

Bevorzugte neuronale Netze für die Anwendung auf Zeitreihendaten

| Einführung | In diesem Artikel wird kurz der Entwicklungsprozess des wiederkehrenden neuronalen Netzwerks RNN vorgestellt und der Gradientenabstiegsalgorithmus, die Backpropagation und der LSTM-Prozess analysiert. |
Mit der Entwicklung von Wissenschaft und Technologie und der erheblichen Verbesserung der Hardware-Computing-Fähigkeiten ist künstliche Intelligenz durch jahrzehntelange Arbeit hinter den Kulissen plötzlich in die Augen der Menschen gesprungen. Das Rückgrat der künstlichen Intelligenz ist die Unterstützung von Big Data, leistungsstarker Hardware und exzellenten Algorithmen. Im Jahr 2016 ist Deep Learning zu einem heißen Wort in der Google-Suche geworden. Da AlphaGo in den letzten ein oder zwei Jahren den Weltmeister im Kampf zwischen Mensch und Maschine besiegt hat, haben die Menschen das Gefühl, dass sie der rasanten Weiterentwicklung der KI nicht länger widerstehen können. Im Jahr 2017 hat die KI einen Durchbruch erzielt, und verwandte Produkte sind auch im Leben der Menschen aufgetaucht, beispielsweise intelligente Roboter, selbstfahrende Autos und Sprachsuche. Kürzlich fand die World Intelligence Conference erfolgreich in Tianjin statt. Auf der Konferenz äußerten viele Branchenexperten und Unternehmer ihre Ansichten über die Zukunft Beispielsweise wird Baidu sein gesamtes Vermögen auf künstlicher Intelligenz basieren, egal ob er berühmt wird oder doch scheitert, solange er nichts gewinnt. Warum hat Deep Learning plötzlich eine so große Wirkung und Begeisterung? Denn Technologie verändert das Leben und viele Berufe könnten in Zukunft langsam durch künstliche Intelligenz ersetzt werden. Alle reden über künstliche Intelligenz und Deep Learning. Sogar Yann LeCun spürt die Popularität der künstlichen Intelligenz in China
Um auf das Thema zurückzukommen: Hinter künstlicher Intelligenz stehen Big Data, hervorragende Algorithmen und Hardwareunterstützung mit leistungsstarken Rechenfunktionen. Beispielsweise steht NVIDIA aufgrund seiner starken Hardware-Forschungs- und Entwicklungskapazitäten und der Unterstützung von Deep-Learning-Frameworks an erster Stelle der fünfzig intelligentesten Unternehmen der Welt. Darüber hinaus gibt es viele hervorragende Deep-Learning-Algorithmen, und von Zeit zu Zeit wird ein neuer Algorithmus erscheinen, der wirklich umwerfend ist. Die meisten von ihnen basieren jedoch auf klassischen Algorithmen wie Convolutional Neural Network (CNN), Deep Believe Network (DBN), Recurrent Neural Network (RNN) usw.
In diesem Artikel wird das klassische Netzwerk Recurrent Neural Network (RNN) vorgestellt, das auch das bevorzugte Netzwerk für Zeitreihendaten ist. Bei bestimmten sequentiellen maschinellen Lernaufgaben kann RNN eine sehr hohe Genauigkeit erreichen, mit der kein anderer Algorithmus mithalten kann. Dies liegt daran, dass herkömmliche neuronale Netze nur über ein Kurzzeitgedächtnis verfügen, während RNN den Vorteil eines begrenzten Kurzzeitgedächtnisses hat. Das RNN-Netzwerk der ersten Generation erregte jedoch keine große Aufmerksamkeit, da die Forscher bei der Verwendung von Backpropagation- und Gradientenabstiegsalgorithmen unter schwerwiegenden Problemen mit dem Verschwinden von Gradienten litten, was die Entwicklung von RNNs jahrzehntelang behinderte. Schließlich gelang Ende der 1990er Jahre ein großer Durchbruch, der zu einer neuen Generation genauerer RNNs führte. Fast zwei Jahrzehnte nach diesem Durchbruch perfektionierten und optimierten Entwickler eine neue Generation von RNNs, bis Apps wie Google Voice Search und Apple Siri begannen, ihre Schlüsselprozesse an sich zu reißen. Heute sind RNN-Netzwerke in allen Forschungsbereichen verbreitet und tragen dazu bei, eine Renaissance der künstlichen Intelligenz einzuleiten.
