

| Einführung | Container revolutionieren den gesamten Software-Lebenszyklus: von den ersten technischen Experimenten und Proofs of Concept bis hin zu Entwicklung, Tests, Bereitstellung und Support. |
Möchten Sie MongoDB auf Ihrem Laptop ausprobieren? Führen Sie einfach einen Befehl aus und Sie erhalten eine kompakte, eigenständige Sandbox. Wenn Sie fertig sind, können Sie alle Spuren Ihrer Arbeit löschen.
Möchten Sie dieselbe Anwendungsstapelkopie in mehreren Umgebungen verwenden? Erstellen Sie Ihre eigenen Container-Images und lassen Sie Ihre Entwicklungs-, Test-, Betriebs- und Supportteams denselben Umgebungsklon verwenden.
Container revolutionieren den gesamten Software-Lebenszyklus: von den ersten technischen Experimenten und Proofs of Concept bis hin zu Entwicklung, Tests, Bereitstellung und Support.
Orchestrierungstools werden verwendet, um zu verwalten, wie mehrere Container erstellt, aktualisiert und hochverfügbar gemacht werden. Die Orchestrierung steuert auch, wie Container verbunden werden, um komplexe Anwendungen aus mehreren Microservice-Containern zu erstellen.
Umfangreiche Funktionen, einfache Tools und leistungsstarke APIs machen Container und Orchestrierungsfunktionen zur ersten Wahl für DevOps-Teams zur Integration in Workflows für kontinuierliche Integration (CI) und kontinuierliche Bereitstellung (CD).
In diesem Artikel werden die zusätzlichen Herausforderungen untersucht, die beim Ausführen und Orchestrieren von MongoDB in Containern auftreten, und erläutert, wie diese bewältigt werden können.
Hinweise zu MongoDBEs gibt einige zusätzliche Überlegungen zum Ausführen von MongoDB mit Containern und Orchestrierung:
MongoDB-Datenbankknoten sind zustandsbehaftet. Wenn ein Container ausfällt und neu geplant wird, gehen die Daten verloren (sie können von anderen Knoten im Replikatsatz wiederhergestellt werden, aber das braucht Zeit), was unerwünscht ist. Um dieses Problem zu lösen, können Sie Funktionen wie die Volume-Abstraktion in Kubernetes verwenden, um das temporäre MongoDB-Datenverzeichnis im Container einem dauerhaften Speicherort zuzuordnen, sodass die Daten Containerausfälle und Neuplanungsprozesse überstehen.
MongoDB-Datenbankknoten in einem Replikatsatz müssen in der Lage sein, miteinander zu kommunizieren – auch nach einer Neuplanung. Alle Knoten in einem Replikatsatz müssen die Adressen aller ihrer Peers kennen, aber wenn ein Container neu geplant wird, kann es sein, dass er mit einer anderen IP-Adresse neu gestartet wird. Beispielsweise teilen sich alle Container in einem Kubernetes-Pod eine IP-Adresse, und wenn ein Pod neu orchestriert wird, ändert sich die IP-Adresse. Bei Kubernetes wird dies dadurch gehandhabt, dass jedem MongoDB-Knoten ein Kubernetes-Dienst zugeordnet wird, der über den Kubernetes-DNS-Dienst einen „Hostnamen“ bereitstellt, um den Dienst bei Neuorchestrierungen unverändert zu lassen.
Sobald jeder einzelne MongoDB-Knoten ausgeführt wird (jeder in seinem eigenen Container), muss der Replikatsatz initialisiert und jeder Knoten hinzugefügt werden. Dies erfordert möglicherweise eine zusätzliche Verarbeitung außerhalb des Orchestrierungstools. Insbesondere müssen Sie einen MongoDB-Knoten im Zielreplikatsatz verwenden, um die Befehle rs.initiate und rs.add auszuführen.
