
 Technologie-Peripheriegeräte
KI
X-Dreamer durchbricht die dimensionale Wand und bringt hochwertigen Text in die 3D-Generierung, indem es die Bereiche der 2D- und 3D-Generierung integriert.
Technologie-Peripheriegeräte
KI
X-Dreamer durchbricht die dimensionale Wand und bringt hochwertigen Text in die 3D-Generierung, indem es die Bereiche der 2D- und 3D-Generierung integriert.
X-Dreamer durchbricht die dimensionale Wand und bringt hochwertigen Text in die 3D-Generierung, indem es die Bereiche der 2D- und 3D-Generierung integriert.

In den letzten Jahren wurden erhebliche Fortschritte bei der automatischen Umwandlung von Text in 3D-Inhalte erzielt, angetrieben durch die Entwicklung vorab trainierter Diffusionsmodelle [1, 2, 3]. Darunter stellt DreamFusion[4] eine effektive Methode vor, die ein vorab trainiertes 2D-Diffusionsmodell[5] verwendet, um automatisch 3D-Assets aus Text zu generieren, ohne dass ein dedizierter 3D-Asset-Datensatz erforderlich ist
Eingeführt von DreamFusion. Eine wichtige Innovation ist der Fractional Distillation Sampling (SDS)-Algorithmus. Der Algorithmus wertet eine einzelne 3D-Darstellung mithilfe eines vorab trainierten 2D-Diffusionsmodells wie NeRF [6] aus und optimiert sie dadurch, um sicherzustellen, dass das gerenderte Bild aus jeder Kameraperspektive eine hohe Konsistenz mit dem gegebenen Text beibehält. Inspiriert durch den bahnbrechenden SDS-Algorithmus sind mehrere Arbeiten [7, 8, 9, 10, 11] entstanden, um Text-zu-3D-Generierungsaufgaben durch die Anwendung vorab trainierter 2D-Diffusionsmodelle voranzutreiben.
Während bei der Text-zu-3D-Generierung durch die Nutzung vorab trainierter Text-zu-2D-Diffusionsmodelle erhebliche Fortschritte erzielt wurden, besteht immer noch eine große Feldlücke zwischen 2D-Bildern und 3D-Assets. Dieser Unterschied ist in Abbildung 1 deutlich zu erkennen.
Erstens erzeugen Text-zu-2D-Modelle kameraunabhängige Generierungsergebnisse, wobei der Schwerpunkt auf der Generierung hochwertiger Bilder aus bestimmten Winkeln liegt und andere Winkel ignoriert werden. Im Gegensatz dazu ist die Erstellung von 3D-Inhalten eng an Kameraparameter wie Position, Aufnahmewinkel und Sichtfeld gebunden. Daher müssen Text-zu-3D-Modelle über alle möglichen Kameraparameter qualitativ hochwertige Ergebnisse liefern.
Darüber hinaus müssen generative Text-zu-2D-Modelle gleichzeitig Vordergrund- und Hintergrundelemente generieren, um die Gesamtkohärenz des Bildes aufrechtzuerhalten. Im Gegensatz dazu müssen sich generative Text-zu-3D-Modelle nur auf die Erstellung von Vordergrundobjekten konzentrieren. Dieser Unterschied ermöglicht es Text-zu-3D-Modellen, mehr Ressourcen und Aufmerksamkeit für die genaue Darstellung und Generierung von Vordergrundobjekten bereitzustellen. Wenn daher vorab trainierte 2D-Diffusionsmodelle direkt für die Erstellung von 3D-Assets verwendet werden, wird der Domänenunterschied zwischen Text-zu-2D- und Text-zu-3D-Generierung zu einem offensichtlichen Leistungshindernis
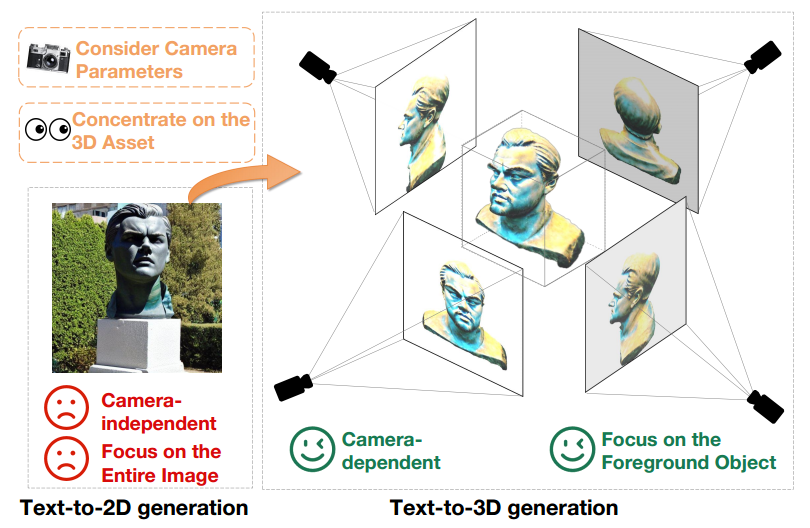
Abbildung 1 Textausgabe des -zu-2D-generiertes Modell (links) und das Text-zu-3D-generierte Modell (rechts) unter derselben Textaufforderung, nämlich „Eine Statue von Leonardo DiCaprios Kopf.“
Um dieses Problem zu lösen, schlägt das Papier X-Dreamer vor, eine neuartige Methode zur Erstellung hochwertiger Text-zu-3D-Inhalte, die Text-zu-2D- und Text-zu-3D-Domänenlücken zwischen Generationen effektiv schließen kann.
