
 Technologie-Peripheriegeräte
KI
Eingehende Analyse der Kernpunkte von Pytorch, CNN-Entschlüsselung!
Technologie-Peripheriegeräte
KI
Eingehende Analyse der Kernpunkte von Pytorch, CNN-Entschlüsselung!
Eingehende Analyse der Kernpunkte von Pytorch, CNN-Entschlüsselung!

Hallo, ich bin Xiaozhuang!
Anfänger sind möglicherweise nicht mit der Erstellung von Faltungs-Neuronalen Netzen (CNN) vertraut. Lassen Sie uns dies anhand eines vollständigen Falls veranschaulichen.
CNN ist ein Deep-Learning-Modell, das häufig bei der Bildklassifizierung, Zielerkennung, Bildgenerierung und anderen Aufgaben verwendet wird. Es extrahiert automatisch Merkmale von Bildern durch Faltungsschichten und Pooling-Schichten und führt die Klassifizierung durch vollständig verbundene Schichten durch. Der Schlüssel zu diesem Modell besteht darin, Faltungs- und Pooling-Operationen zu verwenden, um lokale Merkmale in Bildern effektiv zu erfassen und sie über mehrschichtige Netzwerke zu kombinieren, um eine erweiterte Merkmalsextraktion und Klassifizierung von Bildern zu erreichen.
Prinzip
1. Faltungsschicht:
Die Faltungsschicht extrahiert Merkmale aus dem Eingabebild durch Faltungsoperationen. Bei diesem Vorgang handelt es sich um einen lernbaren Faltungskern, der über das Eingabebild gleitet und das Skalarprodukt unter dem Schiebefenster berechnet. Dieser Prozess hilft bei der Extraktion lokaler Merkmale und verbessert so die Wahrnehmung der Übersetzungsinvarianz durch das Netzwerk.
Formel:
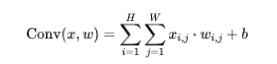
wobei x die Eingabe, w der Faltungskern und b der Bias ist.
2. Pooling-Schicht:
Die Pooling-Schicht ist eine häufig verwendete Dimensionsreduktionstechnologie. Ihre Funktion besteht darin, die räumliche Dimension der Daten zu reduzieren und dadurch den Berechnungsaufwand zu reduzieren und die wichtigsten Merkmale zu extrahieren. Unter diesen ist Max Pooling eine gängige Pooling-Methode, bei der der größte Wert in jedem Fenster als Vertreter ausgewählt wird. Durch maximales Pooling können wir die Komplexität der Daten reduzieren und die Recheneffizienz des Modells verbessern, während wichtige Informationen erhalten bleiben.
Formel (Max Pooling):
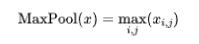
3. Vollständig verbundene Schicht:
Die vollständig verbundene Schicht spielt eine wichtige Rolle im neuronalen Netzwerk. Sie extrahiert die Faltungs- und Pooling-Feature-Maps . Jedes Neuron in der vollständig verbundenen Schicht ist mit allen Neuronen in der vorherigen Schicht verbunden, sodass eine Merkmalssynthese und -klassifizierung erreicht werden kann.
Praktische Schritte und detaillierte Erklärung
1. Schritte
- Importieren Sie die erforderlichen Bibliotheken und Module.
- Definieren Sie die Netzwerkstruktur: Verwenden Sie nn.Module, um eine davon geerbte benutzerdefinierte neuronale Netzwerkklasse zu definieren und die Faltungsschicht, die Aktivierungsfunktion, die Pooling-Schicht und die vollständig verbundene Schicht zu definieren.
- Verlustfunktion und Optimierer definieren.
- Daten laden und vorverarbeiten.
- Trainieren Sie das Netzwerk: Trainieren Sie Netzwerkparameter mithilfe von Trainingsdaten iterativ.
- Testnetzwerk: Verwenden Sie Testdaten, um die Modellleistung zu bewerten.