Wenn ein Orchestrierungsframework eine automatisierte Neuorchestrierung von Containern ermöglichen würde (z. B. Kubernetes), würde dies die Ausfallsicherheit von MongoDB erhöhen, da ausgefallene Replikatsatzmitglieder automatisch neu erstellt werden könnten, wodurch die volle Redundanzebene ohne menschliches Eingreifen wiederhergestellt würde.
Es ist zu beachten, dass das Orchestrierungsframework zwar den Status des Containers überwachen kann, es jedoch unwahrscheinlich ist, dass es die im Container ausgeführte Anwendung überwacht oder deren Daten sichert. Daher ist es wichtig, eine leistungsstarke Überwachungs- und Sicherungslösung wie den in MongoDB Enterprise Advanced und MongoDB Professional enthaltenen MongoDB Cloud Manager zu verwenden. Erwägen Sie die Erstellung Ihres eigenen Images, das Ihre bevorzugte MongoDB-Version und den MongoDB-Automatisierungsagenten enthält.
Wie im vorherigen Abschnitt erwähnt, erfordern verteilte Datenbanken (wie MongoDB) ein wenig Aufmerksamkeit, wenn sie mithilfe von Orchestrierungsframeworks (wie Kubernetes) bereitgestellt werden. In diesem Abschnitt wird detailliert beschrieben, wie Sie dies erreichen.
Wir beginnen mit der Erstellung des gesamten MongoDB-Replikatsatzes in einem einzelnen Kubernetes-Cluster (normalerweise innerhalb eines Rechenzentrums, das offensichtlich keine Georedundanz bietet). In der Praxis ist ein Wechsel zur Ausführung über mehrere Cluster hinweg selten erforderlich. Diese Schritte werden später beschrieben.
Jedes Mitglied des Replikatsatzes wird als eigener Pod ausgeführt und stellt einen Dienst mit einer offengelegten IP-Adresse und einem Port bereit. Diese „feste“ IP-Adresse ist wichtig, da sowohl externe Anwendungen als auch andere Mitglieder des Replikatsatzes darauf vertrauen können, dass sie im Falle einer Pod-Neuplanung unverändert bleibt.
Das Bild unten zeigt einen der Pods und die zugehörigen Replikationscontroller und -dienste.
