
 Technologie-Peripheriegeräte
KI
Dieser Artikel fasst die klassischen Methoden und den Effektvergleich der Funktionsverbesserung und Personalisierung bei der CTR-Schätzung zusammen.
Technologie-Peripheriegeräte
KI
Dieser Artikel fasst die klassischen Methoden und den Effektvergleich der Funktionsverbesserung und Personalisierung bei der CTR-Schätzung zusammen.
Dieser Artikel fasst die klassischen Methoden und den Effektvergleich der Funktionsverbesserung und Personalisierung bei der CTR-Schätzung zusammen.

Bei der CTR-Schätzung verwendet die Mainstream-Methode Feature-Einbettung + MLP, wobei Features sehr wichtig sind. Für dieselben Merkmale ist die Darstellung jedoch in verschiedenen Stichproben gleich. Diese Art der Eingabe in das nachgeschaltete Modell schränkt die Ausdrucksfähigkeit des Modells ein.
Um dieses Problem zu lösen, wurde eine Reihe verwandter Arbeiten im Bereich der CTR-Schätzung vorgeschlagen, die als Feature-Enhancement-Modul bezeichnet werden. Das Feature-Enhancement-Modul korrigiert die Ausgabeergebnisse der Einbettungsschicht basierend auf verschiedenen Samples, um sie an die Feature-Darstellung verschiedener Samples anzupassen und die Ausdrucksfähigkeit des Modells zu verbessern.
Kürzlich haben die Fudan University und Microsoft Research Asia gemeinsam einen Bericht über die Arbeit zur Funktionsverbesserung veröffentlicht, in dem die Implementierungsmethoden und Auswirkungen verschiedener Funktionserweiterungsmodule verglichen werden. Lassen Sie uns nun die Implementierungsmethoden mehrerer Feature-Enhancement-Module sowie die zugehörigen Vergleichsexperimente vorstellen, die in diesem Artikel durchgeführt werden
 Titel des Papiers: Eine umfassende Zusammenfassung und Bewertung von Feature-Refinement-Modulen für die CTR-Vorhersage
Titel des Papiers: Eine umfassende Zusammenfassung und Bewertung von Feature-Refinement-Modulen für die CTR-Vorhersage
Download-Adresse: https ://arxiv.org/pdf/2311.04625v1.pdf
1. Idee zur Funktionsverbesserungsmodellierung
Das Funktionsverbesserungsmodul soll die Ausdrucksfähigkeit der Einbettungsschicht im CTR-Vorhersagemodell verbessern und eine Differenzierung derselben Funktionen erreichen in verschiedenen Proben. Das Funktionserweiterungsmodul kann durch die folgende einheitliche Formel ausgedrückt werden: Geben Sie die ursprüngliche Einbettung ein und generieren Sie nach Übergabe einer Funktion die personalisierte Einbettung dieses Beispiels.
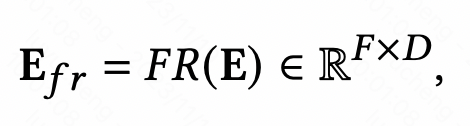 Bilder
Bilder
Die allgemeine Idee dieser Methode besteht darin, nach Erhalt der anfänglichen Einbettung jedes Features die Darstellung des Beispiels selbst zu verwenden, um die Feature-Einbettung zu transformieren und die personalisierte Einbettung des aktuellen Beispiels zu erhalten. Hier stellen wir einige klassische Modellierungsmethoden für Funktionserweiterungsmodule vor.
