

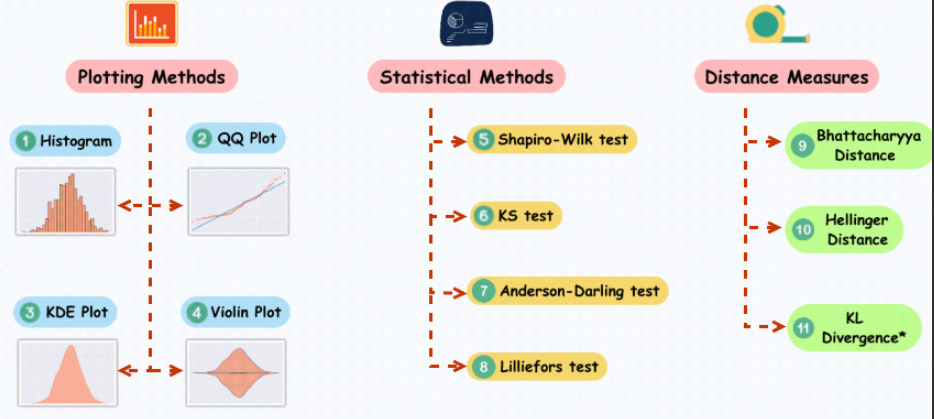
Im Bereich der Datenwissenschaft und des maschinellen Lernens gehen viele Modelle davon aus, dass die Daten normalverteilt sind oder dass die Daten bei einer Normalverteilung besser abschneiden. Beispielsweise geht die lineare Regression davon aus, dass die Residuen normalverteilt sind, und die lineare Diskriminanzanalyse (LDA) wird auf der Grundlage von Annahmen wie der Normalverteilung abgeleitet. Daher ist es für Datenwissenschaftler und Praktiker des maschinellen Lernens von entscheidender Bedeutung zu verstehen, wie die Normalität von Daten getestet werden kann wie man geeignete Analysemethoden anwendet. Dies kann die Auswirkungen der Datenverteilung auf die Modellleistung besser bewältigen und den Prozess des maschinellen Lernens und der Datenmodellierung komfortabler gestalten Die Verteilung entspricht einer Normalverteilung. Im QQ-Diagramm werden die Quantile der Daten mit den Quantilen der Standardnormalverteilung verglichen. Wenn die Datenverteilung nahe an der Normalverteilung liegt, liegen die Punkte im QQ-Diagramm nahe an einer geraden Linie QQ-Diagramm: Der Beispielcode generiert einen Satz Zufallsdaten, die einer Normalverteilung folgen. Nachdem Sie den Code ausgeführt haben, können Sie das QQ-Diagramm zusammen mit der entsprechenden Normalverteilungskurve sehen. Indem Sie die Verteilung der Punkte im Diagramm beobachten, können Sie zunächst beurteilen, ob die Daten einer Normalverteilung nahe kommen.

 3. Violin-Diagramm
3. Violin-Diagramm
Statistische Methoden
5. Shapiro-Wilk-Test
Der Shapiro-Wilk-Test ist eine statistische Methode zum Testen, ob die Daten der Normalverteilung entsprechen, auch bekannt als W-Test. Bei der Durchführung des Shapiro-Wilk-Tests konzentrieren wir uns normalerweise auf zwei Hauptindikatoren: 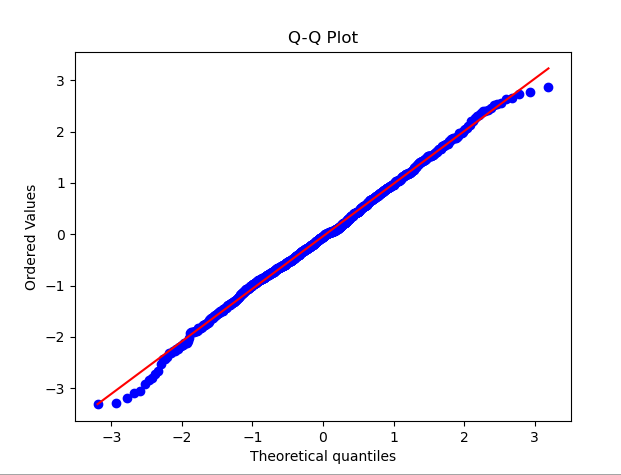
P-Wert: Der P-Wert gibt die Wahrscheinlichkeit der Beobachtung dieser Korrelation an. Wenn der P-Wert größer als das Signifikanzniveau (normalerweise 0,05) ist, deutet dies darauf hin, dass die beobachteten Daten wahrscheinlich aus einer Normalverteilung stammen.
Wenn die Statistik W nahe bei 1 liegt und der P-Wert größer als 0,05 ist, können wir daraus schließen, dass die beobachteten Daten die Normalverteilung erfüllen. Im folgenden Code wird zunächst ein Satz zufälliger Daten generiert, die der Normalverteilung entsprechen, und dann wird der Shapiro-Wilk-Test durchgeführt, um die Teststatistik und den P-Wert zu erhalten. Anhand des Vergleichs zwischen dem P-Wert und dem Signifikanzniveau können Sie feststellen, ob die Stichprobendaten aus einer Normalverteilung stammen.
