
 Technologie-Peripheriegeräte
KI
11 Grundverteilungen, die Datenwissenschaftler in 95 % der Fälle verwenden
Technologie-Peripheriegeräte
KI
11 Grundverteilungen, die Datenwissenschaftler in 95 % der Fälle verwenden
11 Grundverteilungen, die Datenwissenschaftler in 95 % der Fälle verwenden

Nach der letzten Bestandsaufnahme von „11 Basisdiagramme, die Datenwissenschaftler in 95 % der Fälle verwenden“ stellen wir Ihnen heute 11 Basisverteilungen vor, die Datenwissenschaftler in 95 % der Fälle verwenden. Die Beherrschung dieser Verteilungen hilft uns, die Natur der Daten besser zu verstehen und bei der Datenanalyse und Entscheidungsfindung genauere Schlussfolgerungen und Vorhersagen zu treffen.

1. Normalverteilung
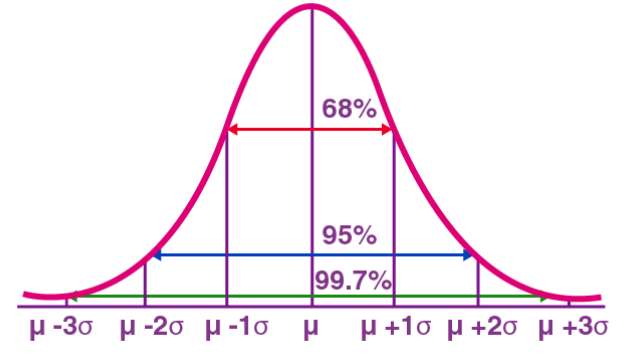
Normalverteilung, auch als Gaußsche Verteilung bekannt, ist eine kontinuierliche Wahrscheinlichkeitsverteilung. Es hat eine symmetrische glockenförmige Kurve mit dem Mittelwert (μ) als Mittelpunkt und der Standardabweichung (σ) als Breite. Die Normalverteilung hat in vielen Bereichen wie Statistik, Wahrscheinlichkeitstheorie und Ingenieurwesen einen wichtigen Anwendungswert.
Die Wahrscheinlichkeitsdichtefunktion der Normalverteilung kann ausgedrückt werden als:
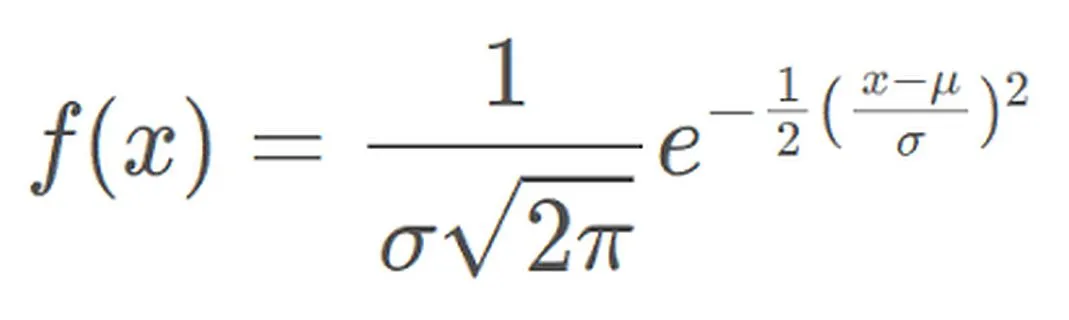
Die Wahrscheinlichkeitsdichtefunktion stellt die Wahrscheinlichkeitsdichte der Werte einer normalverteilten Zufallsvariablen im Einheitsintervall in der Nähe eines bestimmten Werts dar X. Unter diesen stellt μ den Mittelwert und σ die Standardabweichung dar. Die Normalverteilung wird in der Praxis häufig verwendet. Beispielsweise nähert sich die Verteilung der menschlichen Größe und des menschlichen Gewichts einer Normalverteilung an. Darüber hinaus sind Testergebnisse häufig normalverteilt, wobei weniger Personen hohe und niedrige Werte erzielen und mehr Personen im mittleren Bereich abschneiden. Dieses Verteilungsmodell hat in vielen Bereichen einen wichtigen Anwendungswert
2. Die Bernoulli-Verteilung (Bernoulli-Verteilung) ist eine diskrete Wahrscheinlichkeitsverteilung, die zur Beschreibung eines einzelnen Ereignisses mit nur zwei möglichen Ergebnissen verwendet wird. Bei Bernoulli-Versuchen kann es um Kopf oder Zahl, Erfolg oder Misserfolg, Ja oder Nein usw. gehen. Zum Beispiel eine Münze werfen, testen, ob ein Produkt qualifiziert ist, ob jemand ein bestimmtes Produkt kauft usw.