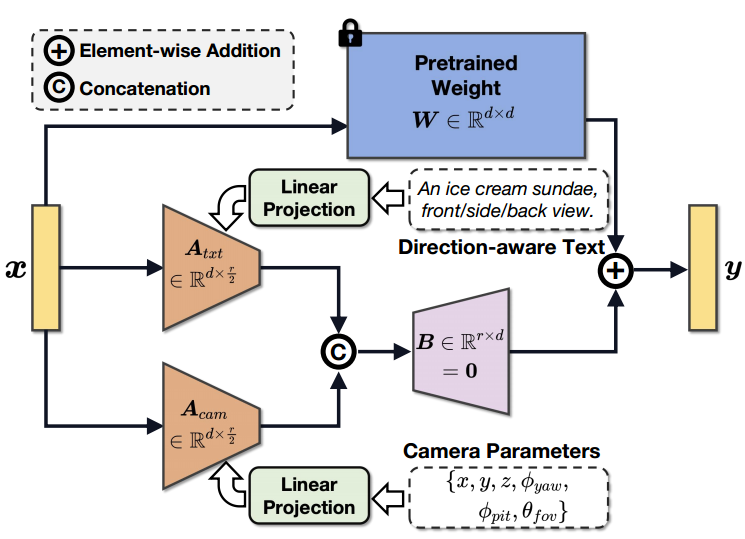
Die Schlüsselkomponenten von X-Dreamer sind zwei innovative Designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) und Attention-Mask Alignment (AMA)-Verlust.
Erstens verwenden bestehende Methoden [7, 8, 9, 10] normalerweise vorab trainierte 2D-Diffusionsmodelle [5, 12] für die Text-zu-3D-Generierung, denen eine inhärente Verbindung mit Kameraparametern fehlt. Um diese Einschränkung zu beheben und sicherzustellen, dass X-Dreamer Ergebnisse liefert, die direkt von den Kameraparametern beeinflusst werden, wird in dem Artikel CG-LoRA eingeführt, um das vorab trainierte 2D-Diffusionsmodell anzupassen. Insbesondere werden die Parameter von CG-LoRA während jeder Iteration dynamisch basierend auf Kamerainformationen generiert, wodurch eine robuste Beziehung zwischen dem Text-zu-3D-Modell und den Kameraparametern hergestellt wird.
Zweitens schenkt das vorab trainierte Text-zu-2D-Diffusionsmodell Aufmerksamkeit der Vorder- und Hintergrundgenerierung, während die Erstellung von 3D-Assets mehr Aufmerksamkeit auf die genaue Generierung von Vordergrundobjekten erfordert. Um dieses Problem anzugehen, schlägt das Papier den AMA-Verlust vor, der eine binäre Maske von 3D-Objekten verwendet, um die Aufmerksamkeitskarte eines vorab trainierten Diffusionsmodells zu steuern und die Erstellung von Vordergrundobjekten zu priorisieren. Durch die Integration dieses Moduls priorisiert X-Dreamer die Generierung von Vordergrundobjekten und verbessert so die Gesamtqualität der generierten 3D-Inhalte erheblich.

Projekt-Homepage:
https://xmu-xiaoma666.github.io/Projects/X-Dreamer/
Github-Homepage: https://github.com/xmu-xiaoma666 /X-Dreamer
DiskussionArtikelAdresse: https://arxiv.org/abs/2312.00085
X-Dreamer hat die folgenden Beiträge zum Bereich der Text-zu-3D-Generierung geleistet:
- Das Papier schlägt einen neuartigen Ansatz, X-Dreamer, für die Erstellung hochwertiger Text-zu-3D-Inhalte vor, der die große Lücke zwischen der Text-zu-2D- und der Text-zu-3D-Generierung effektiv schließt.
