
 Technologie-Peripheriegeräte
KI
KI wird wiedergeboren: Sie erlangt die Hegemonie in der Online-Literaturwelt zurück
Technologie-Peripheriegeräte
KI
KI wird wiedergeboren: Sie erlangt die Hegemonie in der Online-Literaturwelt zurück
KI wird wiedergeboren: Sie erlangt die Hegemonie in der Online-Literaturwelt zurück

Reborn, ich werde als MidReal in diesem Leben wiedergeboren. Ein KI-Roboter, der anderen beim Schreiben von „Webartikeln“ helfen kann.

In dieser Zeit habe ich viele Themenwahlen gesehen und mich gelegentlich darüber beschwert. Jemand hat mich tatsächlich gebeten, über Harry Potter zu schreiben. Kann ich bitte besser schreiben als J.K. Rowling? Allerdings kann ich es immer noch als Ventilator oder so verwenden.
Wer liebt das klassische Ambiente nicht? Ich werde diesen Benutzern widerwillig helfen, ihre Fantasie zu verwirklichen.
Um ehrlich zu sein, habe ich alles gesehen, was ich in meinem vorherigen Leben hätte sehen sollen, und alles, was ich nicht hätte sehen sollen. Die folgenden Themen sind alle meine Favoriten.

Diese Schauplätze, die man in Romanen sehr mag, über die aber niemand geschrieben hat, diese unbeliebten oder sogar bösen CPs, die kann man selbst erstellen.

Ich prahle nicht, aber wenn Sie mich zum Schreiben brauchen, kann ich tatsächlich einen hervorragenden Text für Sie erstellen. Wenn Sie mit dem Ende nicht zufrieden sind, Ihnen die Figur gefällt, die „in der Mitte gestorben“ ist, oder auch wenn der Autor während des Schreibprozesses auf Schwierigkeiten stößt, können Sie es getrost mir überlassen und ich werde Inhalte schreiben, die Sie zufrieden stellen .

Süße Artikel, beleidigende Artikel und fantasievolle Artikel, jeder einzelne wird Ihren Sweet Spot treffen.

Nachdem Sie sich den Selbstbericht von MidReal angehört haben, haben Sie ihn verstanden?
MidReal ist ein sehr leistungsfähiges Tool, das auf der Grundlage der vom Benutzer bereitgestellten Szenariobeschreibung entsprechende neuartige Inhalte generieren kann. Die Logik und Kreativität der Handlung sind nicht nur hervorragend, sie generiert während des Generierungsprozesses auch Illustrationen, um das, was Sie sich vorstellen, anschaulicher darzustellen. Darüber hinaus verfügt MidReal über eine sehr interessante Funktion, nämlich seine Interaktivität. Sie können die Handlung auswählen, die Sie entwickeln möchten, um die gesamte Geschichte besser an Ihre Bedürfnisse anzupassen. Egal, ob Sie einen Roman schreiben oder einen Roman erstellen, MidReal ist ein sehr nützliches Werkzeug.
Geben Sie „/start“ in das Dialogfeld ein, um mit dem Erzählen Ihrer Geschichte zu beginnen.
MidReal-Portal: https://www.midreal.ai/

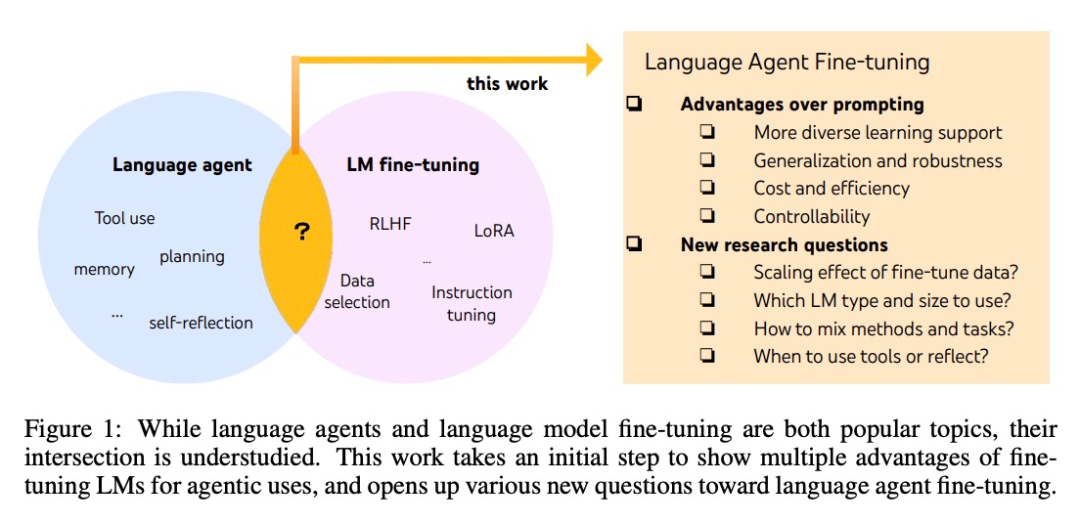
Die Technologie hinter MidReal entstand aus diesem Artikel „FireAct: Toward Language Agent Fine-tuning“. Der Autor des Papiers versuchte zum ersten Mal, einen KI-Agenten zur Feinabstimmung eines Sprachmodells zu verwenden, fand viele Vorteile und schlug daher eine neue Agentenarchitektur vor.