Die Wahrscheinlichkeitsmassenfunktion der Bernoulli-Verteilung ist:
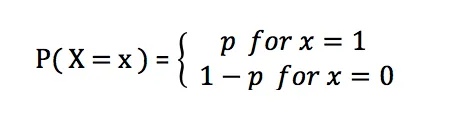 Anwendung der Bernoulli-Verteilung in der Praxis: Beispielsweise besteht die Binomialverteilung aus n unabhängigen wiederholten Experimenten der Bernoulli-Verteilung.
Anwendung der Bernoulli-Verteilung in der Praxis: Beispielsweise besteht die Binomialverteilung aus n unabhängigen wiederholten Experimenten der Bernoulli-Verteilung.
3. Binomialverteilung
Binomialverteilung (Binomialverteilung) ist eine diskrete Wahrscheinlichkeitsverteilung, die zur Beschreibung der Wahrscheinlichkeitsverteilung der Anzahl von Erfolgen in n unabhängigen wiederholten Experimenten verwendet wird. Jeder Versuch hat nur zwei mögliche Ergebnisse: Erfolg (aufgezeichnet als 1) oder Misserfolg (aufgezeichnet als 0). Die Erfolgswahrscheinlichkeit beträgt p und die Misserfolgswahrscheinlichkeit 1-p.
Die Wahrscheinlichkeitsmassenfunktion der Binomialverteilung kann ausgedrückt werden als: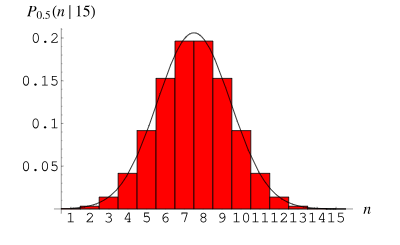
die Anzahl der Kombinationen ist, die die Auswahl angibt k aus n Versuchen Die Anzahl erfolgreicher Kombinationen. p ist die Erfolgswahrscheinlichkeit im Bereich von 0 bis 1. n ist die Anzahl der Versuche. 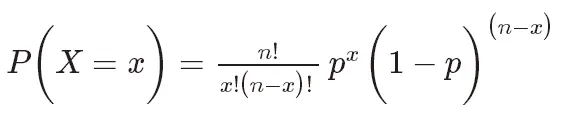
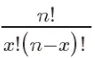
Hier stellt P(X=k) die Wahrscheinlichkeit dar, dass ein Ereignis k-mal innerhalb eines festen Zeitraums auftritt, und λ stellt die durchschnittliche Auftrittsrate eines Ereignisses dar, also die durchschnittliche Anzahl von Ereignissen, die pro Zeiteinheit auftreten. e ist eine natürliche Konstante, die ungefähr 2,718 entspricht. k stellt die Anzahl der auftretenden Ereignisse dar. In einem Callcenter kann die Anzahl der Anrufe beispielsweise als Poisson-Verteilung betrachtet werden, wobei die durchschnittliche Anzahl der Anrufe pro Minute λ
ist5. Exponentialverteilung
Exponentialverteilung (Exponentialverteilung) ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die verwendet wird, um die Wahrscheinlichkeit des Auftretens eines Ereignisses innerhalb einer festgelegten Zeit zu beschreiben. Die Exponentialverteilung eignet sich für Situationen, in denen Ereignisse unabhängig voneinander sind und mit einer konstanten Durchschnittsrate auftreten.