2. Klassische Methode zur Funktionsverbesserung
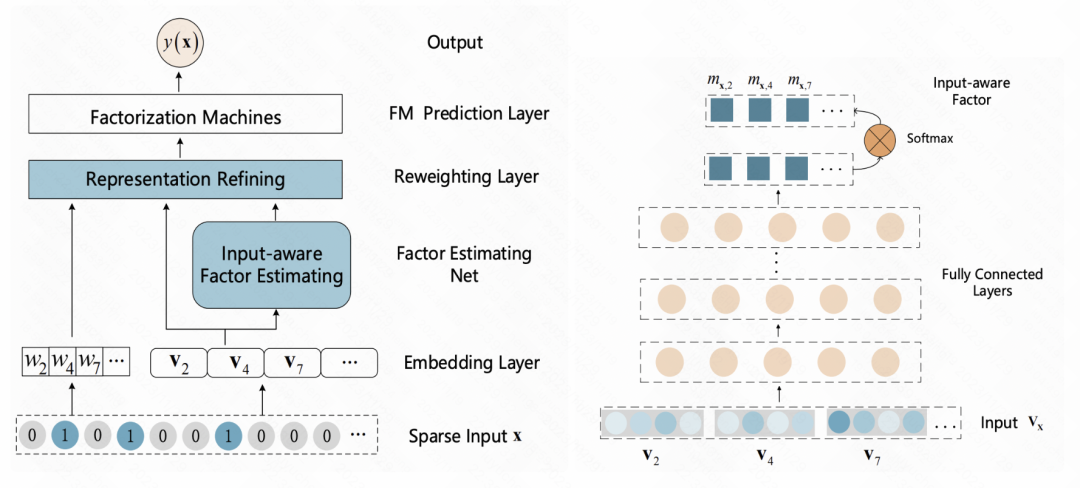
Eine eingabebewusste Faktorisierungsmaschine für die spärliche Vorhersage (IJCAI 2019) Dieser Artikel fügt nach der Einbettungsschicht eine Neugewichtungsschicht hinzu und gibt die anfängliche Einbettung der Probe in einen MLP ein, um eine Darstellung zu erhalten der Probe. Vektoren, normalisiert mit Softmax. Jedes Element nach Softmax entspricht einem Merkmal und stellt die Wichtigkeit dieses Merkmals dar. Dieses Softmax-Ergebnis wird mit der anfänglichen Einbettung jedes entsprechenden Merkmals multipliziert, um eine Gewichtung der Merkmalseinbettung bei Stichprobengranularität zu erreichen.
 Bilder
Bilder
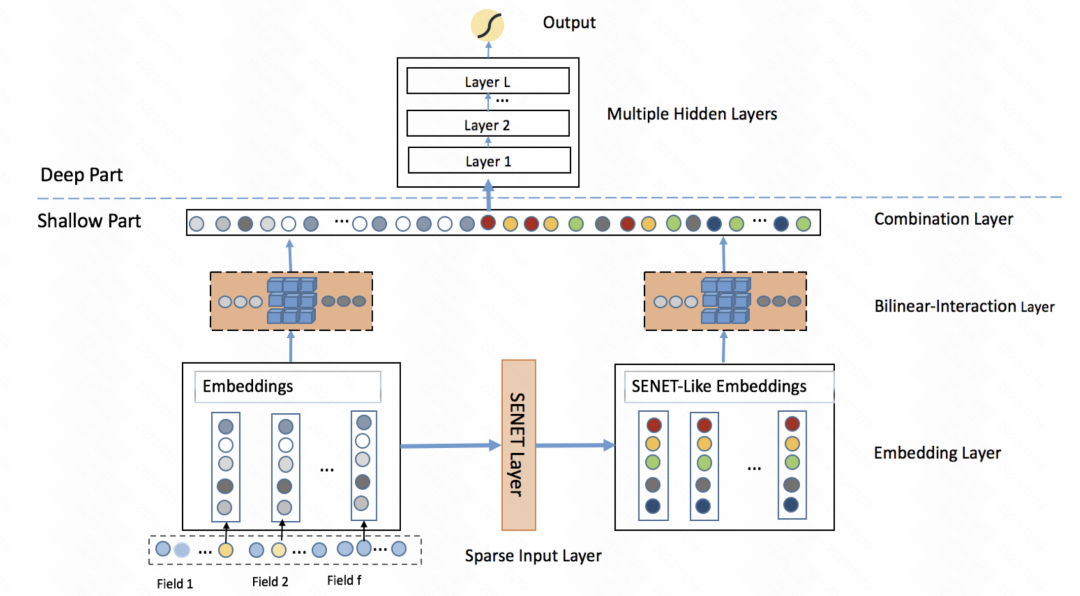
FiBiNET: Das Modell zur Vorhersage der Klickrate, das Merkmalswichtigkeit und Merkmalsinteraktion zweiter Ordnung kombiniert (RecSys 2019), übernimmt ebenfalls eine ähnliche Idee. Das Modell lernt für jede Stichprobe eine personalisierte Gewichtung eines Merkmals. Der gesamte Prozess ist in drei Schritte unterteilt: Auspressen, Extrahieren und Nachgewichten. In der Squeezing-Phase wird der Einbettungsvektor jedes Merkmals durch die Pooling-Methode als statistischer Skalar erhalten. In der Extraktionsphase werden diese Skalare in ein mehrschichtiges Perzeptron (MLP) eingegeben, um das Gewicht jedes Merkmals zu erhalten. Schließlich werden diese Gewichte mit dem Einbettungsvektor jedes Merkmals multipliziert, um