MidReal basiert auf dieser Struktur, weshalb sich Webartikel so gut schreiben lassen.

Link zum Papier: https://arxiv.org/pdf/2310.05915.pdf
Obwohl Agenten und fein abgestimmte große Modelle beide die heißesten KI-Themen sind, gibt es spezifische Unterschiede zwischen ihnen Der Zusammenhang ist unklar. Viele Forscher von System2 Research, der University of Cambridge usw. haben diesen „akademischen blauen Ozean“ erforscht, den nur wenige Menschen betreten haben.
Die Entwicklung von KI-Agenten basiert normalerweise auf Standard-Sprachmodellen. Da Sprachmodelle jedoch nicht als Agenten entwickelt werden, weisen die meisten Sprachmodelle nach der Erweiterung der Agenten eine schlechte Leistung und Robustheit auf. Die intelligentesten Agenten können nur von GPT-4 unterstützt werden und können Probleme wie hohe Kosten und Latenz sowie geringe Steuerbarkeit und hohe Wiederholbarkeit nicht vermeiden.
Durch Feinabstimmung können die oben genannten Probleme gelöst werden. In diesem Artikel machten Forscher auch den ersten Schritt zu einer systematischeren Untersuchung der Sprachintelligenz. Sie schlugen FireAct vor, das die von mehreren Aufgaben und Eingabeaufforderungsmethoden generierten „Aktionstrajektorien“ des Agenten verwenden kann, um das Sprachmodell zu verfeinern, sodass sich das Modell besser an verschiedene Aufgaben und Situationen anpassen und seine Gesamtleistung und Anwendbarkeit verbessern kann.
Methodeneinführung
Diese Forschung basiert hauptsächlich auf einer beliebten KI-Agentenmethode: ReAct. Eine ReAct-Aufgabenlösungsbahn besteht aus mehreren „Denken-Handeln-Beobachten“-Runden. Konkret soll der KI-Agent eine Aufgabe erledigen, bei der das Sprachmodell eine ähnliche Rolle wie das „Gehirn“ spielt. Es bietet KI-Agenten problemlösendes „Denken“ und strukturierte Handlungsanweisungen, interagiert kontextabhängig mit verschiedenen Tools und erhält dabei beobachtetes Feedback.
Basierend auf ReAct schlug der Autor FireAct vor, wie in Abbildung 2 dargestellt. FireAct nutzt die Eingabeaufforderungen eines leistungsstarken Sprachmodells mit wenigen Stichproben, um verschiedene ReAct-Trajektorien zu generieren und kleinere Sprachmodelle zu verfeinern. Im Gegensatz zu früheren ähnlichen Studien ist FireAct in der Lage, mehrere Trainingsaufgaben und Aufforderungsmethoden zu kombinieren und so die Datenvielfalt erheblich zu fördern.