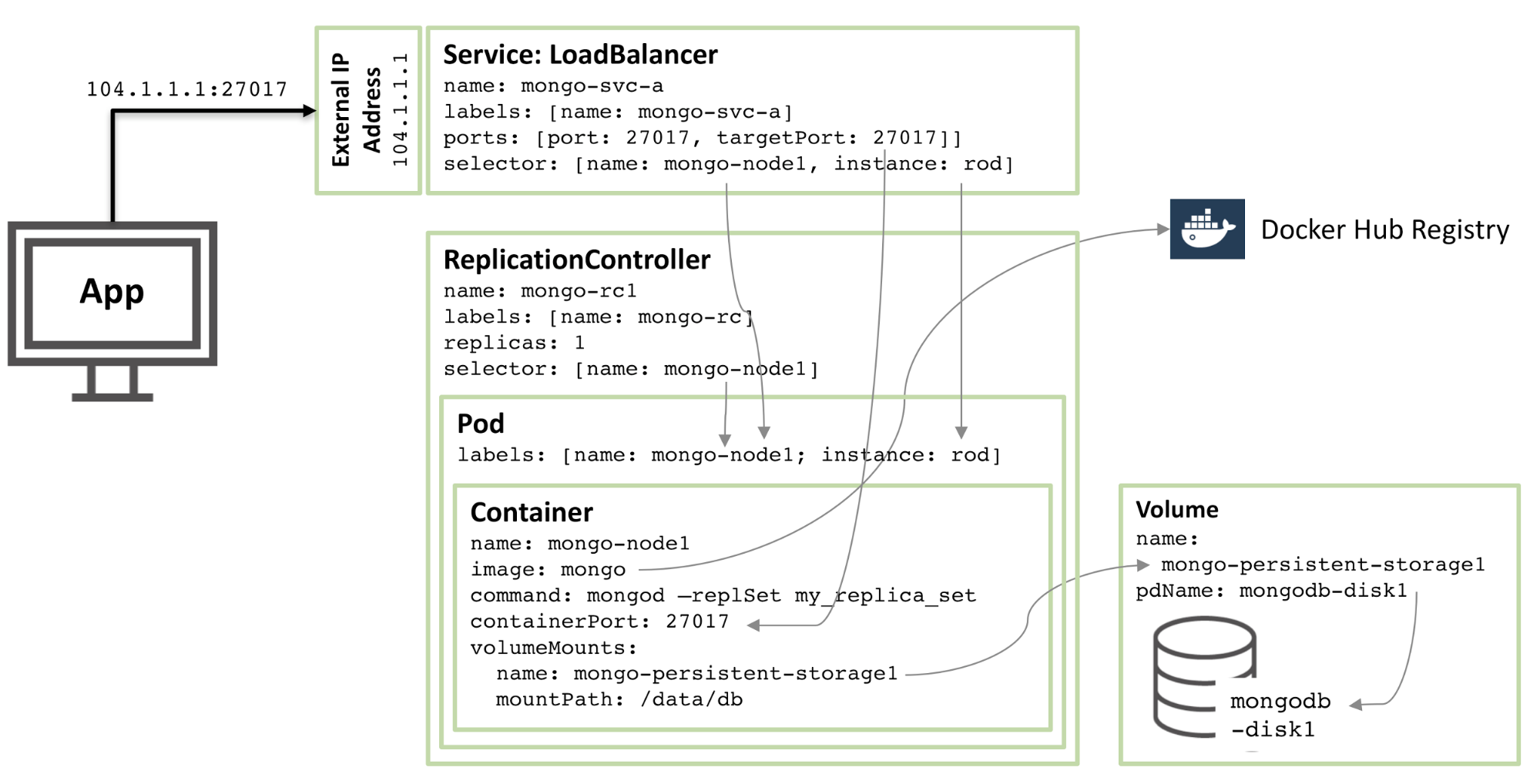
Abbildung 1: Mitglieder des MongoDB-Replikatsatzes, die als Kubernetes-Pods konfiguriert und als Dienste verfügbar gemacht werden
Abbildung 1: Mitglieder des MongoDB-Replikatsatzes, die als Kubernetes-Pods konfiguriert und als Dienste verfügbar gemacht werden
Eine schrittweise Einführung in die in dieser Konfiguration beschriebenen Ressourcen:
Ausgehend vom Kern gibt es einen Container namens mongo-node1. mongo-node1 enthält ein Image namens mongo, ein öffentlich verfügbares MongoDB-Container-Image, das auf Docker Hub gehostet wird. Der Container stellt Port 27107 im Cluster bereit.
Die Datenvolumenfunktion von Kubernetes wird verwendet, um das Verzeichnis /data/db im Connector einem dauerhaften Speicher namens mongo-persistent-storage1 zuzuordnen, der wiederum einer in Google Cloud erstellten Festplatte namens mongodb-disk1 zugeordnet ist. Hier speichert MongoDB seine Daten, sodass sie auch nach der Neuorchestrierung des Containers bestehen bleiben.
Der Container wird in einem Pod mit einer Bezeichnung namens mongo-node und einem (willkürlichen) Beispiel namens rod aufbewahrt.
Konfigurieren Sie den Mongo-node1-Replikationscontroller, um sicherzustellen, dass immer eine einzelne Instanz des Mongo-node1-Pods ausgeführt wird.
Der Lastausgleichsdienst namens mongo-svc-a öffnet eine IP-Adresse und einen Port 27017 für die Außenwelt, die derselben Portnummer des Containers zugeordnet sind. Der Dienst verwendet Selektoren, um Pod-Bezeichnungen abzugleichen und so den richtigen Pod zu ermitteln. Die externe IP-Adresse und der Port werden für die Kommunikation zwischen Anwendungen und Replikatsatzmitgliedern verwendet. Jeder Container verfügt auch über eine lokale IP-Adresse. Wenn der Container jedoch verschoben oder neu gestartet wird, ändern sich diese IP-Adressen und werden daher nicht für den Replikatsatz verwendet.