- Um die Ausrichtung zwischen den generierten Ergebnissen und der Kameraperspektive zu verbessern, schlägt das Papier CG-LoRA vor, das Kamerainformationen verwendet, um spezifische Parameter des 2D-Diffusionsmodells dynamisch zu generieren.
-
Um die Erstellung von Vordergrundobjekten in Text-zu-3D-Modellen zu priorisieren, führt das Papier den AMA-Verlust ein, der eine binäre Maske von Vordergrund-3D-Objekten verwendet, um die Aufmerksamkeitskarte des 2D-Diffusionsmodells zu steuern.
Methode
X-Dreamer enthält zwei Hauptphasen: Geometrielernen und Aussehenslernen. Für das Geometrielernen verwendet diese Studie DMTET als 3D-Darstellung und verwendet ein 3D-Ellipsoid, um es zu initialisieren. Bei der Initialisierung verwendet die Verlustfunktion den Verlust des mittleren quadratischen Fehlers (MSE). Als nächstes werden DMTET und CG-LoRA unter Verwendung des SDS-Verlusts (Fractional Distillation Sampling) und des in dieser Studie vorgeschlagenen AMA-Verlusts optimiert, um die Ausrichtung zwischen der 3D-Darstellung und den eingegebenen Texthinweisen sicherzustellen. Für das Erlernen des Erscheinungsbilds nutzt das Papier bidirektional Modellierung der Reflexionsverteilungsfunktion (BRDF). Konkret nutzt das Papier MLP mit trainierbaren Parametern, um Oberflächenmaterialien vorherzusagen. Ähnlich wie in der Geometrie-Lernphase verwendet das Papier SDS-Verlust und AMA-Verlust, um die trainierbaren Parameter von MLP und CG-LoRA zu optimieren und eine Ausrichtung zwischen 3D-Darstellungen und Texthinweisen zu erreichen. Abbildung 2 zeigt die detaillierte Zusammensetzung von X-Dreamer.
Abbildung 2 Übersicht über X-Dreamer, einschließlich Geometrielernen und Aussehenslernen. 
Geometrielernen
(Geometrielernen)In diesem Modul nutzt X-Dreamer das MLP-Netzwerk
, um DMTET in eine 3D-Darstellung zu parametrisieren. Um die Stabilität der geometrischen Modellierung zu verbessern, verwendet dieser Artikel ein 3D-Ellipsoid als Anfangskonfiguration von DMTET . Für jeden Scheitelpunkt Nachdem Sie die Geometrie initialisiert haben, richten Sie die Geometrie des DMTET an der Eingabeaufforderung aus. Dies erfolgt durch die Verwendung einer Differential-Rendering-Technik, um eine Normalkarte n und eine Maske m des Objekts aus einem initialisierten DMTET wobei, Um SD außerdem auf die Generierung von Vordergrundobjekten zu konzentrieren, führt X-Dreamer einen zusätzlichen AMA-Verlust ein, um die Objektmaske wie folgt an der Aufmerksamkeitskarte von SD auszurichten: Where Appearance Learning(Appearance Learning) Nachdem die Geometrie eines 3D-Objekts ermittelt wurde, besteht das Ziel dieses Artikels darin, das Erscheinungsbild des 3D-Objekts mithilfe eines PBR-Materialmodells (Physically Based Rendering) zu berechnen. Das Materialmodell umfasst einen Diffusionsterm auf der Oberfläche der Geometrie wird das durch wobei Unter diesen stellt Camera-Guided Low-Rank Adaptation (CG-LoRA) Um das Generierungsproblem suboptimaler 3D-Ergebnisse zu lösen, das durch die Domänenlücke zwischen der Generierung von Text in 2D und 3D verursacht wird, X - Dreamer schlug eine kameragesteuerte Low-Rank-Anpassungsmethode vor, wie in Abbildung 3 dargestellt, die Kameraparameter und richtungsbewussten Text verwendet, um die Generierung von Parametern in CG-LoRA zu steuern, sodass X-Dreamer dies effektiv wahrnehmen kann Positions- und Richtungsinformationen der Kamera. Abbildung 3 Darstellung der kamerageführten CG-LoRA. Insbesondere verwenden Sie bei einer Textaufforderung Daunter sind wobei wird verwendet, um die Form des Tensors von Unter diesen stellt Da die Softmax-Funktion zum Normalisieren der Aufmerksamkeitskartenwerte verwendet wird, können die Aktivierungswerte