

Groß angelegte Sprachmodelle (LLM) haben sowohl in der Wissenschaft als auch in der Industrie enorme Fortschritte gemacht. Das Training und die Bereitstellung von LLM sind jedoch sehr teuer und erfordern viele Rechenressourcen und Speicher. Daher haben Forscher viele Open-Source-Frameworks und -Methoden entwickelt, um das LLM-Vortraining, die Feinabstimmung und die Inferenz zu beschleunigen. Allerdings kann die Laufzeitleistung verschiedener Hardware- und Software-Stacks erheblich variieren, was es schwierig macht, die beste Konfiguration auszuwählen.
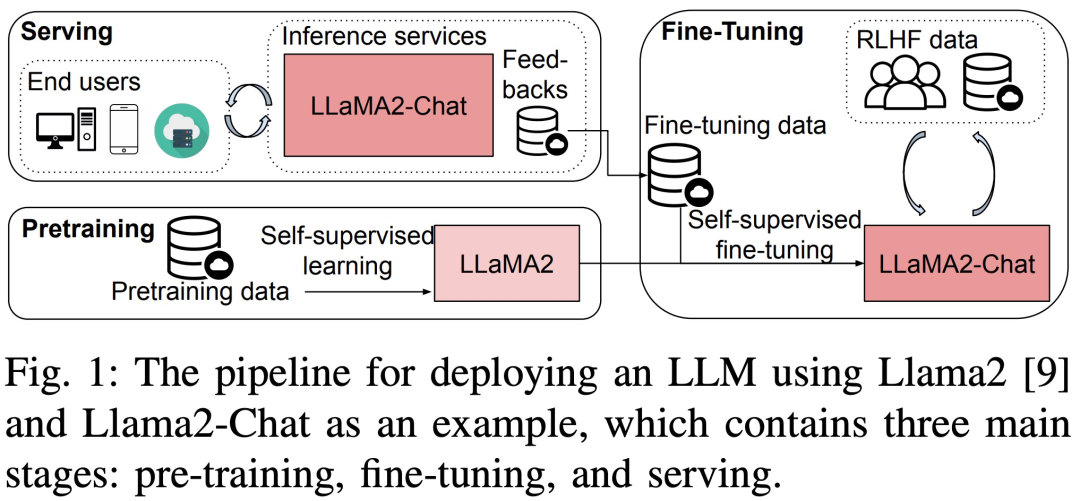
Kürzlich wurde in einem neuen Artikel mit dem Titel „Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models“ das LLM-Training, die Feinabstimmung und die Laufzeitleistung von Inferenz im Detail analysiert.

Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/pdf/2311.03687.pdf
Konkret wurde diese Forschung zunächst an drei 8-GPUs in verschiedenen Maßstäben durchgeführt ( 7B , 13B- und 70B-Parameter) LLM führte einen vollständigen Leistungs-Benchmark-Test durch, ohne die ursprüngliche Bedeutung für Vorschulung, Feinabstimmung und Service zu ändern. Die Tests umfassten Plattformen mit und ohne individuelle Optimierungstechnologien, darunter ZeRO, Quantize, Recalculate und FlashAttention. Die Studie bietet dann außerdem eine detaillierte Laufzeitanalyse der Untermodule von Berechnungs- und Kommunikationsoperatoren in LLM Die Schrittzeitleistung, die Zeitleistung auf Modulebene und die Bedienerzeitleistung auf einer 8-GPU-Hardwareplattform sind in Abbildung 3 dargestellt.
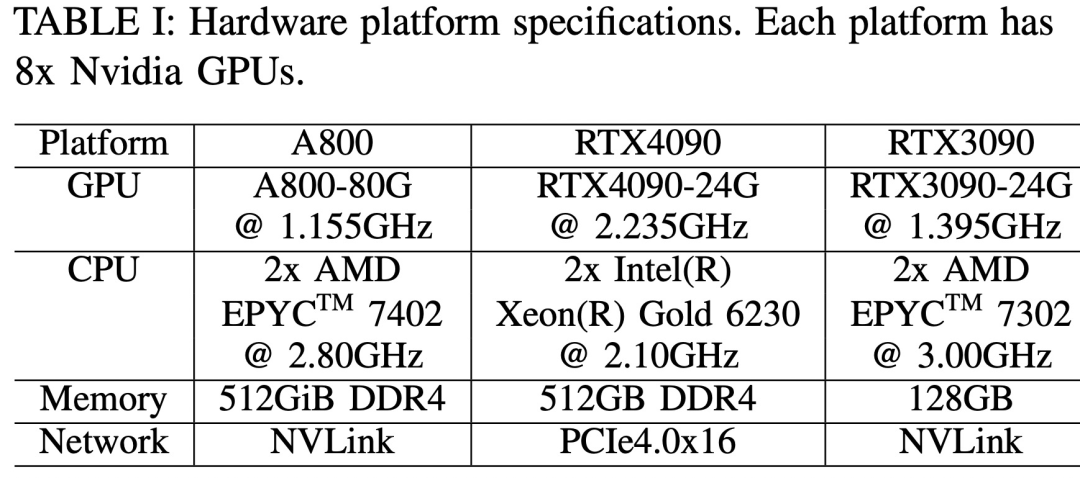
Die drei Hardwareplattformen sind RTX4090, RTX3090 und A800. Die spezifischen Spezifikationen sind in Tabelle 1 unten aufgeführt.
