

Im achten Abschnitt der awk-Reihe haben wir einige leistungsstarke awk-Befehlsfunktionen vorgestellt, nämlich Variablen, numerische Ausdrücke und Zuweisungsoperatoren.
In diesem Abschnitt erfahren wir mehr über die awk-Funktionen, insbesondere die speziellen Modi von awk: BEGIN und END.
Während wir Fortschritte machen und weitere Möglichkeiten zum Aufbau komplexer awk-Operationen entdecken, werden wir beweisen, wie leistungsfähig diese besonderen Funktionen von awk sind.
Bevor wir beginnen, werfen wir einen Blick auf die Einleitung der awk-Reihe. Denken Sie daran, dass ich zu Beginn dieser Reihe darauf hingewiesen habe, dass die allgemeine Syntax der awk-Anweisung wie folgt lautet:
# awk 'script' filenames
In der obigen Syntax hat das awk-Skript die Form:
/pattern/ { actions }
Normalerweise werden Sie feststellen, dass das Muster in Skripten (/pattern) ein regulärer Ausdruck ist, Sie können hier jedoch auch die speziellen Muster BENGIN und END verwenden. Daher können wir einen awk-Befehl auch in der folgenden Form schreiben:
awk '
BEGIN { actions }
/pattern/ { actions }
/pattern/ { actions }
……….
END { actions }
' filenames
Wenn Sie im awk-Skript spezielle Modi verwenden: BEGIN und END, sind die folgenden ihre entsprechenden Bedeutungen:
Der Ausführungsablauf von awk-Befehlsskripten, die diese speziellen Modi enthalten, ist wie folgt:
Wenn Sie spezielle Modi verwenden, sollten Sie die oben genannte Ausführungsreihenfolge beachten, um die besten Ergebnisse bei awk-Vorgängen zu erzielen.
Um das Verständnis zu erleichtern, verwenden wir zur Demonstration das Beispiel in Abschnitt 8. In diesem Beispiel geht es um die Liste der Domänennamen, die Tecmint gehört und in einer Datei namens domains.txt gespeichert ist.
news.tecmint.com tecmint.com linuxsay.com windows.tecmint.com tecmint.com news.tecmint.com tecmint.com linuxsay.com tecmint.com news.tecmint.com tecmint.com linuxsay.com windows.tecmint.com tecmint.com
$ cat ~/domains.txt
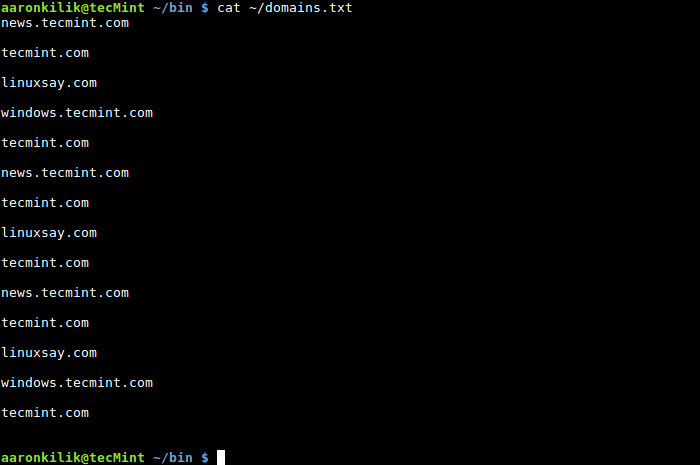
In diesem Beispiel möchten wir zählen, wie oft der Domainname tecmint.com in der Datei domains.txt vorkommt. Deshalb haben wir ein einfaches Shell-Skript geschrieben, das uns bei der Erledigung der Aufgabe hilft und die Ideen von Variablen, mathematischen Ausdrücken und Zuweisungsoperatoren verwendet. Der Skriptinhalt ist wie folgt:
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
### 输出文件名
echo "File is: $file"
### 输出一个递增的数字记录包含 tecmint.com 的行数
awk '/^tecmint.com/ { counter+=1 ; printf "%s/n", counter ; }' $file
else
### 若输入不是文件,则输出错误信息
echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1
fi
done
### 成功执行后使用退出代码 0 终止脚本
exit 0
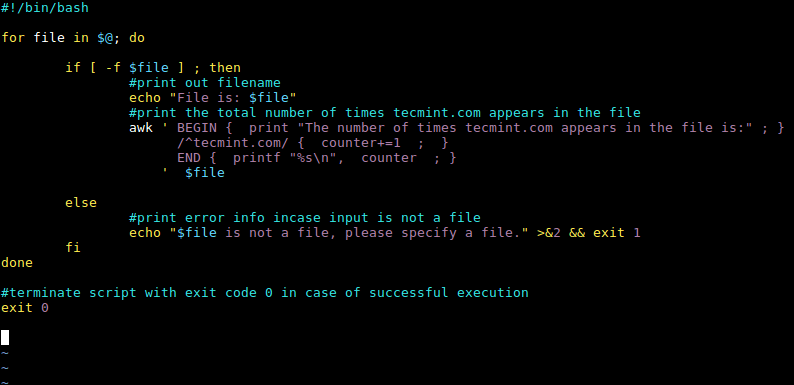
Lassen Sie uns nun diese beiden Spezialmodi im awk-Befehl des obigen Skripts wie folgt anwenden: BEGIN und END:
Wir sollten das Drehbuch schreiben:
awk '/^tecmint.com/ { counter+=1 ; printf "%s/n", counter ; }' $file
Geändert in:
awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; }
/^tecmint.com/ { counter+=1 ; }
END { printf "%s/n", counter ; }
' $file
在修改了 awk 命令之后,现在完整的 shell 脚本就像下面这样:
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
### 输出文件名
echo "File is: $file"
### 输出文件中 tecmint.com 出现的总次数
awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; }
/^tecmint.com/ { counter+=1 ; }
END { printf "%s/n", counter ; }
' $file
else
### 若输入不是文件,则输出错误信息
echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1
fi
done
### 成功执行后使用退出代码 0 终止脚本
exit 0
当我们运行上面的脚本时,它会首先输出 domains.txt 文件的位置,然后执行 awk 命令脚本,该命令脚本中的特殊模式 BEGIN 将会在从文件读取任何行之前帮助我们输出这样的消息“文件中出现 tecmint.com 的次数是: ”。
接下来,我们的模式/^tecmint.com/ 会在每个输入行中进行比较,对应的动作{ counter+=1 ; } 会在每个匹配成功的行上执行,它会统计出 tecmint.com 在文件中出现的次数。
最终,END 模式将会输出域名 tecmint.com 在文件中出现的总次数。
$ ./script.sh ~/domains.txt

最后总结一下,我们在本节中演示了更多的 awk 功能,并学习了特殊模式 BEGIN 和 END 的概念。
正如我之前所言,这些 awk 功能将会帮助我们构建出更复杂的文本过滤操作。第十节将会给出更多的 awk 功能,我们将会学习 awk 内置变量的思想,所以,请继续保持关注。
Das obige ist der detaillierte Inhalt vonSo verwenden Sie die speziellen Modi BEGIN und END von awk für die Verarbeitung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



