
 Technologie-Peripheriegeräte
KI
AAAI2024: Far3D – Innovative Idee zur direkten visuellen 3D-Zielerkennung von 150 m
Technologie-Peripheriegeräte
KI
AAAI2024: Far3D – Innovative Idee zur direkten visuellen 3D-Zielerkennung von 150 m
AAAI2024: Far3D – Innovative Idee zur direkten visuellen 3D-Zielerkennung von 150 m

Ich habe kürzlich eine aktuelle Studie zur reinen visuellen Umgebungswahrnehmung auf Arxiv gelesen. Diese Forschung basiert auf der PETR-Methodenreihe und konzentriert sich auf die Lösung des rein visuellen Wahrnehmungsproblems der Zielerkennung über große Entfernungen, wobei der Wahrnehmungsbereich auf 150 Meter erweitert wird. Die Methoden und Ergebnisse dieses Papiers haben für uns einen großen Referenzwert, daher habe ich versucht, es zu interpretieren
Originaltitel: Far3D: Expanding the Horizon for Surround-view 3D Object Detection
Papierlink: https://arxiv.org/abs /2308.09616
Zugehörigkeit des Autors: Beijing Institute of Technology & Megvii Technology

Aufgabenhintergrund
Die dreidimensionale Objekterkennung spielt eine wichtige Rolle beim Verständnis der dreidimensionalen Szene des autonomen Fahrens und dient der Präzision Lokalisieren und klassifizieren Sie Objekte rund um das Fahrzeug. Reine visuelle Umgebungswahrnehmungsmethoden zeichnen sich durch geringe Kosten und eine breite Anwendbarkeit aus und haben erhebliche Fortschritte gemacht. Die meisten von ihnen konzentrieren sich jedoch auf die Nahbereichserkennung (beispielsweise beträgt der Erfassungsabstand von nuScenes etwa 50 Meter), und der Bereich der Fernerkennung ist weniger erforscht. Die Erkennung entfernter Objekte ist entscheidend für die Einhaltung eines sicheren Abstands während der Fahrt, insbesondere bei hohen Geschwindigkeiten oder bei schwierigen Straßenverhältnissen.
In jüngster Zeit wurden erhebliche Fortschritte bei der 3D-Objekterkennung anhand von Rundumsichtbildern erzielt, die kostengünstig eingesetzt werden können. Die meisten Studien konzentrieren sich jedoch hauptsächlich auf die Erfassungsreichweite im Nahbereich, und es gibt weniger Studien zur Erfassung im Fernbereich. Die direkte Erweiterung vorhandener Methoden zur Abdeckung großer Entfernungen wird mit Herausforderungen wie hohen Rechenkosten und instabiler Konvergenz konfrontiert sein. Um diese Einschränkungen zu beheben, schlägt dieses Papier ein neues, auf spärlichen Abfragen basierendes Framework namens Far3D vor.
Idee für die Abschlussarbeit
Entsprechend der Zwischendarstellung können vorhandene Look-Around-Sensing-Methoden grob in zwei Kategorien unterteilt werden: Methoden, die auf der BEV-Darstellung basieren, und Methoden, die auf der Darstellung spärlicher Abfragen basieren. Die auf der BEV-Darstellung basierende Methode erfordert aufgrund der Notwendigkeit einer intensiven Berechnung der BEV-Merkmale einen sehr großen Rechenaufwand, was eine Ausweitung auf Langstreckenszenarien erschwert. Die auf einer spärlichen Abfragedarstellung basierende Methode lernt die globale 3D-Abfrage aus den Trainingsdaten, der Rechenaufwand ist relativ gering und sie weist eine starke Skalierbarkeit auf. Es weist jedoch auch einige Schwächen auf, obwohl die globale feste Abfrage nicht einfach an dynamische Szenen angepasst werden kann und Ziele bei der Erkennung über große Entfernungen häufig verfehlt werden Datensatz, 3D-Leistungsvergleich zwischen Erkennung und 2D-Erkennung.
Bei der Erkennung über große Entfernungen haben Methoden, die auf einer spärlichen Abfragedarstellung basieren, zwei Hauptherausforderungen. 