das gewichtete Einbettungsergebnis zu erhalten, was dem Filtern der Merkmalswichtigkeit auf Stichprobenebene entspricht. IJCAI 2020) ähnelt dem vorherigen Artikel und nutzt auch die Selbstaufmerksamkeit, um Funktionen zu verbessern. Das Ganze ist in zwei Module unterteilt: vektorweise und bitweise. Vektorweise behandelt die Einbettung jedes Features als Element in der Sequenz und gibt es in den Transformer ein, um die fusionierte Feature-Darstellung zu erhalten. Der bitweise Teil verwendet mehrschichtiges MLP, um die ursprünglichen Features abzubilden. Nachdem die Eingabeergebnisse der beiden Teile addiert wurden, wird das Gewicht jedes Merkmalselements ermittelt und mit jedem Bit des entsprechenden Originalmerkmals multipliziert, um das erweiterte Merkmal zu erhalten.
 Image
Image
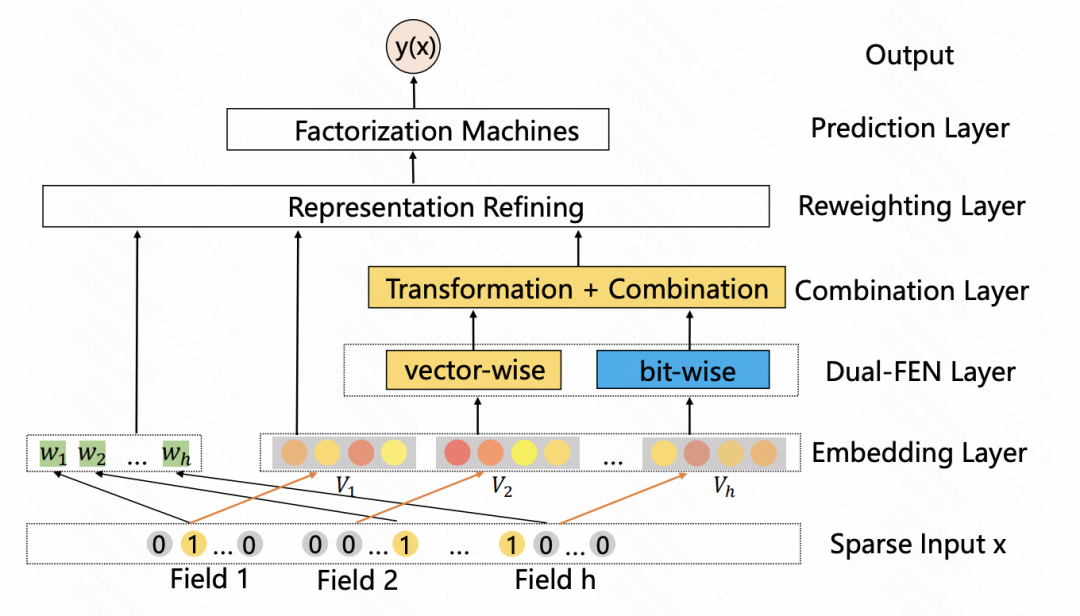
GateNet: Enhanced Gated Deep Network for Click-through-Rate Prediction (2020) Nutzt den anfänglichen Einbettungsvektor jedes Features, um seine unabhängige Feature-Gewichtungsbewertung über eine MLP- und Sigmoid-Funktion zu generieren, während MLP zum Kombinieren verwendet wird Alle Features werden bitweisen Gewichtungswerten zugeordnet, und die beiden werden kombiniert, um die Eingabefeatures zu gewichten. Zusätzlich zur Feature-Ebene wird in der verborgenen Ebene von MLP auch eine ähnliche Methode verwendet, um die Eingabe jeder verborgenen Ebene zu gewichten
 Bild
Bild
