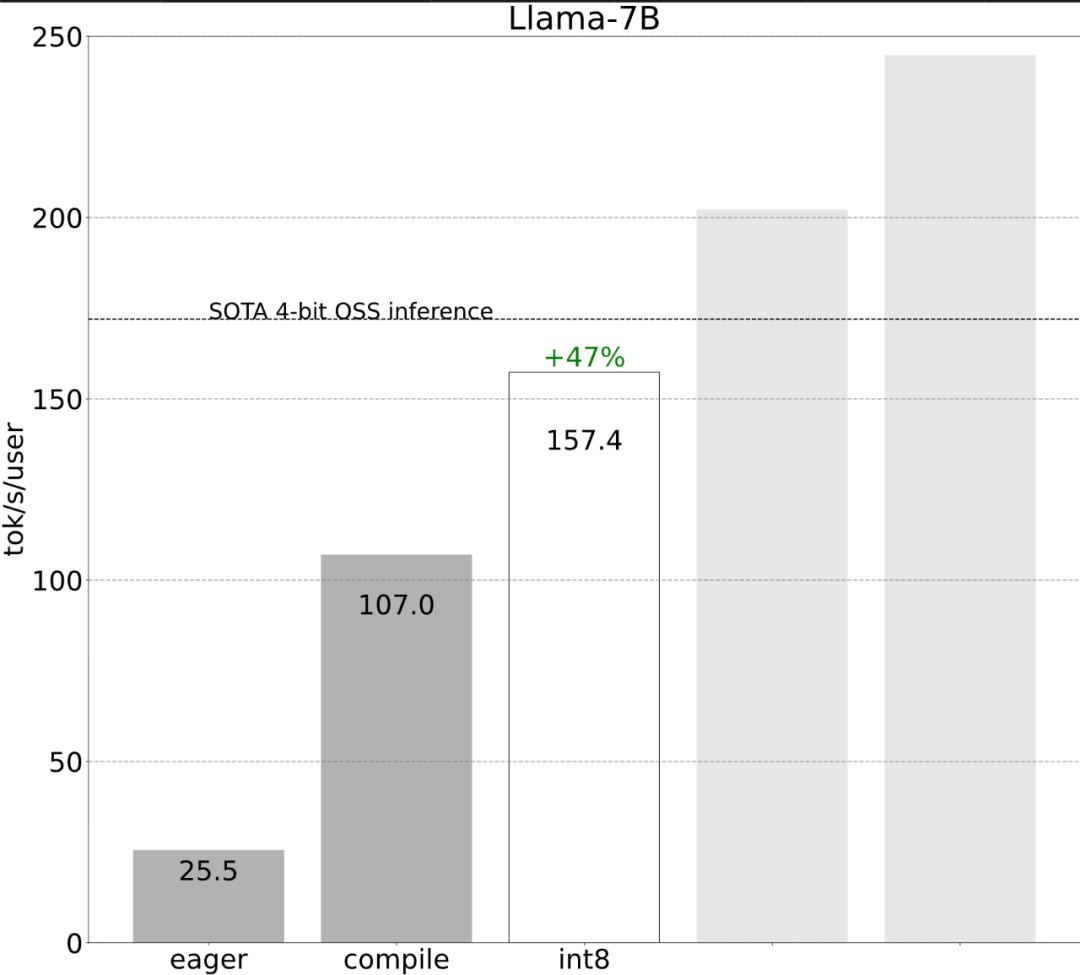
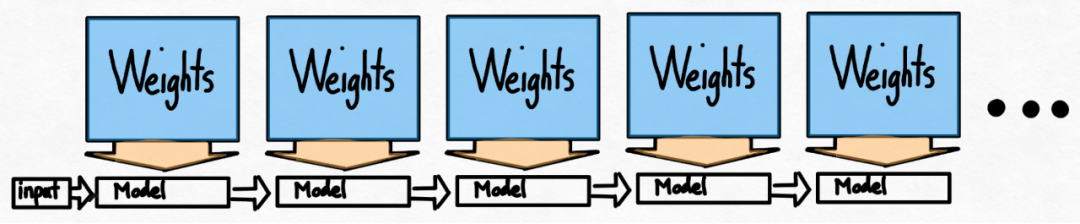
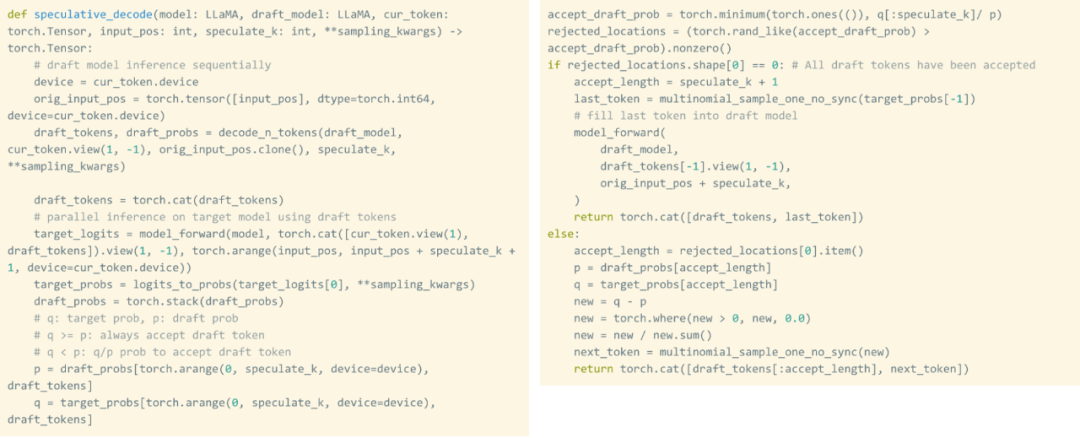
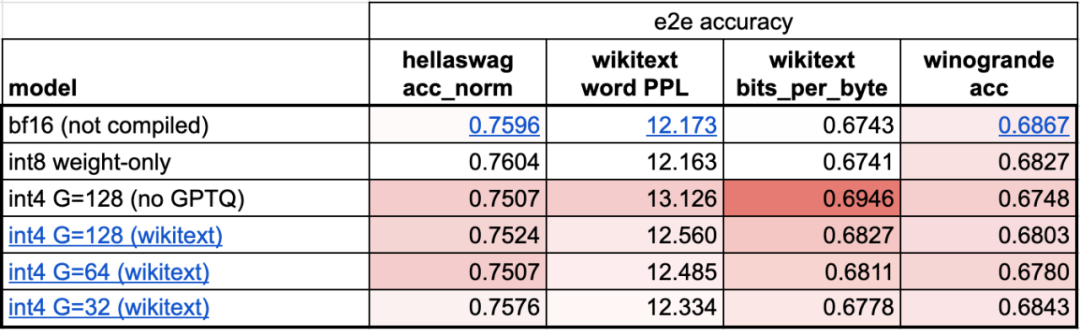
Torch.compile: PyTorch-Modell-Compiler. PyTorch 2.0 fügt eine neue Funktion namens Torch.compile () hinzu, mit der vorhandene Modelle mit einer Codezeile beschleunigt werden können das Modell; GPU-Quantisierung: Beschleunigen Sie das Modell durch Reduzierung der Rechengenauigkeit; Spekulative Dekodierung: eine große Modellinferenzbeschleunigungsmethode, die ein kleines „Entwurfs“-Modell verwendet, um große „Ziele“ vorherzusagen ; Tensor Parallel: Beschleunigen Sie die Modellinferenz, indem Sie das Modell auf mehreren Geräten ausführen.