Im folgenden Code wird zunächst ein Satz zufälliger Daten generiert, die der Normalverteilung entsprechen, und dann wird der Shapiro-Wilk-Test durchgeführt, um die Teststatistik und den P-Wert zu erhalten. Anhand des Vergleichs zwischen dem P-Wert und dem Signifikanzniveau können Sie feststellen, ob die Stichprobendaten aus einer Normalverteilung stammen.
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Shapiro-Wilk检验stat, p = stats.shapiro(data)print('Shapiro-Wilk Statistic:', stat)print('P-value:', p)# 根据P值判断正态性alpha = 0.05if p > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
KS检验(Kolmogorov-Smirnov检验)是一种用于检验数据是否符合特定分布(例如正态分布)的统计方法。它通过计算观测数据与理论分布的累积分布函数(CDF)之间的最大差异来评估它们是否来自同一分布。其基本步骤如下:
Python中使用KS检验来检验数据是否符合正态分布时,可以使用Scipy库中的kstest函数。下面是一个简单的示例,演示了如何使用Python进行KS检验来检验数据是否符合正态分布。
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行KS检验statistic, p_value = stats.kstest(data, 'norm')print('KS Statistic:', statistic)print('P-value:', p_value)# 根据P值判断正态性alpha = 0.05if p_value > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
Anderson-Darling检验是一种用于检验数据是否来自特定分布(例如正态分布)的统计方法。它特别强调观察值在分布尾部的差异,因此在检测极端值的偏差方面非常有效
下面的代码使用stats.anderson函数执行Anderson-Darling检验,并获取检验统计量、临界值以及显著性水平。然后通过比较统计量和临界值,可以判断样本数据是否符合正态分布
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Anderson-Darling检验result = stats.anderson(data, dist='norm')print('Anderson-Darling Statistic:', result.statistic)print('Critical Values:', result.critical_values)print('Significance Level:', result.significance_level)# 判断正态性if result.statistic <p style="text-align:center;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/170255826239547.png" class="lazy" alt="11 grundlegende Methoden zur Bestimmung der Normalität von Datenverteilungen"></p><h4>8.Lilliefors检验</h4><p>Lilliefors检验(也被称为Kolmogorov-Smirnov-Lilliefors检验)是一种用于检验数据是否符合正态分布的统计检验方法。它是Kolmogorov-Smirnov检验的一种变体,专门用于小样本情况。与K-S检验不同,Lilliefors检验不需要假定数据的分布类型,而是基于观测数据来评估是否符合正态分布</p><p>在下面的例子中,我们使用lilliefors函数进行Lilliefors检验,并获得了检验统计量和P值。通过将P值与显著性水平进行比较,我们可以判断样本数据是否符合正态分布</p><pre class="brush:php;toolbar:false">import numpy as npfrom statsmodels.stats.diagnostic import lilliefors# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Lilliefors检验statistic, p_value = lilliefors(data)print('Lilliefors Statistic:', statistic)print('P-value:', p_value)# 根据P值判断正态性alpha = 0.05if p_value > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
距离测量(Distance measures)是一种有效的测试数据正态性的方法,它提供了更直观的方式来比较观察数据分布与参考分布之间的差异。
下面是一些常见的距离测量方法及其在测试正态性时的应用:
(1) "巴氏距离(Bhattacharyya distance)"的定义是:
(2) 「海林格距离(Hellinger distance)」:
(3) "KL 散度(KL Divergence)":
运用这些距离测量方法,我们能够比对观测到的分布与多个参考分布之间的差异,进而更好地评估数据的正态性。通过找出与观察到的分布距离最短的参考分布,我们可以更精确地判断数据是否符合正态分布
Das obige ist der detaillierte Inhalt von11 grundlegende Methoden zur Bestimmung der Normalität von Datenverteilungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So verwenden Sie die Konvertierungsfunktion „Konvertieren'.
So verwenden Sie die Konvertierungsfunktion „Konvertieren'.
 Was tun, wenn die temporäre Dateiumbenennung fehlschlägt?
Was tun, wenn die temporäre Dateiumbenennung fehlschlägt?
 Welche Karte ist eine TF-Karte?
Welche Karte ist eine TF-Karte?
 BigDecimal-Methode zum Vergleichen von Größen
BigDecimal-Methode zum Vergleichen von Größen
 Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
Was tun, wenn das eingebettete Bild nicht vollständig angezeigt wird?
 So konfigurieren Sie die Pfadumgebungsvariable in Java
So konfigurieren Sie die Pfadumgebungsvariable in Java
 Lösung dafür, dass Java-Code nicht ausgeführt wird
Lösung dafür, dass Java-Code nicht ausgeführt wird
 Verwendung von Oracle-Einsätzen
Verwendung von Oracle-Einsätzen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