Past-Related Neural Networks (RNN)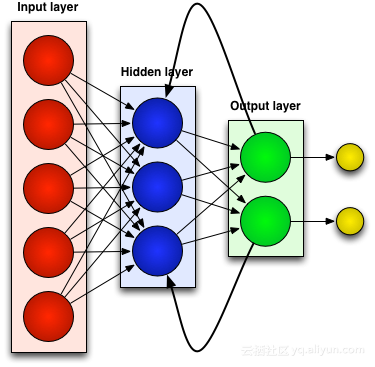
Die meisten künstlichen neuronalen Netze, wie zum Beispiel Feedforward-Neuronale Netze, erinnern sich nicht an die Eingaben, die sie gerade erhalten haben. Wenn einem Feedforward-Neuronalen Netzwerk beispielsweise das Zeichen „WISDOM“ zugeführt wird, hat es beim Erreichen des Zeichens „D“ vergessen, dass es gerade das Zeichen „S“ gelesen hat, was ein großes Problem darstellt. Egal wie sorgfältig das Netzwerk trainiert wurde, es war immer schwierig, das nächstwahrscheinlichste Zeichen „O“ zu erraten. Dies macht es zu einem ziemlich nutzlosen Kandidaten für bestimmte Aufgaben, wie z. B. die Spracherkennung, bei der die Qualität der Erkennung weitgehend von der Fähigkeit abhängt, das nächste Zeichen vorherzusagen. RNN-Netzwerke hingegen erinnern sich zwar an frühere Eingaben, allerdings auf einem sehr ausgefeilten Niveau.
Wir geben „WISDOM“ erneut ein und wenden es auf ein wiederkehrendes Netzwerk an. Wenn die Einheit oder das künstliche Neuron im RNN-Netzwerk „D“ empfängt, erhält sie als Eingabe auch das Zeichen „S“, das sie zuvor empfangen hat. Mit anderen Worten: Es nutzt die vergangenen Ereignisse in Kombination mit den gegenwärtigen Ereignissen als Eingabe, um vorherzusagen, was als nächstes passieren wird, was ihm den Vorteil eines begrenzten Kurzzeitgedächtnisses verschafft. Beim Training kann bei ausreichendem Kontext davon ausgegangen werden, dass das nächste Zeichen höchstwahrscheinlich „O“ ist.
Anpassen und neu anpassenWie alle künstlichen neuronalen Netze weisen RNN-Einheiten ihren mehreren Eingaben eine Gewichtsmatrix zu. Diese Gewichte stellen den Anteil jeder Eingabe in der Netzwerkschicht dar. Anschließend wird eine Funktion auf diese Gewichte angewendet, um eine einzelne Ausgabe zu bestimmen wird Verlustfunktion (Kostenfunktion) genannt und begrenzt den Fehler zwischen der tatsächlichen Ausgabe und der Zielausgabe. Allerdings weisen RNNs Gewichtungen nicht nur aktuellen Eingaben zu, sondern auch Eingaben aus vergangenen Momenten. Anschließend werden die der aktuellen Eingabe und früheren Eingaben zugewiesenen Gewichte durch Minimierung der Verlustfunktion dynamisch angepasst. Dieser Prozess umfasst zwei Schlüsselkonzepte: Gradientenabstieg und Backpropagation (BPTT).