Das erste ist die schlechte Erinnerungsleistung. Aufgrund der geringen Verteilung der Abfragen im 3D-Raum kann in großen Entfernungen nur eine geringe Anzahl passender positiver Abfragen generiert werden. Wie in der Abbildung oben gezeigt, ist die Rückrufrate der 3D-Erkennung niedriger, während die Rückrufrate der vorhandenen 2D-Erkennung viel höher ist, sodass zwischen beiden ein deutlicher Leistungsunterschied besteht. Daher ist die Verwendung hochwertiger 2D-Objektpriors zur Verbesserung der 3D-Abfrage eine vielversprechende Methode, die sich positiv auf die präzise Positionierung und umfassende Abdeckung von Objekten auswirkt.
Zweitens führt die direkte Einführung von 2D-Erkennungsergebnissen zur Unterstützung der 3D-Erkennung zu dem Problem der Fehlerausbreitung. Wie in der folgenden Abbildung dargestellt, sind die beiden Hauptursachen 1) Objektpositionierungsfehler aufgrund einer ungenauen Tiefenvorhersage; 2) 3D-Positionsfehler bei der Kegelstumpftransformation, die mit zunehmender Entfernung zunehmen. Diese verrauschten Abfragen wirken sich auf die Stabilität des Trainings aus und erfordern zur Optimierung wirksame Entrauschungsmethoden. Darüber hinaus zeigt das Modell während des Trainings eine Tendenz zur Überanpassung an dicht besiedelte Objekte in der Nähe, während es dünn verteilte entfernte Objekte ignoriert.
- Um die oben genannten Probleme zu lösen, wird in diesem Artikel der folgende Entwurfsplan übernommen:
- Zusätzlich zur aus dem Datensatz erlernten globalen 3D-Abfrage wird auch eine aus den 2D-Erkennungsergebnissen generierte adaptive 3D-Abfrage eingeführt. Insbesondere werden der 2D-Detektor und das Tiefenvorhersagenetzwerk zunächst verwendet, um die 2D-Box und die entsprechende Tiefe zu erhalten, und dann durch räumliche Transformation als Initialisierung der adaptiven 3D-Abfrage in den 3D-Raum projiziert.
- Um sich an die unterschiedlichen Maßstäbe von Objekten in unterschiedlichen Entfernungen anzupassen, wurde die perspektivische Aggergation entwickelt. Es ermöglicht der 3D-Abfrage die Interaktion mit Features unterschiedlicher Maßstäbe, was für die Feature-Erfassung von Objekten in unterschiedlichen Entfernungen von Vorteil ist. Beispielsweise erfordern entfernte Objekte Merkmale mit hoher Auflösung, während nahe Objekte unterschiedliche Merkmale erfordern. Dieses Design ermöglicht es dem Modell, adaptiv mit Features zu interagieren.
- Entwickelte eine Strategie namens Range-modulated 3D Denoising, um das Problem der Ausbreitung von Abfragefehlern und der langsamen Konvergenz zu lindern. Da die Schwierigkeiten bei der Abfrageregression bei unterschiedlichen Entfernungen unterschiedlich sind, wird die verrauschte Abfrage entsprechend der Entfernung und dem Maßstab der realen Box angepasst. Geben Sie mehrere Sätze verrauschter Abfragen in der Nähe von GT in den Decoder ein, um die reale 3D-Box (für positive Proben) zu rekonstruieren und negative Proben zu verwerfen.
Hauptbeiträge
- In diesem Artikel wird ein neues, auf spärlichen Abfragen basierendes Erkennungsframework vorgeschlagen, das hochwertige 2D-Objekte verwendet, bevor eine adaptive 3D-Abfrage generiert wird, wodurch der Wahrnehmungsbereich der 3D-Erkennung erweitert wird.
- Dieser Artikel entwirft ein perspektivenbewusstes Aggregationsmodul, das visuelle Merkmale aus verschiedenen Maßstäben und Perspektiven aggregiert, sowie eine 3D-Rauschunterdrückungsstrategie basierend auf der Zielentfernung, um Probleme mit der Ausbreitung von Abfragefehlern und der Framework-Konvergenz zu lösen.
- Experimentelle Ergebnisse des Langstreckendatensatzes Argoverse 2 zeigen, dass Far3D frühere Look-Around-Methoden übertrifft und mehrere Lidar-basierte Methoden übertrifft. Und seine Allgemeingültigkeit wird anhand des nuScenes-Datensatzes überprüft.
