
 Technologie-Peripheriegeräte
KI
Systemforschung enthüllt unverzichtbares Großmodell für autonomes Fahrsystem der nächsten Generation
Technologie-Peripheriegeräte
KI
Systemforschung enthüllt unverzichtbares Großmodell für autonomes Fahrsystem der nächsten Generation
Systemforschung enthüllt unverzichtbares Großmodell für autonomes Fahrsystem der nächsten Generation

Mit dem Aufkommen großer Sprachmodelle (LLM) und visueller Basismodelle (VFM) wird erwartet, dass multimodale künstliche Intelligenzsysteme mit großen Modellen die reale Welt umfassend wahrnehmen und Entscheidungen wie Menschen treffen können. In den letzten Monaten hat LLM im Bereich der autonomen Fahrforschung große Aufmerksamkeit erregt. Trotz des großen Potenzials von LLM gibt es immer noch wichtige Herausforderungen, Chancen und zukünftige Forschungsrichtungen bei Fahrsystemen, die derzeit nicht detailliert erläutert werden.
In diesem Artikel wurden Untersuchungen von Tencent Maps, Purdue University, UIUC und University of Virginia Personnel durchgeführt systematische Forschung auf diesem Gebiet. Diese Studie stellt zunächst den Hintergrund multimodaler großer Sprachmodelle (MLLM), den Fortschritt der Entwicklung multimodaler Modelle mithilfe von LLM und einen Rückblick auf die Geschichte des autonomen Fahrens vor. Anschließend bietet die Studie einen Überblick über bestehende MLLM-Tools für Fahr-, Verkehrs- und Kartensysteme sowie bestehende Datensätze. Die Studie fasst auch verwandte Arbeiten des 1. WACV-Workshops zu großen Sprach- und Bildmodellen für autonomes Fahren (LLVM-AD) zusammen, dem ersten Workshop zur Anwendung von LLM beim autonomen Fahren. Um die Entwicklung dieses Bereichs weiter voranzutreiben, werden in dieser Studie auch die Anwendung von MLLM in autonomen Fahrsystemen und einige wichtige Probleme erörtert, die von Wissenschaft und Industrie gelöst werden müssen.

- Rezensionslink: https://arxiv.org/abs/2311.12320
- Workshop-Link: https://llvm-ad.github.io/ Hub-Link : https://github.com/IrohXu/Awesome-Multimodal-LLM-Autonomous-Driving Das Modell kombiniert die Inferenzfähigkeiten von LLM mit Bild-, Video- und Audiodaten und ermöglicht es diesen Daten, durch multimodale Ausrichtung, einschließlich Bildklassifizierung, Ausrichtung von Text mit entsprechenden Videos und Spracherkennung, verschiedene Aufgaben effizienter auszuführen. Darüber hinaus haben einige Studien gezeigt, dass LLM einfache Aufgaben im Bereich der Robotik bewältigen kann. Derzeit schreitet die Integration von MLLM jedoch langsam voran. Gibt es Potenzial zur Verbesserung bestehender autonomer Fahrsysteme? GPT-4, PaLM-2 und LLMs wie LLaMA-2 müssen noch weiter erforscht und erforscht werden