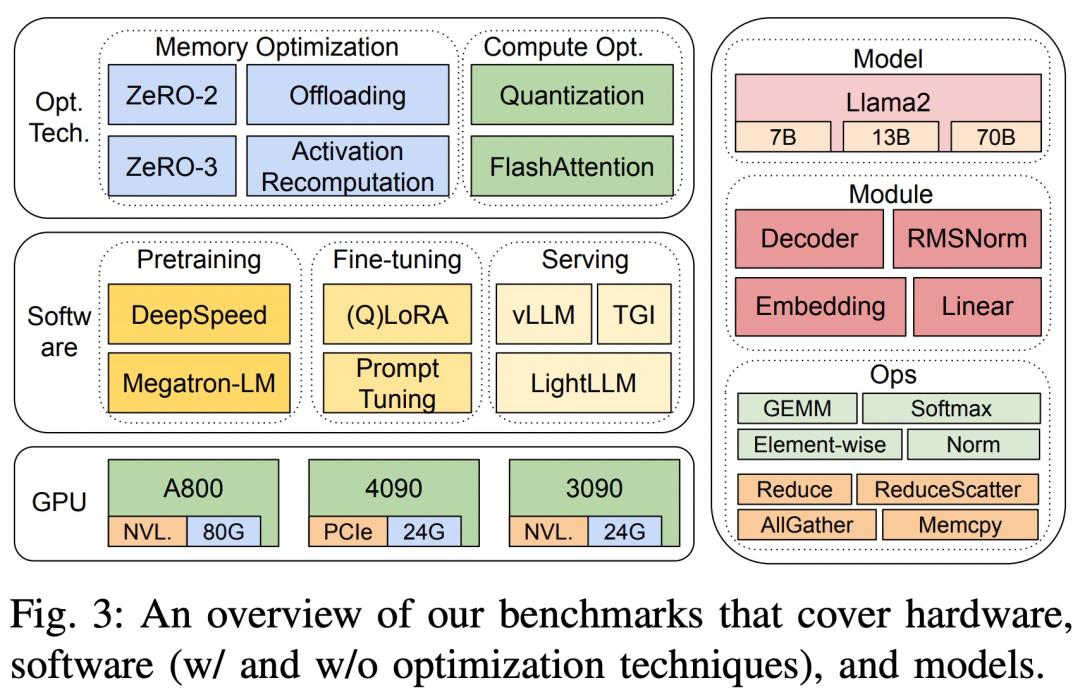
Auf der Softwareseite wurden in der Studie die End-to-End-Schrittzeiten von DeepSpeed und Megatron-LM im Hinblick auf Vortraining und Feinabstimmung verglichen. Um Optimierungstechniken zu bewerten, nutzte die Studie DeepSpeed, um nacheinander die folgenden Optimierungen zu ermöglichen: ZeRO-2, ZeRO-3, Offloading, Aktivierungsneuberechnung, Quantisierung und FlashAttention, um Leistungsverbesserungen und Reduzierungen des Zeit- und Speicherverbrauchs zu messen.
 In Bezug auf LLM-Dienste gibt es drei hochoptimierte Systeme, vLLM, LightLLM und TGI, und diese Studie vergleicht deren Leistung (Latenz und Durchsatz) auf drei Testplattformen.
In Bezug auf LLM-Dienste gibt es drei hochoptimierte Systeme, vLLM, LightLLM und TGI, und diese Studie vergleicht deren Leistung (Latenz und Durchsatz) auf drei Testplattformen.
Um die Genauigkeit und Reproduzierbarkeit der Ergebnisse sicherzustellen, berechnete diese Studie die durchschnittliche Länge der Anweisungen, Eingaben und Ausgaben des gemeinsamen LLM-Datensatzes Alpaka, dh 350 Token pro Probe und zu erreichende zufällig generierte Zeichenfolgen 350 Sequenzlänge.
Im Inferenzdienst werden alle Anforderungen im Burst-Modus geplant, um die Rechenressourcen umfassend zu nutzen und die Robustheit und Effizienz des Frameworks zu bewerten. Der experimentelle Datensatz besteht aus 1000 synthetischen Sätzen, jeder Satz enthält 512 Eingabe-Token. In dieser Studie wird bei allen Experimenten auf derselben GPU-Plattform stets der Parameter „maximal generierte Tokenlänge“ beibehalten, um die Konsistenz und Vergleichbarkeit der Ergebnisse sicherzustellen.