Modelldesign
Far3D-Prozessübersicht:
- Geben Sie das Surround-Bild in das Backbone-Netzwerk und die FPN-Schicht ein, kodieren Sie die 2D-Bildmerkmale und kodieren Sie sie mit den Kameraparametern.
- Verwendet 2D-Detektoren und Tiefenvorhersagenetzwerke, um zuverlässige 2D-Objektkästen und ihre entsprechenden Tiefen zu generieren, die dann durch Kameratransformationen in den 3D-Raum projiziert werden.
- Die generierte adaptive 3D-Abfrage wird mit der anfänglichen globalen 3D-Abfrage kombiniert und von der Decoderschicht iterativ zurückgeführt, um die 3D-Objektbox vorherzusagen. Darüber hinaus kann das Modell eine Zeitreihenmodellierung durch langfristige Abfrageweitergabe implementieren.
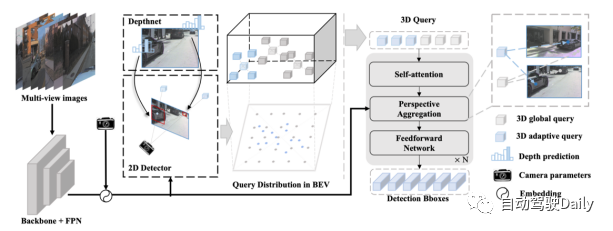
Perspektivbewusste Aggregation:
Um Multiskalenmerkmale in das Fernerkennungsmodell einzuführen, wendet dieser Artikel räumlich verformbare 3D-Aufmerksamkeit an. Es führt zunächst eine Offset-Abtastung in der Nähe der 3D-Position durch, die der Abfrage entspricht, und aggregiert dann Bildmerkmale durch 3D-2D-Ansichtstransformation. Der Vorteil dieser Methode gegenüber der globalen Aufmerksamkeit in der PETR-Reihe besteht darin, dass der Rechenaufwand deutlich reduziert werden kann. Konkret lernt das Modell für den Referenzpunkt jeder Abfrage im 3D-Raum M Abtastversätze um ihn herum und projiziert diese Versatzpunkte in verschiedene 2D-Ansichtsmerkmale.
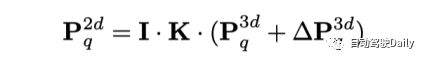
Anschließend interagiert die 3D-Abfrage mit den durch Projektion gewonnenen abgetasteten Features. Auf diese Weise werden verschiedene Merkmale aus unterschiedlichen Perspektiven und Maßstäben unter Berücksichtigung ihrer relativen Bedeutung zu einer dreidimensionalen Abfrage zusammengeführt.
Bereichsmodulierte 3D-Rauschunterdrückung:
3D-Abfragen mit unterschiedlichen Entfernungen haben unterschiedliche Regressionsschwierigkeiten, was sich von bestehenden 2D-Rauschunterdrückungsmethoden (wie DN-DETR, 2D-Abfragen, die normalerweise gleich behandelt werden) unterscheidet. Der Unterschied im Schwierigkeitsgrad ergibt sich aus der Dichte der Abfrageübereinstimmung und der Fehlerausbreitung. Einerseits ist der Grad der Abfrageübereinstimmung, der entfernten Objekten entspricht, niedriger als der von nahegelegenen Objekten. Andererseits werden bei der Einführung von 2D-Prioritäten in adaptive 3D-Abfragen kleine Fehler in 2D-Objektfeldern verstärkt, ganz zu schweigen davon, dass dieser Effekt mit zunehmender Objektentfernung zunimmt. Daher können einige Abfragen in der Nähe des GT-Felds als positive Abfragen betrachtet werden, während andere mit offensichtlichen Abweichungen als negative Abfragen betrachtet werden sollten. In diesem Artikel wird eine 3D-Rauschunterdrückungsmethode vorgeschlagen, die darauf abzielt, diese positiven Proben zu optimieren und negative Proben direkt zu verwerfen.