- In dieser Übersicht glauben Forscher, dass die Integration von LLMs in den Bereich des autonomen Fahrens einen bedeutenden Paradigmenwechsel bewirken und dadurch die Fahrwahrnehmung verbessern kann , Bewegungsplanung und Mensch-Fahrzeug-Interaktion und Bewegungssteuerung, um Benutzern anpassungsfähigere und zuverlässigere zukünftige Transportlösungen zu bieten. Im Hinblick auf die Wahrnehmung kann LLM Tool Learning verwenden, um externe APIs aufzurufen, um auf Echtzeit-Informationsquellen wie hochpräzise Karten, Verkehrsberichte und Wetterinformationen zuzugreifen, sodass das Fahrzeug die Umgebung umfassender verstehen kann. Selbstfahrende Autos können durch LLM über überlastete Strecken nachdenken und alternative Wege vorschlagen, um die Effizienz und das sichere Fahren zu verbessern. Im Hinblick auf Bewegungsplanung und Mensch-Fahrzeug-Interaktion kann LLM eine benutzerzentrierte Kommunikation fördern und es den Fahrgästen ermöglichen, ihre Bedürfnisse und Vorlieben in der Alltagssprache auszudrücken. Im Hinblick auf die Bewegungssteuerung ermöglicht LLM zunächst die Anpassung der Steuerparameter an die Vorlieben des Fahrers und ermöglicht so ein personalisiertes Fahrerlebnis. Darüber hinaus kann LLM dem Benutzer Transparenz bieten, indem es jeden Schritt des Bewegungssteuerungsprozesses erklärt. Die Überprüfung geht davon aus, dass Passagiere in künftigen autonomen Fahrzeugen der Stufen SAE L4–L5 Sprache, Gesten und sogar Augen verwenden können, um ihre Wünsche zu kommunizieren, wobei MLLM über integrierte visuelle Anzeigen oder Sprachantworten Echtzeit-Feedback im Auto und beim Fahren liefert Entwicklungsprozess des autonomen Fahrens und multimodaler großer Sprachmodelle
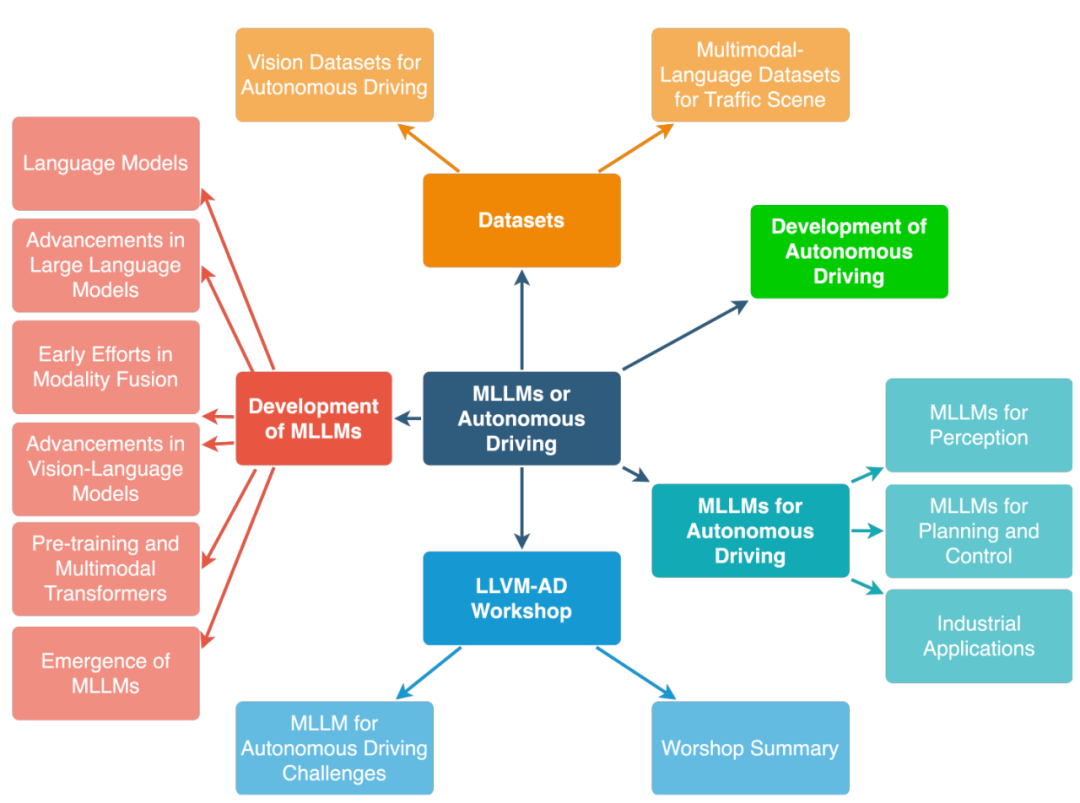
Forschungszusammenfassung zum autonomen Fahren MLLM: Das LLM-Framework des aktuellen Modells umfasst hauptsächlich LLAMA und LLAMA 2. GPT-3.5, GPT-4 , Flan5XXL, Vicuna-13b. FT, ICL und PT beziehen sich in dieser Tabelle auf Feinabstimmung, kontextbezogenes Lernen und Vortraining. Literaturlinks finden Sie im Github-Repo: https://github.com/IrohXu/Awesome-Multimodal-LLM-Autonomous-Driving
Um eine Brücke zwischen autonomem Fahren und LLVM zu schlagen, organisierten relevante Forscher den ersten Large Language and Vision Model Autonomous Driving Workshop (LLVM-AD) auf der IEEE/CVF Winter Conference on Computer Vision Applications (WACV) 2024. Ziel dieses Workshops ist es, die Zusammenarbeit zwischen akademischen Forschern und Fachleuten aus der Industrie zu verbessern, um die Möglichkeiten und Herausforderungen der Implementierung multimodaler groß angelegter Sprachmodelle im Bereich des autonomen Fahrens zu erkunden. LLVM-AD wird die Entwicklung nachfolgender Open-Source-Datensätze zum Verständnis tatsächlicher Verkehrssprache weiter vorantreiben
Der erste WACV Large-scale Language and Vision Model Autonomous Driving Workshop (LLVM-AD) nahm insgesamt neun Beiträge an. Einige dieser Arbeiten drehen sich um multimodale große Sprachmodelle im autonomen Fahren und konzentrieren sich auf die Integration von LLM in die Benutzer-Fahrzeug-Interaktion, Bewegungsplanung und Fahrzeugsteuerung. In mehreren Artikeln werden auch neue Anwendungen von LLM für menschenähnliche Interaktion und Entscheidungsfindung in autonomen Fahrzeugen untersucht. Beispielsweise untersuchen „Imitating Human Driving“ und „Driving by Language“ die Interpretation und Argumentation von LLM in komplexen Fahrszenarien sowie Rahmenbedingungen für die Nachahmung menschlichen Verhaltens. Darüber hinaus legt „Menschzentrierte