
 Technologie-Peripheriegeräte
KI
Vollständiger Testbericht zu Gemini: Von CMU zu GPT 3.5 Turbo verliert Gemini Pro
Technologie-Peripheriegeräte
KI
Vollständiger Testbericht zu Gemini: Von CMU zu GPT 3.5 Turbo verliert Gemini Pro
Vollständiger Testbericht zu Gemini: Von CMU zu GPT 3.5 Turbo verliert Gemini Pro

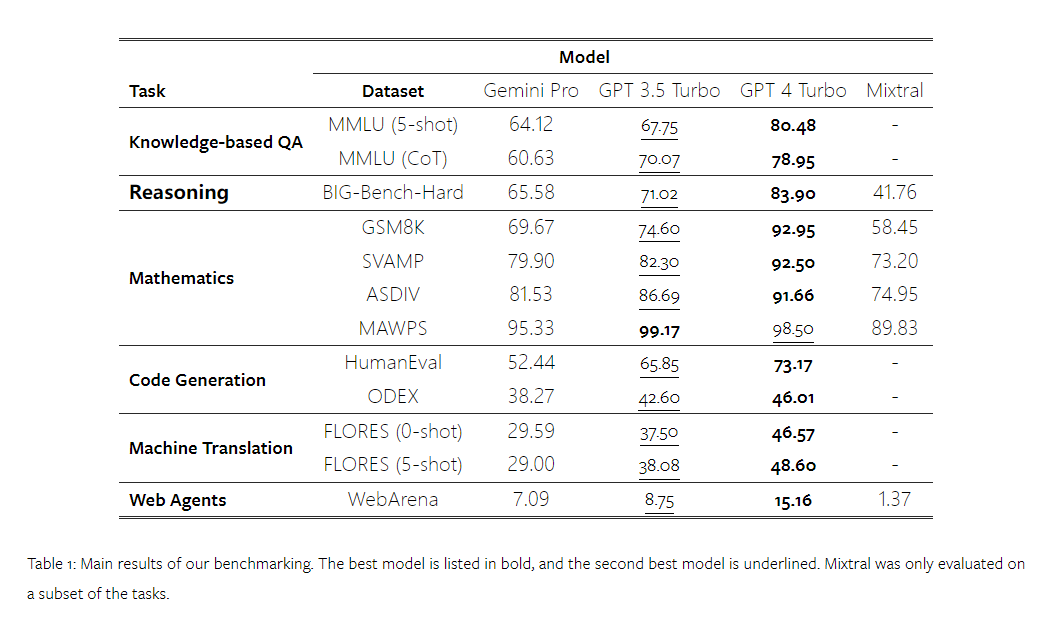
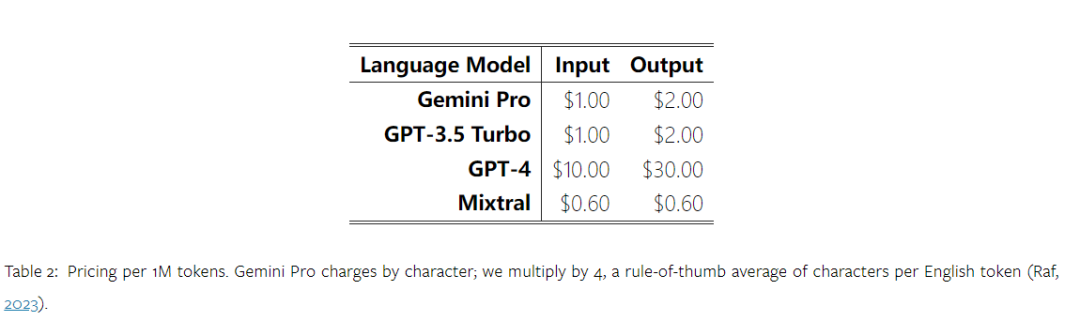
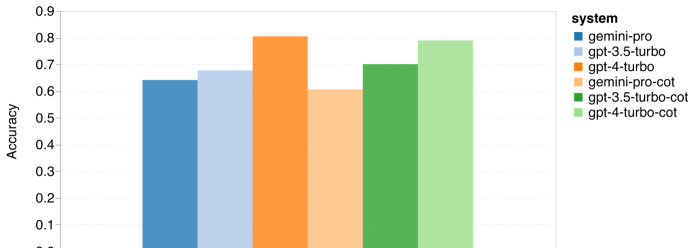