GradientenabstiegEiner der bekanntesten Algorithmen beim maschinellen Lernen ist der Gradientenabstiegsalgorithmus. Sein Hauptvorteil besteht darin, dass es den „Fluch der Dimensionalität“ deutlich vermeidet. Was ist der „Fluch der Dimensionalität“? Er bedeutet, dass bei Berechnungsproblemen mit Vektoren der Rechenaufwand mit zunehmender Anzahl der Dimensionen exponentiell zunimmt. Dieses Problem plagt viele neuronale Netzwerksysteme, da zu viele Variablen berechnet werden müssen, um die kleinste Verlustfunktion zu erreichen. Der Gradientenabstiegsalgorithmus bricht jedoch den Fluch der Dimensionalität, indem er mehrdimensionale Fehler oder lokale Minima der Kostenfunktion verstärkt. Dies hilft dem System, die den einzelnen Einheiten zugewiesenen Gewichtswerte anzupassen, um das Netzwerk präziser zu machen.
Rückausbreitung durch die ZeitRNN trainiert seine Einheiten, indem es seine Gewichte durch Rückwärtsinferenz feinabstimmt. Einfach ausgedrückt wird basierend auf dem Fehler zwischen der von der Einheit berechneten Gesamtausgabe und der Zielausgabe eine umgekehrte schichtweise Regression vom endgültigen Ausgabeende des Netzwerks durchgeführt und die partielle Ableitung der Verlustfunktion zur Anpassung verwendet das Gewicht jeder Einheit. Dies ist der berühmte BP-Algorithmus. Weitere Informationen zum BP-Algorithmus finden Sie in den vorherigen verwandten Blogs dieses Bloggers. Das RNN-Netzwerk verwendet eine ähnliche Version namens Backpropagation Through Time (BPTT). Diese Version erweitert den Optimierungsprozess um Gewichte, die für den Speicher jeder Einheit verantwortlich sind, die dem Eingabewert zum vorherigen Zeitpunkt (T-1) entspricht.
Yikes: Problem mit verschwindendem Gradienten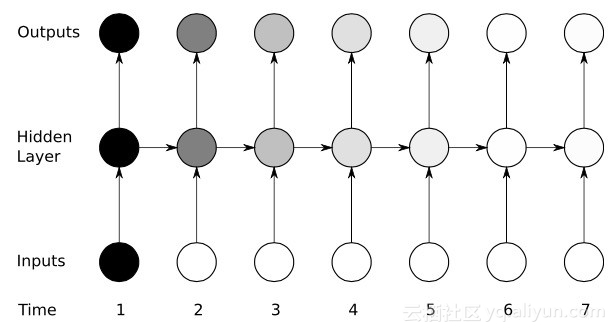
Obwohl viele künstliche neuronale Netze (einschließlich RNNs-Netze der ersten Generation) mit Hilfe von Gradientenabstiegsalgorithmen und BPTT einige anfängliche Erfolge erzielten, erlitten sie schließlich einen schweren Rückschlag – das Problem des verschwindenden Gradienten. Was ist das Problem des verschwindenden Gradienten? Die Grundidee ist eigentlich sehr einfach. Schauen wir uns zunächst das Konzept des Gradienten an und stellen uns den Gradienten als Steigung vor. Im Kontext des Trainings tiefer neuronaler Netze stellen größere Gradientenwerte steilere Steigungen dar und desto schneller kann das System bis zur Ziellinie gleiten und das Training abschließen. Doch hier gerieten die Forscher in Schwierigkeiten: Schnelles Training war unmöglich, wenn der Hang zu flach war. Dies ist besonders wichtig für die erste Schicht in einem tiefen Netzwerk, denn wenn der Gradientenwert der ersten Schicht Null ist, bedeutet dies, dass es keine Anpassungsrichtung gibt und die relevanten Gewichtswerte nicht angepasst werden können, um die Verlustfunktion zu minimieren Dieses Phänomen wird als „Gradientenverlust“ bezeichnet. Je kleiner das Gefälle wird, desto länger wird die Trainingszeit, ähnlich wie bei der linearen Bewegung in der Physik bewegt sich der Ball auf einer glatten Oberfläche weiter.