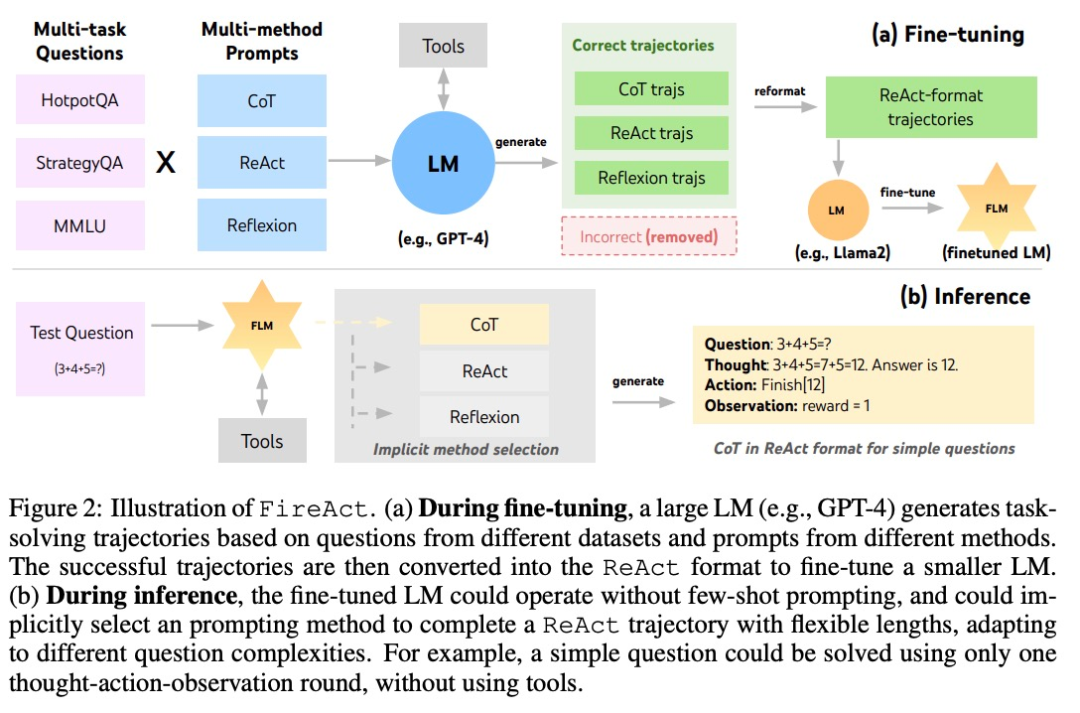
Der Autor verweist außerdem auf zwei ReAct-kompatible Methoden:
- Chain of Thought (CoT) ist eine effektive Möglichkeit, Zwischenschlüsse zu generieren, die Fragen und Antworten verbinden. Jede CoT-Trajektorie kann zu einer einrundigen ReAct-Trajektorie vereinfacht werden, wobei „Denken“ für Zwischenschlussfolgerungen und „Aktion“ für zurückgegebene Antworten steht. CoT ist besonders nützlich, wenn keine Interaktion mit Anwendungstools erforderlich ist.
- Reflexion folgt weitgehend dem ReAct-Verlauf, fügt jedoch zusätzliches Feedback und Selbstreflexion hinzu. In dieser Studie wurde die Reflexion nur in den Runden 6 und 10 von ReAct angeregt. Auf diese Weise kann die lange ReAct-Trajektorie einen strategischen „Drehpunkt“ für die Lösung der aktuellen Aufgabe darstellen, der dem Modell bei der Lösung oder Anpassung der Strategie helfen kann. Wenn Sie beispielsweise bei der Suche nach „Filmtitel“ keine Antwort erhalten, sollten Sie das Suchwort in „Regisseur“ ändern.
Während des Argumentationsprozesses reduziert der KI-Agent im FireAct-Framework die Anzahl der erforderlichen Beispiel-Eingabewörter erheblich, wodurch das Denken effizienter und einfacher wird. Es ist in der Lage, implizit die geeignete Methode basierend auf der Komplexität der Aufgabe auszuwählen. Da FireAct über eine breitere und vielfältigere Lernunterstützung verfügt, weist es stärkere Generalisierungsfähigkeiten und Robustheit auf als herkömmliche Methoden zur Feinabstimmung von Stichworten.
Experimente und Ergebnisse
Der HotpotQuestion Answering (HotpotQA)-Datensatz ist ein in der Forschung zur Verarbeitung natürlicher Sprache weit verbreiteter Datensatz, der eine Reihe von Fragen und Antworten zu aktuellen Themen enthält. Bamboogle ist ein Spiel zur Suchmaschinenoptimierung (SEO), bei dem Spieler mithilfe von Suchmaschinen eine Reihe von Rätseln lösen müssen. StrategyQA ist ein Datensatz zur Beantwortung von Strategiefragen, der eine Vielzahl von Fragen und Antworten im Zusammenhang mit der Strategieformulierung und -ausführung enthält. MMLU ist ein multimodaler Lerndatensatz, mit dem untersucht wird, wie mehrere Wahrnehmungsmodalitäten (wie Bilder, Sprache usw.) zum Lernen und Denken kombiniert werden können.