Das nächste Diagramm zeigt die Konfiguration des zweiten Mitglieds des Replikatsatzes.
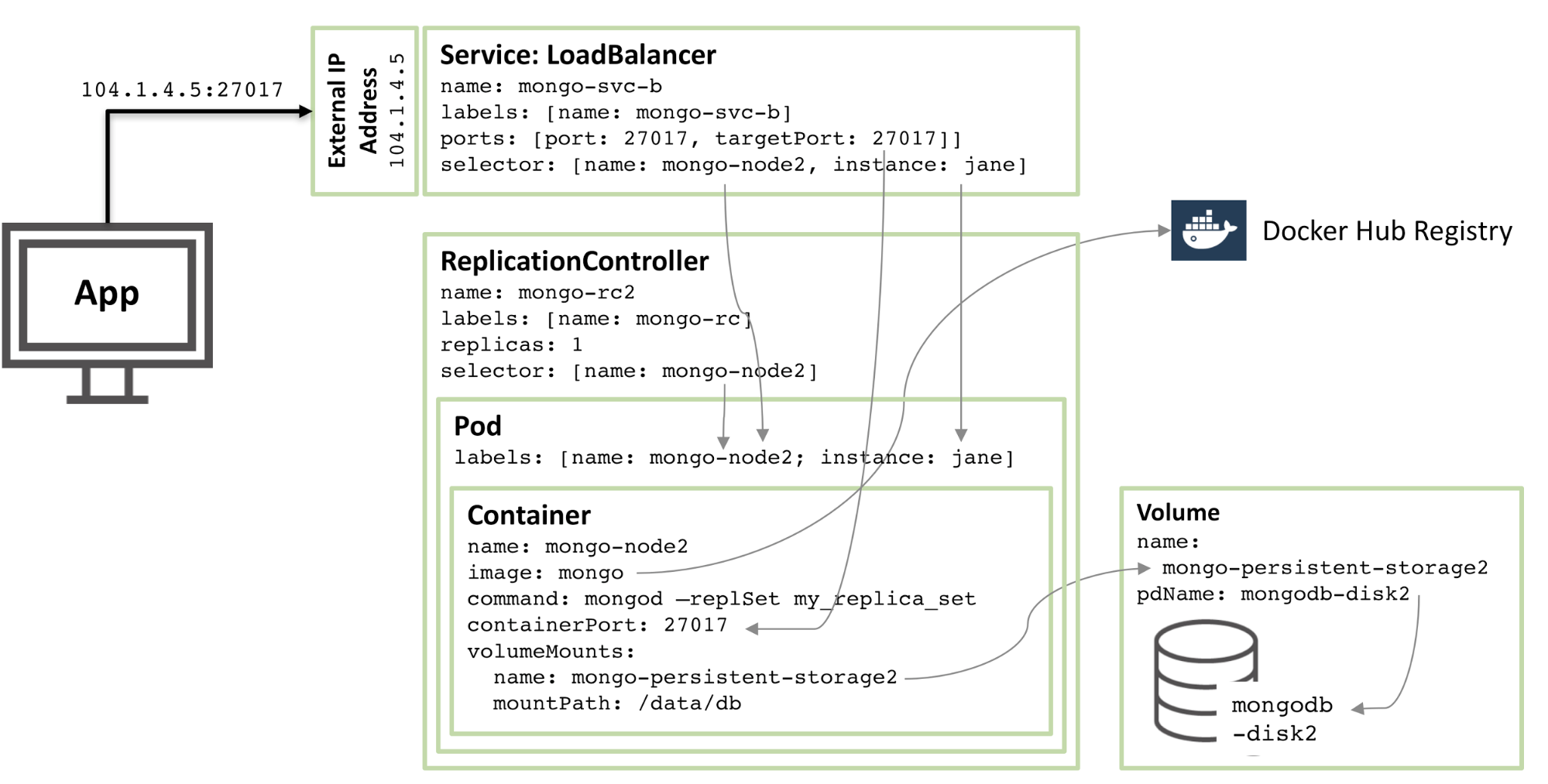
Abbildung 2: Zweites Mitglied des MongoDB-Replikatsatzes, konfiguriert als Kubernetes-Pod
Abbildung 2: Zweites Mitglied des MongoDB-Replikatsatzes, konfiguriert als Kubernetes-Pod
90 % der Konfiguration sind gleich, nur diese Änderungen:
Festplatten- und Volume-Namen müssen eindeutig sein, daher werden mongodb-disk2 und mongo-persistent-storage2 verwendet
Dem Pod wird die Bezeichnung „Instanz: Jane“ und der Name „Mongo-Node2“ zugewiesen, sodass der neue Dienst mithilfe des Selektors vom in Abbildung 1 gezeigten Rod-Pod unterschieden werden kann.
