
 Technologie-Peripheriegeräte
KI
4090-Generator: Im Vergleich zur A100-Plattform beträgt die Geschwindigkeit der Token-Generierung nur weniger als 18 %, und die Übermittlung an die Inferenz-Engine hat zu heftigen Diskussionen geführt
Technologie-Peripheriegeräte
KI
4090-Generator: Im Vergleich zur A100-Plattform beträgt die Geschwindigkeit der Token-Generierung nur weniger als 18 %, und die Übermittlung an die Inferenz-Engine hat zu heftigen Diskussionen geführt
4090-Generator: Im Vergleich zur A100-Plattform beträgt die Geschwindigkeit der Token-Generierung nur weniger als 18 %, und die Übermittlung an die Inferenz-Engine hat zu heftigen Diskussionen geführt

PowerInfer verbessert die Effizienz der Ausführung von KI auf Consumer-Hardware.
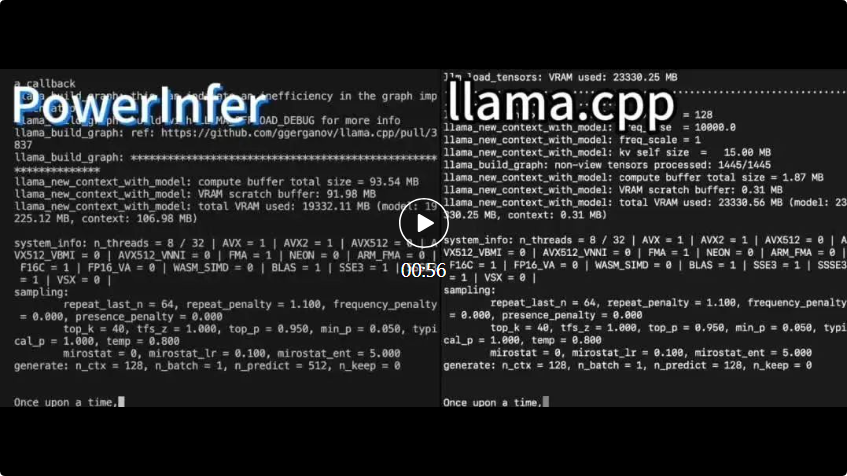 ama.cpp läuft beide auf derselben Hardware und nutzt den VRAM der RTX 4090 voll aus.
ama.cpp läuft beide auf derselben Hardware und nutzt den VRAM der RTX 4090 voll aus. PowerInfer Im Vergleich zum lokalen erweiterten LLM-Inferenz-Framework llama.cpp wird durch die Ausführung des Falcon (ReLU)-40B-FP16-Modells auf einer einzelnen RTX 4090 (24G) nicht nur eine mehr als 11-fache Beschleunigung erreicht, sondern auch die Modellgenauigkeit beibehalten
PowerInfer ist eine Hochgeschwindigkeits-Inferenz-Engine, die für die lokale Bereitstellung von LLM entwickelt wurde. Im Gegensatz zu Multi-Experten-Systemen (MoE) hat PowerInfer geschickt eine GPU-CPU-Hybrid-Inferenz-Engine entwickelt, die die hohe Lokalität der LLM-Inferenz voll ausnutzt. Häufig aktivierte Neuronen (d. h. Hot-Aktivierung) werden vorab auf die GPU geladen. Für einen schnellen Zugriff werden Neuronen verwendet, die selten aktiviert werden (d. h. Kaltaktivierungen) werden auf der CPU berechnet. So funktioniert es