2. Code-Implementierung
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transforms# 定义卷积神经网络类class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 卷积层1self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(kernel_size=2, stride=2)# 卷积层2self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)# 全连接层self.fc1 = nn.Linear(32 * 7 * 7, 10)# 输入大小根据数据调整def forward(self, x):x = self.conv1(x)x = self.relu(x)x = self.pool(x)x = self.conv2(x)x = self.relu(x)x = self.pool(x)x = x.view(-1, 32 * 7 * 7)x = self.fc1(x)return x# 定义损失函数和优化器net = SimpleCNN()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.001)# 加载和预处理数据transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)# 训练网络num_epochs = 5for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):optimizer.zero_grad()outputs = net(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item()}')# 测试网络net.eval()with torch.no_grad():correct = 0total = 0for images, labels in test_loader:outputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / totalprint('Accuracy on the test set: {}%'.format(100 * accuracy))Dieses Beispiel zeigt ein einfaches CNN-Modell, trainiert und getestet mit dem MNIST-Datensatz.
Als nächstes fügen wir einen Visualisierungsschritt hinzu, um die Leistung und den Trainingsprozess des Modells intuitiver zu verstehen.
Visualisierung
1. Matplotlib importieren
import matplotlib.pyplot as plt
2. Zeichnen Sie Verlust und Genauigkeit während des Trainings auf:
Zeichnen Sie während der Trainingsschleife den Verlust und die Genauigkeit jeder Epoche auf.
# 在训练循环中添加以下代码train_loss_list = []accuracy_list = []for epoch in range(num_epochs):running_loss = 0.0correct = 0total = 0for i, (images, labels) in enumerate(train_loader):optimizer.zero_grad()outputs = net(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item()}')epoch_loss = running_loss / len(train_loader)accuracy = correct / totaltrain_loss_list.append(epoch_loss)accuracy_list.append(accuracy)3. Verlust und Genauigkeit visualisieren:
# 在训练循环后,添加以下代码plt.figure(figsize=(12, 4))# 可视化损失plt.subplot(1, 2, 1)plt.plot(range(1, num_epochs + 1), train_loss_list, label='Training Loss')plt.title('Training Loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.legend()# 可视化准确率plt.subplot(1, 2, 2)plt.plot(range(1, num_epochs + 1), accuracy_list, label='Accuracy')plt.title('Accuracy')plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.legend()plt.tight_layout()plt.show()Auf diese Weise können wir die Veränderungen des Trainingsverlusts und der Genauigkeit nach dem Trainingsprozess sehen.
Nach dem Import des Codes können Sie den visuellen Inhalt und das Format nach Bedarf anpassen.
Das obige ist der detaillierte Inhalt vonEingehende Analyse der Kernpunkte von Pytorch, CNN-Entschlüsselung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 iFlytek: Die Fähigkeiten des Ascend 910B von Huawei sind grundsätzlich mit denen des A100 von Nvidia vergleichbar, und sie arbeiten zusammen, um eine neue Basis für die allgemeine künstliche Intelligenz meines Landes zu schaffen
Oct 22, 2023 pm 06:13 PM
iFlytek: Die Fähigkeiten des Ascend 910B von Huawei sind grundsätzlich mit denen des A100 von Nvidia vergleichbar, und sie arbeiten zusammen, um eine neue Basis für die allgemeine künstliche Intelligenz meines Landes zu schaffen
Oct 22, 2023 pm 06:13 PM