Interpretierbare Click-Through-Rate-Vorhersage durch hierarchische Aufmerksamkeit (WSDM 2020) nutzt ebenfalls Selbstaufmerksamkeit, um eine Feature-Konvertierung zu erreichen, fügt jedoch die Generierung von Features höherer Ordnung hinzu. Hier wird hierarchische Selbstaufmerksamkeit verwendet. Jede Schicht der Selbstaufmerksamkeit verwendet die Ausgabe der vorherigen Schicht als Eingabe. Jede Schicht fügt eine Merkmalskombination erster Ordnung hinzu, um eine hierarchische Merkmalsextraktion mehrerer Ordnung zu erreichen. Insbesondere wird die generierte neue Feature-Matrix nach der Durchführung der Selbstaufmerksamkeit durch Softmax geleitet, um das Gewicht jedes Features zu erhalten. Die neuen Features werden entsprechend den Gewichten der ursprünglichen Features gewichtet und anschließend ein Skalarprodukt durchgeführt mit den ursprünglichen Merkmalen, um eine Erhöhung der charakteristischen Schnittmenge der Ebenen zu erreichen.
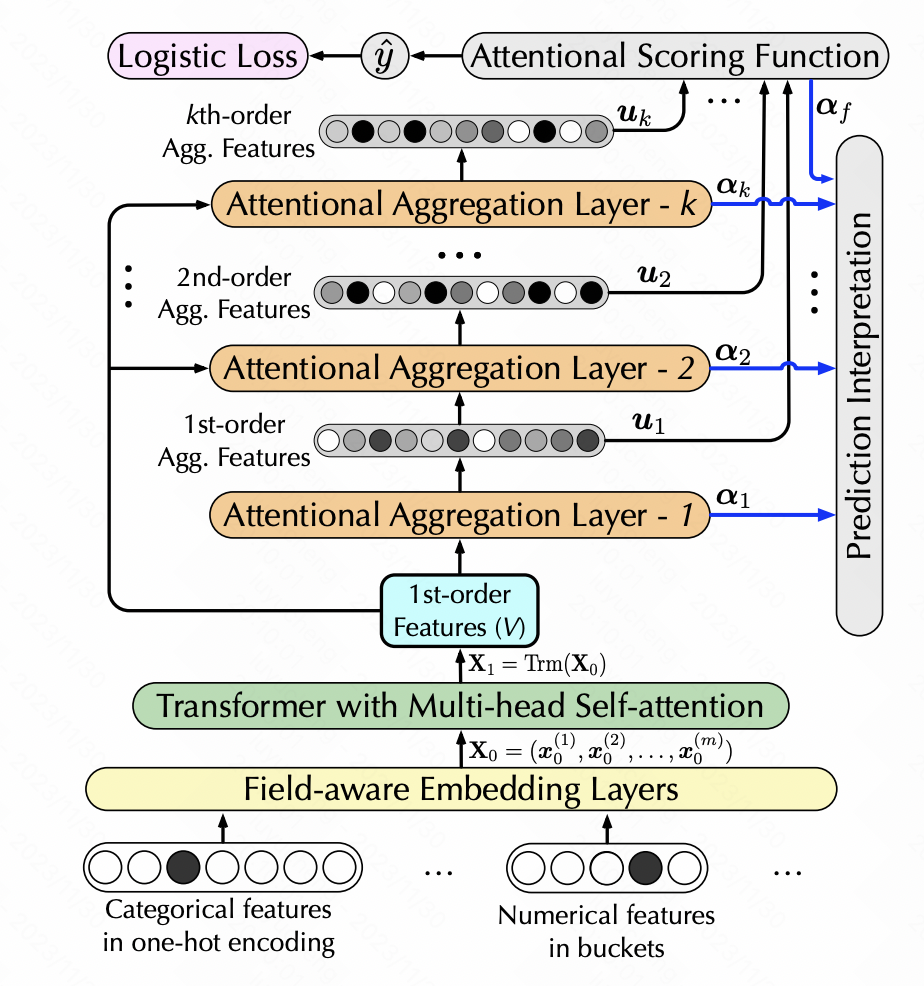 Pictures
Pictures
ContextNet: A Click-Through Rate Prediction Framework Using Contextual information to Refine Feature Embedding (2021) ist ebenfalls ein ähnlicher Ansatz, bei dem ein MLP verwendet wird, um alle Features in einer Dimension jeder Feature-Einbettungsgröße abzubilden, z Die ursprünglichen Features werden skaliert und für jedes Feature werden personalisierte MLP-Parameter verwendet. Auf diese Weise wird jedes Merkmal verbessert, indem andere Merkmale im Beispiel als obere und untere Bits verwendet werden.