Diese Methode kann den GPU-Speicherbedarf und die Menge der Datenübertragung zwischen CPU und GPU erheblich reduzieren

- Projektlink: https://github.com/SJTU-IPADS/ PowerInfer
- Link zum Papier: https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf
- PowerInfer kann LLM mit hoher Geschwindigkeit auf einem PC ausführen, der mit einer einzelnen Consumer-GPU ausgestattet ist. Benutzer können PowerInfer jetzt mit Llama 2 und
verwenden, die Unterstützung für Mistral-7B folgt in Kürze. An einem Tag hat PowerInfer erfolgreich 2K-Sterne erhalten
 Nachdem die Internetnutzer diese Untersuchung gesehen hatten, zeigten sie sich begeistert: Jetzt kann eine einzige Karte 4090 große 175B-Modelle betreiben, nicht mehr nur Was für ein Traum
Nachdem die Internetnutzer diese Untersuchung gesehen hatten, zeigten sie sich begeistert: Jetzt kann eine einzige Karte 4090 große 175B-Modelle betreiben, nicht mehr nur Was für ein Traum
Der Schlüssel zum Design von PowerInfer besteht darin, den hohen Grad an Lokalität auszunutzen, der der LLM-Inferenz innewohnt, die durch „Potenzgesetzverteilungen bei Neuronenaktivierungen“ gekennzeichnet ist. Diese Verteilung legt nahe, dass eine kleine Untergruppe von Neuronen, sogenannte heiße Neuronen, über alle Eingaben hinweg konsistent aktiviert wird, während die Mehrheit der kalten Neuronen je nach bestimmten Eingaben variiert. PowerInfer nutzt diesen Mechanismus, um eine GPU-CPU-Hybrid-Inferenz-Engine zu entwerfen.
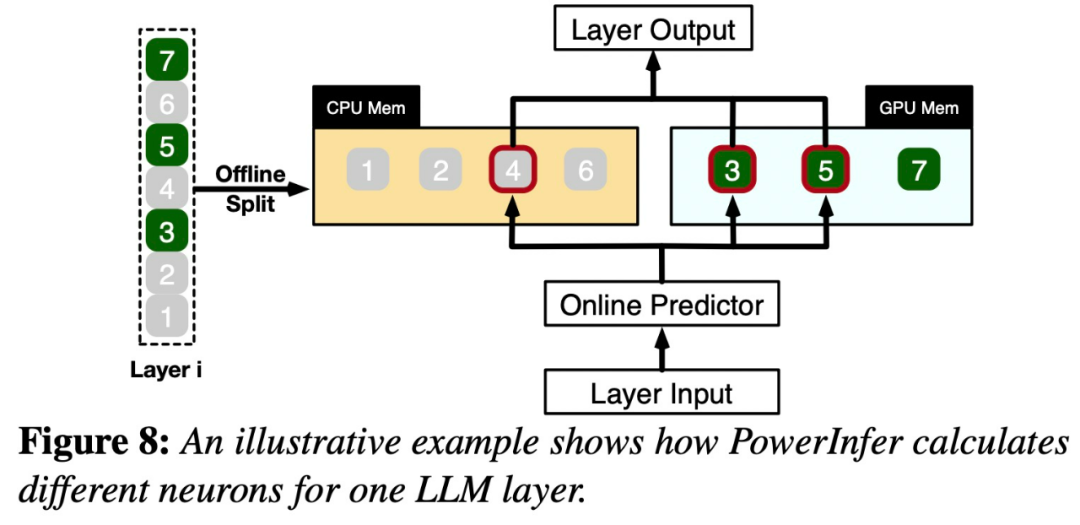
Bitte sehen Sie sich Abbildung 7 unten an, die einen Architekturüberblick von PowerInfer zeigt, einschließlich Offline- und Online-Komponenten. Die Offline-Komponente ist dafür verantwortlich, die Aktivierungsparsität von LLM zu handhaben und gleichzeitig zwischen heißen und kalten Neuronen zu unterscheiden. Während der Online-Phase lädt die Inferenz-Engine beide Arten von Neuronen in die GPU