Diese Website berichtete am 22. Oktober, dass iFlytek im dritten Quartal dieses Jahres einen Nettogewinn von 25,79 Millionen Yuan erzielte, was einem Rückgang von 81,86 % gegenüber dem Vorjahr entspricht; der Nettogewinn in den ersten drei Quartalen betrug 99,36 Millionen Yuan Rückgang um 76,36 % gegenüber dem Vorjahr. Jiang Tao, Vizepräsident von iFlytek, gab bei der Leistungsbesprechung im dritten Quartal bekannt, dass iFlytek Anfang 2023 ein spezielles Forschungsprojekt mit Huawei Shengteng gestartet und gemeinsam mit Huawei eine leistungsstarke Betreiberbibliothek entwickelt hat, um gemeinsam eine neue Basis für Chinas allgemeine künstliche Intelligenz zu schaffen Intelligenz, die den Einsatz inländischer Großmodelle ermöglicht. Die Architektur basiert auf unabhängig innovativer Soft- und Hardware. Er wies darauf hin, dass die aktuellen Fähigkeiten des Huawei Ascend 910B grundsätzlich mit dem A100 von Nvidia vergleichbar seien. Auf dem bevorstehenden iFlytek 1024 Global Developer Festival werden iFlytek und Huawei weitere gemeinsame Ankündigungen zur Rechenleistungsbasis für künstliche Intelligenz machen. Er erwähnte auch,
 Die perfekte Kombination aus PyCharm und PyTorch: detaillierte Installations- und Konfigurationsschritte
Feb 21, 2024 pm 12:00 PM
Die perfekte Kombination aus PyCharm und PyTorch: detaillierte Installations- und Konfigurationsschritte
Feb 21, 2024 pm 12:00 PM
PyCharm ist eine leistungsstarke integrierte Entwicklungsumgebung (IDE) und PyTorch ist ein beliebtes Open-Source-Framework im Bereich Deep Learning. Im Bereich maschinelles Lernen und Deep Learning kann die Verwendung von PyCharm und PyTorch für die Entwicklung die Entwicklungseffizienz und Codequalität erheblich verbessern. In diesem Artikel wird detailliert beschrieben, wie PyTorch in PyCharm installiert und konfiguriert wird, und es werden spezifische Codebeispiele angehängt, um den Lesern zu helfen, die leistungsstarken Funktionen dieser beiden besser zu nutzen. Schritt 1: Installieren Sie PyCharm und Python
 Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Bei Aufgaben zur Generierung natürlicher Sprache ist die Stichprobenmethode eine Technik, um eine Textausgabe aus einem generativen Modell zu erhalten. In diesem Artikel werden fünf gängige Methoden erläutert und mit PyTorch implementiert. 1. GreedyDecoding Bei der Greedy-Decodierung sagt das generative Modell die Wörter der Ausgabesequenz basierend auf der Eingabesequenz Zeit Schritt für Zeit voraus. In jedem Zeitschritt berechnet das Modell die bedingte Wahrscheinlichkeitsverteilung jedes Wortes und wählt dann das Wort mit der höchsten bedingten Wahrscheinlichkeit als Ausgabe des aktuellen Zeitschritts aus. Dieses Wort wird zur Eingabe für den nächsten Zeitschritt und der Generierungsprozess wird fortgesetzt, bis eine Abschlussbedingung erfüllt ist, beispielsweise eine Sequenz mit einer bestimmten Länge oder eine spezielle Endmarkierung. Das Merkmal von GreedyDecoding besteht darin, dass die aktuelle bedingte Wahrscheinlichkeit jedes Mal die beste ist
 Implementierung eines Rauschentfernungs-Diffusionsmodells mit PyTorch
Jan 14, 2024 pm 10:33 PM
Implementierung eines Rauschentfernungs-Diffusionsmodells mit PyTorch
Jan 14, 2024 pm 10:33 PM
Bevor wir das Funktionsprinzip des Denoising Diffusion Probabilistic Model (DDPM) im Detail verstehen, wollen wir zunächst einige Aspekte der Entwicklung generativer künstlicher Intelligenz verstehen, die auch zu den Grundlagenforschungen von DDPM gehört. VAEVAE verwendet einen Encoder, einen probabilistischen latenten Raum und einen Decoder. Während des Trainings sagt der Encoder den Mittelwert und die Varianz jedes Bildes voraus und tastet diese Werte aus einer Gaußschen Verteilung ab. Das Ergebnis der Abtastung wird an den Decoder weitergeleitet, der das Eingabebild in eine dem Ausgabebild ähnliche Form umwandelt. Zur Berechnung des Verlusts wird die KL-Divergenz verwendet. Ein wesentlicher Vorteil von VAE ist die Fähigkeit, vielfältige Bilder zu erzeugen. In der Abtastphase kann man direkt aus der Gaußschen Verteilung Stichproben ziehen und über den Decoder neue Bilder erzeugen. GAN hat in nur einem Jahr große Fortschritte bei Variational Autoencodern (VAEs) gemacht.
 Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Als leistungsstarkes Deep-Learning-Framework wird PyTorch häufig in verschiedenen maschinellen Lernprojekten eingesetzt. Als leistungsstarke integrierte Python-Entwicklungsumgebung kann PyCharm auch bei der Umsetzung von Deep-Learning-Aufgaben eine gute Unterstützung bieten. In diesem Artikel wird die Installation von PyTorch in PyCharm ausführlich vorgestellt und spezifische Codebeispiele bereitgestellt, um den Lesern den schnellen Einstieg in die Verwendung von PyTorch für Deep-Learning-Aufgaben zu erleichtern. Schritt 1: Installieren Sie PyCharm. Zuerst müssen wir sicherstellen, dass wir es haben
 Deep Learning mit PHP und PyTorch
Jun 19, 2023 pm 02:43 PM
Deep Learning mit PHP und PyTorch
Jun 19, 2023 pm 02:43 PM
Deep Learning ist ein wichtiger Zweig im Bereich der künstlichen Intelligenz und hat in den letzten Jahren immer mehr Aufmerksamkeit erhalten. Um Deep-Learning-Forschung und -Anwendungen durchführen zu können, ist es oft notwendig, einige Deep-Learning-Frameworks zu verwenden, um dies zu erreichen. In diesem Artikel stellen wir vor, wie man PHP und PyTorch für Deep Learning verwendet. 1. Was ist PyTorch? PyTorch ist ein von Facebook entwickeltes Open-Source-Framework für maschinelles Lernen. Es kann uns helfen, schnell Deep-Learning-Modelle zu erstellen und zu trainieren. PyTorc
 so schnell! Erkennen Sie Videosprache in nur wenigen Minuten mit weniger als 10 Codezeilen in Text
Feb 27, 2024 pm 01:55 PM
so schnell! Erkennen Sie Videosprache in nur wenigen Minuten mit weniger als 10 Codezeilen in Text
Feb 27, 2024 pm 01:55 PM
Hallo zusammen, ich bin Kite. Die Notwendigkeit, Audio- und Videodateien in Textinhalte umzuwandeln, war vor zwei Jahren schwierig, aber jetzt kann dies problemlos in nur wenigen Minuten gelöst werden. Es heißt, dass einige Unternehmen, um Trainingsdaten zu erhalten, Videos auf Kurzvideoplattformen wie Douyin und Kuaishou vollständig gecrawlt haben, dann den Ton aus den Videos extrahiert und sie in Textform umgewandelt haben, um sie als Trainingskorpus für Big-Data-Modelle zu verwenden . Wenn Sie eine Video- oder Audiodatei in Text konvertieren müssen, können Sie diese heute verfügbare Open-Source-Lösung ausprobieren. Sie können beispielsweise nach bestimmten Zeitpunkten suchen, zu denen Dialoge in Film- und Fernsehsendungen erscheinen. Kommen wir ohne weitere Umschweife zum Punkt. Whisper ist OpenAIs Open-Source-Whisper. Es ist natürlich in Python geschrieben und erfordert nur ein paar einfache Installationspakete.
 Detaillierte Erläuterung der GQA, des in großen Modellen häufig verwendeten Aufmerksamkeitsmechanismus und der Pytorch-Codeimplementierung
Apr 03, 2024 pm 05:40 PM
Detaillierte Erläuterung der GQA, des in großen Modellen häufig verwendeten Aufmerksamkeitsmechanismus und der Pytorch-Codeimplementierung
Apr 03, 2024 pm 05:40 PM
Grouped Query Attention (GroupedQueryAttention) ist eine Methode zur Aufmerksamkeit für mehrere Abfragen in großen Sprachmodellen. Ihr Ziel besteht darin, die Qualität von MHA zu erreichen und gleichzeitig die Geschwindigkeit von MQA beizubehalten. GroupedQueryAttention gruppiert Abfragen und Abfragen innerhalb jeder Gruppe haben die gleiche Aufmerksamkeitsgewichtung, was dazu beiträgt, die Rechenkomplexität zu reduzieren und die Inferenzgeschwindigkeit zu erhöhen. In diesem Artikel erklären wir die Idee der GQA und wie man sie in Code übersetzt. GQA befindet sich im Artikel GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