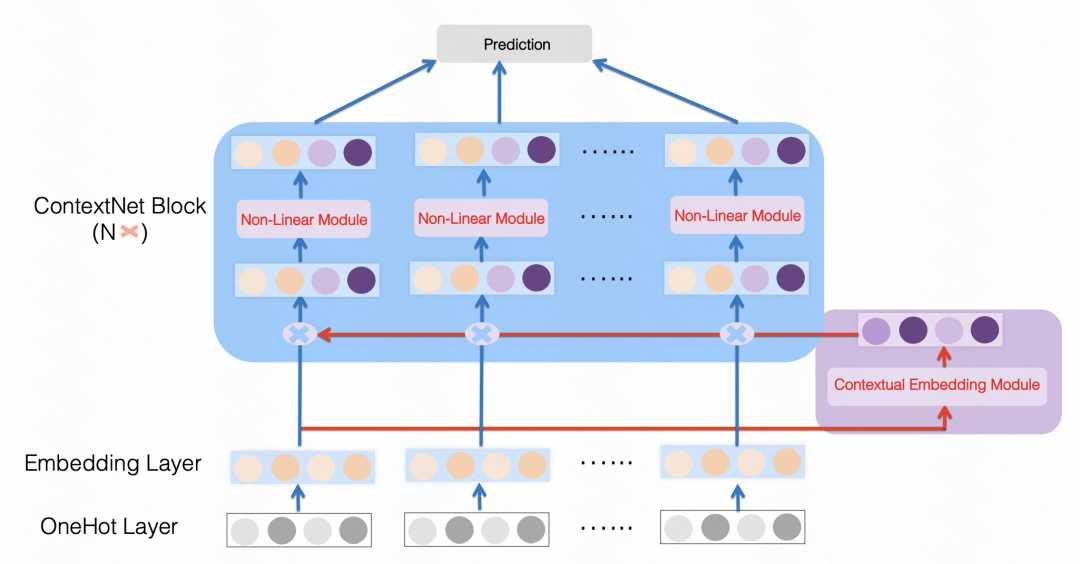 Bilder
Bilder
Enhancing CTR Prediction with Context-Aware Feature Representation Learning (SIGIR 2022) nutzt die Selbstaufmerksamkeit zur Funktionsverbesserung. Bei einer Reihe von Eingabefunktionen ist der Grad des Einflusses jeder Funktion auf andere Funktionen unterschiedlich. Durch Selbstaufmerksamkeit wird die Einbettung jedes Merkmals selbst durchgeführt, um eine Informationsinteraktion zwischen Merkmalen innerhalb der Stichprobe zu erreichen. Zusätzlich zur Interaktion zwischen Funktionen verwendet der Artikel MLP auch für die Informationsinteraktion auf Bitebene. Die oben generierte neue Einbettung wird über ein Gate-Netzwerk mit der ursprünglichen Einbettung zusammengeführt, um die endgültige verfeinerte Merkmalsdarstellung zu erhalten.