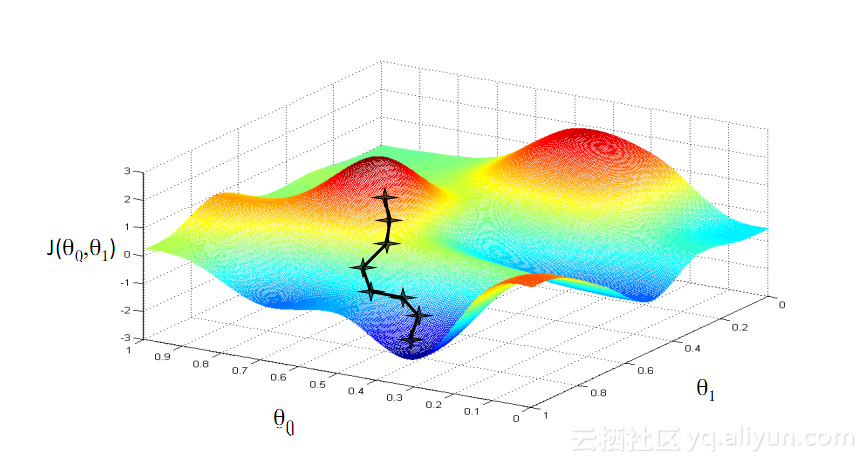
In den späten 1990er Jahren löste ein großer Durchbruch das oben erwähnte Problem des verschwindenden Gradienten und löste einen zweiten Forschungsboom bei der Entwicklung von RNN-Netzwerken aus. Die zentrale Idee dieses großen Durchbruchs ist die Einführung des Unit Long Short-Term Memory (LSTM).
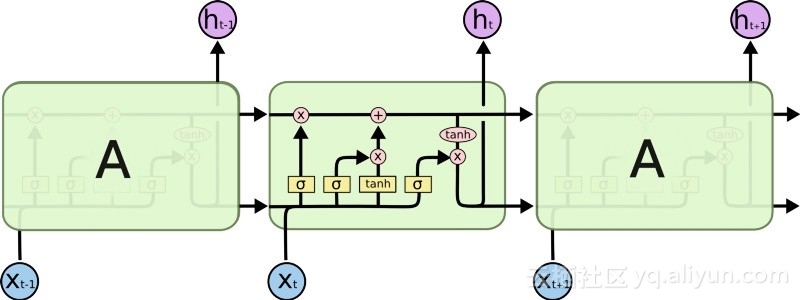
Die Einführung von LSTM hat eine andere Welt im KI-Bereich geschaffen. Dies liegt daran, dass diese neuen Einheiten oder künstlichen Neuronen (wie die Standard-Kurzzeitgedächtniseinheiten von RNN) sich ihre Eingaben von Anfang an merken. Im Gegensatz zu Standard-RNN-Zellen können LSTMs jedoch in ihren Speichern montiert werden, die ähnliche Lese-/Schreibeigenschaften wie Speicherregister in normalen Computern haben. Darüber hinaus sind LSTMs analog und nicht digital, wodurch ihre Merkmale unterscheidbar sind. Mit anderen Worten: Ihre Kurven sind kontinuierlich und die Steilheit ihrer Steigungen lässt sich ermitteln. Daher eignet sich LSTM besonders für die Teilrechnung bei Backpropagation und Gradientenabstieg.