und die CPU und bedient LLM-Anfragen zur Laufzeit mit geringer Latenz. Abbildung 8 zeigt, wie PowerInfer funktioniert. Es koordiniert die Schichten zwischen GPU und CPU Verarbeitung von Neuronen. PowerInfer klassifiziert Neuronen anhand von Offline-Daten und weist aktive Neuronen (z. B. Index 3, 5, 7) dem GPU-Speicher und andere Neuronen dem CPU-Speicher zuSobald die Eingabe eingegangen ist, identifiziert der Prädiktor Neuronen in der aktuellen Schicht, die wahrscheinlich aktiviert werden. Es ist zu beachten, dass thermisch aktivierte Neuronen, die durch statistische Offline-Analyse identifiziert wurden, möglicherweise nicht mit dem tatsächlichen Aktivierungsverhalten zur Laufzeit übereinstimmen. Obwohl beispielsweise Neuron 7 als thermisch aktiviert gekennzeichnet ist, ist dies in Wirklichkeit nicht der Fall. Die CPU und die GPU verarbeiten dann die bereits aktivierten Neuronen und ignorieren diejenigen, die nicht aktiviert sind. Die GPU ist für die Berechnung der Neuronen 3 und 5 verantwortlich, während die CPU für Neuron 4 zuständig ist. Wenn die Berechnung von Neuron 4 abgeschlossen ist, wird seine Ausgabe zur Ergebnisintegration an die GPU gesendet
Um den Inhalt neu zu schreiben, ohne die ursprüngliche Bedeutung zu ändern, muss die Sprache ins Chinesische umgeschrieben werden. Es ist nicht erforderlich, dass der Originalsatz erscheint
Die Studie wurde mit dem OPT-Modell mit verschiedenen Parametern durchgeführt. Um den Inhalt neu zu schreiben, ohne die ursprüngliche Bedeutung zu ändern, muss die Sprache ins Chinesische umgeschrieben werden. Es ist nicht erforderlich, Originalsätze vorzulegen, die Parameter reichen von 6,7B bis 175B, und die Modelle Falcon (ReLU)-40B und LLaMA (ReGLU)-70B sind ebenfalls enthalten. Es ist erwähnenswert, dass die Größe des 175B-Parametermodells mit dem „GPT-3-Modell“ vergleichbar ist. In diesem Artikel wird PowerInfer auch mit llama.cpp verglichen, einem hochmodernen nativen LLM-Inferenz-Framework. Um den Vergleich zu erleichtern, wurde in dieser Studie auch llama.cpp erweitert, um das OPT-Modell zu unterstützen pro Sekunde generierte Token (Tokens/s) zur Quantifizierung
Diese Studie vergleicht zunächst die End-to-End-Inferenzleistung von PowerInfer und llama.cpp mit einer Stapelgröße von 1
Auf PC-High mit NVIDIA RTX 4090, Abbildung 10 zeigt die verschiedenen Modelle und die Generierungsgeschwindigkeit von Ein- und Ausgabekonfigurationen. Im Durchschnitt erreicht PowerInfer eine Generierungsgeschwindigkeit von 8,32 Token/s, mit einem Maximum von 16,06 Token/s, was deutlich besser ist als llama.cpp, 7,23-mal höher als llama.cpp und 11,69-mal höher als Falcon-40B
Nachfolgend: Mit zunehmender Anzahl der Ausgabetoken wird der Leistungsvorteil von PowerInfer deutlicher, da die Generierungsphase eine wichtigere Rolle in der gesamten Inferenzzeit spielt. Zu diesem Zeitpunkt wird eine kleine Anzahl von Neuronen sowohl auf der CPU als auch auf der GPU aktiviert, was im Vergleich zu llama.cpp unnötige Berechnungen reduziert. Im Fall von OPT-30B werden beispielsweise nur etwa 20 % der Neuronen pro generiertem Token aktiviert, die meisten davon werden auf der GPU verarbeitet, was der Vorteil der neuronenbewussten Inferenz von PowerInfer ist
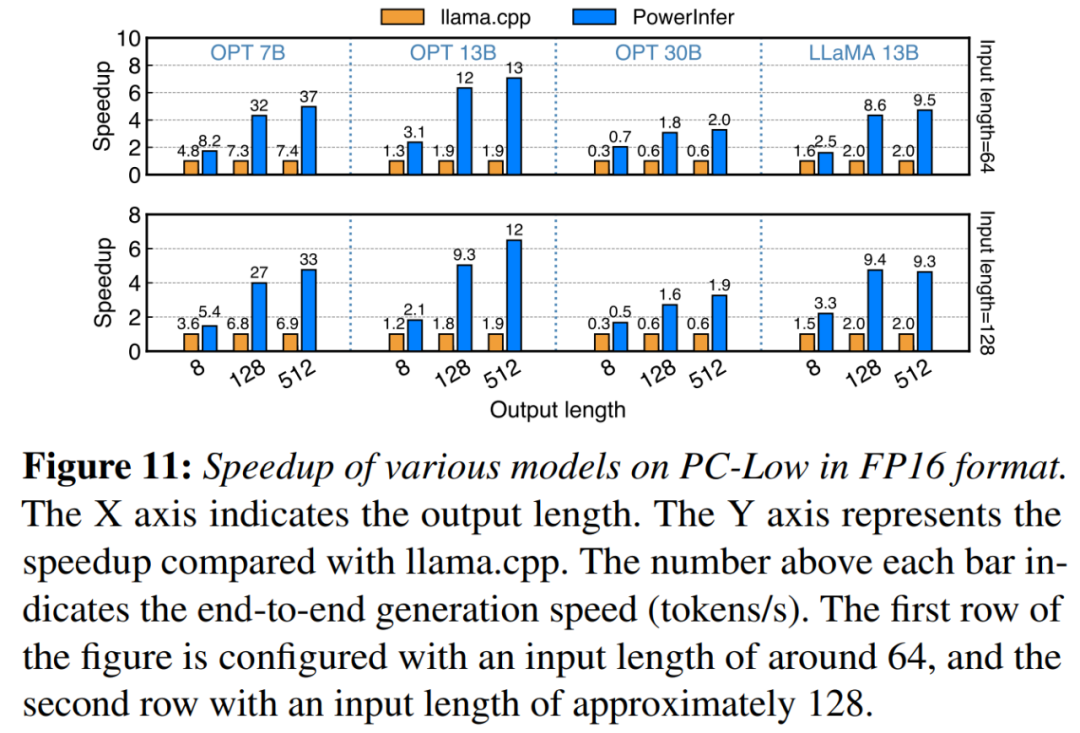
in Abbildung 11 Wie in der Abbildung gezeigt, erzielte PowerInfer trotz der Ausführung auf PC-Low immer noch erhebliche Leistungssteigerungen mit einer durchschnittlichen Geschwindigkeitssteigerung von 5,01x und einer Spitzengeschwindigkeitssteigerung von 7,06x. Allerdings fallen diese Verbesserungen im Vergleich zu PC-High geringer aus, was hauptsächlich auf die 11-GB-GPU-Speicherbeschränkung von PC-Low