Keine Notwendigkeit, die ursprüngliche Bedeutung zu ändern, volle Leistung
Diese Studie verwendet Indikatoren wie Vortraining, Feinabstimmung und Rückschlüsse auf Schrittzeit, Durchsatz und Speicherverbrauch verschiedener Llama2-Modelle Größen (7B, 13B und 70B), um die volle Leistung auf drei Testplattformen zu messen, ohne die ursprüngliche Bedeutung zu ändern. Drei weit verbreitete Inferenzbereitstellungssysteme: TGI, vLLM und LightLLM werden ebenfalls evaluiert, wobei der Schwerpunkt auf Metriken wie Latenz, Durchsatz und Speicherverbrauch liegt. Leistung auf Modulebene
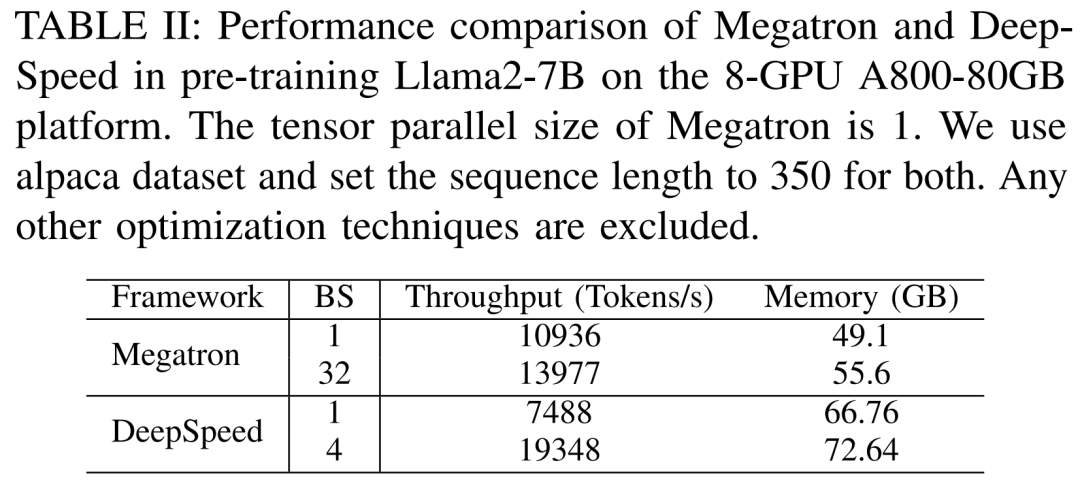
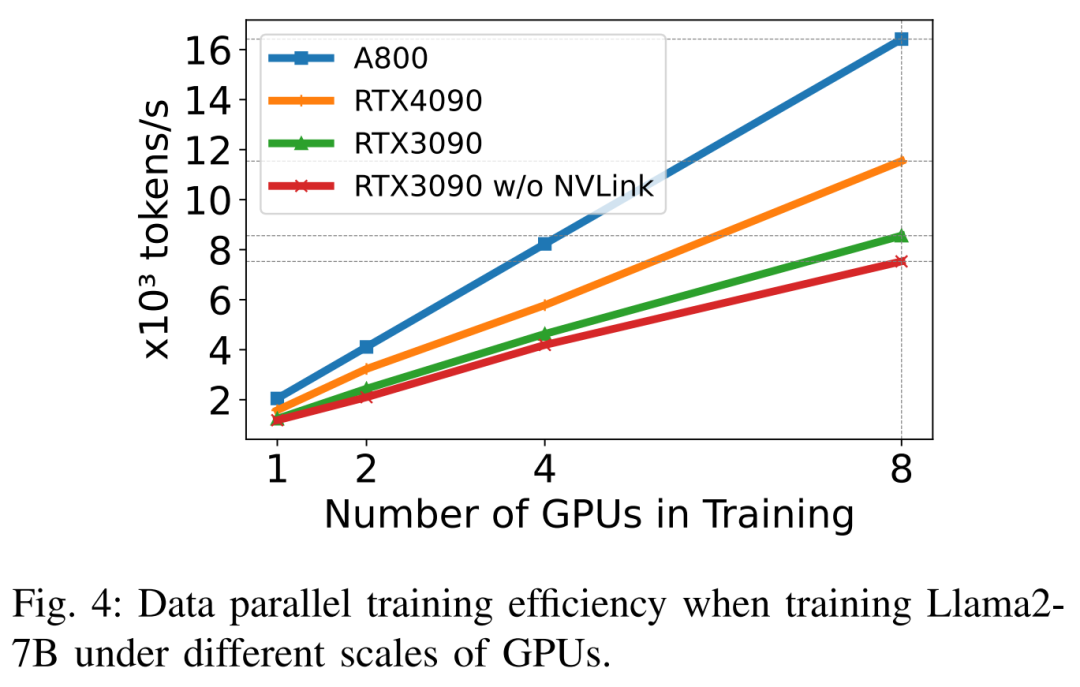
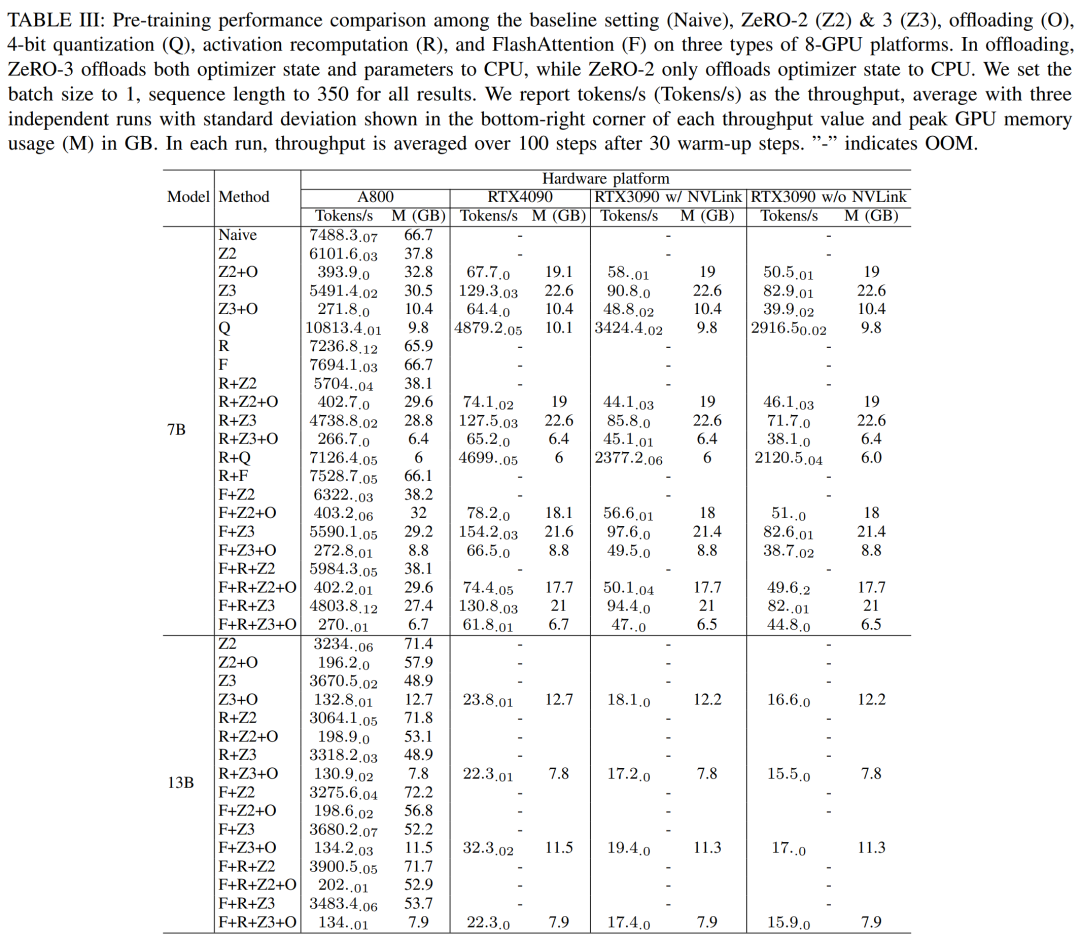
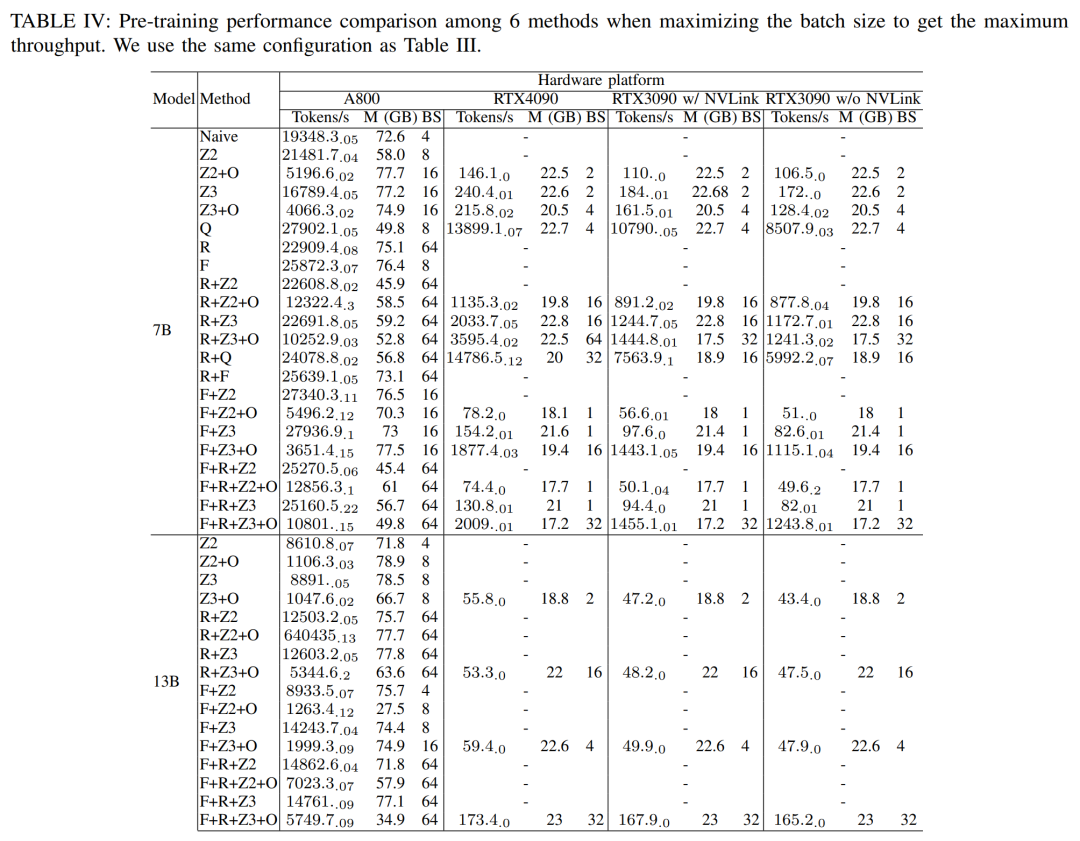
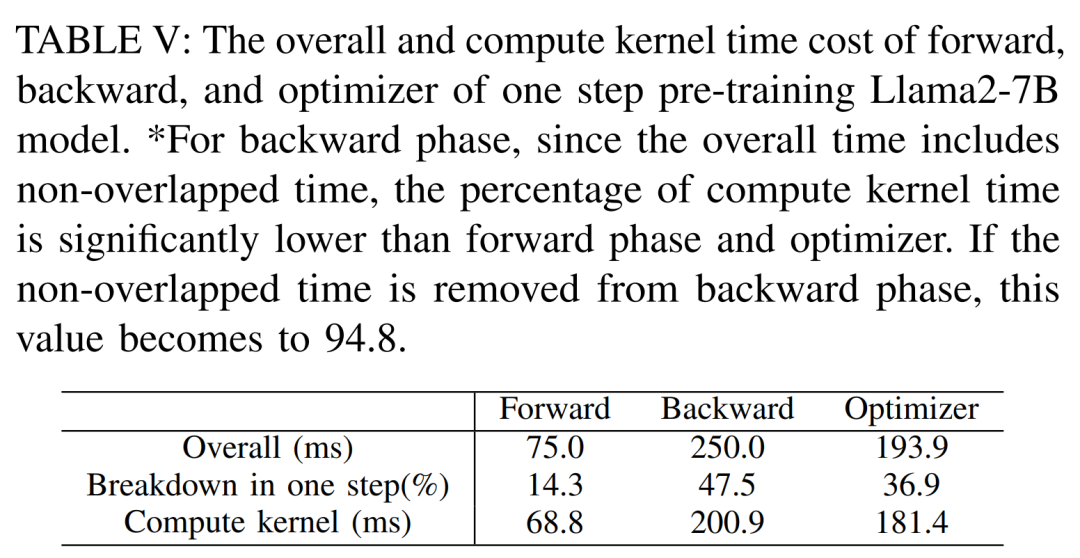
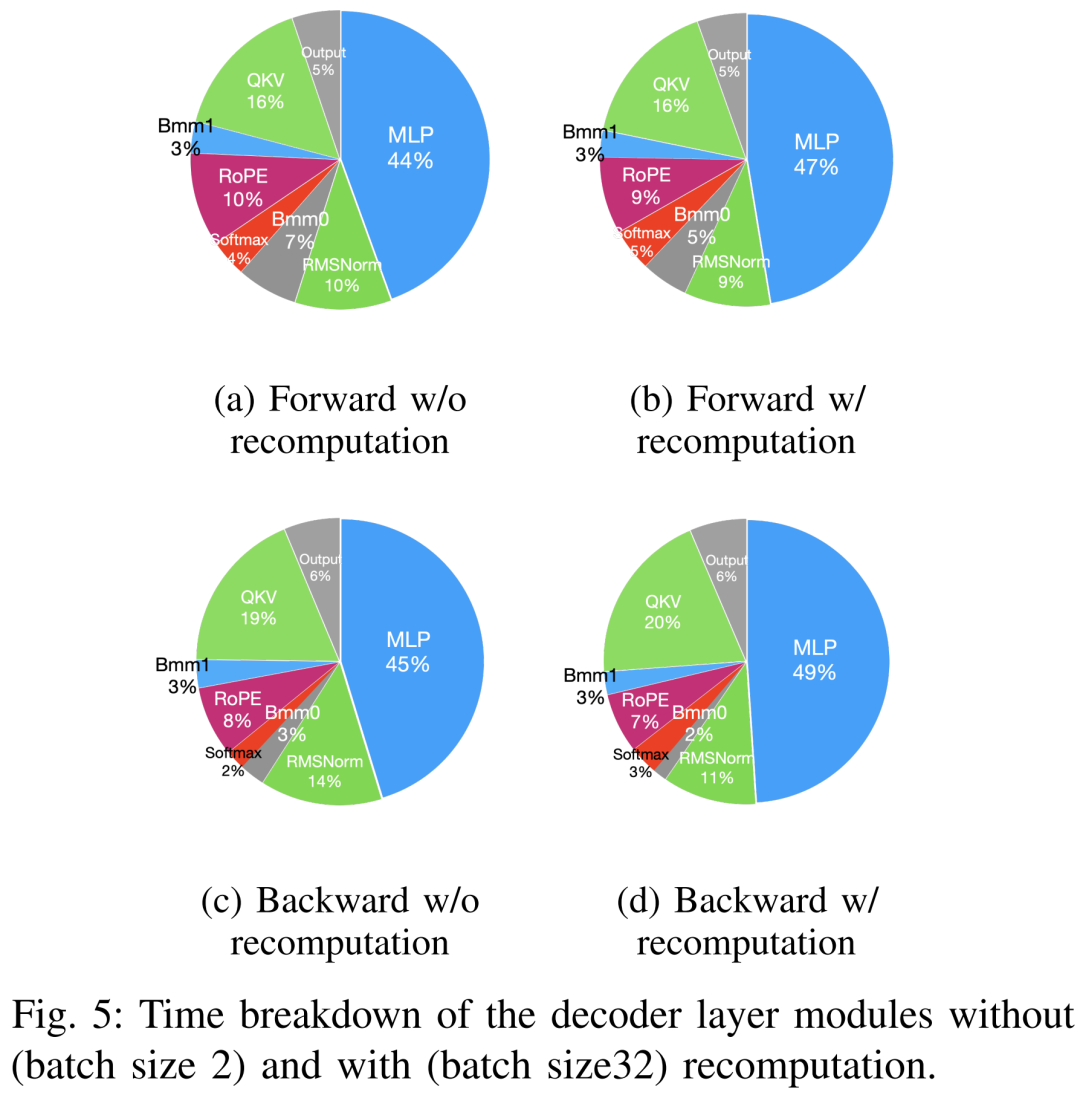
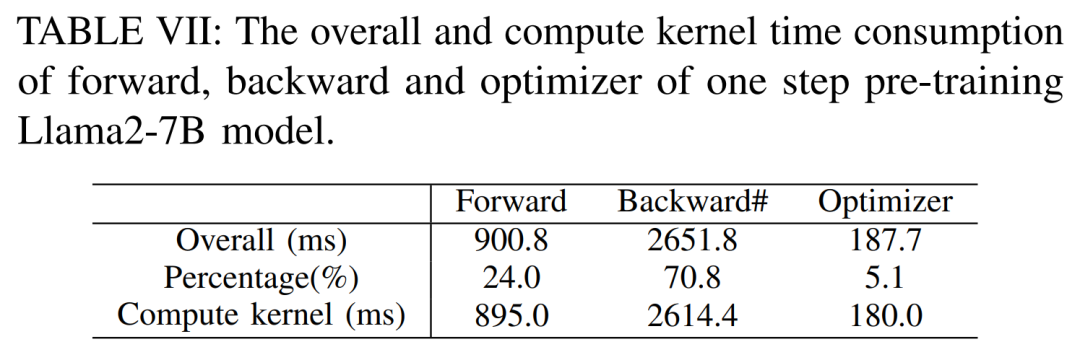
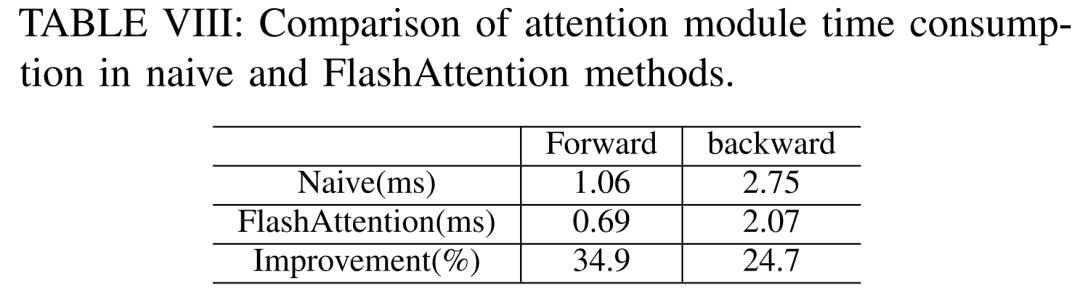
LLM besteht typischerweise aus einer Reihe von Modulen (oder Schichten), die einzigartige Rechen- und Kommunikationseigenschaften aufweisen können. Die Schlüsselmodule, aus denen das Llama2-Modell besteht, sind beispielsweise Embedding, LlamaDecoderLayer, Linear, SiLUActivation und LlamaRMSNorm. In der Experimentiersitzung vor dem Training analysierten die Forscher zunächst die Leistung vor dem Training (Iterationszeit oder Durchsatz, Speicherverbrauch) von Modellen unterschiedlicher Größe (7B, 13B und 70B) in drei Tests Anschließend wurden Mikrobenchmarks auf Modul- und Betriebsebene durchgeführt. Keine Notwendigkeit, die ursprüngliche Bedeutung