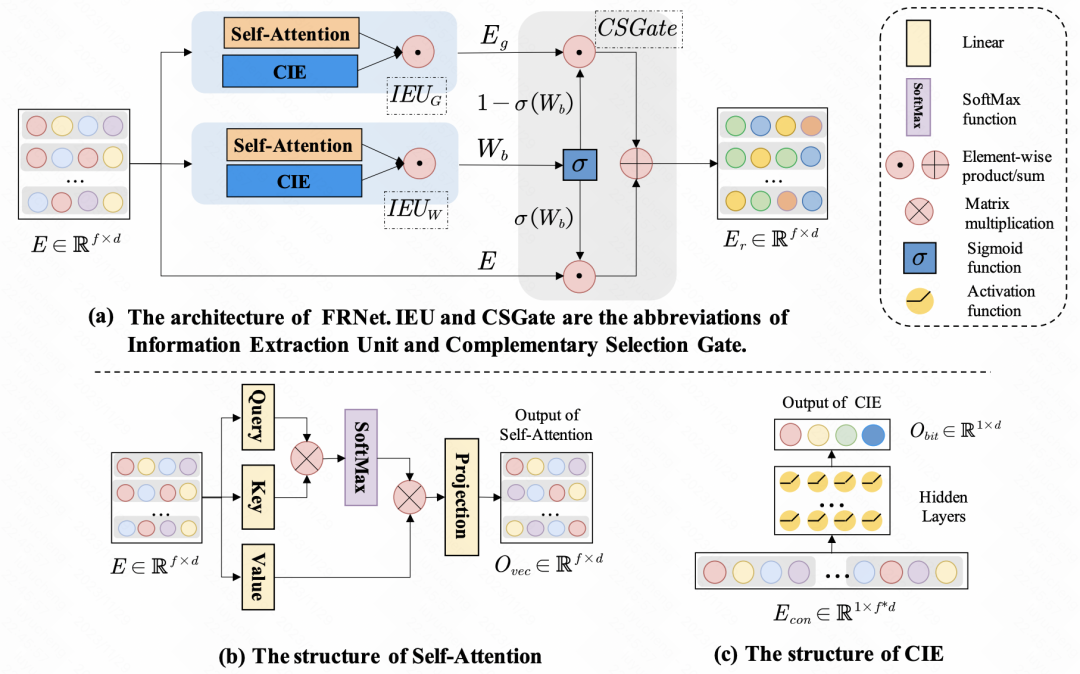 Bilder
Bilder
3. Experimentelle Ergebnisse
Nachdem wir die Auswirkungen verschiedener Methoden zur Funktionsverbesserung verglichen hatten, kamen wir zu dem Gesamtschluss: Unter vielen Modulen zur Funktionsverbesserung schneiden GFRL, FRNet-V und FRNetB am besten ab Der Effekt ist besser als bei anderen Methoden zur Funktionsverbesserung
Das obige ist der detaillierte Inhalt vonDieser Artikel fasst die klassischen Methoden und den Effektvergleich der Funktionsverbesserung und Personalisierung bei der CTR-Schätzung zusammen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

![WLAN-Erweiterungsmodul ist gestoppt [Fix]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN-Erweiterungsmodul ist gestoppt [Fix]
Feb 19, 2024 pm 02:18 PM
WLAN-Erweiterungsmodul ist gestoppt [Fix]
Feb 19, 2024 pm 02:18 PM
Wenn es ein Problem mit dem WLAN-Erweiterungsmodul Ihres Windows-Computers gibt, kann dies dazu führen, dass Sie nicht mehr mit dem Internet verbunden sind. Diese Situation ist oft frustrierend, aber glücklicherweise enthält dieser Artikel einige einfache Vorschläge, die Ihnen helfen können, dieses Problem zu lösen und Ihre drahtlose Verbindung wieder ordnungsgemäß funktionieren zu lassen. Behebung, dass das WLAN-Erweiterbarkeitsmodul nicht mehr funktioniert Wenn das WLAN-Erweiterbarkeitsmodul auf Ihrem Windows-Computer nicht mehr funktioniert, befolgen Sie diese Vorschläge, um das Problem zu beheben: Führen Sie die Netzwerk- und Internet-Fehlerbehebung aus, um drahtlose Netzwerkverbindungen zu deaktivieren und wieder zu aktivieren. Starten Sie den WLAN-Autokonfigurationsdienst neu. Ändern Sie die Energieoptionen. Ändern Erweiterte Energieeinstellungen Netzwerkadaptertreiber neu installieren Einige Netzwerkbefehle ausführen Schauen wir uns das nun im Detail an
 Das WLAN-Erweiterungsmodul kann nicht gestartet werden
Feb 19, 2024 pm 05:09 PM
Das WLAN-Erweiterungsmodul kann nicht gestartet werden
Feb 19, 2024 pm 05:09 PM
In diesem Artikel werden Methoden zur Behebung des Ereignisses ID10000 beschrieben, das darauf hinweist, dass das WLAN-Erweiterungsmodul nicht gestartet werden kann. Dieser Fehler kann im Ereignisprotokoll des Windows 11/10-PCs erscheinen. Das WLAN-Erweiterbarkeitsmodul ist eine Komponente von Windows, die es unabhängigen Hardwareanbietern (IHVs) und unabhängigen Softwareanbietern (ISVs) ermöglicht, Benutzern angepasste Features und Funktionen für drahtlose Netzwerke bereitzustellen. Es erweitert die Funktionalität nativer Windows-Netzwerkkomponenten durch Hinzufügen von Windows-Standardfunktionen. Das WLAN-Erweiterungsmodul wird im Rahmen der Initialisierung gestartet, wenn das Betriebssystem Netzwerkkomponenten lädt. Wenn beim WLAN-Erweiterungsmodul ein Problem auftritt und es nicht gestartet werden kann, wird möglicherweise eine Fehlermeldung im Protokoll der Ereignisanzeige angezeigt.
