

Installieren Sie Apache Hadoop auf CentOS!

| Einführung | Die Apache Hadoop-Softwarebibliothek ist ein Framework, das die verteilte Verarbeitung großer Datenmengen auf einem Computercluster mithilfe eines einfachen Programmiermodells ermöglicht. Apache™ Hadoop® ist Open-Source-Software für zuverlässiges, skalierbares, verteiltes Computing. |
Das Projekt umfasst folgende Module:
- Hadoop Common: Gemeinsame Tools, die andere Hadoop-Module unterstützen.
- Hadoop Distributed File System (HDFS™): Ein verteiltes Dateisystem, das Zugriffsunterstützung mit hohem Durchsatz auf Anwendungsdaten bietet.
- Hadoop YARN: Jobplanungs- und Clusterressourcenmanagement-Framework.
- Hadoop MapReduce: Ein YARN-basiertes Parallelverarbeitungssystem für große Datenmengen.
Dieser Artikel hilft Ihnen Schritt für Schritt bei der Installation von Hadoop unter CentOS und der Konfiguration eines Einzelknoten-Hadoop-Clusters.
Java installierenBevor Sie Hadoop installieren, stellen Sie bitte sicher, dass Java auf Ihrem System installiert ist. Verwenden Sie diesen Befehl, um die installierte Java-Version zu überprüfen.
java -version java version "1.7.0_75" Java(TM) SE Runtime Environment (build 1.7.0_75-b13) Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
Um Java zu installieren oder zu aktualisieren, befolgen Sie bitte die nachstehenden Schritt-für-Schritt-Anweisungen.
Der erste Schritt besteht darin, die neueste Java-Version von der offiziellen Oracle-Website herunterzuladen.
cd /opt/ wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz" tar xzf jdk-7u79-linux-x64.tar.gz
Erfordert Setup, um alternativ eine neuere Version von Java zu verwenden. Verwenden Sie dazu den folgenden Befehl.
cd /opt/jdk1.7.0_79/ alternatives --install /usr/bin/java java /opt/jdk1.7.0_79/bin/java 2 alternatives --config java There are 3 programs which provide 'java'. Selection Command ----------------------------------------------- * 1 /opt/jdk1.7.0_60/bin/java + 2 /opt/jdk1.7.0_72/bin/java 3 /opt/jdk1.7.0_79/bin/java Enter to keep the current selection[+], or type selection number: 3 [Press Enter]
Jetzt müssen Sie möglicherweise auch den Befehl alternatives verwenden, um die Befehlspfade javac und jar festzulegen.
alternatives --install /usr/bin/jar jar /opt/jdk1.7.0_79/bin/jar 2 alternatives --install /usr/bin/javac javac /opt/jdk1.7.0_79/bin/javac 2 alternatives --set jar /opt/jdk1.7.0_79/bin/jar alternatives --set javac /opt/jdk1.7.0_79/bin/javac
Der nächste Schritt besteht darin, die Umgebungsvariablen zu konfigurieren. Verwenden Sie die folgenden Befehle, um diese Variablen korrekt festzulegen.
Java_HOME-Variable festlegen:
export JAVA_HOME=/opt/jdk1.7.0_79
JRE_HOME-Variable festlegen:
export JRE_HOME=/opt/jdk1.7.0_79/jre
PATH-Variable festlegen:
export PATH=$PATH:/opt/jdk1.7.0_79/bin:/opt/jdk1.7.0_79/jre/bin
Nach dem Einrichten der Java-Umgebung. Beginnen Sie mit der Installation von Apache Hadoop.
Der erste Schritt besteht darin, ein Systembenutzerkonto für die Hadoop-Installation zu erstellen.
useradd hadoop passwd hadoop
Jetzt müssen Sie den SSH-Schlüssel für den Benutzer hadoop konfigurieren. Verwenden Sie den folgenden Befehl, um die passwortlose SSH-Anmeldung zu aktivieren.
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys exit
Laden Sie jetzt die neueste verfügbare Version von Hadoop von der offiziellen Website hadoop.apache.org herunter.
cd ~ wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz tar xzf hadoop-2.6.0.tar.gz mv hadoop-2.6.0 hadoop
Der nächste Schritt besteht darin, die von Hadoop verwendeten Umgebungsvariablen festzulegen.
Bearbeiten Sie ~/.bashrc und fügen Sie die folgenden Werte am Ende der Datei hinzu.