zu ändern, volle Leistung Die Forscher führten zunächst Experimente durch, um die Leistung von Megatron-LM und DeepSpeed zu vergleichen, die beim Vortraining von Llama2-7B nicht verwendet wurden der A800-80GB-Server. Jede Speicheroptimierungstechnologie (z. B. ZeRO). Sie verwendeten eine Sequenzlänge von 350 und stellten zwei Sätze von Chargengrößen für Megatron-LM und DeepSpeed bereit, von 1 bis zur maximalen Chargengröße. Die Ergebnisse sind in Tabelle II unten aufgeführt und werden anhand des Trainingsdurchsatzes (Tokens/Sekunde) und des GPU-Speichers für Endverbraucher (in GB) verglichen. Die Ergebnisse zeigen, dass Megatron-LM etwas schneller als DeepSpeed ist, wenn die Chargengröße beide 1 beträgt. Allerdings ist DeepSpeed die höchste Trainingsgeschwindigkeit, wenn die Batch-Größe ihr Maximum erreicht. Bei gleichen Batch-Größen verbraucht DeepSpeed mehr GPU-Speicher als der auf Tensor-Parallel basierende Megatron-LM. Selbst bei kleinen Batch-Größen verbrauchten beide Systeme erhebliche Mengen an GPU-Speicher, was zu einem Speicherüberlauf auf den GPU-Servern RTX4090 oder RTX3090 führte. Beim Training von Llama2-7B (Sequenzlänge 350, Batchgröße 2) verwendeten die Forscher DeepSpeed mit Quantisierung, um die Skalierungseffizienz auf verschiedenen Hardwareplattformen zu untersuchen. Die Ergebnisse sind in Abbildung 4 unten dargestellt. Der A800 skaliert nahezu linear, und die Skalierungseffizienz von RTX4090 und RTX3090 ist mit 90,8 % bzw. 85,9 % etwas geringer. Auf der RTX3090-Plattform sind NVLink-Verbindungen 10 % effizienter als