 Python verwendet häufig Standardbibliotheken und Bibliotheken von Drittanbietern im 2-SYS-Modul
Apr 10, 2023 pm 02:56 PM
Python verwendet häufig Standardbibliotheken und Bibliotheken von Drittanbietern im 2-SYS-Modul
Apr 10, 2023 pm 02:56 PM
1. Einführung in das SYS-Modul Das zuvor vorgestellte OS-Modul ist hauptsächlich für das Betriebssystem gedacht, während das SYS-Modul in diesem Artikel hauptsächlich für den Python-Interpreter gedacht ist. Das sys-Modul ist ein Modul, das mit Python geliefert wird. Es ist eine Schnittstelle für die Interaktion mit dem Python-Interpreter. Das sys-Modul bietet viele Funktionen und Variablen für den Umgang mit verschiedenen Teilen der Python-Laufzeitumgebung. 2. Häufig verwendete Methoden des sys-Moduls Sie können mithilfe der dir()-Methode überprüfen, welche Methoden im sys-Modul enthalten sind: import sys print(dir(sys))1.sys.argv – Rufen Sie die Befehlszeilenparameter sys ab. argv wird verwendet, um den Befehl von außerhalb des Programms zu implementieren. Dem Programm werden Parameter übergeben und es kann die Befehlszeilenparameterspalte abrufen
 Python-Programmierung: Detaillierte Erläuterung der wichtigsten Punkte bei der Verwendung benannter Tupel
Apr 11, 2023 pm 09:22 PM
Python-Programmierung: Detaillierte Erläuterung der wichtigsten Punkte bei der Verwendung benannter Tupel
Apr 11, 2023 pm 09:22 PM
Vorwort In diesem Artikel wird weiterhin das Python-Sammlungsmodul vorgestellt. Dieses Mal werden hauptsächlich die darin enthaltenen benannten Tupel vorgestellt, dh die Verwendung von benannten Tupeln. Fangen wir ohne Umschweife an – denken Sie daran, „Gefällt mir“, „Folgen“ und „Weiterleiten“ zu markieren. Sie können überall dort verwendet werden, wo reguläre Tupel verwendet werden, und bieten die Möglichkeit, auf Felder über den Namen statt über den Positionsindex zuzugreifen. Es stammt aus den in Python integrierten Modulsammlungen. Die verwendete allgemeine Syntax lautet: Sammlungen importieren XxNamedT
 So verwenden Sie DateTime in Python
Apr 19, 2023 pm 11:55 PM
So verwenden Sie DateTime in Python
Apr 19, 2023 pm 11:55 PM
Alle Daten werden zu Beginn automatisch mit einem „DOB“ (Geburtsdatum) versehen. Daher ist es unvermeidlich, dass bei der Verarbeitung von Daten irgendwann Datums- und Uhrzeitdaten auftreten. Dieses Tutorial führt Sie durch das Datetime-Modul in Python und die Verwendung einiger Peripheriebibliotheken wie Pandas und Pytz. In Python wird alles, was mit Datum und Uhrzeit zu tun hat, vom datetime-Modul verarbeitet, das das Modul weiter in fünf verschiedene Klassen unterteilt. Klassen sind einfach Datentypen, die Objekten entsprechen. Die folgende Abbildung fasst die fünf Datetime-Klassen in Python zusammen mit häufig verwendeten Attributen und Beispielen zusammen. 3 nützliche Snippets 1. Konvertieren Sie einen String in das Datetime-Format, möglicherweise mit datet
 Ausführliche Erklärung der Funktionsweise von Ansible
Feb 18, 2024 pm 05:40 PM