Der Kopiercontroller heißt mongo-rc2
Der Dienst heißt mongo-svc-b und erhält eine eindeutige externe IP-Adresse (in diesem Fall Kubernetes zugewiesen 104.1.4.5)
Die Konfiguration des dritten Replikatmitglieds folgt dem gleichen Muster und das Bild unten zeigt den vollständigen Replikatsatz:
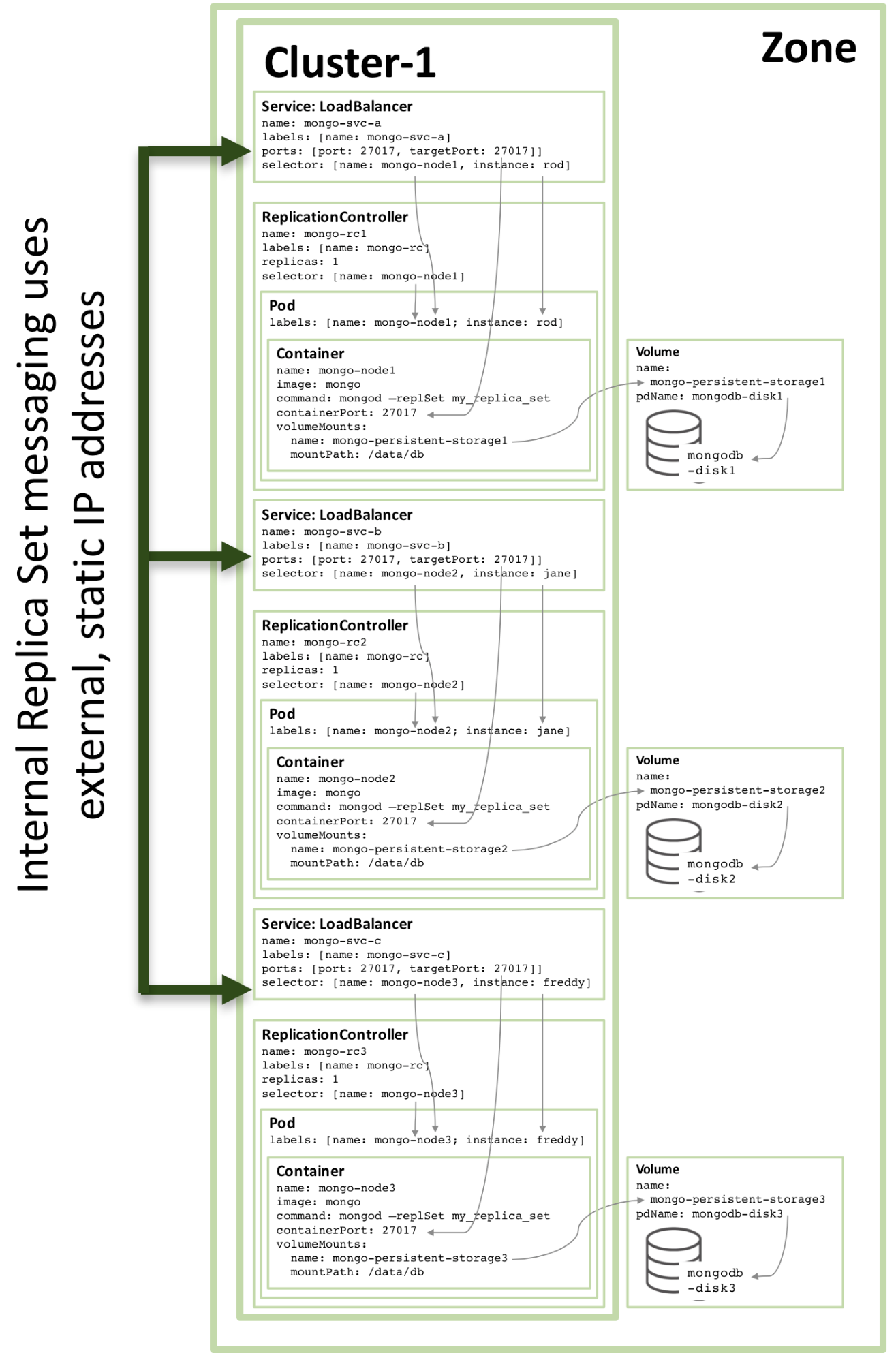
Abbildung 3: Vollständiges Replikatsatzmitglied, konfiguriert als Kubernetes-Dienst
Abbildung 3: Mitglied des vollständigen Replikatsatzes, konfiguriert als Kubernetes-Dienst
Beachten Sie, dass selbst wenn die in Abbildung 3 dargestellte Konfiguration auf einem Kubernetes-Cluster mit drei oder mehr Knoten ausgeführt wird, Kubernetes möglicherweise zwei oder mehr Mitglieder des MongoDB-Replikatsatzes auf demselben Host orchestriert (und dies häufig auch tut). Dies liegt daran, dass Kubernetes die drei Pods als zu drei separaten Diensten gehörend behandelt.