zurückzuführen ist. Diese Grenze wirkt sich auf die Anzahl der Neuronen aus, die der GPU zugewiesen werden können, insbesondere bei Modellen mit etwa 30B Parametern oder mehr, was zu einer größeren Abhängigkeit von der CPU führt, um eine große Anzahl aktivierter Neuronen zu verarbeiten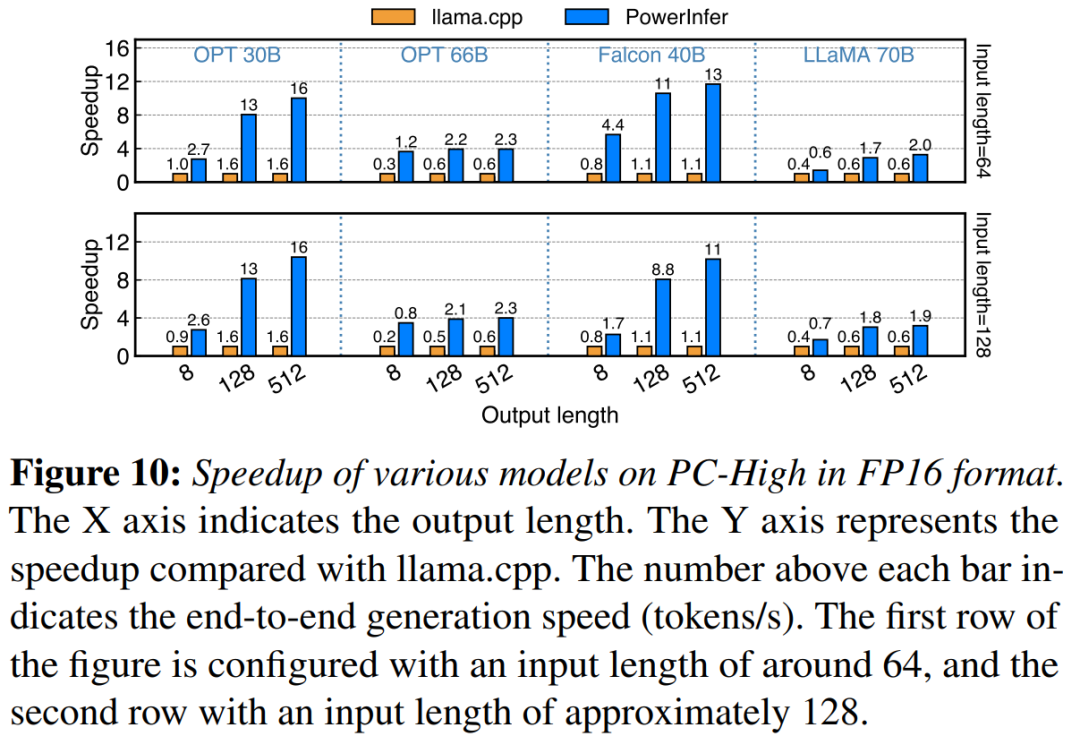

Abschließend bewertet die Studie auch die End-to-End-Inferenzleistung von PowerInfer bei verschiedenen Stapelgrößen. Wie in Abbildung 14 dargestellt, zeigt PowerInfer bei einer Stapelgröße von weniger als 32 erhebliche Vorteile mit einer durchschnittlichen Leistungsverbesserung um das 6,08-fache im Vergleich zu Lama. Mit zunehmender Batchgröße nimmt die von PowerInfer bereitgestellte Beschleunigung ab. Doch selbst wenn die Stapelgröße auf 32 eingestellt ist, sorgt PowerInfer immer noch für eine beträchtliche Geschwindigkeitssteigerung mehr Inhalt
Das obige ist der detaillierte Inhalt von4090-Generator: Im Vergleich zur A100-Plattform beträgt die Geschwindigkeit der Token-Generierung nur weniger als 18 %, und die Übermittlung an die Inferenz-Engine hat zu heftigen Diskussionen geführt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Derzeit sind autoregressive groß angelegte Sprachmodelle, die das nächste Token-Vorhersageparadigma verwenden, auf der ganzen Welt populär geworden. Gleichzeitig haben uns zahlreiche synthetische Bilder und Videos im Internet bereits die Leistungsfähigkeit von Diffusionsmodellen gezeigt. Kürzlich hat ein Forschungsteam am MITCSAIL (darunter Chen Boyuan, ein Doktorand am MIT) erfolgreich die leistungsstarken Fähigkeiten des Vollsequenz-Diffusionsmodells und des nächsten Token-Modells integriert und ein Trainings- und Sampling-Paradigma vorgeschlagen: Diffusion Forcing (DF). ). Papiertitel: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Papieradresse: https:/