ohne NVLink. Forscher nutzen DeepSpeed, um die Trainingsleistung mit verschiedenen speicher- und recheneffizienten Methoden zu bewerten. Aus Gründen der Fairness sind alle Auswertungen auf eine Sequenzlänge von 350, eine Stapelgröße von 1 und eine standardmäßig geladene Modellgewichtung von bf16 eingestellt. Für ZeRO-2 und ZeRO-3 mit Offloading-Funktionen laden sie den Optimiererstatus und den Optimiererstatus + Modell jeweils in den CPU-RAM aus. Zur Quantisierung verwendeten sie eine 4-Bit-Konfiguration mit doppelter Quantisierung. Außerdem wird die Leistung des RTX3090 berichtet, wenn NVLink deaktiviert ist (d. h. alle Daten werden über den PCIe-Bus übertragen). Die Ergebnisse sind in der folgenden Tabelle III aufgeführt. Um einen maximalen Durchsatz zu erzielen, nutzten die Forscher zusätzlich die Rechenleistung verschiedener GPU-Server, indem sie die Stapelgröße jeder Methode maximierten. Die Ergebnisse sind in Tabelle IV aufgeführt und zeigen, dass eine Erhöhung der Batchgröße den Trainingsprozess leicht verbessern kann. Daher eignen sich GPU-Server mit hoher Bandbreite und großem Speicher besser für das Training mit gemischter Präzision mit vollständigen Parametern als GPU-Server für Endverbraucher. Gesamt- und Rechenkernzeitaufwand für das Training des Vorwärts-, Rückwärts- und Optimierers des Llama2-7B-Modells. Für die Rückwärtsphase ist die Rechenkernzeit viel kleiner als für die Vorwärtsphase und den Optimierer, da die Gesamtzeit die nicht überlappende Zeit umfasst. Wenn die nicht überlappende Zeit aus der Rückwärtsphase entfernt