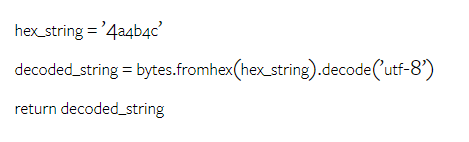
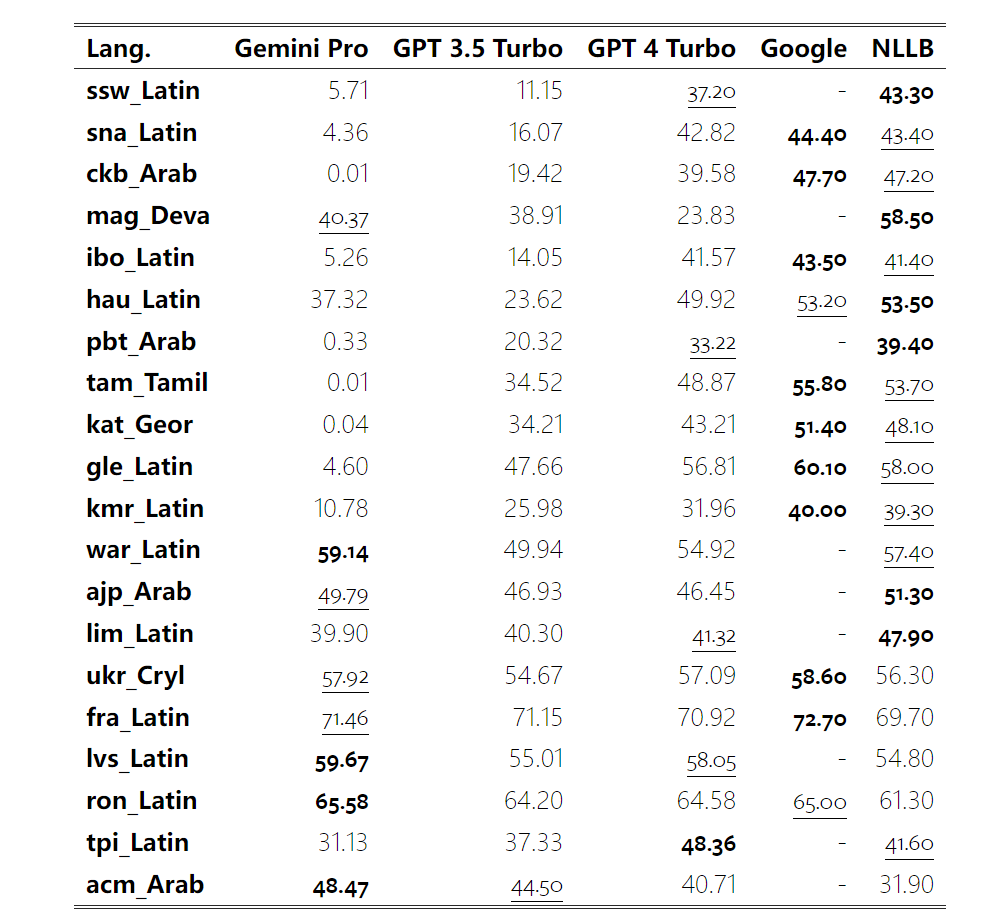
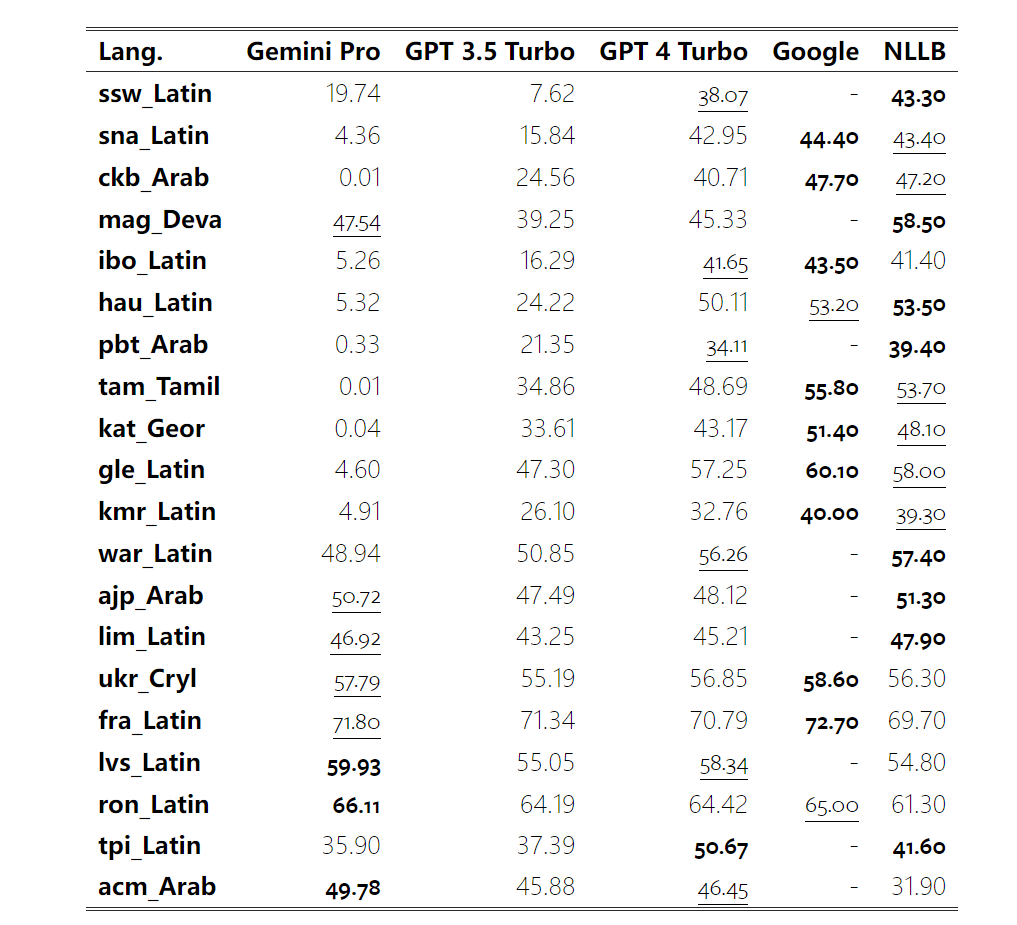
Wie viel wiegt Googles Gemini? Wie ist der Vergleich mit dem GPT-Modell von OpenAI? Dieses CMU-Papier hat eindeutige Messergebnisse

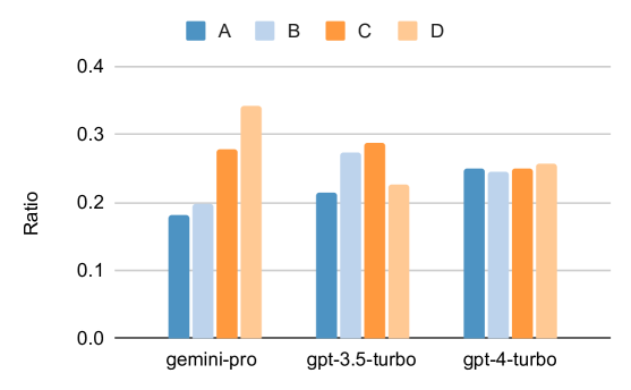
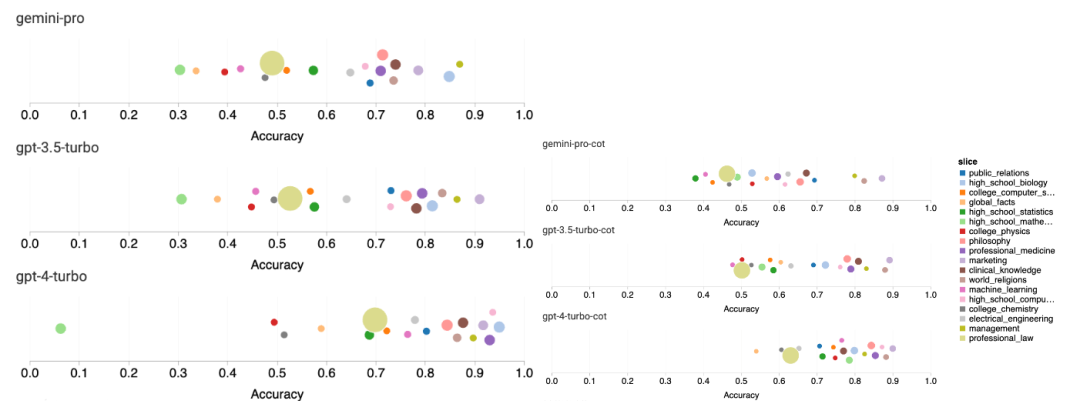
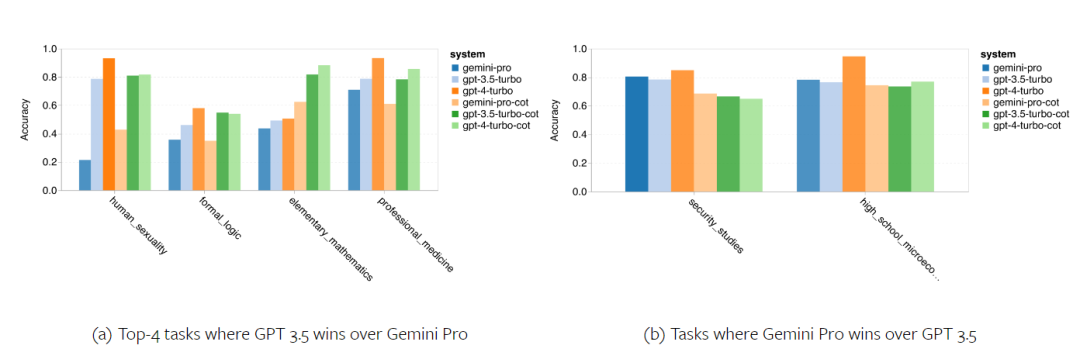
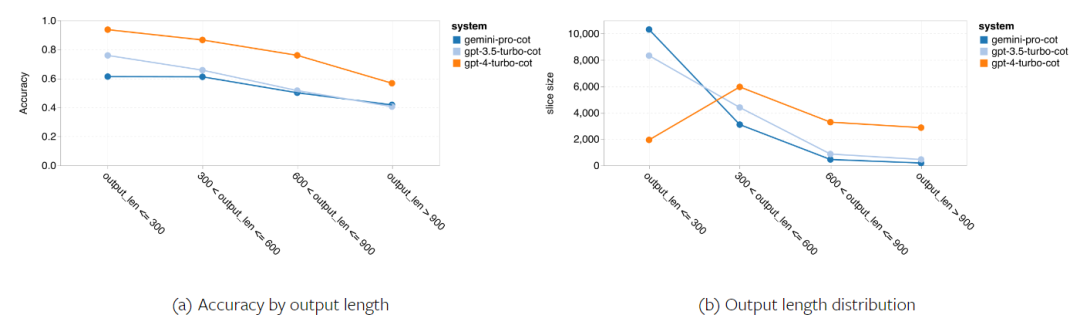