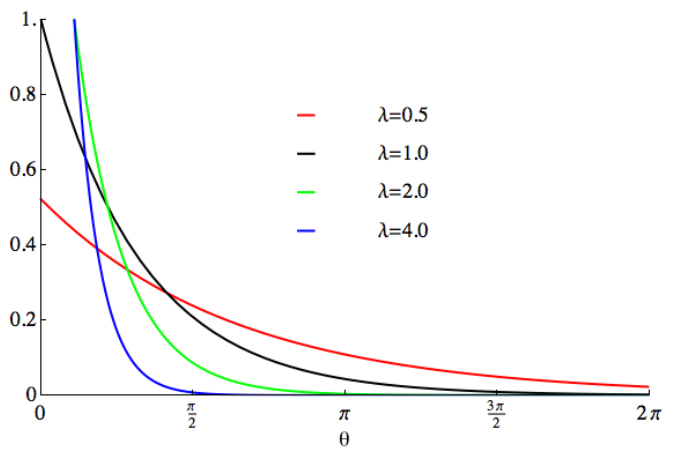 Die Wahrscheinlichkeitsdichtefunktion der Exponentialverteilung ist:
Die Wahrscheinlichkeitsdichtefunktion der Exponentialverteilung ist:
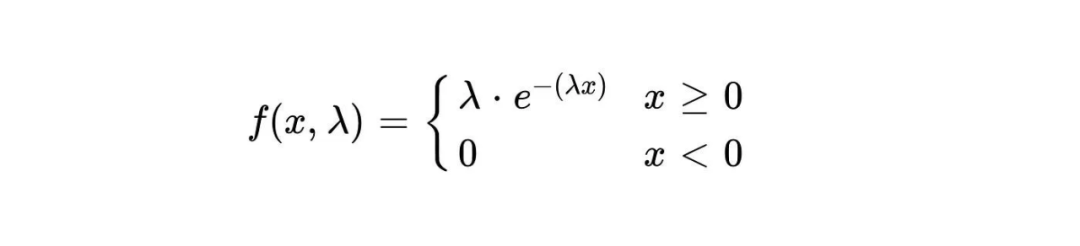 Die Wahrscheinlichkeitsdichte eines Ereignisses, das innerhalb einer bestimmten Zeit x auftritt, wird durch f(x,λ) dargestellt. λ stellt die durchschnittliche Auftrittsrate von Ereignissen dar, also die durchschnittliche Anzahl von Ereignissen, die pro Zeiteinheit auftreten. e ist eine natürliche Konstante, die ungefähr 2,718 entspricht. Die Exponentialverteilung hat im wirklichen Leben viele Anwendungen. Beispielsweise können beim radioaktiven Zerfall die Zerfallszeiten radioaktiver Kerne als exponentiell verteilt angesehen werden. Dies bedeutet, dass die Wahrscheinlichkeitsverteilung der Abklingzeiten einer Exponentialfunktion folgt. Die durchschnittliche Abklingzeit entspricht dem Parameter λ der Exponentialfunktion
Die Wahrscheinlichkeitsdichte eines Ereignisses, das innerhalb einer bestimmten Zeit x auftritt, wird durch f(x,λ) dargestellt. λ stellt die durchschnittliche Auftrittsrate von Ereignissen dar, also die durchschnittliche Anzahl von Ereignissen, die pro Zeiteinheit auftreten. e ist eine natürliche Konstante, die ungefähr 2,718 entspricht. Die Exponentialverteilung hat im wirklichen Leben viele Anwendungen. Beispielsweise können beim radioaktiven Zerfall die Zerfallszeiten radioaktiver Kerne als exponentiell verteilt angesehen werden. Dies bedeutet, dass die Wahrscheinlichkeitsverteilung der Abklingzeiten einer Exponentialfunktion folgt. Die durchschnittliche Abklingzeit entspricht dem Parameter λ der Exponentialfunktion
6. Gammaverteilung
Gammaverteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die verwendet wird, um die Wahrscheinlichkeit des Auftretens eines Ereignisses innerhalb einer bestimmten Zeit zu beschreiben. Dies gilt für Situationen, in denen Ereignisse unabhängig voneinander sind und die durchschnittliche Auftrittsrate immer konstant ist. Die Wahrscheinlichkeitsdichtefunktion der Gammaverteilung lautet:
wobei f(x) die Zeit x zu einem bestimmten Zeitpunkt darstellt Wahrscheinlichkeitsdichte interner Ereignisse. α und β sind die Formparameter und Geschwindigkeitsparameter der Gammaverteilung. α wird verwendet, um die Form der Gammaverteilung zu bestimmen, und sein Wert reicht von 0 bis positiv unendlich. β stellt die durchschnittliche Auftretensrate von Ereignissen dar, dh die durchschnittliche Anzahl von Ereignissen, die pro Zeiteinheit auftreten, und der Wertebereich reicht von 0 bis positiv unendlich. e ist eine natürliche Konstante, die ungefähr 2,718 entspricht. Praktische Anwendungen der Gammaverteilung: Zum Beispiel radioaktiver Zerfall: Beim radioaktiven Zerfall kann die Zeit, die radioaktive Kerne zum Zerfall benötigen, als Gammaverteilung betrachtet werden, und die durchschnittliche Zerfallszeit beträgt β/. α.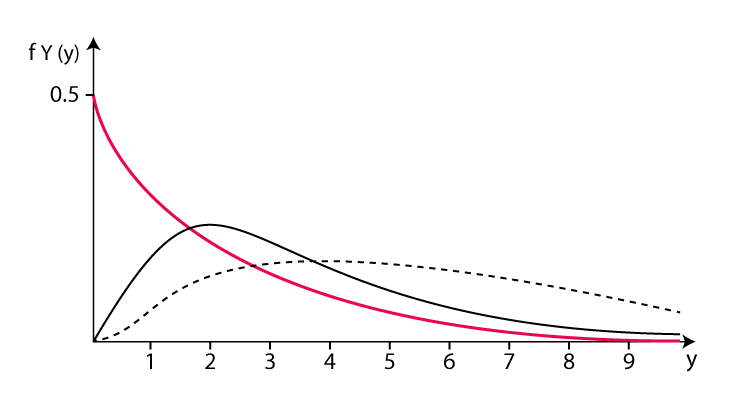 7. Beta-Verteilung
7. Beta-Verteilung
Beta-Verteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die verwendet wird, um die Wahrscheinlichkeitsverteilung der Anzahl von Erfolgen in einer Menge von Werten zu beschreiben. Es verfügt über zwei Parameter, die den Erwartungswert (Mittelwert) und die Standardabweichung (Standardabweichung) der Erfolgswahrscheinlichkeit darstellen.
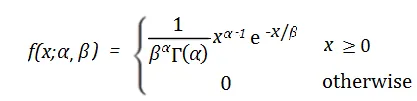
Die Wahrscheinlichkeitsdichtefunktion der Beta-Verteilung lautet wie folgt:
Dabei stellt x die Anzahl der Erfolge dar, α und β stellen jeweils die Formparameter der Verteilung darDie Beta-Verteilung hat Anwendungen in vielen praktischen Problemen. Bei der Genbearbeitung könnten Forscher beispielsweise eine Betaverteilung verwenden, um die Wahrscheinlichkeit vorherzusagen, dass eine Genbearbeitungstechnologie eine bestimmte Zielstelle erfolgreich bearbeiten wird. Im Finanzbereich kann die Betaverteilung zur Beschreibung der Volatilität von Vermögenspreisen oder zur Berechnung der erwarteten Rendite eines Anlageportfolios verwendet werden.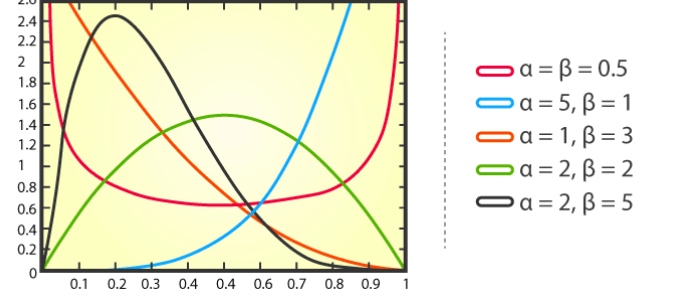 8 Gleichmäßige Verteilung
8 Gleichmäßige Verteilung
Die Gleichverteilung ist eine Wahrscheinlichkeitsverteilung, die zur Beschreibung einer Menge verwendet wird von Werten in einem bestimmten Intervall gleichmäßig verteilt. Es gibt zwei Arten von Gleichverteilungen: diskrete Gleichverteilung und kontinuierliche Gleichverteilung.