Konkret erstellen die Autoren GT-basierte verrauschte Abfragen, indem sie Gruppen positiver und negativer Stichproben gleichzeitig hinzufügen. Bei beiden Typen wird zufälliges Rauschen basierend auf der Position und Größe des Objekts angewendet, um das Entrauschen des Lernens bei der Fernwahrnehmung zu erleichtern. Konkret handelt es sich bei positiven Stichproben um zufällige Punkte innerhalb der 3D-Box, während negative Stichproben dem GT einen größeren Versatz auferlegen und sich der Versatzbereich mit der Entfernung des Objekts ändert. Mit dieser Methode können während des Trainings verrauschte Kandidaten-Positiv- und falsch-Positiv-Proben simuliert werden. Und nachdem das Modell skaliert wurde, kann es die Leistung mehrerer Lidar-basierter Methoden erreichen und so das Potenzial rein visueller Methoden demonstrieren.
Um die Generalisierungsleistung zu überprüfen, führte der Autor auch Experimente mit dem nuScenes-Datensatz durch und zeigte, dass er sowohl beim Validierungssatz als auch beim Testsatz eine SoTA-Leistung erreichte.
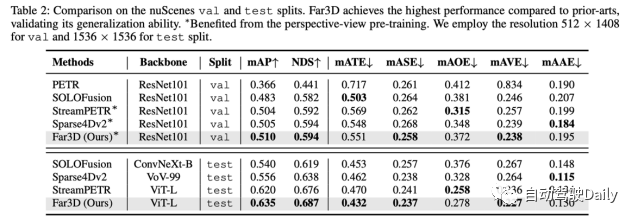
Nach Ablationsexperimenten kamen wir zu folgendem Schluss: 3D-adaptive Abfrage, perspektivbezogene Aggregation und bereichsangepasste 3D-Rauschunterdrückung haben jeweils einen gewissen Gewinn

Gedanken zum Papier
F : Was ist die Neuheit dieses Artikels?
A: Die Hauptneuheit besteht darin, das Problem der Wahrnehmung von Fernszenen zu lösen. Bei der Ausweitung bestehender Methoden auf Langstreckenszenarien gibt es viele Probleme, einschließlich Rechenkosten und Konvergenzschwierigkeiten. Die Autoren dieses Artikels schlagen einen effizienten Rahmen für diese Aufgabe vor. Obwohl jedes Modul einzeln bekannt vorkommt, dienen sie alle der Erkennung weit entfernter Ziele und haben klare Ziele.
F: Was sind die Unterschiede zwischen MV2D und BevFormer v2?
A: MV2D verlässt sich hauptsächlich auf 2D-Anker, um die entsprechenden Funktionen zum Binden von 3D zu erhalten, es gibt jedoch keine explizite Tiefenschätzung, sodass die Unsicherheit für entfernte Objekte relativ groß ist und es dann hauptsächlich schwierig ist, BevFormer v2 zu konvergieren Behebt die Domänenlücke zwischen dem 2D-Backbone und der 3D-Aufgabenszene. Im Allgemeinen ist das für die 2D-Erkennungsaufgabe vorab trainierte Backbone nicht in der Lage, die 3D-Szene zu erkennen, und untersucht die Probleme bei Fernaufgaben nicht.
F: Kann das Timing verbessert werden, z. B. die Weitergabe von Abfragen plus Feature-Weitergabe?
A: Theoretisch ist es machbar, bei praktischen Anwendungen sollte jedoch ein Kompromiss zwischen Leistung und Effizienz in Betracht gezogen werden.
F: Gibt es Bereiche, die verbessert werden müssen?
A: Sowohl Long-Tail-Probleme als auch langfristige Bewertungsindikatoren verdienen eine Verbesserung. Auf einem 26-Klassen-Ziel wie Argoverse 2 schneiden Modelle bei Long-Tail-Klassen nicht gut ab und verringern letztendlich die durchschnittliche Genauigkeit, was noch nicht untersucht wurde. Andererseits ist die Verwendung einheitlicher Metriken zur Bewertung entfernter und naher Objekte möglicherweise nicht angemessen, was die Notwendigkeit praktischer dynamischer Bewertungskriterien unterstreicht, die an verschiedene Szenarien in der realen Welt angepasst werden können.