- HotpotQA ist ein QA-Datensatz, der einen anspruchsvolleren Test für mehrstufiges Denken und Wissensabruf darstellt. Die Forscher verwendeten 2.000 zufällige Trainingsfragen zur Feinabstimmung der Datenkuration und 500 zufällige Entwicklerfragen zur Auswertung.
- Bamboogle ist ein Testsatz mit 125 Multi-Hop-Fragen in einem ähnlichen Format wie HotpotQA, aber sorgfältig gestaltet, um ein direktes Googeln der Fragen zu vermeiden.
- StrategyQA ist ein Ja/Nein-QA-Datensatz, der einen impliziten Inferenzschritt erfordert.
- MMLU umfasst 57 Multiple-Choice-Qualitätssicherungsaufgaben in verschiedenen Bereichen wie Grundmathematik, Geschichte und Informatik.
Tool: Forscher haben mit SerpAPI1 ein Google-Suchtool erstellt, das das erste Ergebnis aus den vorhandenen Einträgen „Antwortfeld“, „Antwortausschnitt“, „hervorgehobenes Wort“ oder „Erster Ergebnisausschnitt“ zurückgibt und so kurze Antworten gewährleistet und relevant. Sie fanden heraus, dass ein solch einfaches Tool ausreicht, um grundlegende Qualitätssicherungsanforderungen für verschiedene Aufgaben zu erfüllen und die Benutzerfreundlichkeit und Vielseitigkeit fein abgestimmter Modelle verbessert.
Forscher untersuchten drei LM-Serien: OpenAI GPT, Llama-2 und CodeLlama.
Feinabstimmungsmethode: Die Forscher verwendeten in den meisten Feinabstimmungsexperimenten Low-Rank Adaptation (LoRA), in einigen Vergleichen wurde jedoch auch die Feinabstimmung des vollständigen Modells verwendet. Unter Berücksichtigung verschiedener grundlegender Faktoren für die Feinabstimmung von Sprachagenten teilten sie das Experiment mit zunehmender Komplexität in drei Teile auf:
- Feinabstimmung mithilfe einer einzigen Eingabeaufforderungsmethode in einer einzigen Aufgabe;
- Verwendung mehrerer Eingabeaufforderungsmethoden in einer einzigen Aufgabenmethoden zur Feinabstimmung;
- Verwenden Sie mehrere Methoden zur Feinabstimmung über mehrere Aufgaben hinweg.
1. Verwenden Sie eine einzelne Eingabeaufforderungsmethode zur Feinabstimmung in einer einzelnen Aufgabe
Forscher untersuchten das Problem der Feinabstimmung mithilfe von Daten aus einer einzelnen Aufgabe (HotpotQA) und einer einzigen Eingabeaufforderungsmethode (ReAct). Mit diesem einfachen und kontrollierbaren Aufbau bestätigen sie die verschiedenen Vorteile der Feinabstimmung gegenüber Hinweisen (Leistung, Effizienz, Robustheit, Generalisierung) und untersuchen die Auswirkungen verschiedener LMs, Datengrößen und Feinabstimmungsmethoden.
Wie in Tabelle 2 gezeigt, kann eine Feinabstimmung die Aufforderungswirkung von HotpotQA EM kontinuierlich und deutlich verbessern. Während schwächere LMs stärker von der Feinabstimmung profitieren (z. B. verbesserte sich Llama-2-7B um 77 %), kann selbst ein leistungsstarker LM wie GPT-3.5 die Leistung durch Feinabstimmung um 25 % verbessern, was die Vorteile des Lernens deutlich demonstriert aus weiteren Proben. Im Vergleich zur starken Cue-Basislinie in Tabelle 1 haben wir festgestellt, dass das fein abgestimmte Llama-2-13B alle GPT-3.5-Cueing-Methoden übertrifft. Dies deutet darauf hin, dass die Feinabstimmung eines kleinen Open-Source-LM effektiver sein könnte als die Einführung eines leistungsfähigeren kommerziellen LM.