Diskrete Gleichverteilung: Wenn eine diskrete Zufallsvariable vorliegt, folgt sie einer diskreten Gleichverteilung. Kontinuierliche Gleichverteilung: Wenn die Wahrscheinlichkeitsdichtefunktion einer kontinuierlichen Zufallsvariablen auftreten. Wenn Sie beispielsweise eine faire Münze werfen, beträgt die Wahrscheinlichkeit von Kopf und Zahl 1/2, was einer gleichmäßigen Verteilung entspricht. 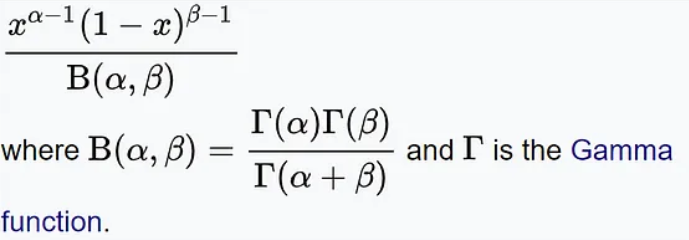
9. Log-Normalverteilung
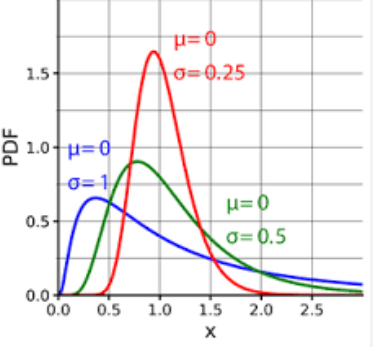
Die Log-Normalverteilung (Log-Normalverteilung) ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die dadurch gekennzeichnet ist, dass der Logarithmus der Zufallsvariablen der Normalverteilung folgt. Mit anderen Worten: Wenn der Logarithmus ln(X) einer Zufallsvariablen X der Normalverteilung folgt, dann folgt die Zufallsvariable X der Lognormalverteilung.
Die Wahrscheinlichkeitsdichtefunktion der Lognormalverteilung kann ausgedrückt werden als:
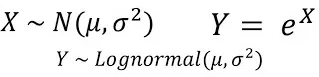
wobei μ der Mittelwert der Lognormalverteilung und σ die Standardabweichung der Lognormalverteilung ist.
Die logarithmische Normalverteilung ist in vielen praktischen Anwendungen von großer Bedeutung, beispielsweise im Finanzwesen (Aktienkurse, Renditen usw.), in der Biologie (Wachstumsrate usw.), in der Wirtschaft (Verbraucherausgaben usw.) usw.