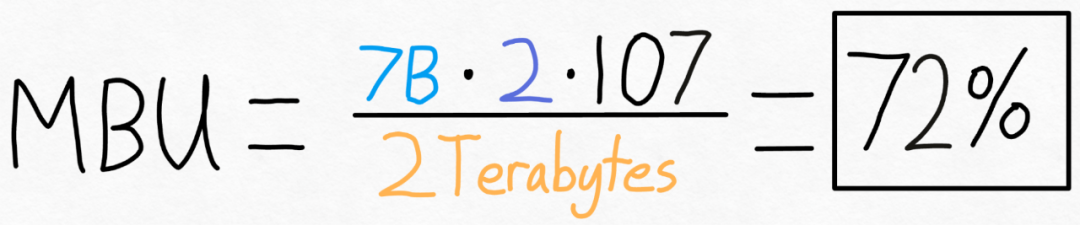


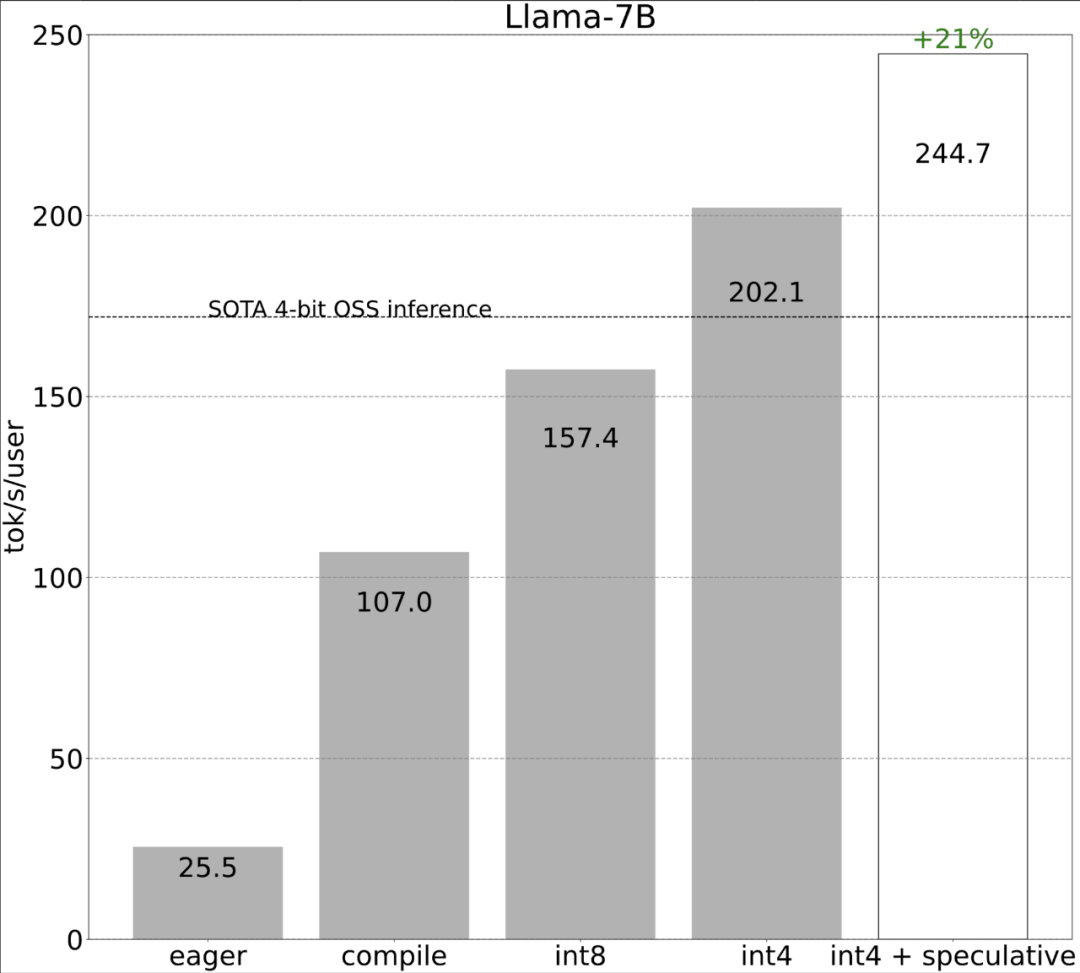

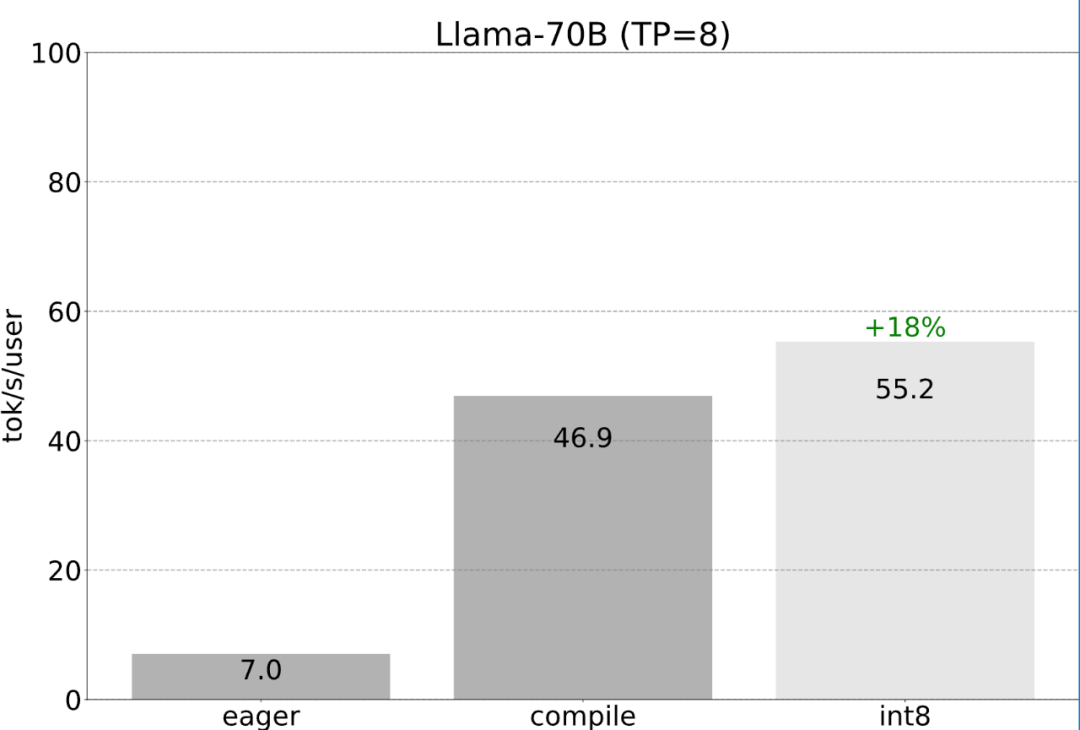
Das obige ist der detaillierte Inhalt vonMit weniger als 1.000 Codezeilen hat das PyTorch-Team Llama 7B zehnmal schneller gemacht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion kann nicht nur besser imitieren, sondern auch „erschaffen“. Das Diffusionsmodell (DiffusionModel) ist ein Bilderzeugungsmodell. Im Vergleich zu bekannten Algorithmen wie GAN und VAE im Bereich der KI verfolgt das Diffusionsmodell einen anderen Ansatz. Seine Hauptidee besteht darin, dem Bild zunächst Rauschen hinzuzufügen und es dann schrittweise zu entrauschen. Das Entrauschen und Wiederherstellen des Originalbilds ist der Kernbestandteil des Algorithmus. Der endgültige Algorithmus ist in der Lage, aus einem zufälligen verrauschten Bild ein Bild zu erzeugen. In den letzten Jahren hat das phänomenale Wachstum der generativen KI viele spannende Anwendungen in der Text-zu-Bild-Generierung, Videogenerierung und mehr ermöglicht. Das Grundprinzip dieser generativen Werkzeuge ist das Konzept der Diffusion, ein spezieller Sampling-Mechanismus, der die Einschränkungen bisheriger Methoden überwindet.
 Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Kimi: In nur einem Satz, in nur zehn Sekunden ist ein PPT fertig. PPT ist so nervig! Um ein Meeting abzuhalten, benötigen Sie einen PPT; um einen wöchentlichen Bericht zu schreiben, müssen Sie einen PPT vorlegen, auch wenn Sie jemanden des Betrugs beschuldigen PPT. Das College ähnelt eher dem Studium eines PPT-Hauptfachs. Man schaut sich PPT im Unterricht an und macht PPT nach dem Unterricht. Als Dennis Austin vor 37 Jahren PPT erfand, hatte er vielleicht nicht damit gerechnet, dass PPT eines Tages so weit verbreitet sein würde. Wenn wir über unsere harte Erfahrung bei der Erstellung von PPT sprechen, treiben uns Tränen in die Augen. „Es dauerte drei Monate, ein PPT mit mehr als 20 Seiten zu erstellen, und ich habe es Dutzende Male überarbeitet. Als ich das PPT sah, musste ich mich übergeben.“ war PPT.“ Wenn Sie ein spontanes Meeting haben, sollten Sie es tun
 Die perfekte Kombination aus PyCharm und PyTorch: detaillierte Installations- und Konfigurationsschritte
Feb 21, 2024 pm 12:00 PM
Die perfekte Kombination aus PyCharm und PyTorch: detaillierte Installations- und Konfigurationsschritte
Feb 21, 2024 pm 12:00 PM
PyCharm ist eine leistungsstarke integrierte Entwicklungsumgebung (IDE) und PyTorch ist ein beliebtes Open-Source-Framework im Bereich Deep Learning. Im Bereich maschinelles Lernen und Deep Learning kann die Verwendung von PyCharm und PyTorch für die Entwicklung die Entwicklungseffizienz und Codequalität erheblich verbessern. In diesem Artikel wird detailliert beschrieben, wie PyTorch in PyCharm installiert und konfiguriert wird, und es werden spezifische Codebeispiele angehängt, um den Lesern zu helfen, die leistungsstarken Funktionen dieser beiden besser zu nutzen. Schritt 1: Installieren Sie PyCharm und Python
 Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Bei Aufgaben zur Generierung natürlicher Sprache ist die Stichprobenmethode eine Technik, um eine Textausgabe aus einem generativen Modell zu erhalten. In diesem Artikel werden fünf gängige Methoden erläutert und mit PyTorch implementiert. 1. GreedyDecoding Bei der Greedy-Decodierung sagt das generative Modell die Wörter der Ausgabesequenz basierend auf der Eingabesequenz Zeit Schritt für Zeit voraus. In jedem Zeitschritt berechnet das Modell die bedingte Wahrscheinlichkeitsverteilung jedes Wortes und wählt dann das Wort mit der höchsten bedingten Wahrscheinlichkeit als Ausgabe des aktuellen Zeitschritts aus. Dieses Wort wird zur Eingabe für den nächsten Zeitschritt und der Generierungsprozess wird fortgesetzt, bis eine Abschlussbedingung erfüllt ist, beispielsweise eine Sequenz mit einer bestimmten Länge oder eine spezielle Endmarkierung. Das Merkmal von GreedyDecoding besteht darin, dass die aktuelle bedingte Wahrscheinlichkeit jedes Mal die beste ist
 Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Als leistungsstarkes Deep-Learning-Framework wird PyTorch häufig in verschiedenen maschinellen Lernprojekten eingesetzt. Als leistungsstarke integrierte Python-Entwicklungsumgebung kann PyCharm auch bei der Umsetzung von Deep-Learning-Aufgaben eine gute Unterstützung bieten. In diesem Artikel wird die Installation von PyTorch in PyCharm ausführlich vorgestellt und spezifische Codebeispiele bereitgestellt, um den Lesern den schnellen Einstieg in die Verwendung von PyTorch für Deep-Learning-Aufgaben zu erleichtern. Schritt 1: Installieren Sie PyCharm. Zuerst müssen wir sicherstellen, dass wir es haben