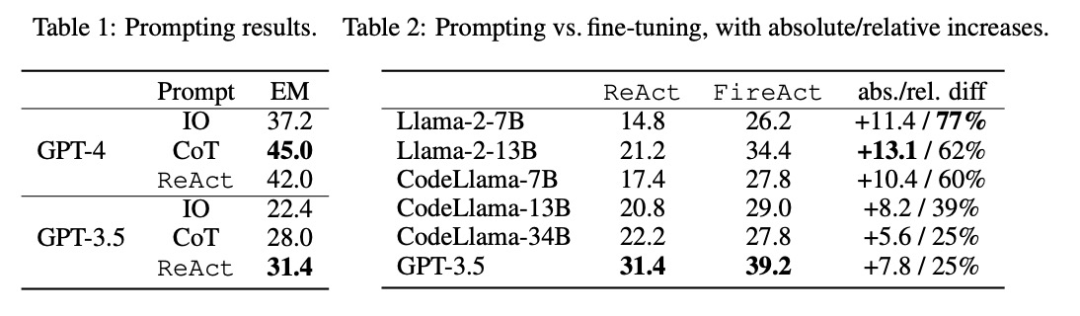
Während des Agent-Inferenzprozesses ist die Feinabstimmung kostengünstiger und schneller. Da für die Feinabstimmung von LM keine geringe Anzahl kontextbezogener Beispiele erforderlich ist, ist die Schlussfolgerung effizienter. Beispielsweise vergleicht der erste Teil von Tabelle 3 die Kosten einer fein abgestimmten Inferenz mit der ShiyongtishideGPT-3.5-Inferenz und stellt eine Reduzierung der Inferenzzeit um 70 % und eine Reduzierung der gesamten Inferenzkosten fest. Die Forscher betrachteten eine vereinfachte und harmlose Einstellung, d immer noch möglich, die Frage fundiert zu beantworten. Den Daten im zweiten Teil von Tabelle 3 zufolge ist die Einstellung „Keine“ schwieriger, da ReAct EM um 33,8 % zurückgeht, während FireAct EM nur um 14,2 % zurückgeht. Diese vorläufigen Ergebnisse zeigen, dass vielfältige Lernunterstützung wichtig ist, um die Robustheit zu verbessern.
Der dritte Teil von Tabelle 3 zeigt die EM-Ergebnisse des fein abgestimmten und angedeuteten GPT-3.5 auf Bamboogle. Während sich GPT-3.5 mit HotpotQA oder der Verwendung von Hinweisen einigermaßen gut auf Bamboogle verallgemeinern lässt, übertrifft ersteres (44,0 EM) immer noch letzteres (40,8 EM), was darauf hindeutet, dass die Feinabstimmung einen Generalisierungsvorteil hat. 
Zweitens hat die Verwendung mehrerer Methoden zur Feinabstimmung verschiedener Sprachmodelle unterschiedliche Auswirkungen. Wie in Tabelle 4 gezeigt, führt die Verwendung einer Kombination mehrerer Agenten zur Feinabstimmung nicht immer zu Verbesserungen, und die optimale Kombination von Methoden hängt vom zugrunde liegenden Sprachmodell ab. Beispielsweise übertrifft ReAct+CoT ReAct für GPT-3.5- und Llama-2-Modelle, nicht jedoch für das CodeLlama-Modell. Für CodeLlama7/13B erzielte ReAct+CoT+Reflexion die schlechtesten Ergebnisse, CodeLlama-34B erzielte jedoch die besten Ergebnisse. Diese Ergebnisse legen nahe, dass weitere Untersuchungen zur Interaktion zwischen zugrunde liegenden Sprachmodellen und Feinabstimmungsdaten erforderlich sind.

Um besser zu verstehen, ob ein Agent, der mehrere Methoden kombiniert, in der Lage ist, basierend auf der Aufgabe eine geeignete Lösung auszuwählen, berechneten die Forscher die Punktzahl der zufällig ausgewählten Methoden während des Inferenzprozesses. Dieser Wert (32,4) ist viel niedriger als bei allen Agenten, die mehrere Methoden kombiniert haben, was darauf hindeutet, dass die Auswahl einer Lösung keine leichte Aufgabe ist. Allerdings erreichte die beste Lösung pro Instanz ebenfalls nur 52,0, was darauf hindeutet, dass es bei der Auswahl der Aufforderungsmethode noch Raum für Verbesserungen gibt.