autonome Systeme und LLM“ Wert darauf, den Benutzer in den Mittelpunkt des LLM-Designs zu stellen und LLM zur Interpretation von Benutzeranweisungen zu verwenden. Dieser Ansatz stellt einen wichtigen Wandel hin zu menschenzentrierten autonomen Systemen dar. Zusätzlich zum kombinierten LLM behandelte der Workshop auch einige reine Bildverarbeitungs- und Datenverarbeitungsmethoden. Darüber hinaus wurden im Workshop innovative Datenverarbeitungs- und Auswertungsmethoden vorgestellt. NuScenes-MQA führt beispielsweise ein neues Annotationsschema für autonome Fahrdatensätze ein. Zusammengenommen zeigen diese Arbeiten Fortschritte bei der Integration von Sprachmodellen und fortschrittlichen Techniken in das autonome Fahren und ebnen den Weg für intuitivere, effizientere und menschzentrierte autonome Fahrzeuge
Für zukünftige Entwicklungen schlägt diese Studie die folgenden Forschungsrichtungen vor:
Der Inhalt, der neu geschrieben werden muss, ist: 1. Neue Datensätze für multimodale große Sprachmodelle beim autonomen Fahren
Obwohl große Sprachmodelle in der Sprache verwendet werden, gab es Erfolge beim Verständnis, aber auch Herausforderungen Wir bleiben dabei, es auf das autonome Fahren anzuwenden. Dies liegt daran, dass diese Modelle Eingaben aus verschiedenen Modalitäten, wie Panoramabildern, 3D-Punktwolken und hochpräzisen Karten, integrieren und verstehen müssen. Aufgrund der derzeitigen Einschränkungen in Bezug auf Datengröße und -qualität können die vorhandenen Datensätze diese Herausforderungen nicht vollständig bewältigen. Darüber hinaus bieten visuelle Sprachdatensätze, die aus frühen Open-Source-Datensätzen wie NuScenes annotiert wurden, möglicherweise keine solide Grundlage für das visuelle Sprachverständnis in Fahrszenarien. Daher besteht ein dringender Bedarf an neuen, umfangreichen Datensätzen, die ein breites Spektrum an Verkehrs- und Fahrszenarien abdecken, um das Long-Tail-Problem (Ungleichgewicht) früherer Datensatzverteilungen zu beheben und die Leistung dieser Modelle effektiv zu testen und zu verbessern autonome Fahranwendungen.
2. Hardwareunterstützung für große Sprachmodelle im autonomen Fahren erforderlich
Unterschiedliche Funktionen in autonomen Fahrzeugen haben unterschiedliche Hardwareanforderungen. Der Einsatz von LLM in einem Fahrzeug zur Fahrplanung oder zur Beteiligung an der Fahrzeugsteuerung erfordert Echtzeitverarbeitung und geringe Latenz, um die Sicherheit zu gewährleisten, was den Rechenaufwand erhöht und sich auf den Stromverbrauch auswirkt. Wird LLM in der Cloud eingesetzt, wird die Bandbreite für den Datenaustausch zu einem weiteren kritischen Sicherheitsfaktor. Im Gegensatz dazu erfordert die Verwendung von LLM für die Navigationsplanung oder die Analyse von Befehlen, die nichts mit dem Fahren zu tun haben (z. B. Musikwiedergabe im Auto), kein hohes Abfragevolumen und keine Echtzeitleistung, sodass Remote-Dienste eine praktikable Option sind. Zukünftig kann LLM im autonomen Fahren durch Wissensdestillation komprimiert werden, um den Rechenaufwand und die Latenz zu reduzieren. In diesem Bereich gibt es noch viel Raum für Entwicklung.