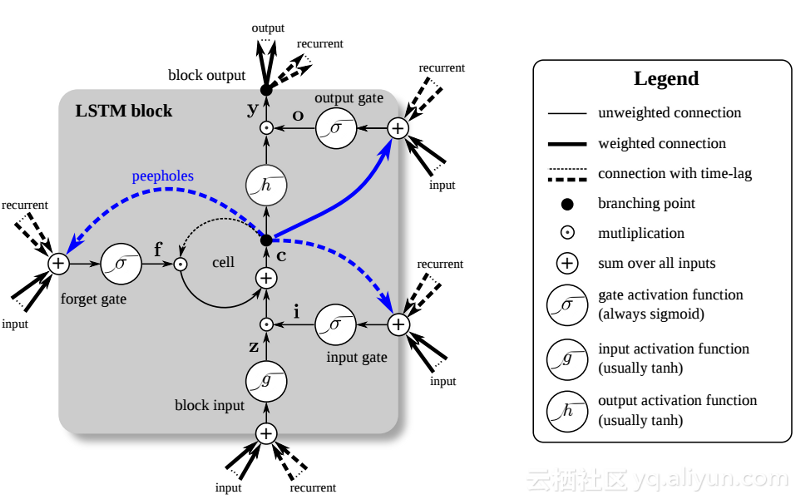
Zusammenfassend lässt sich sagen, dass LSTM nicht nur seine Gewichte anpassen, sondern auch den Zu- und Abfluss seiner gespeicherten Daten basierend auf dem Trainingsgradienten behalten, löschen, transformieren und steuern kann. Am wichtigsten ist, dass LSTM wichtige Fehlerinformationen über einen langen Zeitraum hinweg bewahren kann, sodass der Gradient relativ steil ist und somit die Trainingszeit des Netzwerks relativ kurz ist. Dies löst das Problem verschwindender Gradienten und verbessert die Genauigkeit heutiger LSTM-basierter RNN-Netzwerke erheblich. Aufgrund erheblicher Verbesserungen in der RNN-Architektur nutzen Google, Apple und viele andere fortschrittliche Unternehmen jetzt RNN, um Anwendungen im Zentrum ihrer Unternehmen zu betreiben.
ZusammenfassungRekurrente neuronale Netze (RNN) können sich an ihre vorherigen Eingaben erinnern, was ihnen gegenüber anderen künstlichen neuronalen Netzen größere Vorteile verschafft, wenn es um kontinuierliche, kontextsensitive Aufgaben wie die Spracherkennung geht.
Zur Entwicklungsgeschichte von RNN-Netzwerken: Die erste Generation von RNNs erlangte die Fähigkeit, Fehler durch Backpropagation- und Gradientenabstiegsalgorithmen zu korrigieren. Das Problem des verschwindenden Gradienten verhinderte jedoch die Entwicklung von RNN; erst 1997 gelang mit der Einführung einer LSTM-basierten Architektur ein großer Durchbruch.
Die neue Methode verwandelt jede Einheit im RNN-Netzwerk effektiv in einen analogen Computer und verbessert so die Netzwerkgenauigkeit erheblich.
Informationen zum Autor
Jason Roell: Softwareentwickler mit einer Leidenschaft für Deep Learning und seine Anwendung auf transformative Technologien.
Linkedin: http://www.linkedin.com/in/jason-roell-47830817/
Das obige ist der detaillierte Inhalt vonBevorzugte neuronale Netze für die Anwendung auf Zeitreihendaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Deepseek Web Version Eingang Deepseek Offizielle Website Eingang
Feb 19, 2025 pm 04:54 PM
Deepseek Web Version Eingang Deepseek Offizielle Website Eingang
Feb 19, 2025 pm 04:54 PM
Deepseek ist ein leistungsstarkes Intelligent -Such- und Analyse -Tool, das zwei Zugriffsmethoden bietet: Webversion und offizielle Website. Die Webversion ist bequem und effizient und kann ohne Installation verwendet werden. Unabhängig davon, ob Einzelpersonen oder Unternehmensnutzer, können sie massive Daten über Deepseek problemlos erhalten und analysieren, um die Arbeitseffizienz zu verbessern, die Entscheidungsfindung zu unterstützen und Innovationen zu fördern.
 So installieren Sie Deepseek
Feb 19, 2025 pm 05:48 PM
So installieren Sie Deepseek
Feb 19, 2025 pm 05:48 PM
Es gibt viele Möglichkeiten, Deepseek zu installieren, einschließlich: kompilieren Sie von Quelle (für erfahrene Entwickler) mit vorberechtigten Paketen (für Windows -Benutzer) mit Docker -Containern (für bequem am besten, um die Kompatibilität nicht zu sorgen), unabhängig von der Methode, die Sie auswählen, bitte lesen Die offiziellen Dokumente vorbereiten sie sorgfältig und bereiten sie voll und ganz vor, um unnötige Schwierigkeiten zu vermeiden.