Um die Redundanz innerhalb der Zone zu erhöhen, kann ein zusätzlicher Headless-Dienst erstellt werden. Der neue Dienst bietet der Außenwelt keine Funktionalität (er wird nicht einmal eine IP-Adresse haben), aber er ermöglicht es Kubernetes, drei MongoDB-Pods zu benachrichtigen, um einen Dienst zu bilden, sodass Kubernetes versuchen wird, sie auf verschiedenen Knoten zu orchestrieren.
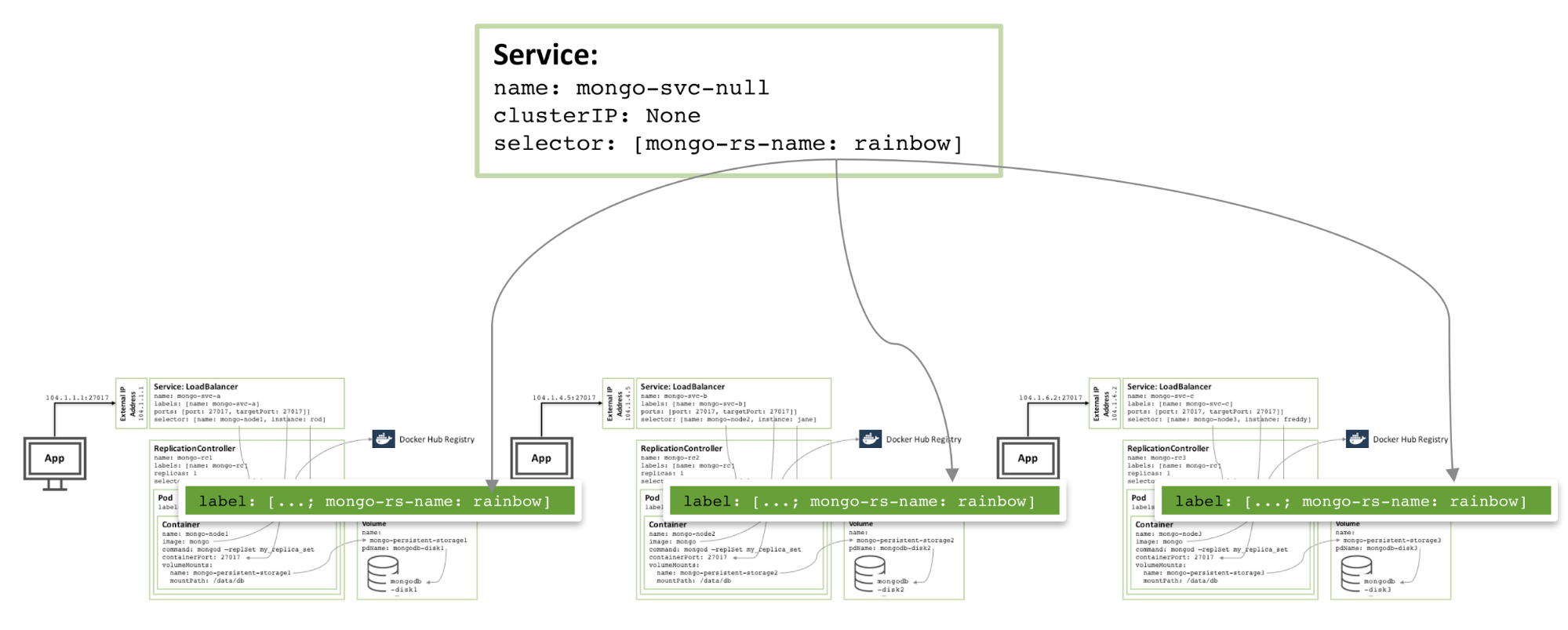
Abbildung 4: Headless-Dienste, die Mitglieder desselben MongoDB-Replikatsatzes meiden
Abbildung 4: Headless-Dienste, die Mitglieder desselben MongoDB-Replikatsatzes meiden
Die tatsächlichen Konfigurationsdateien und Befehle, die zum Konfigurieren und Starten eines MongoDB-Replikatsatzes erforderlich sind, finden Sie im Whitepaper „Enabling Microservices: Elucidating Containers and Orchestration“. Insbesondere sind einige der in diesem Artikel beschriebenen besonderen Schritte erforderlich, um drei MongoDB-Instanzen zu einem funktionsfähigen, robusten Replikatsatz zu kombinieren.
Der oben erstellte Replikatsatz ist riskant, da alles im selben GCE-Cluster und daher in derselben Verfügbarkeitszone ausgeführt wird. Wenn eine Availability Zone aufgrund eines Großereignisses offline geht, ist der MongoDB-Replikatsatz nicht verfügbar. Wenn geografische Redundanz erforderlich ist, sollten die drei Pods in drei verschiedenen Availability Zones oder Regionen ausgeführt werden.
Überraschenderweise waren nur sehr wenige Änderungen erforderlich, um ähnliche Replikatsätze zu erstellen, die auf drei Regionen aufgeteilt waren (wofür drei Cluster erforderlich waren). Jeder Cluster erfordert eine eigene Kubernetes-YAML-Datei, die die Pods, Replikationscontroller und Dienste für nur ein Mitglied dieses Replikatsatzes definiert. Dann ist es ganz einfach, für jede Region einen Cluster, persistenten Speicher und MongoDB-Knoten zu erstellen.