10. T-Verteilung
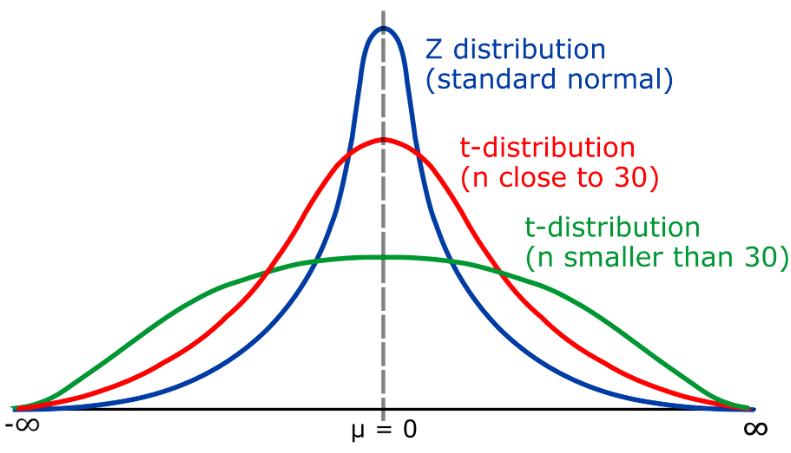
T-Verteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die hauptsächlich zur Beschreibung der Mittelwertverteilung bei kleinen Stichproben verwendet wird. Die t-Verteilung ähnelt der Normalverteilung, ihr Ende kann sich jedoch je nach Freiheitsgrad (k) nach links und rechts erstrecken. Die t-Verteilung wird häufig bei statistischen Schlussfolgerungen verwendet, beispielsweise beim Testen von Hypothesen, um den signifikanten Unterschied zwischen dem Stichprobenmittelwert und dem Populationsmittelwert zu bewerten.
Der Erwartungswert und die Varianz der t-Verteilung sind wie folgt:
E(t)=0
Der umzuschreibende Inhalt ist: Var(t)=k/(k-1)
Der Grad von Die Freiheit der t-Verteilung (k) stellt die Beziehung zwischen der Stichprobengröße (n) und der Standardabweichung der Grundgesamtheit dar. Wenn k > 30 ist, liegt die t-Verteilung nahe an der Normalverteilung; wenn k nahe bei 1 liegt, wird die t-Verteilung zur Cauchy-Verteilung (Cauchy-Verteilung)
In praktischen Anwendungen, wenn die Stichprobengröße groß ist (n>30) , es kann die Normalverteilung verwenden, um Hypothesentests durchzuführen. In diesem Fall können Sie die Z-Statistik verwenden, um ein Konfidenzintervall festzulegen. Wenn die Stichprobengröße jedoch klein ist (n
11. Weibull-Verteilung
Weibull-Verteilung (Weibull-Verteilung) ist eine kontinuierliche Wahrscheinlichkeitsverteilung.
Die Wahrscheinlichkeitsdichtefunktion der Weibull-Verteilung lautet:
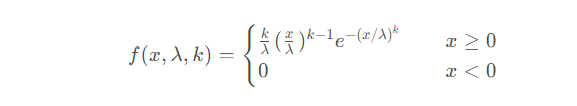
In der Weibull-Verteilung wird x als Zufallsvariable betrachtet, λ wird als Skalenparameter (Skala) bezeichnet und k ist der Formparameter (Form). Was die Weber-Verteilung betrifft, handelt es sich bei k gleich 1 um eine Exponentialverteilung. Wenn λ gleich 1 ist, ist dies die minimierte Weber-Verteilung
Das obige ist der detaillierte Inhalt von11 Grundverteilungen, die Datenwissenschaftler in 95 % der Fälle verwenden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Lesen Sie CSV-Dateien und führen Sie eine Datenanalyse mit Pandas durch
Jan 09, 2024 am 09:26 AM
Lesen Sie CSV-Dateien und führen Sie eine Datenanalyse mit Pandas durch
Jan 09, 2024 am 09:26 AM
Pandas ist ein leistungsstarkes Datenanalysetool, das verschiedene Arten von Datendateien problemlos lesen und verarbeiten kann. Unter diesen sind CSV-Dateien eines der gebräuchlichsten und am häufigsten verwendeten Datendateiformate. In diesem Artikel wird erläutert, wie Sie mit Pandas CSV-Dateien lesen und Datenanalysen durchführen, und es werden spezifische Codebeispiele bereitgestellt. 1. Importieren Sie die erforderlichen Bibliotheken. Zuerst müssen wir die Pandas-Bibliothek und andere möglicherweise benötigte verwandte Bibliotheken importieren, wie unten gezeigt: importpandasaspd 2. Lesen Sie die CSV-Datei mit Pan
 Einführung in Datenanalysemethoden
Jan 08, 2024 am 10:22 AM
Einführung in Datenanalysemethoden
Jan 08, 2024 am 10:22 AM
Gängige Datenanalysemethoden: 1. Vergleichende Analysemethode; 3. Methode der Trendanalyse; , Hauptkomponentenanalysemethode 9. Streuanalysemethode; 10. Matrixanalysemethode; Detaillierte Einführung: 1. Vergleichende Analysemethode: Vergleichende Analyse von zwei oder mehr Daten, um die Unterschiede und Muster zu finden. 2. Strukturelle Analysemethode: Eine Methode zur vergleichenden Analyse zwischen jedem Teil des Ganzen , usw.