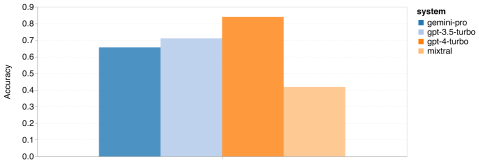
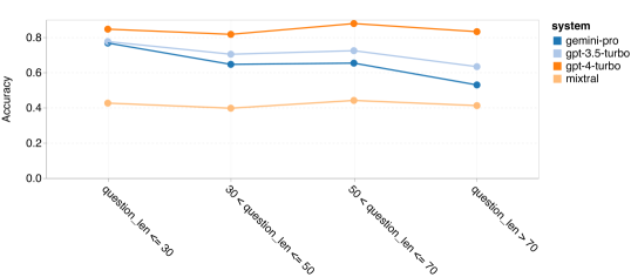
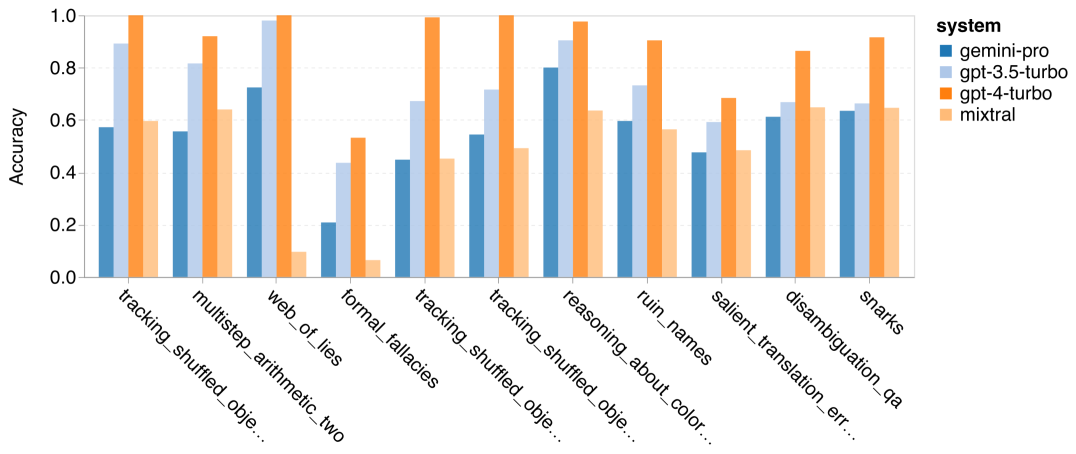
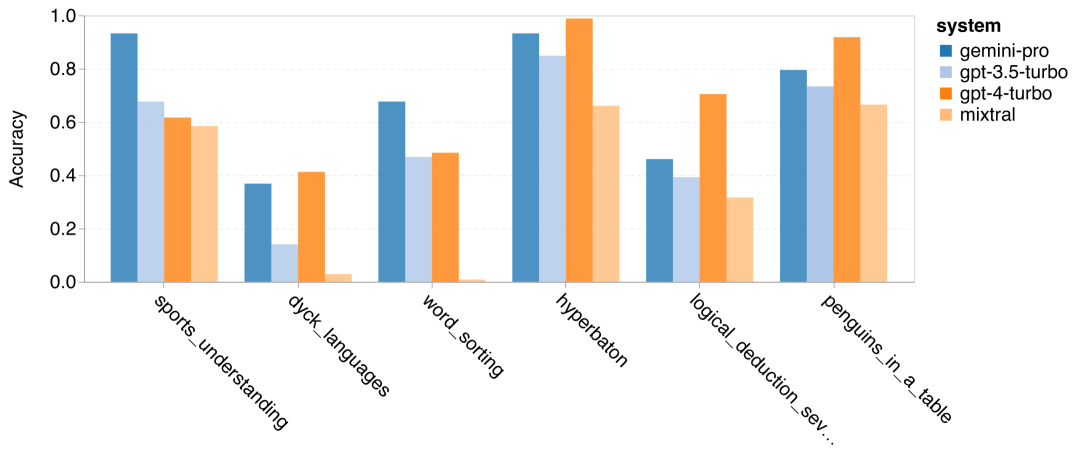
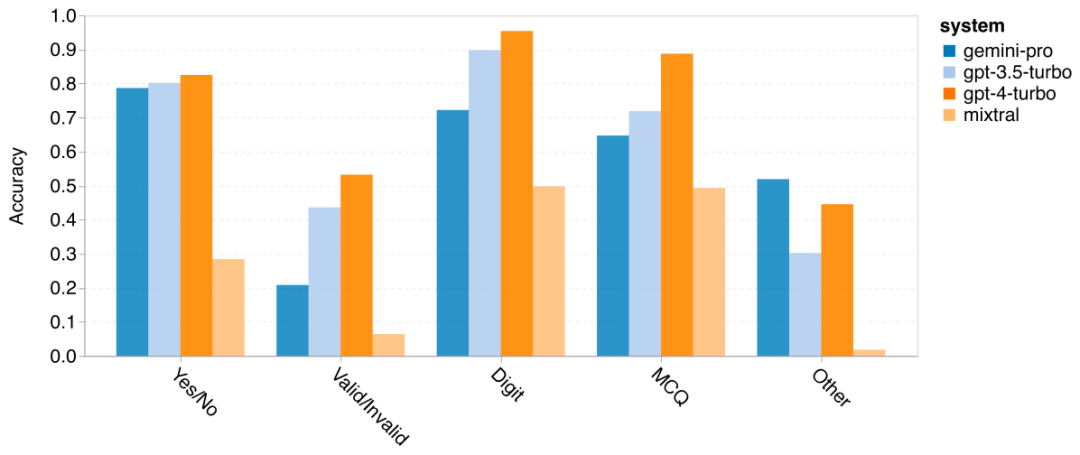
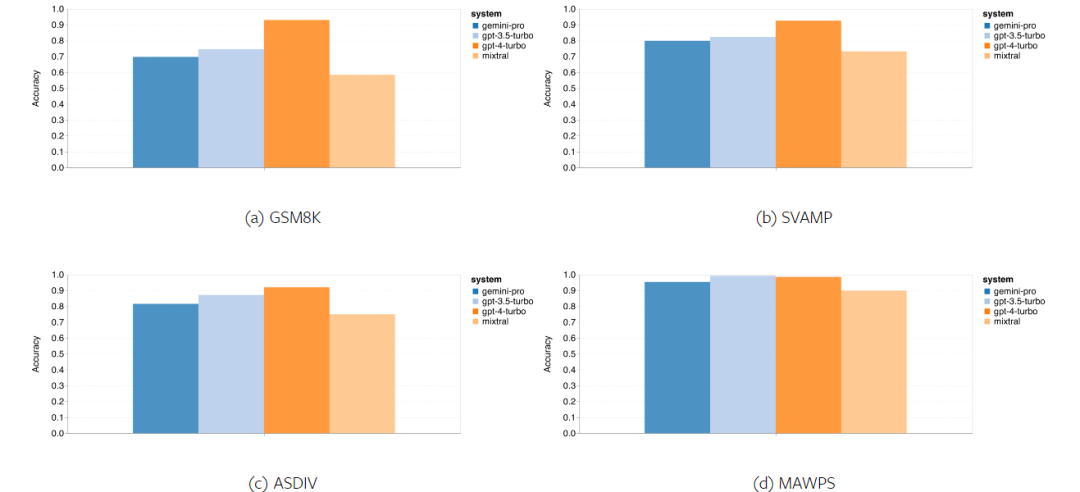
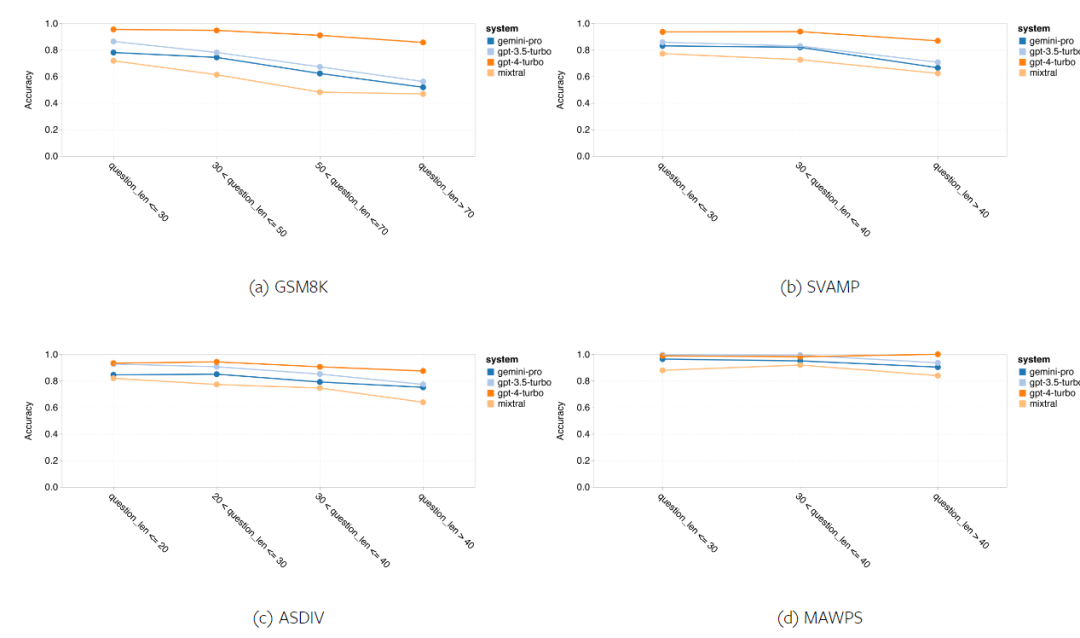
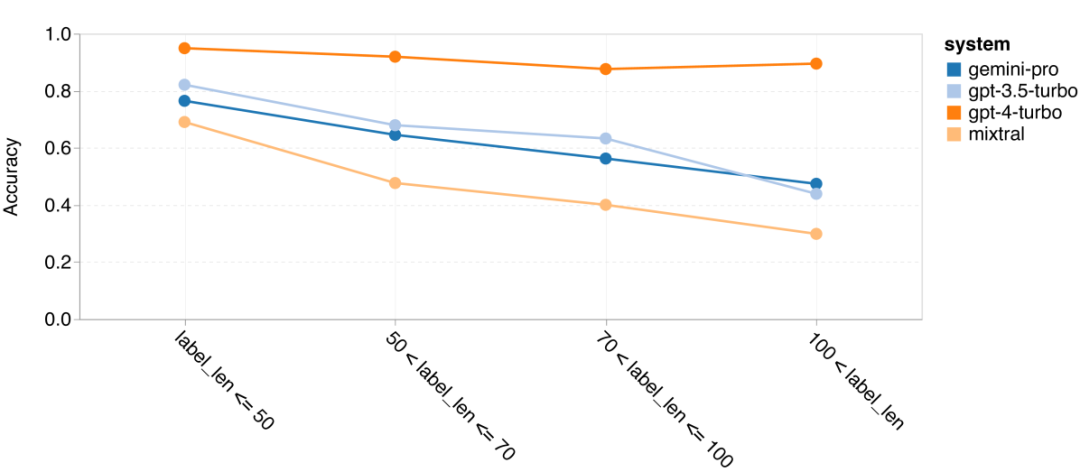
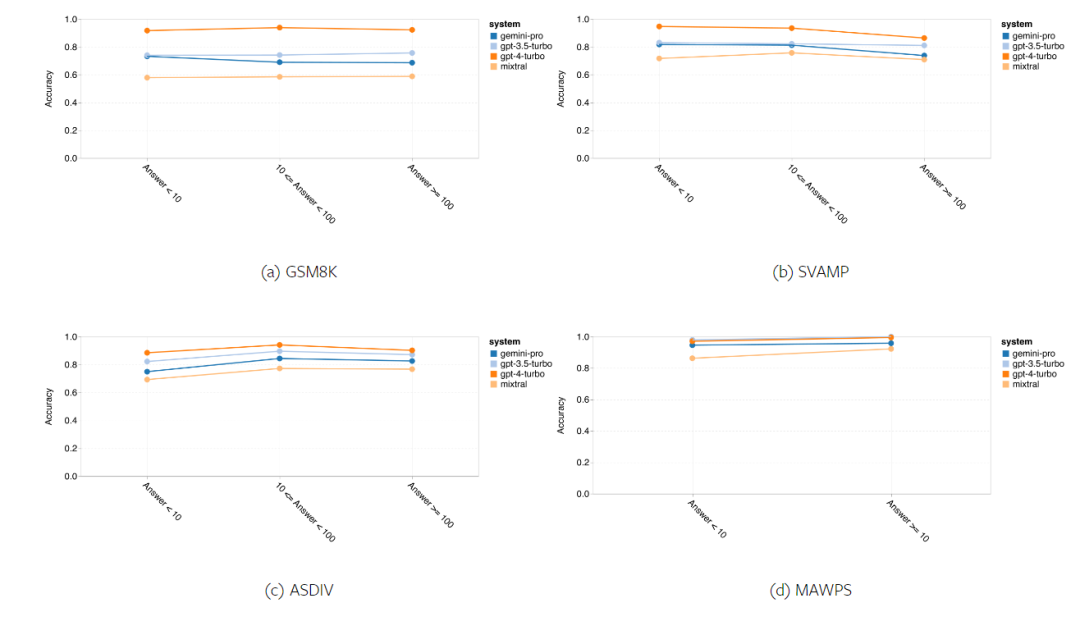
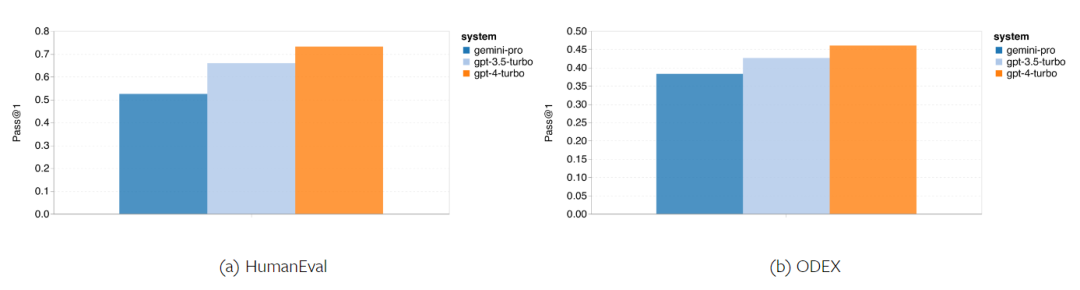