wird, beträgt der Wert 94,8. Die Auswirkungen von FlashAttention müssen neu berechnet und bewertet werden. Techniken zur Beschleunigung des Vortrainings können grob in zwei Kategorien unterteilt werden: Speicher sparen, Stapelgröße erhöhen und Berechnung beschleunigen Kerne. Wie in Abbildung 5 unten dargestellt, verbringt die GPU während der Vorwärts-, Rückwärts- und Optimierungsphase 5–10 % ihrer Zeit im Leerlauf. Die Forscher gingen davon aus, dass diese Leerlaufzeit auf kleinere Chargengrößen zurückzuführen war, und testeten daher alle Techniken mit den größten verfügbaren Chargengrößen. Schließlich führten sie eine Neuberechnung ein, um die Stapelgröße zu erhöhen, und nutzten FlashAttention, um die Berechnung der Kernanalyse zu beschleunigen Wie in Tabelle VII unten gezeigt, erhöhen sich mit zunehmender Stapelgröße die Vorwärts- und Rückwärtsphasenzeiten erheblich, sodass fast keine GPU-Leerlaufzeit entsteht. Gemäß Tabelle VIII unten kann FlashAttention die Vorwärts- und Rückwärtsaufmerksamkeitsmodule um 34,9 % bzw. 24,7 % beschleunigen , die Forscher Die Parametereffiziente Feinabstimmungsmethode (PEFT) wird hauptsächlich diskutiert, um die Feinabstimmungsleistung von LoRA und QLoRA unter verschiedenen Modellgrößen und Hardwareeinstellungen zu demonstrieren. Verwenden Sie eine Sequenzlänge von 350, eine Stapelgröße von 1 und laden Sie die Modellgewichte standardmäßig in bf16. Wenn jedoch alle Optimierungstechniken kombiniert werden, können sogar RTX4090 und RTX3090 Llama2-70B feinabstimmen, um 200 zu erreichen Tokens/Sek. Gesamtdurchsatz. Inferenzergebnisse