Originallink: https://mp.weixin.qq.com/s/xxaaYQsjuWzMI7PnSmuaWg
Das obige ist der detaillierte Inhalt vonAAAI2024: Far3D – Innovative Idee zur direkten visuellen 3D-Zielerkennung von 150 m. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Lösung für i7-7700, kein Upgrade auf Windows 11 möglich
Dec 26, 2023 pm 06:52 PM
Lösung für i7-7700, kein Upgrade auf Windows 11 möglich
Dec 26, 2023 pm 06:52 PM
Die Leistung des i77700 reicht völlig aus, um Win11 auszuführen, aber Benutzer stellen fest, dass ihr i77700 nicht auf Win11 aktualisiert werden kann. Dies ist hauptsächlich auf die von Microsoft auferlegten Einschränkungen zurückzuführen, sodass sie es installieren können, solange sie diese Einschränkung überspringen. i77700 kann nicht auf win11 aktualisiert werden: 1. Weil Microsoft die CPU-Version begrenzt. 2. Nur die Intel-Versionen der achten Generation und höher können direkt auf Win11 aktualisiert werden. 3. Als 7. Generation kann der i77700 die Upgrade-Anforderungen von Win11 nicht erfüllen. 4. Der i77700 ist jedoch hinsichtlich der Leistung durchaus in der Lage, Win11 reibungslos zu nutzen. 5. Sie können also das Win11-Direktinstallationssystem dieser Site verwenden. 6. Nachdem der Download abgeschlossen ist, klicken Sie mit der rechten Maustaste auf die Datei und „laden“ sie. 7. Doppelklicken Sie, um den „One-Click“-Vorgang auszuführen
 Die Sturzerkennung basiert auf der Erkennung menschlicher Skelettpunkte. Ein Teil des Codes wird mit Chatgpt vervollständigt
Apr 12, 2023 am 08:19 AM
Die Sturzerkennung basiert auf der Erkennung menschlicher Skelettpunkte. Ein Teil des Codes wird mit Chatgpt vervollständigt
Apr 12, 2023 am 08:19 AM
Hallo zusammen. Heute möchte ich Ihnen ein Projekt zur Sturzerkennung vorstellen. Genauer gesagt handelt es sich um die Erkennung menschlicher Bewegungen auf der Grundlage von Skelettpunkten. Es ist grob in drei Schritte unterteilt: Erkennung des menschlichen Körpers, Punktaktionsklassifizierung des menschlichen Skeletts. Der Quellcode des Projekts wurde gepackt. Informationen zum Erhalt finden Sie am Ende des Artikels. 0. chatgpt Zuerst müssen wir den überwachten Videostream abrufen. Dieser Code ist relativ fest. Wir können chatgpt den von chatgpt geschriebenen Code direkt vervollständigen lassen. Wenn es jedoch später um geschäftliche Aufgaben geht, beispielsweise die Verwendung von Mediapipe zur Identifizierung menschlicher Skelettpunkte, ist der von chatgpt bereitgestellte Code falsch. Ich denke, dass chatgpt als Toolbox verwendet werden kann, die unabhängig von der Geschäftslogik sein kann. Sie können versuchen, es an c zu übergeben
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Das neueste Meisterwerk des MIT: Verwendung von GPT-3.5 zur Lösung des Problems der Erkennung von Zeitreihenanomalien
Jun 08, 2024 pm 06:09 PM
Das neueste Meisterwerk des MIT: Verwendung von GPT-3.5 zur Lösung des Problems der Erkennung von Zeitreihenanomalien
Jun 08, 2024 pm 06:09 PM
Heute möchte ich Ihnen einen letzte Woche vom MIT veröffentlichten Artikel vorstellen, in dem GPT-3.5-turbo verwendet wird, um das Problem der Erkennung von Zeitreihenanomalien zu lösen, und zunächst die Wirksamkeit von LLM bei der Erkennung von Zeitreihenanomalien überprüft wird. Im gesamten Prozess gibt es keine Feinabstimmung, und GPT-3.5-Turbo wird direkt zur Anomalieerkennung verwendet. Der Kern dieses Artikels besteht darin, wie man Zeitreihen in Eingaben umwandelt, die von GPT-3.5-Turbo erkannt werden können, und wie man sie entwirft Eingabeaufforderungen oder Pipelines, damit LLM die Anomalieerkennungsaufgabe lösen kann. Lassen Sie mich Ihnen diese Arbeit im Detail vorstellen. Titel des Bildpapiers: Largelingualmodelscanbezero-shotanomalydete
 Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Oct 16, 2023 am 11:33 AM
Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Oct 16, 2023 am 11:33 AM