Ausführliche Erklärung der Funktionsweise von Ansible
Feb 18, 2024 pm 05:40 PM
Das Funktionsprinzip von Ansible kann aus der obigen Abbildung verstanden werden: Die Verwaltungsseite unterstützt drei Methoden: Lokal, SSH und Zeromq, um eine Verbindung zur verwalteten Seite herzustellen. Dieser Teil entspricht der Verbindung Im obigen Architekturdiagramm können Sie den Anwendungstyp HostInventory (Hostliste) verwenden, um entsprechende Vorgänge über verschiedene Module zu implementieren und einen einzelnen Befehl auszuführen -hoc; Der Verwaltungsknoten kann eine Reihe von Aufgaben über Playbooks implementieren, z. B. die Installation und Bereitstellung von Webdiensten, die Stapelsicherung von Datenbankservern usw. Wir können Playbooks einfach so verstehen, wie das System vergeht
 Wie funktioniert der Import von Python?
May 15, 2023 pm 08:13 PM
Wie funktioniert der Import von Python?
May 15, 2023 pm 08:13 PM
Hallo, mein Name ist somenzz, du kannst mich Bruder Zheng nennen. Der Import von Python ist sehr intuitiv, aber manchmal werden Sie feststellen, dass trotz des Vorhandenseins des Pakets immer noch ModuleNotFoundError auftritt. Der relative Pfad ist offensichtlich sehr korrekt, aber der Fehler ImportError:attemptedrelativeimportwithnoknownparentpackage importiert ein Modul im selben Verzeichnis ein anderes. Die Module des Verzeichnisses sind völlig unterschiedlich. Dieser Artikel hilft Ihnen, den Import zu vereinfachen, indem er einige Probleme analysiert, die bei der Verwendung des Imports auftreten. Auf dieser Grundlage können Sie problemlos Attribute erstellen.
 Dieser Artikel fasst die klassischen Methoden und den Effektvergleich der Funktionsverbesserung und Personalisierung bei der CTR-Schätzung zusammen.
Dec 15, 2023 am 09:23 AM
Dieser Artikel fasst die klassischen Methoden und den Effektvergleich der Funktionsverbesserung und Personalisierung bei der CTR-Schätzung zusammen.
Dec 15, 2023 am 09:23 AM
Bei der CTR-Schätzung verwendet die Mainstream-Methode Feature-Einbettung + MLP, wobei Features sehr wichtig sind. Für dieselben Merkmale ist die Darstellung jedoch in verschiedenen Stichproben gleich. Diese Art der Eingabe in das nachgeschaltete Modell schränkt die Ausdrucksfähigkeit des Modells ein. Um dieses Problem zu lösen, wurde eine Reihe verwandter Arbeiten im Bereich der CTR-Schätzung vorgeschlagen, die als Feature-Enhancement-Modul bezeichnet werden. Das Feature-Enhancement-Modul korrigiert die Ausgabeergebnisse der Einbettungsschicht basierend auf verschiedenen Samples, um sie an die Feature-Darstellung verschiedener Samples anzupassen und die Ausdrucksfähigkeit des Modells zu verbessern. Kürzlich haben die Fudan-Universität und Microsoft Research Asia gemeinsam einen Bericht über die Arbeit zur Funktionsverbesserung veröffentlicht, in dem die Implementierungsmethoden und Auswirkungen verschiedener Funktionserweiterungsmodule verglichen werden. Lassen Sie uns nun a vorstellen