 11 Grundverteilungen, die Datenwissenschaftler in 95 % der Fälle verwenden
Dec 15, 2023 am 08:21 AM
11 Grundverteilungen, die Datenwissenschaftler in 95 % der Fälle verwenden
Dec 15, 2023 am 08:21 AM
Im Anschluss an die letzte Bestandsaufnahme von „11 Basisdiagramme, die Datenwissenschaftler in 95 % der Zeit verwenden“ stellen wir Ihnen heute 11 Basisverteilungen vor, die Datenwissenschaftler in 95 % der Zeit verwenden. Die Beherrschung dieser Verteilungen hilft uns, die Natur der Daten besser zu verstehen und bei der Datenanalyse und Entscheidungsfindung genauere Schlussfolgerungen und Vorhersagen zu treffen. 1. Normalverteilung Die Normalverteilung, auch Gaußsche Verteilung genannt, ist eine kontinuierliche Wahrscheinlichkeitsverteilung. Es hat eine symmetrische glockenförmige Kurve mit dem Mittelwert (μ) als Mittelpunkt und der Standardabweichung (σ) als Breite. Die Normalverteilung hat in vielen Bereichen wie Statistik, Wahrscheinlichkeitstheorie und Ingenieurwesen einen wichtigen Anwendungswert.
 Maschinelles Lernen und Datenanalyse mit der Go-Sprache
Nov 30, 2023 am 08:44 AM
Maschinelles Lernen und Datenanalyse mit der Go-Sprache
Nov 30, 2023 am 08:44 AM
In der heutigen intelligenten Gesellschaft sind maschinelles Lernen und Datenanalyse unverzichtbare Werkzeuge, die den Menschen helfen können, große Datenmengen besser zu verstehen und zu nutzen. Auch in diesen Bereichen hat sich die Go-Sprache zu einer Programmiersprache entwickelt, die aufgrund ihrer Geschwindigkeit und Effizienz die erste Wahl vieler Programmierer ist. In diesem Artikel wird die Verwendung der Go-Sprache für maschinelles Lernen und Datenanalyse vorgestellt. 1. Das Ökosystem der Go-Sprache für maschinelles Lernen ist nicht so reichhaltig wie Python und R. Da jedoch immer mehr Menschen beginnen, es zu verwenden, gibt es einige Bibliotheken und Frameworks für maschinelles Lernen
 11 erweiterte Visualisierungen für Datenanalyse und maschinelles Lernen
Oct 25, 2023 am 08:13 AM
11 erweiterte Visualisierungen für Datenanalyse und maschinelles Lernen
Oct 25, 2023 am 08:13 AM
Visualisierung ist ein leistungsstarkes Werkzeug, um komplexe Datenmuster und Beziehungen auf intuitive und verständliche Weise zu kommunizieren. Sie spielen eine wichtige Rolle bei der Datenanalyse und liefern Erkenntnisse, die aus Rohdaten oder herkömmlichen numerischen Darstellungen oft nur schwer zu erkennen sind. Visualisierung ist für das Verständnis komplexer Datenmuster und -beziehungen von entscheidender Bedeutung. Wir stellen die 11 wichtigsten und unverzichtbarsten Diagramme vor, die dabei helfen, die Informationen in den Daten offenzulegen und komplexe Daten verständlicher und aussagekräftiger zu machen. 1. KSPlotKSPlot wird zur Bewertung von Verteilungsunterschieden verwendet. Die Kernidee besteht darin, den maximalen Abstand zwischen den kumulativen Verteilungsfunktionen (CDF) zweier Verteilungen zu messen. Je kleiner der maximale Abstand, desto wahrscheinlicher ist es, dass sie zur gleichen Verteilung gehören. Daher wird es hauptsächlich als „System“ zur Bestimmung von Verteilungsunterschieden interpretiert.