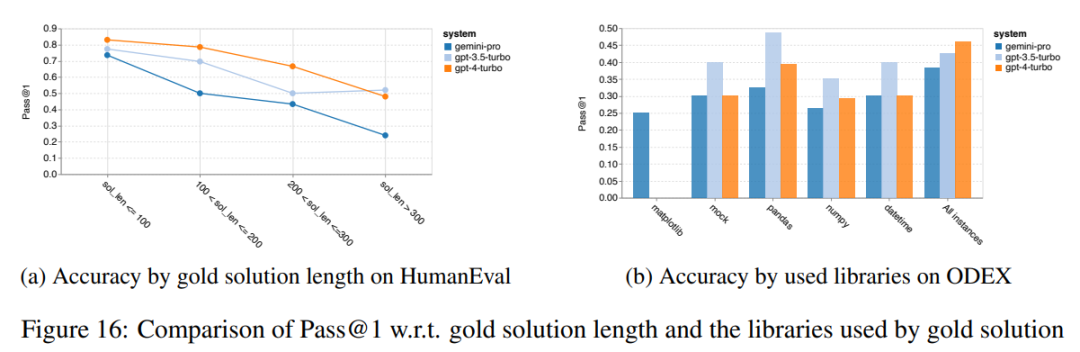
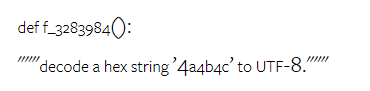
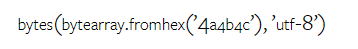


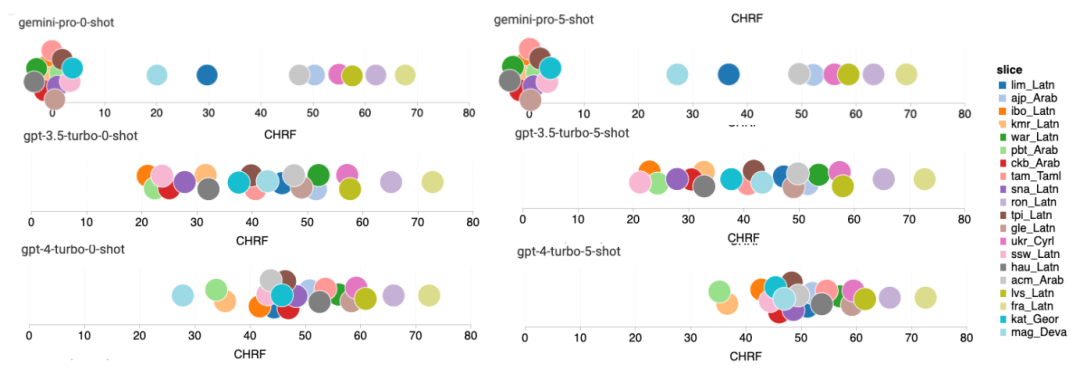
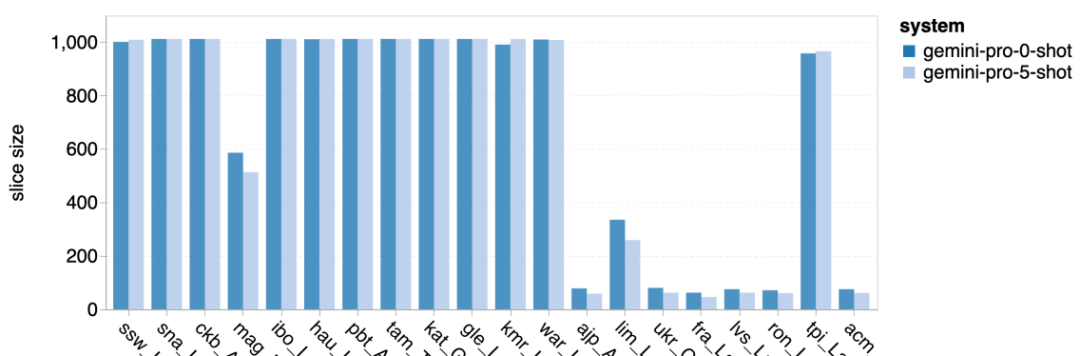
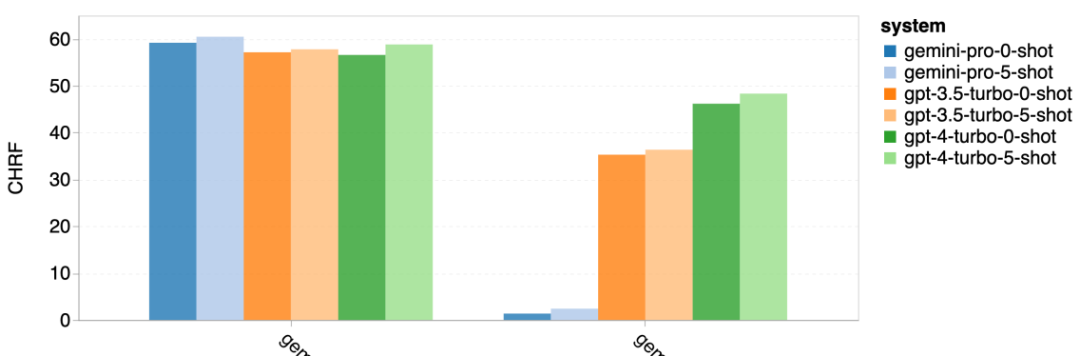
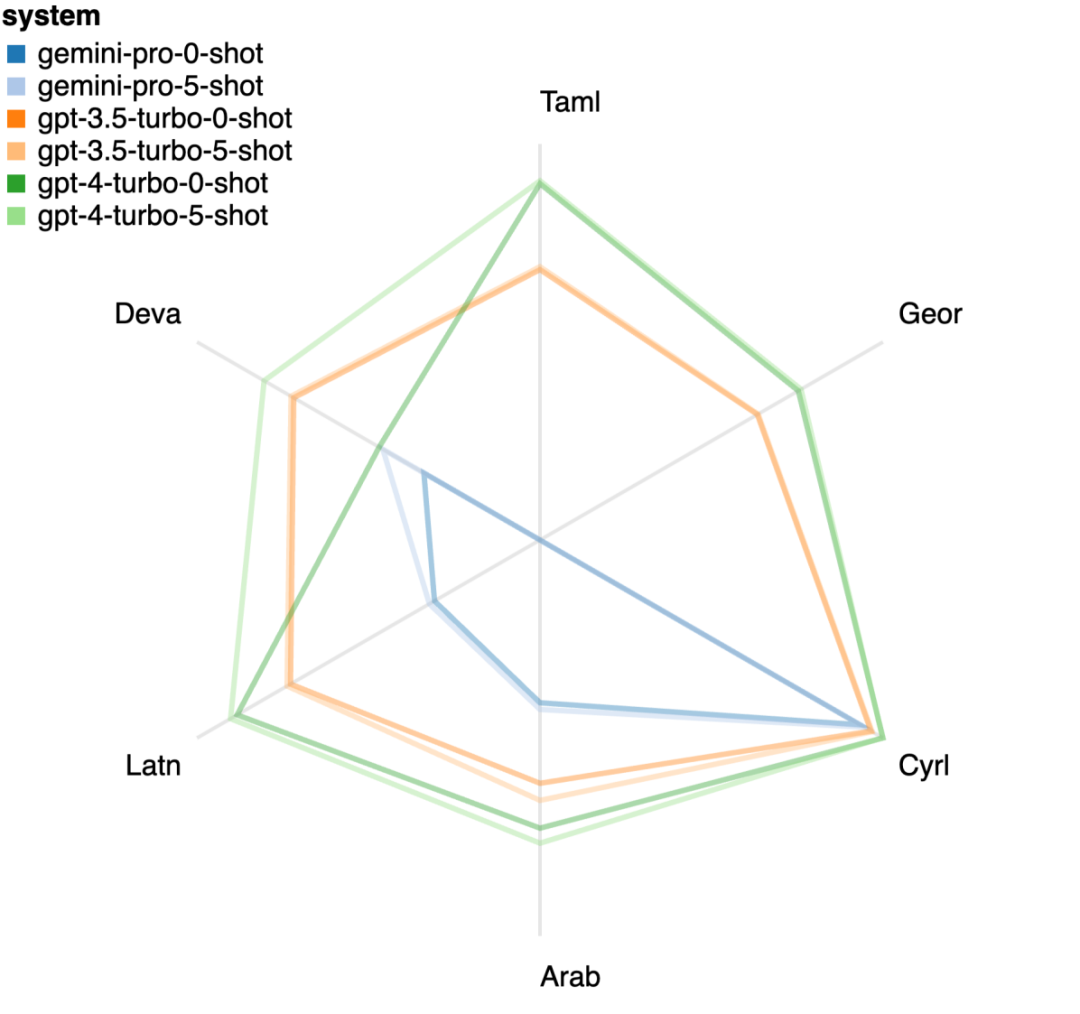
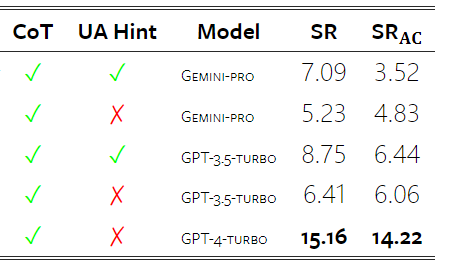
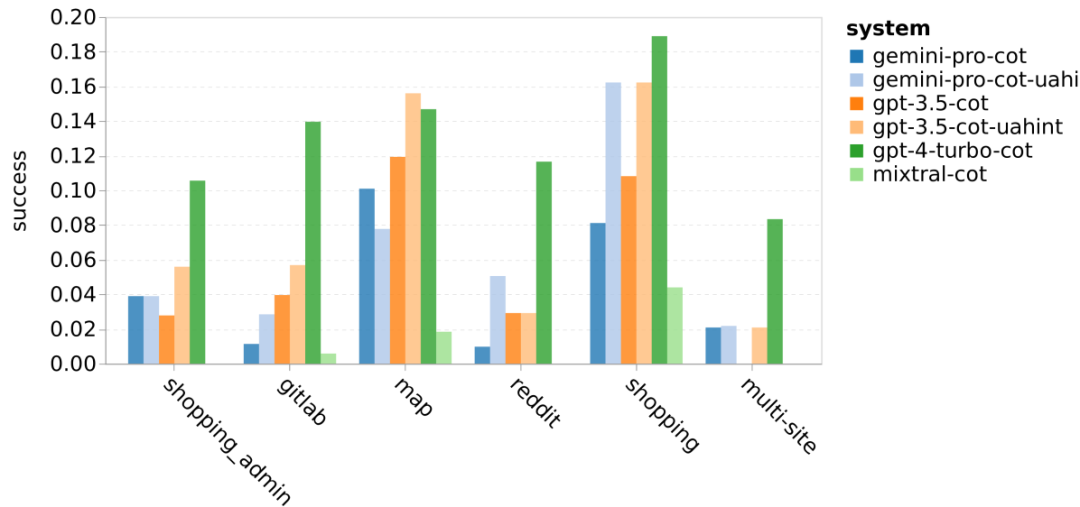
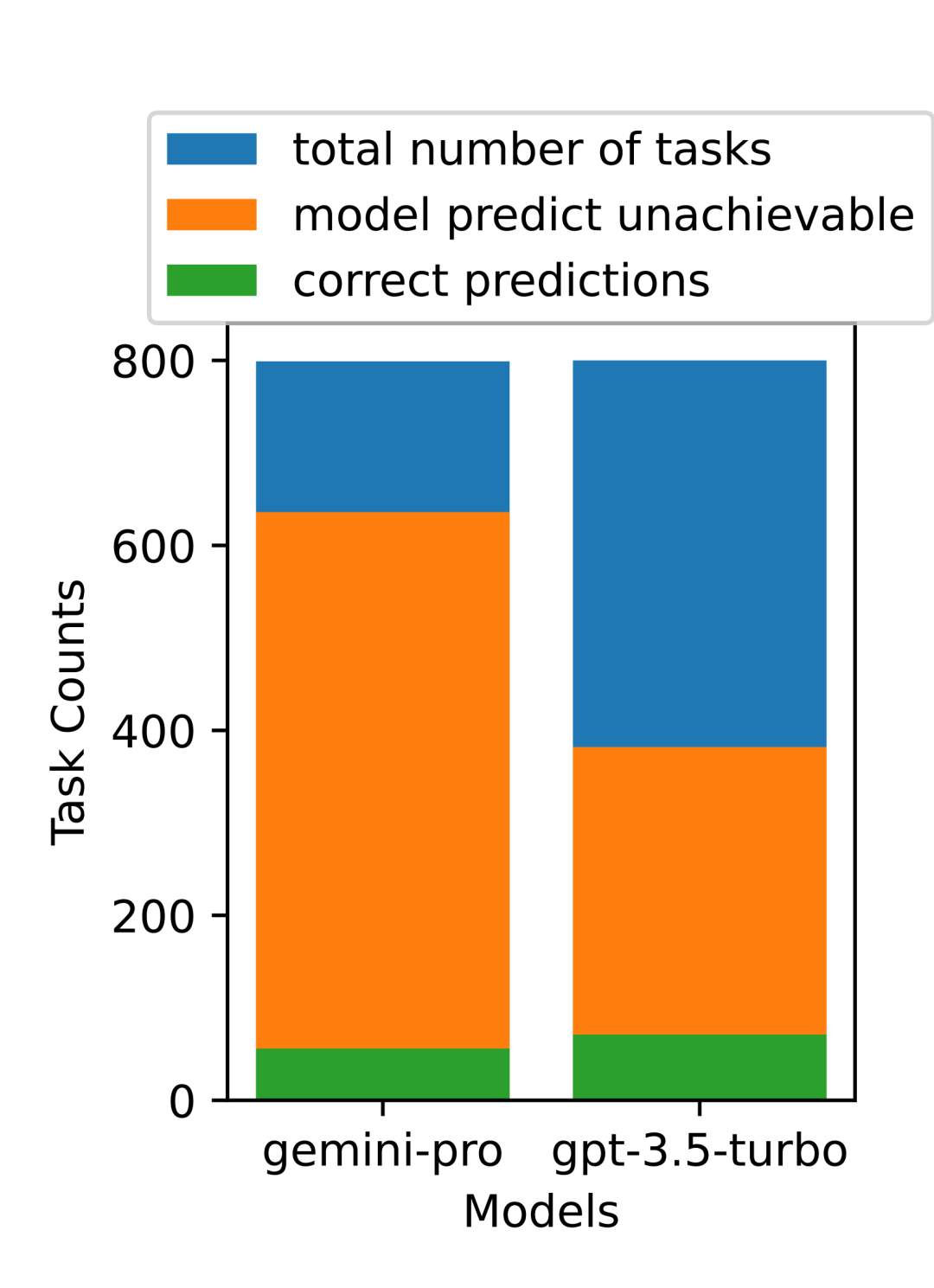
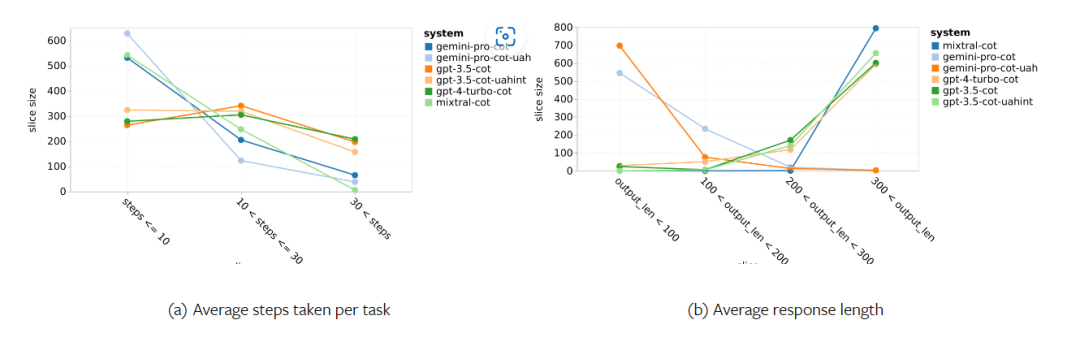