 Ouyi OKX Installationspaket ist direkt enthalten
Feb 21, 2025 pm 08:00 PM
Ouyi OKX Installationspaket ist direkt enthalten
Feb 21, 2025 pm 08:00 PM
Ouyi Okx, die weltweit führende digitale Asset Exchange, hat jetzt ein offizielles Installationspaket gestartet, um ein sicheres und bequemes Handelserlebnis zu bieten. Auf das OKX -Installationspaket von Ouyi muss nicht über einen Browser zugegriffen werden. Der Installationsprozess ist einfach und einfach zu verstehen.
 Holen Sie sich das Installationspaket Gate.io kostenlos
Feb 21, 2025 pm 08:21 PM
Holen Sie sich das Installationspaket Gate.io kostenlos
Feb 21, 2025 pm 08:21 PM
Gate.io ist ein beliebter Kryptowährungsaustausch, den Benutzer verwenden können, indem sie sein Installationspaket herunterladen und auf ihren Geräten installieren. Die Schritte zum Abholen des Installationspakets sind wie folgt: Besuchen Sie die offizielle Website von Gate.io, klicken Sie auf "Download", wählen Sie das entsprechende Betriebssystem (Windows, Mac oder Linux) und laden Sie das Installationspaket auf Ihren Computer herunter. Es wird empfohlen, die Antiviren -Software oder -Firewall während der Installation vorübergehend zu deaktivieren, um eine reibungslose Installation zu gewährleisten. Nach Abschluss muss der Benutzer ein Gate.io -Konto erstellen, um es zu verwenden.
 Bitget Offizielle Website -Installation (2025 Anfängerhandbuch)
Feb 21, 2025 pm 08:42 PM
Bitget Offizielle Website -Installation (2025 Anfängerhandbuch)
Feb 21, 2025 pm 08:42 PM
Bitget ist eine Kryptowährungsbörse, die eine Vielzahl von Handelsdienstleistungen anbietet, darunter Spot -Handel, Vertragshandel und Derivate. Der 2018 gegründete Austausch hat seinen Hauptsitz in Singapur und verpflichtet sich, den Benutzern eine sichere und zuverlässige Handelsplattform zu bieten. Bitget bietet eine Vielzahl von Handelspaaren, einschließlich BTC/USDT, ETH/USDT und XRP/USDT. Darüber hinaus hat der Austausch einen Ruf für Sicherheit und Liquidität und bietet eine Vielzahl von Funktionen wie Premium -Bestellarten, gehebelter Handel und Kundenunterstützung rund um die Uhr.
 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi, auch bekannt als OKX, ist eine weltweit führende Kryptowährungsplattform. Der Artikel enthält ein Download -Portal für das offizielle Installationspaket von Ouyi, mit dem Benutzer den Ouyi -Client auf verschiedenen Geräten installiert werden können. Dieses Installationspaket unterstützt Windows, Mac, Android und iOS -Systeme. Nach Abschluss der Installation können sich Benutzer registrieren oder sich beim Ouyi -Konto anmelden, Kryptowährungen mit dem Handel mit den von der Plattform erbrachten Diensten anmelden.
 Wie setze ich nach dem Neustart des Systems automatisch Berechtigungen von Unixsocket fest?
Mar 31, 2025 pm 11:54 PM
Wie setze ich nach dem Neustart des Systems automatisch Berechtigungen von Unixsocket fest?
Mar 31, 2025 pm 11:54 PM
So setzen Sie die Berechtigungen von Unixsocket automatisch nach dem Neustart des Systems. Jedes Mal, wenn das System neu startet, müssen wir den folgenden Befehl ausführen, um die Berechtigungen von Unixsocket: sudo ...