 Verwendung von ECharts und PHP-Schnittstellen zur Implementierung der Datenanalyse und Vorhersage statistischer Diagramme
Dec 17, 2023 am 10:26 AM
Verwendung von ECharts und PHP-Schnittstellen zur Implementierung der Datenanalyse und Vorhersage statistischer Diagramme
Dec 17, 2023 am 10:26 AM
Verwendung von ECharts und PHP-Schnittstellen zur Implementierung der Datenanalyse und Vorhersage statistischer Diagramme. Datenanalyse und -vorhersage spielen in verschiedenen Bereichen eine wichtige Rolle. Sie können uns helfen, die Trends und Muster von Daten zu verstehen und Referenzen für zukünftige Entscheidungen bereitzustellen. ECharts ist eine Open-Source-Datenvisualisierungsbibliothek, die umfangreiche und flexible Diagrammkomponenten bereitstellt, die mithilfe der PHP-Schnittstelle Daten dynamisch laden und verarbeiten können. In diesem Artikel wird die Implementierungsmethode der statistischen Diagrammdatenanalyse und -vorhersage basierend auf ECharts und der PHP-Schnittstelle vorgestellt und bereitgestellt
 Die romantische Reise von Python und maschinellem Lernen, ein Schritt vom Anfänger zum Experten
Feb 23, 2024 pm 08:34 PM
Die romantische Reise von Python und maschinellem Lernen, ein Schritt vom Anfänger zum Experten
Feb 23, 2024 pm 08:34 PM
1. Die Begegnung zwischen Python und maschinellem Lernen. Als leicht zu erlernende und leistungsstarke Programmiersprache ist Python bei Entwicklern sehr beliebt. Maschinelles Lernen als Zweig der künstlichen Intelligenz zielt darauf ab, Computern das Lernen aus Daten zu ermöglichen und Vorhersagen oder Entscheidungen zu treffen. Die Kombination von Python und maschinellem Lernen passt perfekt zusammen und bietet uns eine Reihe leistungsstarker Tools und Bibliotheken, die die Implementierung und Anwendung von maschinellem Lernen erleichtern. 2. Erkundung der Python-Bibliothek für maschinelles Lernen Python bietet viele funktionsreiche Bibliotheken für maschinelles Lernen, zu den beliebtesten gehören: NumPy: Bietet effiziente numerische Berechnungsfunktionen und ist die Basisbibliothek für maschinelles Lernen. SciPy: Bietet fortschrittlichere wissenschaftliche Computertools
 Integrierte Excel-Datenanalyse
Mar 21, 2024 am 08:21 AM
Integrierte Excel-Datenanalyse
Mar 21, 2024 am 08:21 AM
1. In dieser Lektion erklären wir die integrierte Excel-Datenanalyse. Wir vervollständigen sie anhand eines Falls. Öffnen Sie das Kursmaterial und klicken Sie auf Zelle E2, um die Formel einzugeben. 2. Anschließend wählen wir Zelle E53 aus, um alle folgenden Daten zu berechnen. 3. Dann klicken wir auf Zelle F2 und geben dann die Formel ein, um sie zu berechnen. Ebenso können wir durch Ziehen nach unten den gewünschten Wert berechnen. 4. Wir wählen Zelle G2 aus, klicken auf die Registerkarte „Daten“, klicken auf „Datenvalidierung“, wählen aus und bestätigen. 5. Verwenden wir dieselbe Methode, um die unten stehenden Zellen, die berechnet werden müssen, automatisch auszufüllen. 6. Als nächstes berechnen wir den tatsächlichen Lohn und wählen Zelle H2 aus, um die Formel einzugeben. 7. Dann klicken wir auf das Wert-Dropdown-Menü, um auf andere Zahlen zu klicken.