in der Aufmerksamkeitskarte sehr klein werden, wenn die Auflösung der Bildmerkmale hoch ist. Allerdings ist die direkte Ausrichtung der Aufmerksamkeitskarte an der Maske des gerenderten 3D-Objekts nicht optimal, wenn man bedenkt, dass jedes Element in der gerenderten 3D-Objektmaske einen Binärwert von 0 oder 1 hat. Um dieses Problem zu lösen, schlägt das Papier eine Normalisierungstechnik vor, die die Werte in der Aufmerksamkeitskarte auf Werte zwischen (0, 1) abbildet. Die Formel für diesen Normalisierungsprozess lautet wie folgt: wobei Der Artikel verwendet vier Nvidia RTX 3090 GPUs und die PyTorch-Bibliothek, um Experimente durchzuführen. Zur Berechnung des SDS-Verlusts wurde das über Hugging Face Diffusers implementierte Stable Diffusion-Modell verwendet. Für DMTET- und Material-Encoder werden sie als zweischichtiges MLP bzw. einschichtiges MLP mit einer verborgenen Schichtdimension von 32 implementiert. Beginnen Sie mit dem Ellipsoid, um Text-zu-3D zu generieren Der Artikel zeigt die Ergebnisse der Text-zu-3D-Generierung von X-Dreamer unter Verwendung des Ellipsoids als anfängliche geometrische Form, wie in gezeigt Abbildung 4 dargestellt. Die Ergebnisse belegen die Fähigkeit von X-Dreamer, hochwertige und fotorealistische 3D-Objekte zu erzeugen, die genau den eingegebenen Textaufforderungen entsprechen. Abbildung 4: Verwendung des Ellipsoids als Ausgangspunkt für die Text-zu-3D-Generierung Ausgehend vom grobkörnigen Raster für die Text-zu-3D-Generierung Allerdings Eine große Anzahl grobkörniger Netze kann aus dem Internet heruntergeladen werden. Die direkte Verwendung dieser Netze zur Erstellung von 3D-Inhalten führt jedoch aufgrund fehlender geometrischer Details häufig zu einer schlechten Leistung. Allerdings können diese Netze X-Dreamer bessere 3D-Formvorinformationen liefern als 3D-Ellipsoide. Daher ist es auch möglich, anstelle eines Ellipsoids ein grobkörniges Führungsgitter zur Initialisierung von DMTET zu verwenden. Wie in Abbildung 5 dargestellt, kann X-Dreamer 3D-Assets mit präzisen geometrischen Details basierend auf gegebenem Text generieren, selbst wenn das bereitgestellte grobkörnige Netz keine Details aufweist. Abbildung 5 Text-zu-3D-Generierung ausgehend von einem grobkörnigen Netz. Was neu geschrieben werden muss, ist: Qualitativer Vergleich. Um die Wirksamkeit von X-Dreamer zu bewerten, vergleicht dieses Papier es mit vier fortgeschrittenen Methoden: DreamFusion [4], Magic3D [8], Fantasia3D [ 7] und ProlificDreamer [11], wie in Abbildung 6 Im Vergleich zu SDS-basierten Methoden [4, 7, 8] übertrifft X-Dreamer diese bei der Generierung hochwertiger und realistischer 3D-Assets. Darüber hinaus erzeugt X-Dreamer 3D-Inhalte mit vergleichbaren oder sogar besseren visuellen Effekten im Vergleich zu VSD-basierten Methoden [11] und erfordert dabei deutlich weniger Optimierungszeit. Insbesondere dauert der Lernprozess für Geometrie und Aussehen bei X-Dreamer nur etwa 27 Minuten, im Vergleich zu mehr als 8 Stunden bei ProlificDreamer. Abbildung 6 Vergleich mit State-of-the-Art-Methoden (SOTA). Der Inhalt, der neu geschrieben werden muss, ist: Ablationsexperiment Um die Fähigkeiten von CG-LoRA und AMA-Verlust tiefgreifend zu verstehen, führte das Papier eine durch Ablationsstudie, bei der jedes Modul einzeln hinzugefügt wurde, um seine Wirkung zu bewerten. Wie in Abbildung 7 dargestellt, zeigen die Ablationsergebnisse, dass die Geometrie und die Erscheinungsqualität der generierten 3D-Objekte erheblich abnehmen, wenn CG-LoRA aus X-Dreamer ausgeschlossen wird. Darüber hinaus wirkt sich der fehlende AMA-Verlust von X-Dreamer auch nachteilig auf die Geometrie und die Wiedergabetreue der generierten 