Diese experimentellen Ergebnisse zeigen, dass das TGI-Inferenz-Framework auf der 24-GB-Speicher-GPU-Plattform eine hervorragende Leistung aufweist, während das LightLLM-Inferenz-Framework auf der A800-80-GB-GPU-Plattform den höchsten Durchsatz aufweist. Dieses Ergebnis legt nahe, dass LightLLM speziell für die Hochleistungs-GPUs der A800/A100-Serie optimiert ist. Die Latenzleistung unter verschiedenen Hardwareplattformen und Inferenz-Frameworks ist in den Abbildungen 7, 8, 9 und 10 dargestellt Umfassend Wie oben gezeigt, ist die A800-Plattform hinsichtlich Durchsatz und Latenz deutlich besser als die beiden Consumer-Plattformen RTX4090 und RTX3090. Und unter den beiden Consumer-Plattformen hat die RTX3090 einen leichten Vorteil gegenüber der RTX4090. Die drei Inferenz-Frameworks TGI, vLLM und LightLLM zeigen keinen wesentlichen Unterschied im Durchsatz, wenn sie auf Plattformen der Verbraucherklasse ausgeführt werden. Im Vergleich dazu übertrifft TGI die anderen beiden in Bezug auf die Latenz durchweg. Auf der A800-GPU-Plattform schneidet LightLLM hinsichtlich des Durchsatzes am besten ab und auch seine Latenz kommt dem TGI-Framework sehr nahe. Ergebnisse vor dem Training
 Gemäß den Ergebnissen in Tabelle IX unten stimmt der Leistungstrend nach der Feinabstimmung von Llama2-13B mit LoRA und QLoRA mit Llama2-7B überein. Im Vergleich zu Llama2-7B sank der Durchsatz des fein abgestimmten Llama2-13B um etwa 30 %