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Übernehmen Sie Änderungen in der aktuellen Betriebsumgebung.
source ~/.bashrc
Bearbeiten Sie $HADOOP_HOME/etc/hadoop/hadoop-env.sh und legen Sie die Umgebungsvariable JAVA_HOME fest.
export JAVA_HOME=/opt/jdk1.7.0_79/
Jetzt beginnen wir mit der Konfiguration eines einfachen Hadoop-Einzelknoten-Clusters.
Bearbeiten Sie zunächst die Hadoop-Konfigurationsdatei und nehmen Sie die folgenden Änderungen vor.
cd /home/hadoop/hadoop/etc/hadoop
Bearbeiten wir core-site.xml.
fs.default.name hdfs://localhost:9000
Dann bearbeiten Sie hdfs-site.xml:
dfs.replication 1 dfs.name.dir file:///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode
und bearbeiten Sie mapred-site.xml:
mapreduce.framework.name yarn
Letzte Bearbeitung Yarn-Site.xml:
yarn.nodemanager.aux-services mapreduce_shuffle
Formatieren Sie nun den Namensknoten mit dem folgenden Befehl:
hdfs namenode -format
Um alle Hadoop-Dienste zu starten, verwenden Sie den folgenden Befehl:
cd /home/hadoop/hadoop/sbin/ start-dfs.sh start-yarn.sh
Um zu überprüfen, ob alle Dienste normal starten, verwenden Sie den jps-Befehl:
jps
Sie sollten eine Ausgabe wie diese sehen.
26049 SecondaryNameNode 25929 DataNode 26399 Jps 26129 JobTracker 26249 TaskTracker 25807 NameNode
Jetzt können Sie in Ihrem Browser auf den Hadoop-Dienst zugreifen: http://Ihre-IP-Adresse:8088/.
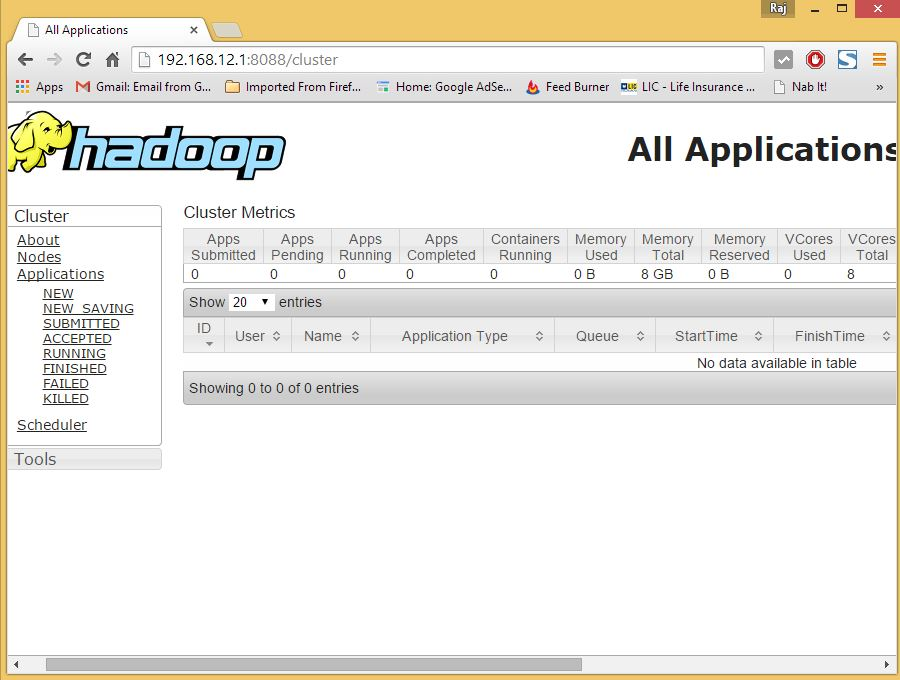
hadoop
Das obige ist der detaillierte Inhalt vonInstallieren Sie Apache Hadoop auf CentOS!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Deepseek Web Version Eingang Deepseek Offizielle Website Eingang
Feb 19, 2025 pm 04:54 PM
Deepseek Web Version Eingang Deepseek Offizielle Website Eingang
Feb 19, 2025 pm 04:54 PM
Deepseek ist ein leistungsstarkes Intelligent -Such- und Analyse -Tool, das zwei Zugriffsmethoden bietet: Webversion und offizielle Website. Die Webversion ist bequem und effizient und kann ohne Installation verwendet werden. Unabhängig davon, ob Einzelpersonen oder Unternehmensnutzer, können sie massive Daten über Deepseek problemlos erhalten und analysieren, um die Arbeitseffizienz zu verbessern, die Entscheidungsfindung zu unterstützen und Innovationen zu fördern.