3. Verwenden Sie große Sprachmodelle, um hochpräzise Karten zu verstehen.
Hochpräzise Karten spielen eine wichtige Rolle in der autonomen Fahrzeugtechnologie, da sie grundlegende Informationen über die physische Umgebung liefern, in der das Fahrzeug betrieben wird. Die semantische Kartenebene in HD-Karten ist wichtig, da sie die Bedeutung und Kontextinformationen der physischen Umgebung erfasst. Um diese Informationen effektiv in die nächste Generation des autonomen Fahrens zu kodieren, das durch Tencents hochpräzises automatisches Karten-KI-Annotationssystem angetrieben wird, sind neue Modelle erforderlich, um diese multimodalen Merkmale im Sprachraum abzubilden. Tencent hat das hochpräzise automatische KI-Beschriftungssystem für Karten THMA entwickelt, das auf aktivem Lernen basiert und hochpräzise Karten im Maßstab von Hunderttausenden Kilometern erstellen und beschriften kann. Um die Entwicklung dieses Bereichs voranzutreiben, schlug Tencent den auf THMA basierenden MAPLM-Datensatz vor, der Panoramabilder, 3D-Lidar-Punktwolken und kontextbasierte hochpräzise Kartenanmerkungen sowie einen neuen Frage- und Antwort-Benchmark MAPLM-QA enthält
4. Großes Sprachmodell in der Mensch-Fahrzeug-Interaktion
Die Mensch-Fahrzeug-Interaktion und das Verständnis des menschlichen Fahrverhaltens stellen auch beim autonomen Fahren eine große Herausforderung dar. Menschliche Fahrer verlassen sich häufig auf nonverbale Signale, etwa auf das Verlangsamen, um nachzugeben, oder auf die Nutzung von Körperbewegungen, um mit anderen Fahrern oder Fußgängern zu kommunizieren. Diese nonverbalen Signale spielen eine entscheidende Rolle bei der Kommunikation im Straßenverkehr. In der Vergangenheit kam es zu vielen Unfällen mit selbstfahrenden Systemen, weil selbstfahrende Autos sich oft anders verhielten, als andere Autofahrer erwartet hätten. Zukünftig wird MLLM in der Lage sein, umfangreiche Kontextinformationen aus verschiedenen Quellen zu integrieren und den Blick, die Gesten und den Fahrstil eines Fahrers zu analysieren, um diese sozialen Signale besser zu verstehen und eine effiziente Planung zu ermöglichen. Durch die Schätzung der sozialen Signale anderer Fahrer kann LLM die Entscheidungsfähigkeit und die Gesamtsicherheit autonomer Fahrzeuge verbessern.
Personalisiertes autonomes Fahren
Bei der Entwicklung autonomer Fahrzeuge ist ein wichtiger Aspekt die Überlegung, wie sie sich an die individuellen Fahrpräferenzen des Benutzers anpassen. Es besteht ein wachsender Konsens darüber, dass selbstfahrende Autos den Fahrstil ihrer Benutzer nachahmen sollten. Um dies zu erreichen, müssen autonome Fahrsysteme Benutzerpräferenzen in verschiedenen Aspekten wie Navigation, Fahrzeugwartung und Unterhaltung lernen und integrieren. Dank der Möglichkeiten zur Abstimmung von Anweisungen und kontextbezogenen Lernfunktionen eignet sich LLM ideal für die Integration von Benutzerpräferenzen und Informationen zum Fahrverlauf in autonome Fahrzeuge, um ein personalisiertes Fahrerlebnis zu bieten.
Zusammenfassung
Autonomes Fahren steht seit vielen Jahren im Mittelpunkt der Aufmerksamkeit und zog viele Risikokapitalgeber an. Die Integration von LLM in autonome Fahrzeuge stellt einzigartige Herausforderungen dar, deren Bewältigung jedoch die bestehenden autonomen Systeme erheblich verbessern wird. Es ist absehbar, dass durch LLM unterstützte intelligente Cockpits in der Lage sind, Fahrszenarien und Benutzerpräferenzen zu verstehen und ein tieferes Vertrauen zwischen dem Fahrzeug und den Insassen aufzubauen. Darüber hinaus werden autonome Fahrsysteme, die LLM einsetzen, besser in der Lage sein, ethische Dilemmata zu bewältigen, bei denen es um die Abwägung der Sicherheit von Fußgängern und der Sicherheit von Fahrzeuginsassen geht, und so einen Entscheidungsprozess fördern, der in komplexen Fahrszenarien eher ethisch ist. Dieser Artikel integriert Erkenntnisse der Mitglieder des WACV 2024 LLVM-AD-Workshop-Komitees und soll Forscher dazu inspirieren, zur Entwicklung autonomer Fahrzeuge der nächsten Generation mit LLM-Technologie beizutragen.
Das obige ist der detaillierte Inhalt vonSystemforschung enthüllt unverzichtbares Großmodell für autonomes Fahrsystem der nächsten Generation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