3D-Assets aus. Diese müssen neu geschrieben werden: Die Ablationsexperimente liefern wertvolle Untersuchungen zu den einzelnen Beiträgen von CG-LoRA- und AMA-Verlusten zur Verbesserung der Geometrie, des Erscheinungsbilds und der Gesamtqualität der erzeugten 3D-Objekte. Abbildung 7 Ablationsstudie von X-Dreamer. Der Zweck der Einführung von AMA-Verlust besteht darin, die Aufmerksamkeit während des Entrauschungsprozesses auf die Vordergrundobjekte zu lenken. Dies wird erreicht, indem die Aufmerksamkeitskarte des SD an der Rendering-Maske des 3D-Objekts ausgerichtet wird. Um die Wirksamkeit des AMA-Verlusts beim Erreichen dieses Ziels zu bewerten, vergleicht dieser Artikel die Aufmerksamkeitskarten von SD mit und ohne AMA-Verlust in den Phasen des Geometrielernens und des Aussehenslernens. Wie in Abbildung 8 dargestellt, kann dies beobachtet werden Das Hinzufügen von AMA Der Verlust verbessert nicht nur die Geometrie und das Erscheinungsbild der generierten 3D-Assets, sondern ermöglicht es SD auch, seine Aufmerksamkeit gezielt auf Vordergrundobjektbereiche zu richten. Die Visualisierungsergebnisse bestätigen die Wirksamkeit des AMA-Verlusts bei der Lenkung der SD-Aufmerksamkeit und verbessern dadurch die Qualität der Lernphasen für Geometrie und Aussehen sowie die Fokussierung von Vordergrundobjekten Was neu geschrieben werden muss, ist: Abbildung 8 zeigt das Aufmerksamkeit Visualisierungsergebnisse von Kraftdiagrammen, Rendermasken und gerenderten Bildern mit und ohne AMA-Verlust Diese Forschung stellt ein bahnbrechendes Framework namens X-Dreamer vor, das darauf abzielt, Text-zu-2D- und Text-zu-Domänenlücken zwischen 3D zu schließen Generierung zur Verbesserung der Text-zu-3D-Generierung. Um dieses Ziel zu erreichen, schlägt das Papier zunächst CG-LoRA vor, ein Modul, das dreidimensionale relevante Informationen (einschließlich richtungsbewusstem Text und Kameraparameter) in ein vorab trainiertes Stable Diffusion (SD)-Modell integriert. Auf diese Weise ist dieses Papier in der Lage, Informationen im Zusammenhang mit dem dreidimensionalen Bereich effektiv zu erfassen. Darüber hinaus entwirft dieser Artikel einen AMA-Verlust, um die SD-generierte Aufmerksamkeitskarte an der Renderingmaske des 3D-Objekts auszurichten. Das Hauptziel des AMA-Verlusts besteht darin, den Textfokus auf 3D-Modelle zu lenken, um Vordergrundobjekte zu generieren. Durch umfangreiche Experimente bewertet dieser Artikel umfassend die Wirksamkeit der vorgeschlagenen Methode und zeigt, dass X-Dreamer in der Lage ist, hochwertige und realistische 3D-Inhalte basierend auf vorgegebenen Textaufforderungen zu generieren , der zu einem Tetraedernetz
, der zu einem Tetraedernetz  gehört, trainieren wir
gehört, trainieren wir  , um zwei wichtige Größen vorherzusagen: den SDF-Wert
, um zwei wichtige Größen vorherzusagen: den SDF-Wert  und den Verformungsversatz
und den Verformungsversatz 
 . Um als Ellipsoid zu initialisieren, werden in diesem Artikel N Punkte abgetastet, die gleichmäßig innerhalb des Ellipsoids verteilt sind, und der entsprechende SDF-Wert
. Um als Ellipsoid zu initialisieren, werden in diesem Artikel N Punkte abgetastet, die gleichmäßig innerhalb des Ellipsoids verteilt sind, und der entsprechende SDF-Wert  berechnet. Anschließend wird der Verlust des mittleren quadratischen Fehlers (MSE) zur Optimierung verwendet
berechnet. Anschließend wird der Verlust des mittleren quadratischen Fehlers (MSE) zur Optimierung verwendet  . Dieser Optimierungsprozess stellt sicher, dass der DMTET effektiv so initialisiert wird, dass er einem 3D-Ellipsoid ähnelt. Die Formel für den MSE-Verlust lautet wie folgt:
. Dieser Optimierungsprozess stellt sicher, dass der DMTET effektiv so initialisiert wird, dass er einem 3D-Ellipsoid ähnelt. Die Formel für den MSE-Verlust lautet wie folgt: 


 bei einer zufällig ausgewählten Kameraposition c zu generieren. Anschließend wird die Normalkarte n in ein eingefrorenes stabiles Diffusionsmodell (SD) mit einer trainierbaren CG-LoRA-Einbettung eingegeben und die Parameter in
bei einer zufällig ausgewählten Kameraposition c zu generieren. Anschließend wird die Normalkarte n in ein eingefrorenes stabiles Diffusionsmodell (SD) mit einer trainierbaren CG-LoRA-Einbettung eingegeben und die Parameter in  werden unter Verwendung des SDS-Verlusts aktualisiert, der wie folgt definiert ist:
werden unter Verwendung des SDS-Verlusts aktualisiert, der wie folgt definiert ist: 
 stellt die Parameter von SD dar und
stellt die Parameter von SD dar und  ist das vorhergesagte Rauschen von SD unter einem gegebenen Rauschpegel t und Texteinbettung y. Darüber hinaus
ist das vorhergesagte Rauschen von SD unter einem gegebenen Rauschpegel t und Texteinbettung y. Darüber hinaus  , wobei
, wobei 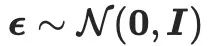 Rauschen darstellt, das aus einer Normalverteilung entnommen wurde. Die Implementierung von
Rauschen darstellt, das aus einer Normalverteilung entnommen wurde. Die Implementierung von  ,
,  und
und  basiert auf DreamFusion [4].
basiert auf DreamFusion [4]. 
 stellt die Anzahl der Aufmerksamkeitsschichten dar,
stellt die Anzahl der Aufmerksamkeitsschichten dar,  ist die Aufmerksamkeitskarte der i-ten Aufmerksamkeitsschicht. Mit der Funktion
ist die Aufmerksamkeitskarte der i-ten Aufmerksamkeitsschicht. Mit der Funktion  wird die Größe der gerenderten 3D-Objektmaske angepasst, um sicherzustellen, dass ihre Größe mit der Größe der Aufmerksamkeitskarte übereinstimmt.
wird die Größe der gerenderten 3D-Objektmaske angepasst, um sicherzustellen, dass ihre Größe mit der Größe der Aufmerksamkeitskarte übereinstimmt.  , einen Rauheits- und Metallizitätsterm
, einen Rauheits- und Metallizitätsterm  und einen Normaländerungsterm
und einen Normaländerungsterm  . Für jeden Punkt
. Für jeden Punkt 
 parametrisierte Multilayer-Perzeptron (MLP) verwendet, um drei Materialterme zu erhalten, die wie folgt ausgedrückt werden können:
parametrisierte Multilayer-Perzeptron (MLP) verwendet, um drei Materialterme zu erhalten, die wie folgt ausgedrückt werden können: 
 Stellt die Positionskodierung mithilfe der Hash-Grid-Technologie dar. Danach kann jedes Pixel des gerenderten Bildes mit der folgenden Formel berechnet werden:
Stellt die Positionskodierung mithilfe der Hash-Grid-Technologie dar. Danach kann jedes Pixel des gerenderten Bildes mit der folgenden Formel berechnet werden: 
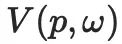 den Pixelwert des Punktes auf der Oberfläche des 3D-Objekts dar, der aus der Richtung
den Pixelwert des Punktes auf der Oberfläche des 3D-Objekts dar, der aus der Richtung 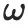
 gerendert wird.
gerendert wird.  stellt die Hemisphäre dar, die durch die Menge der Einfallsrichtungen definiert ist, die die Bedingung
stellt die Hemisphäre dar, die durch die Menge der Einfallsrichtungen definiert ist, die die Bedingung 
 erfüllen, wobei
erfüllen, wobei  die Einfallsrichtung und
die Einfallsrichtung und 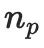 die Oberflächennormale am Punkt
die Oberflächennormale am Punkt  darstellt.
darstellt.  entspricht dem einfallenden Licht aus der vorgefertigten Umgebungskarte und
entspricht dem einfallenden Licht aus der vorgefertigten Umgebungskarte und  ist die bidirektionale Reflexionsverteilungsfunktion (BRDF), die sich auf die Materialeigenschaften (d. h.