 So installieren Sie Deepseek
Feb 19, 2025 pm 05:48 PM
So installieren Sie Deepseek
Feb 19, 2025 pm 05:48 PM
Es gibt viele Möglichkeiten, Deepseek zu installieren, einschließlich: kompilieren Sie von Quelle (für erfahrene Entwickler) mit vorberechtigten Paketen (für Windows -Benutzer) mit Docker -Containern (für bequem am besten, um die Kompatibilität nicht zu sorgen), unabhängig von der Methode, die Sie auswählen, bitte lesen Die offiziellen Dokumente vorbereiten sie sorgfältig und bereiten sie voll und ganz vor, um unnötige Schwierigkeiten zu vermeiden.
 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Bitget Offizielle Website -Installation (2025 Anfängerhandbuch)
Feb 21, 2025 pm 08:42 PM
Bitget Offizielle Website -Installation (2025 Anfängerhandbuch)
Feb 21, 2025 pm 08:42 PM
Bitget ist eine Kryptowährungsbörse, die eine Vielzahl von Handelsdienstleistungen anbietet, darunter Spot -Handel, Vertragshandel und Derivate. Der 2018 gegründete Austausch hat seinen Hauptsitz in Singapur und verpflichtet sich, den Benutzern eine sichere und zuverlässige Handelsplattform zu bieten. Bitget bietet eine Vielzahl von Handelspaaren, einschließlich BTC/USDT, ETH/USDT und XRP/USDT. Darüber hinaus hat der Austausch einen Ruf für Sicherheit und Liquidität und bietet eine Vielzahl von Funktionen wie Premium -Bestellarten, gehebelter Handel und Kundenunterstützung rund um die Uhr.
 Holen Sie sich das Installationspaket Gate.io kostenlos
Feb 21, 2025 pm 08:21 PM
Holen Sie sich das Installationspaket Gate.io kostenlos
Feb 21, 2025 pm 08:21 PM
Gate.io ist ein beliebter Kryptowährungsaustausch, den Benutzer verwenden können, indem sie sein Installationspaket herunterladen und auf ihren Geräten installieren. Die Schritte zum Abholen des Installationspakets sind wie folgt: Besuchen Sie die offizielle Website von Gate.io, klicken Sie auf "Download", wählen Sie das entsprechende Betriebssystem (Windows, Mac oder Linux) und laden Sie das Installationspaket auf Ihren Computer herunter. Es wird empfohlen, die Antiviren -Software oder -Firewall während der Installation vorübergehend zu deaktivieren, um eine reibungslose Installation zu gewährleisten. Nach Abschluss muss der Benutzer ein Gate.io -Konto erstellen, um es zu verwenden.
 Ouyi OKX Installationspaket ist direkt enthalten
Feb 21, 2025 pm 08:00 PM
Ouyi OKX Installationspaket ist direkt enthalten
Feb 21, 2025 pm 08:00 PM
Ouyi Okx, die weltweit führende digitale Asset Exchange, hat jetzt ein offizielles Installationspaket gestartet, um ein sicheres und bequemes Handelserlebnis zu bieten. Auf das OKX -Installationspaket von Ouyi muss nicht über einen Browser zugegriffen werden. Der Installationsprozess ist einfach und einfach zu verstehen.
 Wie setze ich nach dem Neustart des Systems automatisch Berechtigungen von Unixsocket fest?
Mar 31, 2025 pm 11:54 PM
Wie setze ich nach dem Neustart des Systems automatisch Berechtigungen von Unixsocket fest?
Mar 31, 2025 pm 11:54 PM
So setzen Sie die Berechtigungen von Unixsocket automatisch nach dem Neustart des Systems. Jedes Mal, wenn das System neu startet, müssen wir den folgenden Befehl ausführen, um die Berechtigungen von Unixsocket: sudo ...
 Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi Exchange Download Official Portal
Feb 21, 2025 pm 07:51 PM
Ouyi, auch bekannt als OKX, ist eine weltweit führende Kryptowährungsplattform. Der Artikel enthält ein Download -Portal für das offizielle Installationspaket von Ouyi, mit dem Benutzer den Ouyi -Client auf verschiedenen Geräten installiert werden können. Dieses Installationspaket unterstützt Windows, Mac, Android und iOS -Systeme. Nach Abschluss der Installation können sich Benutzer registrieren oder sich beim Ouyi -Konto anmelden, Kryptowährungen mit dem Handel mit den von der Plattform erbrachten Diensten anmelden.