3. Verwenden Sie mehrere Methoden zur Feinabstimmung für mehrere Aufgaben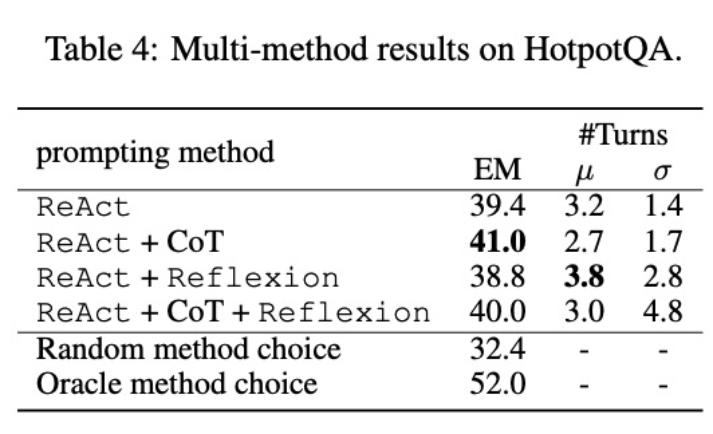
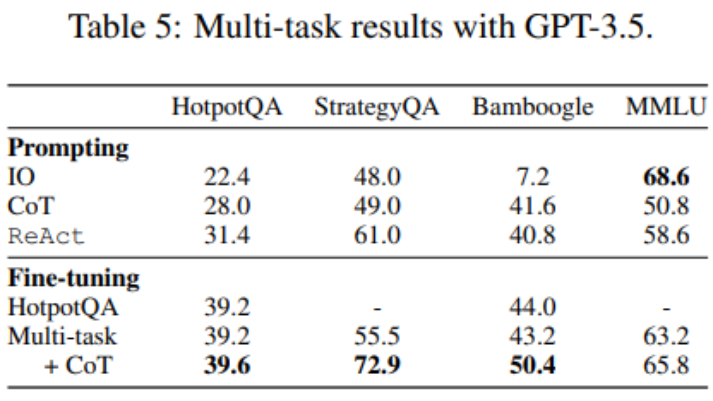
Bislang wurden für die Feinabstimmung nur HotpotQA-Daten verwendet, aber empirische Studien zur LM-Feinabstimmung zeigen, dass die Mischung verschiedener Aufgaben Vorteile bietet. Die Forscher optimierten GPT-3.5 anhand gemischter Trainingsdaten aus drei Datensätzen: HotpotQA (500 ReAct-Proben, 277 CoT-Proben), StrategyQA (388 ReAct-Proben, 380 CoT-Proben) und MMLU-Proben (456 ReAct-Proben, 469 CoT-Proben). ).
Wie in Tabelle 5 gezeigt, bleibt die Leistung von HotpotQA/Bamboogle nach dem Hinzufügen von StrategyQA/MMLU-Daten nahezu unverändert. Einerseits enthalten StrategyQA/MMLU-Tracks sehr unterschiedliche Fragen und Tools-Nutzungsstrategien, was die Migration erschwert. Andererseits hatte das Hinzufügen von StrategyQA/MMLU trotz der Änderung in der Verteilung keinen Einfluss auf die Leistung von HotpotQA/Bamboogle, was darauf hindeutet, dass die Feinabstimmung eines Multitask-Agenten, um mehrere Singletask-Agenten zu ersetzen, eine mögliche zukünftige Richtung ist. Als die Forscher von der Feinabstimmung mit mehreren Aufgaben und einer einzelnen Methode zur Feinabstimmung mit mehreren Aufgaben und mehreren Methoden wechselten, stellten sie Leistungsverbesserungen bei allen Aufgaben fest, was erneut den Wert der Feinabstimmung von Agenten mit mehreren Methoden verdeutlichte.
Für weitere technische Details lesen Sie bitte den Originalartikel.
Referenzlink:
- https://twitter.com/Tisoga/status/1739813471246786823
- https://www.zhihu.com/people/eyew3g
Das obige ist der detaillierte Inhalt vonKI wird wiedergeboren: Sie erlangt die Hegemonie in der Online-Literaturwelt zurück. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