ist die bidirektionale Reflexionsverteilungsfunktion (BRDF), die sich auf die Materialeigenschaften (d. h.  ) bezieht. Durch die Aggregation aller gerenderten Pixelfarben wird ein gerendertes Bild
) bezieht. Durch die Aggregation aller gerenderten Pixelfarben wird ein gerendertes Bild  erhalten. Ähnlich wie in der Geometrie-Lernphase wird das gerenderte Bild
erhalten. Ähnlich wie in der Geometrie-Lernphase wird das gerenderte Bild 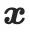 in SD eingespeist und mithilfe von SDS-Verlust und AMA-Verlust optimiert
in SD eingespeist und mithilfe von SDS-Verlust und AMA-Verlust optimiert  .
. 
 und Kameraparametern
und Kameraparametern  zunächst einen vortrainierten Text-CLIP-Encoder
zunächst einen vortrainierten Text-CLIP-Encoder  und ein trainierbares MLP
und ein trainierbares MLP  , um diese Eingaben in den Funktionsraum zu projizieren:
, um diese Eingaben in den Funktionsraum zu projizieren: 
 und
und 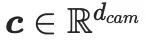 Textfunktionen bzw. Kamerafunktionen. Danach werden zwei Matrizen mit niedrigem Rang verwendet, um
Textfunktionen bzw. Kamerafunktionen. Danach werden zwei Matrizen mit niedrigem Rang verwendet, um  und
und  in eine trainierbare Dimensionsreduktionsmatrix in CG-LoRA zu projizieren:
in eine trainierbare Dimensionsreduktionsmatrix in CG-LoRA zu projizieren: 
 und
und  CG-LoRA sind von zweidimensionalen Reduktionsmatrizen. Die Funktion
CG-LoRA sind von zweidimensionalen Reduktionsmatrizen. Die Funktion 
 in
in  zu transformieren.
zu transformieren. 
 und
und  sind zwei Matrizen mit niedrigem Rang. Daher können sie in das Produkt zweier Matrizen zerlegt werden, um die trainierbaren Parameter in der Implementierung zu reduzieren, d
sind zwei Matrizen mit niedrigem Rang. Daher können sie in das Produkt zweier Matrizen zerlegt werden, um die trainierbaren Parameter in der Implementierung zu reduzieren, d  ist eine kleine Zahl (z. B. 4). Entsprechend der Zusammensetzung von LoRA wird die Dimensionserweiterungsmatrix
ist eine kleine Zahl (z. B. 4). Entsprechend der Zusammensetzung von LoRA wird die Dimensionserweiterungsmatrix  auf Null initialisiert, um sicherzustellen, dass das Modell mit dem Training mit den vorab trainierten Parametern von SD beginnt. Daher lautet die Feedforward-Prozessformel von CG-LoRA wie folgt:
auf Null initialisiert, um sicherzustellen, dass das Modell mit dem Training mit den vorab trainierten Parametern von SD beginnt. Daher lautet die Feedforward-Prozessformel von CG-LoRA wie folgt: 
 wobei die eingefrorenen Parameter des vorab trainierten SD-Modells darstellt und
wobei die eingefrorenen Parameter des vorab trainierten SD-Modells darstellt und  die Kaskadenoperation ist. Bei der Implementierung dieser Methode wird CG-LoRA in die lineare Einbettungsschicht des Aufmerksamkeitsmoduls in SD integriert, um Orientierungs- und Kamerainformationen effektiv zu erfassen.
die Kaskadenoperation ist. Bei der Implementierung dieser Methode wird CG-LoRA in die lineare Einbettungsschicht des Aufmerksamkeitsmoduls in SD integriert, um Orientierungs- und Kamerainformationen effektiv zu erfassen. 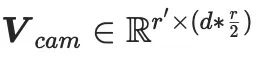
 Was neu zum Ausdruck gebracht werden muss, ist: Verlust der Aufmerksamkeitsmaskenausrichtung (AMA-Verlust)
Was neu zum Ausdruck gebracht werden muss, ist: Verlust der Aufmerksamkeitsmaskenausrichtung (AMA-Verlust) 

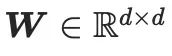 , um die Aufmerksamkeitskarte zu berechnen. Die Berechnungsformel lautet wie folgt:
, um die Aufmerksamkeitskarte zu berechnen. Die Berechnungsformel lautet wie folgt: 
 die Anzahl der Köpfe im Mehrkopf-Aufmerksamkeitsmechanismus dar,
die Anzahl der Köpfe im Mehrkopf-Aufmerksamkeitsmechanismus dar,  stellt die Aufmerksamkeitskarte dar und dann wird die Gesamtaufmerksamkeitskarte durch Mitteln der Aufmerksamkeitswerte der Aufmerksamkeitskarten berechnet
stellt die Aufmerksamkeitskarte dar und dann wird die Gesamtaufmerksamkeitskarte durch Mitteln der Aufmerksamkeitswerte der Aufmerksamkeitskarten berechnet  in allen Aufmerksamkeitsköpfen Der Wert von
in allen Aufmerksamkeitsköpfen Der Wert von  .