Gemäß den Ergebnissen in Tabelle IX unten stimmt der Leistungstrend nach der Feinabstimmung von Llama2-13B mit LoRA und QLoRA mit Llama2-7B überein. Im Vergleich zu Llama2-7B sank der Durchsatz des fein abgestimmten Llama2-13B um etwa 30 %
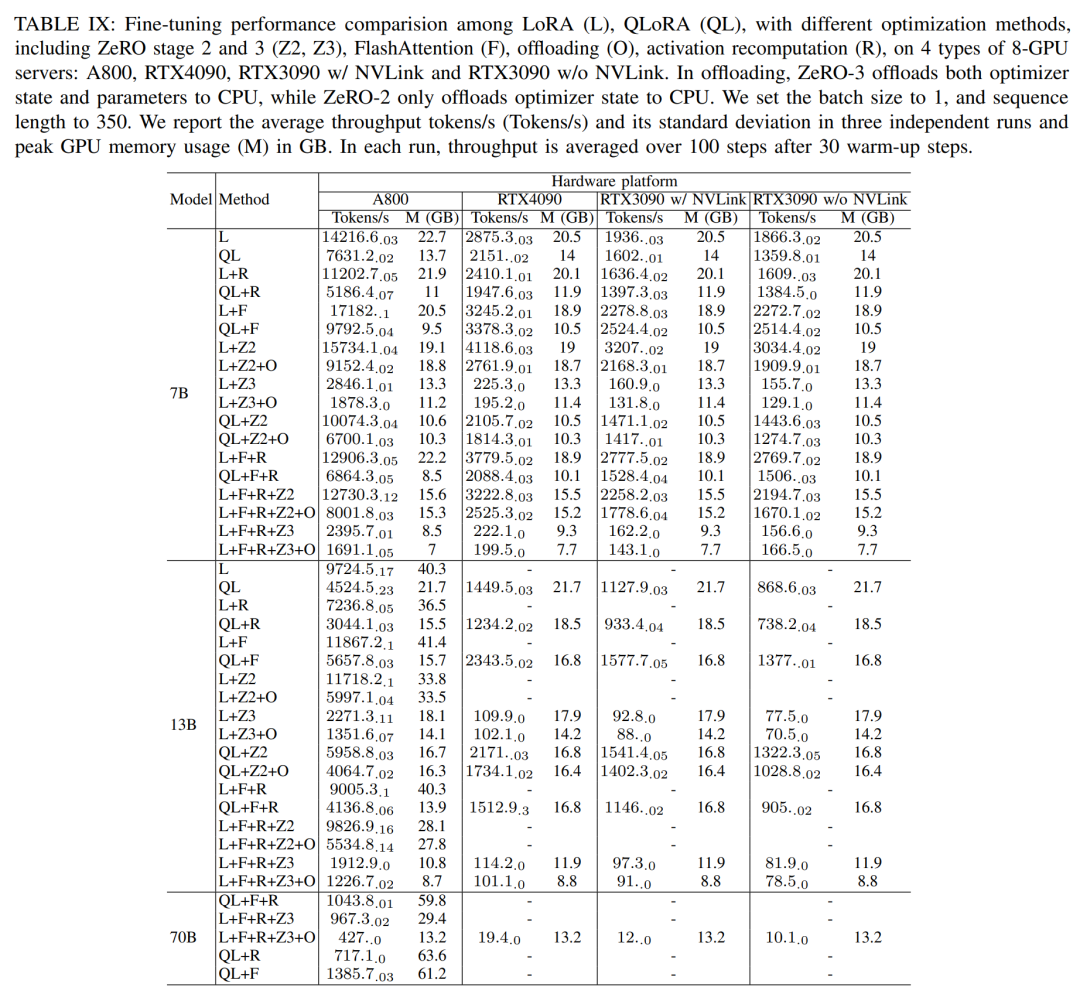
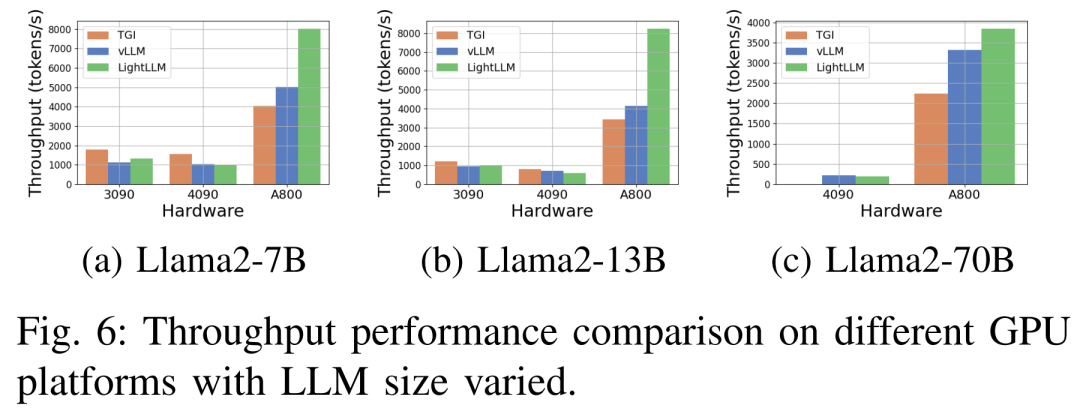
Abbildung 6 unten zeigt eine umfassende Analyse des Durchsatzes unter verschiedenen Hardwareplattformen und Inferenzframeworks, wobei Llama2-70B weggelassen wird zugehörige Inferenzdaten. Unter anderem zeigte das TGI-Framework einen hervorragenden Durchsatz, insbesondere auf GPUs mit 24 GB Speicher wie der RTX3090 und der RTX4090. Darüber hinaus übertrifft LightLLM TGI und vLLM auf der A800-GPU-Plattform deutlich, wobei sich der Durchsatz nahezu verdoppelt.
Das obige ist der detaillierte Inhalt vonA800 übertrifft Llama2 Inference RTX3090 und 4090 deutlich und bietet hervorragende Latenz und Durchsatz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Handelsplattform für digitale Währungen
Handelsplattform für digitale Währungen
 Worauf bezieht sich „Schreiben' in Python?
Worauf bezieht sich „Schreiben' in Python?
 Einführung in PHP-Konfigurationsdateien
Einführung in PHP-Konfigurationsdateien
 Welches Format ist PNG?
Welches Format ist PNG?
 Ist ein Upgrade von Windows 11 notwendig?
Ist ein Upgrade von Windows 11 notwendig?
 Oracle-Datenbank, die die SQL-Methode ausführt
Oracle-Datenbank, die die SQL-Methode ausführt
 So lösen Sie 404 nicht gefunden
So lösen Sie 404 nicht gefunden
 Der heutige Marktpreis von Ethereum
Der heutige Marktpreis von Ethereum








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