1 Einleitung Neural Radiation Fields (NeRF) sind ein relativ neues Paradigma im Bereich Deep Learning und Computer Vision. Diese Technologie wurde im ECCV2020-Papier „NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis“ (das mit dem Best Paper Award ausgezeichnet wurde) vorgestellt und erfreut sich seitdem mit bisher fast 800 Zitaten äußerster Beliebtheit [1]. Der Ansatz markiert einen grundlegenden Wandel in der traditionellen Art und Weise, wie maschinelles Lernen 3D-Daten verarbeitet. Darstellung neuronaler Strahlungsfelder und differenzierbarer Rendering-Prozess: Zusammengesetzte Bilder durch Abtasten von 5D-Koordinaten (Position und Blickrichtung) entlang der Kamerastrahlen, Eingabe dieser Positionen in ein MLP, um mithilfe volumetrischer Rendering-Techniken Bilder zu erzeugen; ; Die Rendering-Funktion ist differenzierbar und kann daher übergeben werden
 Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Jun 02, 2024 pm 03:24 PM
Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Jun 02, 2024 pm 03:24 PM
Eine rein visuelle Annotationslösung nutzt hauptsächlich die visuelle Darstellung sowie einige Daten von GPS, IMU und Radgeschwindigkeitssensoren für die dynamische Annotation. Für Massenproduktionsszenarien muss es sich natürlich nicht nur um visuelle Aspekte handeln. Einige in Massenproduktion hergestellte Fahrzeuge verfügen über Sensoren wie Festkörperradar (AT128). Wenn wir aus Sicht der Massenproduktion einen geschlossenen Datenkreislauf erstellen und alle diese Sensoren verwenden, können wir das Problem der Kennzeichnung dynamischer Objekte effektiv lösen. Aber in unserem Plan gibt es kein Festkörperradar. Aus diesem Grund stellen wir diese gängigste Etikettierungslösung für die Massenproduktion vor. Der Kern einer rein visuellen Annotationslösung liegt in der hochpräzisen Posenrekonstruktion. Wir verwenden das Posenrekonstruktionsschema von Structure from Motion (SFM), um die Genauigkeit der Rekonstruktion sicherzustellen. Aber pass
 Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
01Ausblicksübersicht Derzeit ist es schwierig, ein angemessenes Gleichgewicht zwischen Detektionseffizienz und Detektionsergebnissen zu erreichen. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird. 02 Hintergrund und Motivation Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Objekterkennung bei der Interpretation von Fernerkundungsbildern
 Werfen Sie einen Blick auf die Vergangenheit und Gegenwart von Occ und autonomem Fahren! Die erste Rezension fasst die drei Hauptthemen Funktionserweiterung/Massenproduktionsbereitstellung/effiziente Annotation umfassend zusammen.
May 08, 2024 am 11:40 AM
Werfen Sie einen Blick auf die Vergangenheit und Gegenwart von Occ und autonomem Fahren! Die erste Rezension fasst die drei Hauptthemen Funktionserweiterung/Massenproduktionsbereitstellung/effiziente Annotation umfassend zusammen.
May 08, 2024 am 11:40 AM
Oben geschrieben und persönliches Verständnis des Autors In den letzten Jahren hat autonomes Fahren aufgrund seines Potenzials, die Belastung des Fahrers zu verringern und die Fahrsicherheit zu verbessern, zunehmende Aufmerksamkeit erhalten. Die visionsbasierte dreidimensionale Belegungsvorhersage ist eine neue Wahrnehmungsaufgabe, die sich für eine kostengünstige und umfassende Untersuchung der Sicherheit autonomen Fahrens eignet. Obwohl viele Studien die Überlegenheit von 3D-Belegungsvorhersagetools im Vergleich zu objektzentrierten Wahrnehmungsaufgaben gezeigt haben, gibt es immer noch Rezensionen, die diesem sich schnell entwickelnden Bereich gewidmet sind. In diesem Artikel wird zunächst der Hintergrund der visionsbasierten 3D-Belegungsvorhersage vorgestellt und die bei dieser Aufgabe auftretenden Herausforderungen erörtert. Als nächstes diskutieren wir umfassend den aktuellen Status und die Entwicklungstrends aktueller 3D-Belegungsvorhersagemethoden unter drei Gesichtspunkten: Funktionsverbesserung, Bereitstellungsfreundlichkeit und Kennzeichnungseffizienz. zu guter Letzt