. 
 einen kleinen konstanten Wert darstellt (z. B.
einen kleinen konstanten Wert darstellt (z. B.  ), um zu verhindern, dass 0 im Nenner erscheint. Schließlich wird ein AMA-Verlust verwendet, um die Aufmerksamkeitskarten aller Aufmerksamkeitsebenen an der gerenderten Maske des 3D-Objekts auszurichten.
), um zu verhindern, dass 0 im Nenner erscheint. Schließlich wird ein AMA-Verlust verwendet, um die Aufmerksamkeitskarten aller Aufmerksamkeitsebenen an der gerenderten Maske des 3D-Objekts auszurichten. Experimentelle Ergebnisse





Das obige ist der detaillierte Inhalt vonX-Dreamer durchbricht die dimensionale Wand und bringt hochwertigen Text in die 3D-Generierung, indem es die Bereiche der 2D- und 3D-Generierung integriert.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Detaillierte Erläuterung der SQLORDSBY -Klausel: Die effiziente Sortierung der Datenreihenfolge -Klausel ist eine Schlüsselanweisung in SQL, die zur Sortierung von Abfrageergebnissen verwendet wird. Es kann in einzelnen Spalten oder mehreren Spalten in den Aufstieg (ASC) oder absteigender Reihenfolge (Desc) angeordnet werden, wodurch die Datenlesbarkeit und die Effizienz der Datenverwaltung erheblich verbessert werden. OrderBy syntax SelectColumn1, Spalte2, ... fromTable_NameOrDByColumn_Name [ASC | Desc]; Column_Name: Sortieren nach Spalte. ASC: Ascending Order Sort (Standard). Desc: Sortieren Sie in absteigender Reihenfolge. OrderBy Hauptmerkmale: Multi-Sortier-Sortierung: Unterstützt mehrere Spaltensortierungen, und die Reihenfolge der Spalten bestimmt die Priorität der Sortierung. seit
 Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Häufige Fehler und Lösungen beim Anschließen mit Datenbanken: Benutzername oder Kennwort (Fehler 1045) Firewall -Blocks -Verbindungsverbindung (Fehler 2003) Timeout (Fehler 10060) Die Verwendung von Socket -Verbindung kann nicht verwendet werden (Fehler 1042).
 So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
Mit der SQL -Insert -Anweisung wird eine Datenbanktabelle neue Zeilen hinzufügen, und ihre Syntax ist: Intable_Name (Spalte1, Spalte2, ..., Columnn) Werte (Value1, Value2, ..., Valuen);. Diese Anweisung unterstützt das Einfügen mehrerer Werte und ermöglicht es, Nullwerte in Spalten eingefügt zu werden. Es ist jedoch erforderlich, sicherzustellen, dass die eingefügten Werte mit dem Datentyp der Spalte kompatibel sind, um zu vermeiden, dass Einzigartigkeitsbeschränkungen verstoßen.
 Gibt es eine gespeicherte Prozedur in MySQL?
Apr 08, 2025 pm 03:45 PM
Gibt es eine gespeicherte Prozedur in MySQL?
Apr 08, 2025 pm 03:45 PM
MySQL bietet gespeicherte Prozeduren, die ein vorkompilierter SQL -Codeblock sind, der die komplexe Logik zusammenfasst, die Wiederverwendbarkeit und Sicherheit des Codes verbessert. Zu den Kernfunktionen gehören Schleifen, bedingte Aussagen, Cursoren und Transaktionskontrolle. Durch das Aufrufen gespeicherter Prozeduren können Benutzer Datenbankvorgänge ausführen, indem sie einfach eingeben und ausgeben, ohne auf interne Implementierungen zu achten. Es ist jedoch notwendig, auf häufige Probleme wie Syntaxfehler, Berechtigungsprobleme und Logikfehler zu achten und die Leistungsoptimierung und Best -Practice -Prinzipien zu befolgen.