Das obige ist der detaillierte Inhalt vonVollständiger Testbericht zu Gemini: Von CMU zu GPT 3.5 Turbo verliert Gemini Pro. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Offizielle Website Eingang der großen Handelsplattformen der digitalen Währung 2025
Mar 31, 2025 pm 05:33 PM
Offizielle Website Eingang der großen Handelsplattformen der digitalen Währung 2025
Mar 31, 2025 pm 05:33 PM
In diesem Artikel wird zehn Mainstream -Kryptowährungsbörsen empfohlen, darunter Binance, OKX, Sesame Door (Gate.io), Coinbase, Kraken, Bitstamp, Gemini, Bittrex, Kucoin und Bitfinex. Diese Börsen haben ihre eigenen Vorteile, wie beispielsweise Binance für sein größtes Handelsvolumen und seine weltweit reichhaltige Währungsauswahl bekannt ist. OKX bietet innovative Tools wie Grid -Handel und eine Vielzahl von Derivaten. Coinbase konzentriert sich auf die Einhaltung der USA. Kraken zieht Benutzer für seine hohen Sicherheits- und Versprechen -Renditen an. Andere Börsen haben ihre eigenen Merkmale in verschiedenen Aspekten wie Fiat-Währungshandel, Altcoin-Handel, Hochfrequenzhandels-Tools usw. Wählen Sie eine Börse aus, die zu Ihnen passt, und Sie müssen Ihre eigene Investitionserfahrung nutzen
 Auf welcher Plattform handelt es sich um Web3 -Transaktion?