 Alle CVPR 2024-Auszeichnungen bekannt gegeben! Fast 10.000 Menschen nahmen offline an der Konferenz teil und ein chinesischer Forscher von Google gewann den Preis für den besten Beitrag
Jun 20, 2024 pm 05:43 PM
Alle CVPR 2024-Auszeichnungen bekannt gegeben! Fast 10.000 Menschen nahmen offline an der Konferenz teil und ein chinesischer Forscher von Google gewann den Preis für den besten Beitrag
Jun 20, 2024 pm 05:43 PM
Am frühen Morgen des 20. Juni (Pekinger Zeit) gab CVPR2024, die wichtigste internationale Computer-Vision-Konferenz in Seattle, offiziell die besten Beiträge und andere Auszeichnungen bekannt. In diesem Jahr wurden insgesamt 10 Arbeiten ausgezeichnet, darunter zwei beste Arbeiten und zwei beste studentische Arbeiten. Darüber hinaus gab es zwei Nominierungen für die beste Arbeit und vier Nominierungen für die beste studentische Arbeit. Die Top-Konferenz im Bereich Computer Vision (CV) ist die CVPR, die jedes Jahr zahlreiche Forschungseinrichtungen und Universitäten anzieht. Laut Statistik wurden in diesem Jahr insgesamt 11.532 Arbeiten eingereicht, von denen 2.719 angenommen wurden, was einer Annahmequote von 23,6 % entspricht. Laut der statistischen Analyse der CVPR2024-Daten des Georgia Institute of Technology befassen sich die meisten Arbeiten aus Sicht der Forschungsthemen mit der Bild- und Videosynthese und -generierung (Imageandvideosyn
 Fünf Programmiersoftware für den Einstieg in das Erlernen der C-Sprache
Feb 19, 2024 pm 04:51 PM
Fünf Programmiersoftware für den Einstieg in das Erlernen der C-Sprache
Feb 19, 2024 pm 04:51 PM
Als weit verbreitete Programmiersprache ist die C-Sprache eine der grundlegenden Sprachen, die für diejenigen erlernt werden müssen, die sich mit Computerprogrammierung befassen möchten. Für Anfänger kann das Erlernen einer neuen Programmiersprache jedoch etwas schwierig sein, insbesondere aufgrund des Mangels an entsprechenden Lernwerkzeugen und Lehrmaterialien. In diesem Artikel werde ich fünf Programmiersoftware vorstellen, die Anfängern den Einstieg in die C-Sprache erleichtert und Ihnen einen schnellen Einstieg ermöglicht. Die erste Programmiersoftware war Code::Blocks. Code::Blocks ist eine kostenlose integrierte Open-Source-Entwicklungsumgebung (IDE) für
 Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Wir wissen, dass LLM auf großen Computerclustern unter Verwendung umfangreicher Daten trainiert wird. Auf dieser Website wurden viele Methoden und Technologien vorgestellt, die den LLM-Trainingsprozess unterstützen und verbessern. Was wir heute teilen möchten, ist ein Artikel, der tief in die zugrunde liegende Technologie eintaucht und vorstellt, wie man einen Haufen „Bare-Metals“ ohne Betriebssystem in einen Computercluster für das LLM-Training verwandelt. Dieser Artikel stammt von Imbue, einem KI-Startup, das allgemeine Intelligenz durch das Verständnis der Denkweise von Maschinen erreichen möchte. Natürlich ist es kein einfacher Prozess, einen Haufen „Bare Metal“ ohne Betriebssystem in einen Computercluster für das Training von LLM zu verwandeln, aber Imbue hat schließlich erfolgreich ein LLM mit 70 Milliarden Parametern trainiert der Prozess akkumuliert