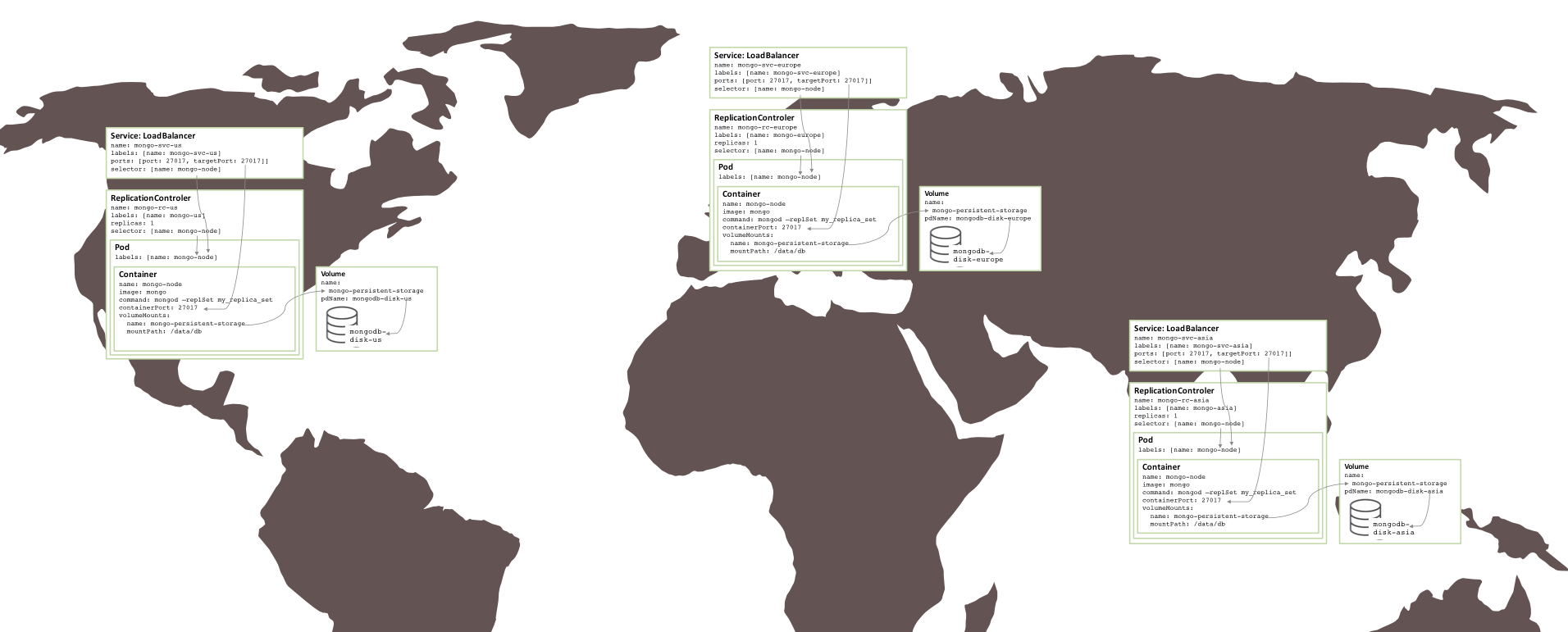
Abbildung 5: Replikatsatz, der in mehreren Verfügbarkeitszonen ausgeführt wird
Abbildung 5: Replikatsatz, der in mehreren Verfügbarkeitszonen ausgeführt wird
Nächster Schritt
Um mehr über Container und Orchestrierung zu erfahren – die beteiligten Technologien und die Geschäftsvorteile, die sie bieten – lesen Sie das Whitepaper „Enabling Microservices: Containers and Orchestration Explained“. Dieses Dokument enthält vollständige Anweisungen zum Abrufen des in diesem Artikel beschriebenen Replikatsatzes und zum Ausführen auf Docker und Kubernetes in Google Container Engine.
Über den Autor:
Andrew ist General Manager für Produktmarketing bei MongoDB. Er kam letzten Sommer von Oracle zu MongoDB, wo er mehr als sechs Jahre im Produktmanagement mit Schwerpunkt auf Hochverfügbarkeit tätig war. Er kann unter @andrewmorgan oder durch Kommentieren in seinem Blog (clusterdb.com) erreicht werden.
Das obige ist der detaillierte Inhalt vonKonfigurieren Sie den Mongodb-Dienst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