Mar 31, 2025 pm 07:54 PM
Auf welcher Plattform handelt es sich um Web3 -Transaktion?
Mar 31, 2025 pm 07:54 PM
Dieser Artikel listet die zehn bekannten Web3-Handelsplattformen auf, darunter Binance, OKX, Gate.io, Kraken, Bybit, Coinbase, Kucoin, Bitget, Gemini und Bitstamp. Der Artikel vergleicht die Merkmale jeder Plattform im Detail, z. B. die Anzahl der Währungen, Handelstypen (Spot, Futures, Optionen, NFT usw.), Handhabungsgebühren, Sicherheit, Compliance, Benutzergruppen usw., um den Anlegern dabei zu helfen, die am besten geeignete Handelsplattform auszuwählen. Egal, ob es sich um Hochfrequenzhändler, Vertragshandelsbegeisterte oder Investoren, die sich auf Compliance und Sicherheit konzentrieren, sie können Referenzinformationen daraus finden.
 Top 10 der formellen Web3 Trading Platform App -Rankings (maßgeblich im Jahr 2025 veröffentlicht)
Mar 31, 2025 pm 08:09 PM
Top 10 der formellen Web3 Trading Platform App -Rankings (maßgeblich im Jahr 2025 veröffentlicht)
Mar 31, 2025 pm 08:09 PM
Basierend auf Marktdaten und gemeinsamen Bewertungskriterien listet dieser Artikel die zehn besten Apps für die formelle Web3-Handelsplattform im Jahr 2025 auf. Die Liste umfasst bekannte Plattformen wie Binance, OKX, Gate.io, Huobi (jetzt bekannt als HTX), Crypto.com, Coinbase, Kraken, Gemini, Bitmex und Bybit. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Benutzerskala, Transaktionsvolumen, Sicherheit, Konformität, Produktinnovation usw. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf Ihren eigenen Bedürfnissen und Ihrer Risikotoleranz basiert.
 Was ist Blockchain -Datenschutzwährung? Was sind die Transaktionen?
Apr 20, 2025 pm 07:09 PM
Was ist Blockchain -Datenschutzwährung? Was sind die Transaktionen?
Apr 20, 2025 pm 07:09 PM
Blockchain -Datenschutzmünzen schützen die Privatsphäre der Benutzertransaktion durch Datenschutz -Schutztechnologie. Hier sind die Börsen für den Handel mit Datenschutzmünzen: 1. Binance, 2. OKX, 3. Gate.io, 4. Huobi, 5. Coinbase, 6. Kraken, 7. Kucoin, 8. Bitfinex, 9. Gemini, 10. Xbit.
 Welche Währungsbörsen 2025 sind sicherer?
Apr 20, 2025 pm 06:09 PM
Welche Währungsbörsen 2025 sind sicherer?
Apr 20, 2025 pm 06:09 PM
Zu den zehn besten sicheren und zuverlässigen Austauschern im Kryptowährungskreis 2025 gehören: 1. Binance, 2. OKX, 3. Gate.io (Sesam offen), 4. Coinbase, 5. Kraken, 6. Huobi Global, 7. Gemini, 8. Crypto.com, 9. Bitfinex, 10. Kucoin. Diese Börsen werden basierend auf Compliance, technischer Stärke und Benutzerkennzahl als sicher und zuverlässig eingestuft.
 Ranking von Apps für juristische Plattform für den Handel mit virtueller Währung
Apr 21, 2025 am 09:27 AM
Ranking von Apps für juristische Plattform für den Handel mit virtueller Währung
Apr 21, 2025 am 09:27 AM
In diesem Artikel werden die Apps für Rechtsplattformen für virtuelle Währungstransaktionen aufgeführt und betont, dass die Einhaltung einer wichtigen Überlegung für die Auswahl einer Plattform ist. Der Artikel empfiehlt Plattformen wie Coinbase, Gemini und Kraken und erinnert die Anleger daran, regulatorische Informationen zu studieren und auf Sicherheitsakten zu achten, wenn sie Entscheidungen treffen. Gleichzeitig betont der Artikel, dass virtuelle Währungstransaktionen ein hohes Risiko sind und Investitionen vorsichtig sein sollten.
 Was sind die Hybrid -Blockchain -Handelsplattformen?
Apr 21, 2025 pm 11:36 PM
Was sind die Hybrid -Blockchain -Handelsplattformen?
Apr 21, 2025 pm 11:36 PM
Vorschläge für die Auswahl eines Kryptowährungsaustauschs: 1. Für die Liquiditätsanforderungen ist Priorität Binance, Gate.io oder OKX aufgrund seiner Bestelltiefe und der starken Volatilitätsbeständigkeit. 2. Compliance and Security, Coinbase, Kraken und Gemini haben strenge regulatorische Bestätigung. 3. Innovative Funktionen, Kucoins sanftes Stakel und Derivatdesign von Bitbit eignen sich für fortschrittliche Benutzer.
 Top 10 Währungs -Apps der Welt 2025
Mar 31, 2025 pm 06:33 PM
Top 10 Währungs -Apps der Welt 2025
Mar 31, 2025 pm 06:33 PM
Welche Global Virtual Currency Trading App ist die beste im Jahr 2025? Dieser Artikel listet die zehn Top -Apps der virtuellen Währung der Welt der Welt auf, darunter Binance, OKX, Huobi, Gate.io, Coinbase, Kraken, Kucoin, Bitfinex, Gemini und Bitbit. Diese Plattformen haben ihre eigenen Vorteile hinsichtlich der Transaktionspaarmenge, der Transaktionsgeschwindigkeit, der Sicherheit, der Einhaltung, der Benutzererfahrung usw. Einige sind für Anfänger geeignet, während andere unter professionellen Händlern beliebter sind. Unabhängig davon, ob Sie ein erfahrener Händler oder ein Neuling im Bereich Kryptowährung sind, finden Sie in diesem Artikel die richtige Plattform für Sie. Kommen Sie und erfahren Sie mehr über diese Top -Apps mit virtueller Währung und wählen Sie das Handelstool, das Ihnen am meisten passt!
